커널 주성분분석Kernel PCA
PCA
주성분분석(Principal Component Analysis, 이하 PCA) 의 기본원리는 Input Matrix의 고유값을 이용해 Input 데이터들의 성분을 분리하는 것이다.
원리
Input Matrix X가 p개의 성분과 첫 열로 일벡터를 가지는 n개의 데이터셋, 즉 n×(p+1) 행렬이라고 하자. 즉,
X=(1,X1)
로 두면, 다음과 같은 n×p 중심화행렬
X1,⊥=(x1−x1ˉ1…xp−xpˉ1)
을 만들 수 있다. 이때 행렬 X1,⊥⊤X1,⊥ 이 Positive Definite 이므로, 고유값분해를 이용해
X1,⊥⊤X1,⊥=PΛP⊤
로 표현가능하다. 이때 p×p 행렬 Λ 는 고유값들로 이루어진 대각행렬 diag(λi) 이다. 만약 고유값들을 크기가 큰 순부터 정리하여 λ1≥⋯≥λp 가 되도록 한다면, 처음 k(<p) 개의 고유값을 선택하고 이에 대응하는 고유벡터들을 P 에서 취하면 이를 주성분분석이라 한다. j번째 고유값에 대응하는 고유벡터를 vj=(vj1,…,vjp) 라고 했을 때, 새로운 벡터 zj=X1,⊥vj 를 정의하면 이는 새로운 input 벡터로 볼 수 있고 이를 각각의 주성분이라고 한다.
PCA의 최적화적 관점
앞서 행렬의 분해로 설명한 PCA를 최적화 문제로 끌고와보도록 하자. 쉽게 설명하기 위해 Input Space를 Rp=X 로 하고 여기서의 유한데이터셋 S=(x1,…,xn) 이 중심화벡터라고 하자 (원소들의 합이 0). X의 각 원소에 대한 w∈Rp 방향으로의 정사영을 hw:X→R 로 두면 이를
hw(x)=x⊤∥w∥w
로 표현할 수 있다 (정사영의 정의). 이때, PCA는 w1,…,wp로 연속적인 축(axis)을 찾는 것이라고 할 수 있는데, 각각의 wi는 나머지 축들과 직교한다. 여기에서 최적화 문제가 발생하는데, 효과적인 축을 찾기 위해 정사영 hw의 분산을 최대화해야 한다는 것이다.
var^(hw)=n1i=1∑n∥w∥2(xi⊤w)2
또한, 이렇게 정의된 분산을 empirical variance라고 한다.
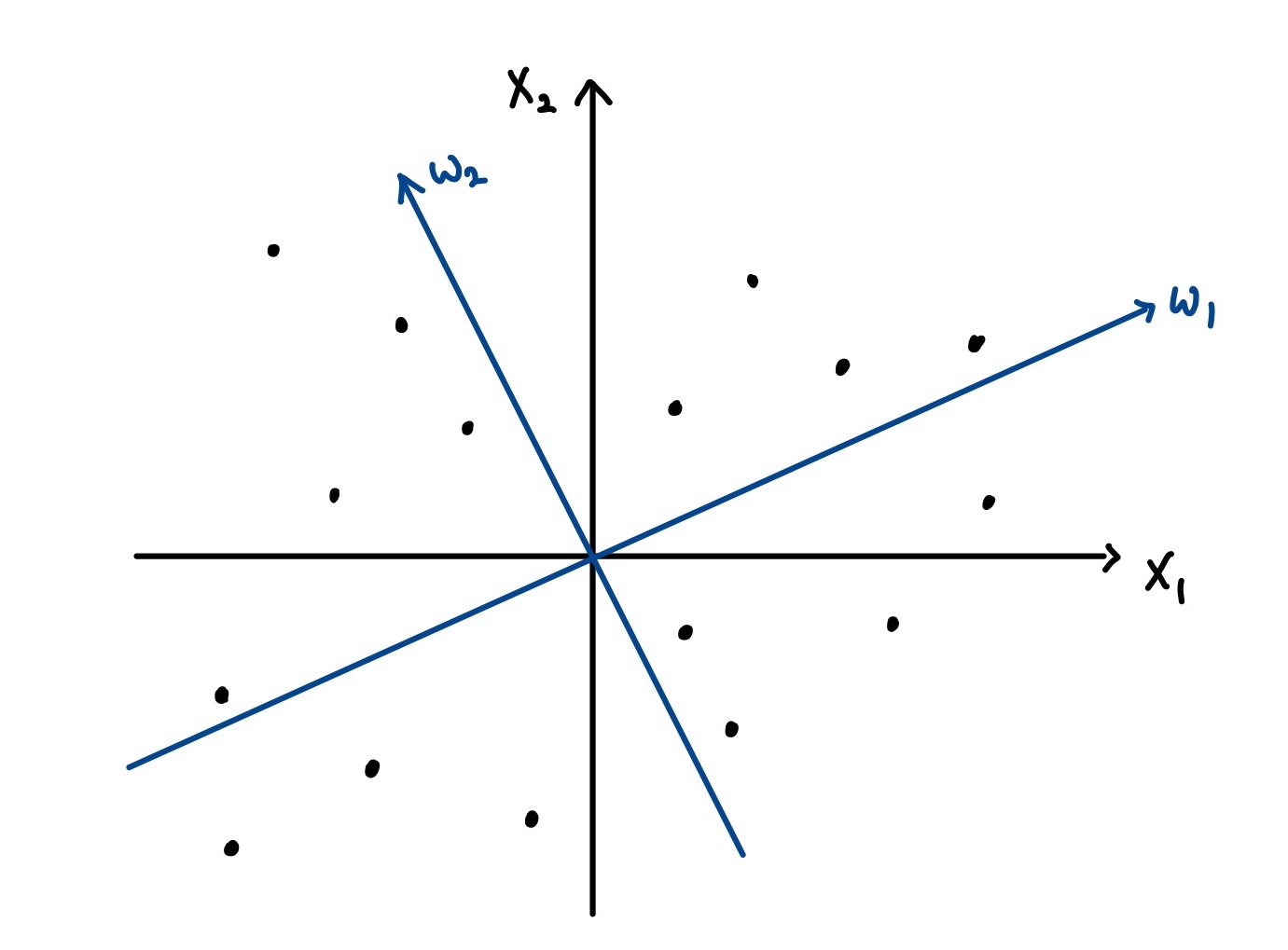
Input Data가 두개의 성분 x1,x2를 가질 떄 PCA는 분산을 최대화하는 두 축 w1,w2(파란색) 를 찾는 것이다.
이렇게 설명되는 PCA와 앞서 설명한 행렬의 고유값분해를 이용한 정의가 동치임은 아래에서 선형커널을 이용해 설명할 수 있다.
범함수의 최적화적 관점
이제 PCA를 범함수의 최적화 관점에서 살펴보자. 선형커널 kL(x,x′)=x⊤x′ 을 생각하고 이에 대응되는 RKHS재생커널힐베르트공간 Hk 가 주어진다고 해보자. PCA에서의 축 w∈Rp 에 대해 RKHS의 함수 fw∈Hk 를 다음과 같이 정의하자.
fw(x)=w⊤x,∥fw∥=∥w∥
그러면 위에서 살펴본 empirical variance는 다음과 같이 표현된다.
∀w∈Rp.var^(hw)=n∥fw∥21i=1∑nfw(xi)2
이떄 각각의 축 wi,wj 가 직교하는 조건이 존재하므로, 각각에 대응하는 RKHS의 함수 fwi,fwj 역시 RKHS상의 점곱에 대해 직교한다. 따라서, 선형커널을 이용한 PCA(Linear PCA)는 다음 최적화 문제로 귀결된다.
PCA as functional optimization
선형PCA는 fi:i=1...p 를 차례대로 찾는 문제로, 다음 범함수 Ψ 를 최대화시킴과 동시에 f1...fi−1 까지의 함수들과 직교해야한다.
∀f∈Hk,Ψ(f)=n∥f∥21j=1∑nf(xj)2
표현자 정리의 적용
앞선 최적화 문제
∀f∈Hk,Ψ(f)=n∥f∥21j=1∑nf(xj)2
는 표현자정리의 조건을 만족시킨다(범함수 Ψ 가 ∥f∥에 대해 단조감소하므로). 그러므로 표현자정리를 적용하면 우리는 위 최적화 문제, 즉 선형PCA의 해가 되는 함수들이 다음의 형태를 취함을 알 수 있다.
∀x∈X,fi(x)=j=1∑nαi,jk(xj,x)
이떄 각 i에 대해 (αi,1,…,αi,n)⊤∈Rn 이고 이를 αi∈Rn 으로 정의하자. 그러면 각 함수의 노음은 다음과 같이 표현된다.
∥fi∥2=αi⊤kαi
또한, 이를 이용하여 최적화 문제를 다시 쓰면 PCA는 결과적으로 연속적인 벡터 α1,...αp∈Rn 이 αi⊤Kαj=0 인 제약조건 하에서 (행렬 K는 커널 행렬 (K)ij=k(xi,xj) 를 의미한다)
nα⊤Kαα⊤K2α
의 값을 최대화시키도록 하는 것이다. 이때 커널행렬은 positive definite하므로 K1/2가 존재한다. β=α⊤K1/2 로 두면 최적화는
βmaxnβ⊤ββ⊤Kβunder βi⊤βj=0
으로 쓸 수 있다. 위 최적화 문제는 Rayleigh's quotient 형태이므로, 커널행렬 K의 가장 큰 고유값에서 최대가 된다. 따라서 이 문제는 가장 큰 값부터 순차적으로 고유값을 찾아가는 문제이므로 이는 위 PCA에서 살펴본 고유값분해 문제와 동치이다.
비선형커널을 이용한 PCA
비선형커널 PCA의 대략적인 원리를 설명하는 다음 그림을 살펴보자.
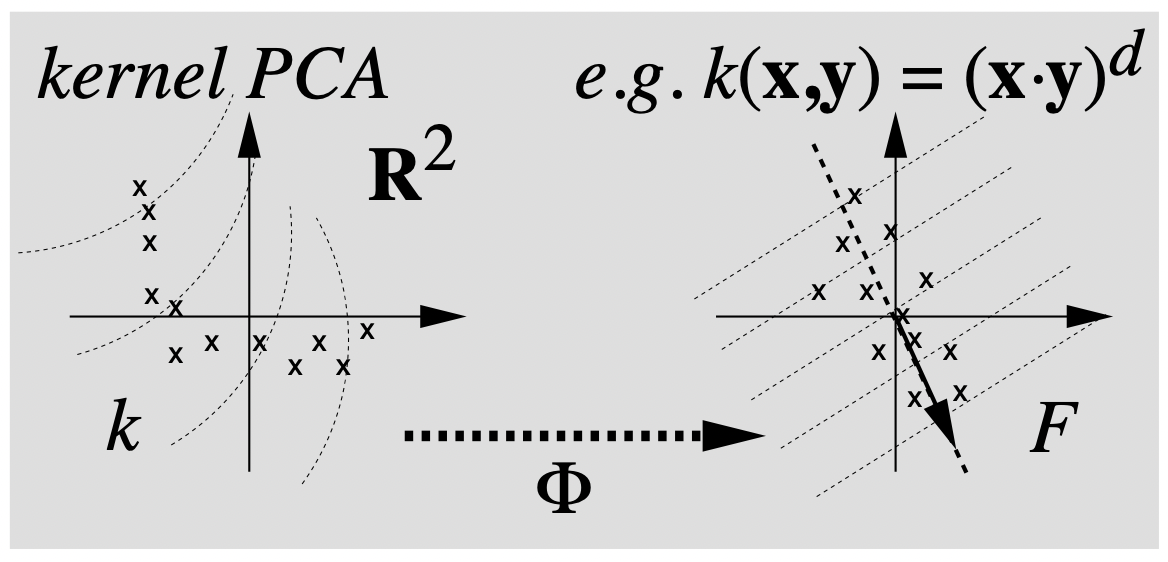
왼쪽과 오른쪽 그림 모두 두개의 성분을 가지는 R2 상의 데이터셋을 표현한 것이다. 이떄 특성공간 F 로의 사상 Φ:R2→F 가 주어진다고 하자. 오른쪽 그림은 각 데이터를(x로 표시된 점들) 특성함수로 mapping해서 Linear PCA를 실행시킨 것이다. 이떄 오른쪽 그림의 대각 화살표는 주성분을 나타내고, 이와 수직으로 그려진 점선들은 주성분의 등고선을 의미한다. 반면, 왼쪽 그림은 다항커널((x,y)d)과 같은 비선형커널을 이용해 커널행렬을 구하고 PCA를 진행한 결과이다. 오른쪽 그림의 직선형태인 등고선은 왼쪽에서 비선형으로 나타남을 확인할 수 있으며, 고유벡터의 존재성 역시 확실하지 않기 때문에 주성분이 표시되지 않음을 의미한다.
핵심은, 이미지, 영상과 같은 고차원 대용량 데이터를 처리하게 될 경우 오른쪽과 같이 특성공간으로 매핑하게 된다면 계산 비용이 과도해지는 문제가 발생하게 될 수 있다는 것이다. 이때 커널함수를 이용한다면 커널행렬을 구하는 연산만으로도 주성분 분석을 쉽게 할 수 있다. 이는 계산비용을 효과적으로 사용할 수 있게 해준다.
References
- A primer on kernel methods, J.Philippe Vert et al.
- Linear Models in Statistics
- Nonlinear Component Analysis as a Kernel Eigenvalue Problem, B.Scholkopf et al. 1998
