따릉이 Project
1.따릉이 데이터 분석하기 (1) EDA
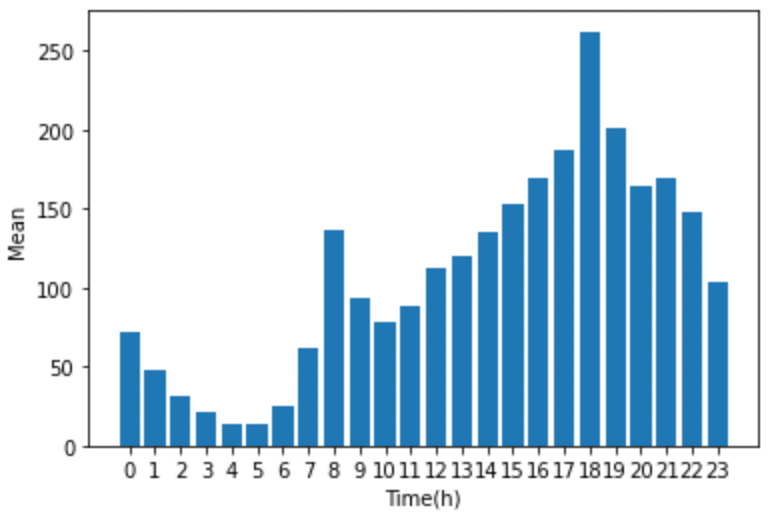
이번 시리즈는 공공데이터인 서울시 공유자전거 따릉이의 데이터를 이용한 small project를 진행해보고자 한다. 데이터를 비롯한 프로젝트의 내용은 데이콘의 내용을 바탕으로 진행했으며, 원래 주제는 데이터를 바탕으로 한 AI 모델을 개발하는 것이다. 하지만 여기서는
2.따릉이 데이터 분석하기 (2) Linear Regression
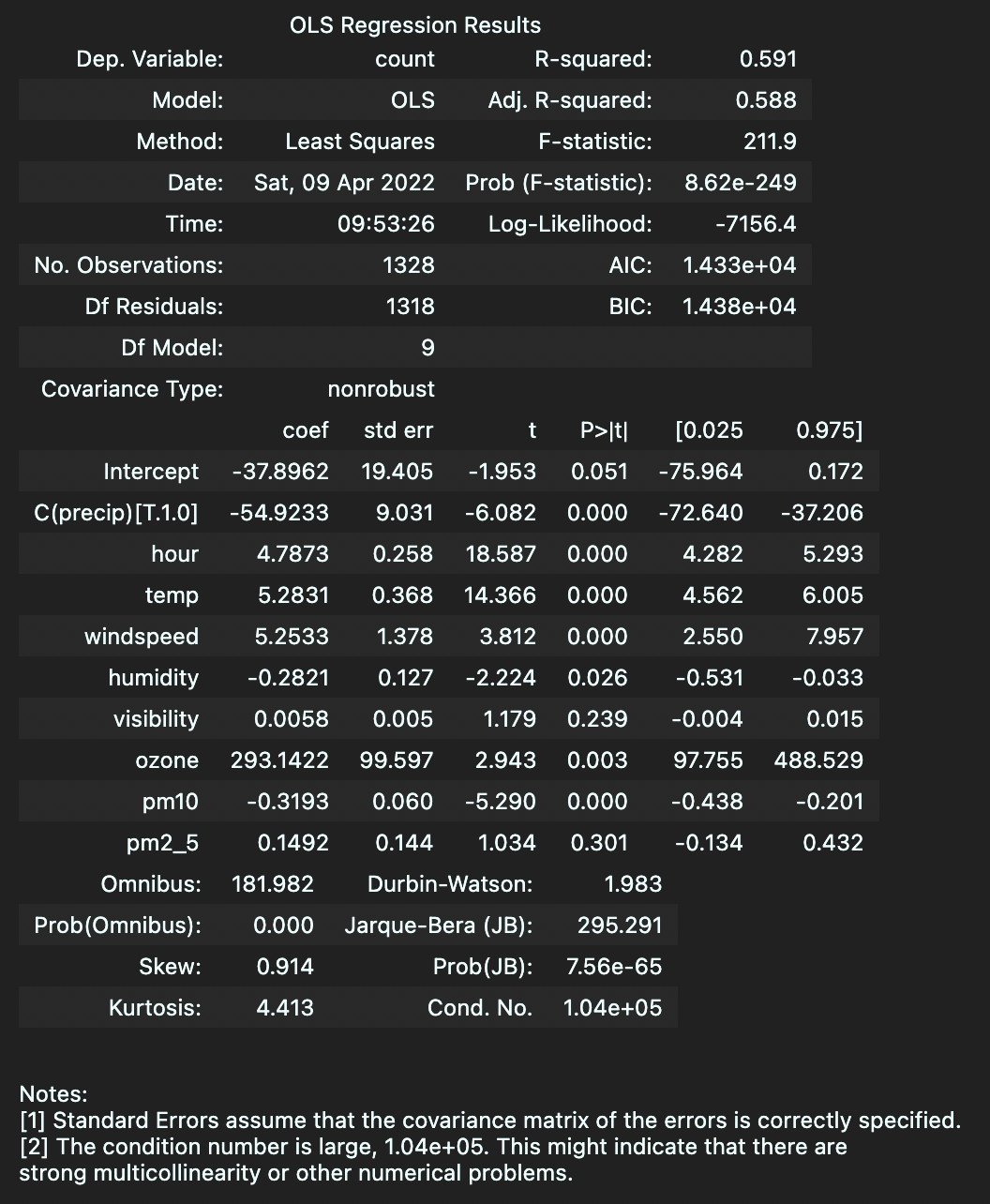
먼저, 앞서 살펴본 따릉이 데이터셋을 이용해 가장 간단한 Linear Regression Model을 구현해보도록 하자. Python에는 statsmodels라는 패키지가 있는데, 이는 R에서 사용하는 형태로 통계분석을 가능하게 해주는 패키지이다(공식 문서 참고). 이
3.따릉이 데이터 분석하기 (3) Shrinkage Methods
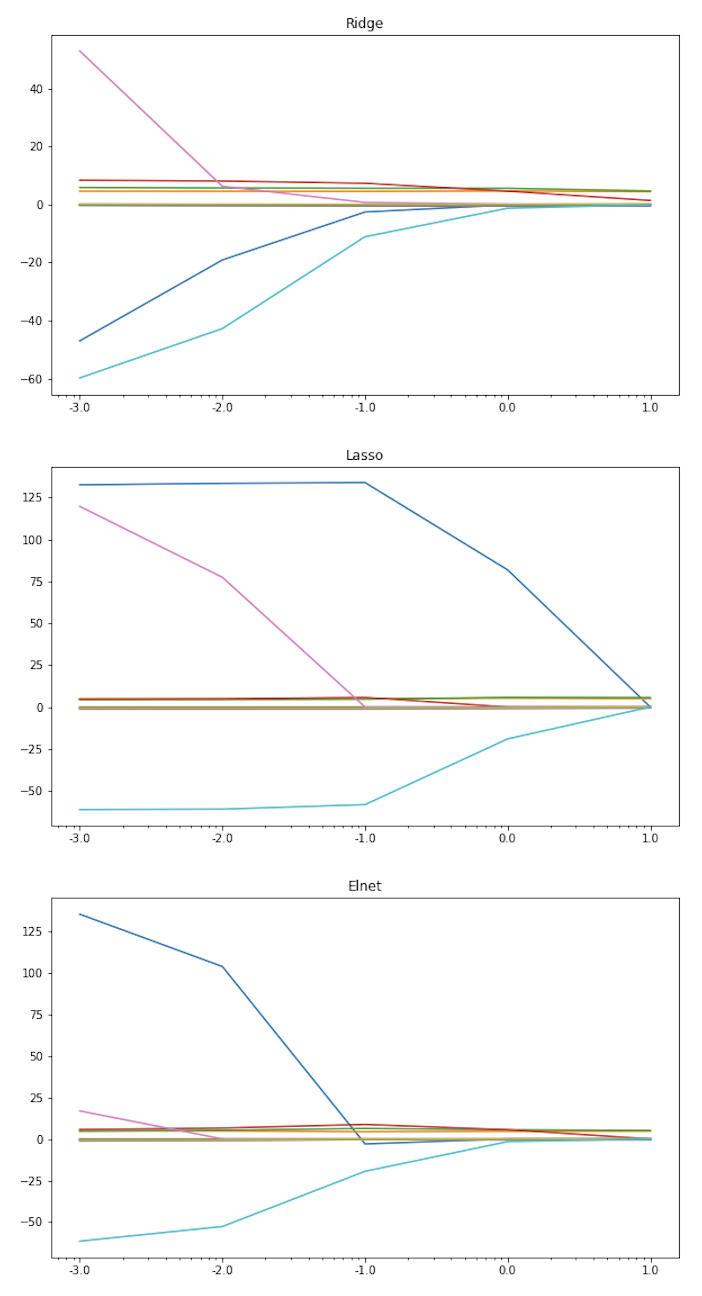
이번 글에서는 Linear regression을 계속 다룰 것인데, 그중에서도 regularization method나 spline regression과 같은 변형된 방법들을 다루어보고자 한다(역시 Regression 문제가 Linear Model로 다루기 최적인듯 하
4.따릉이 데이터 분석하기 (4) Transformation
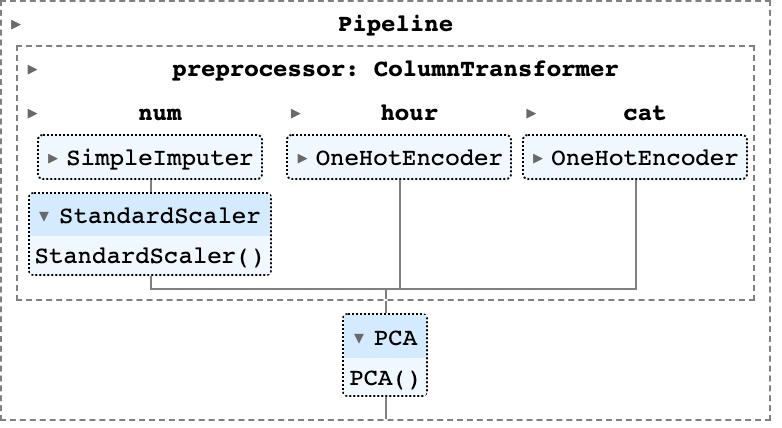
이번에는 PCA를 비롯해 예측변수의 데이터셋을 변환시키는transformation 여러 가지 방법들에 대해 다루어보도록 하겠다. 대표적으로 PCA는 기본적인 회귀문제에 응용되어 PCR로 사용되거나, 고차원 문제의 차원 축소 기법으로 필수적인 역할을 한다. 여기서는 우선
5.따릉이 데이터 분석하기 (5) Tree
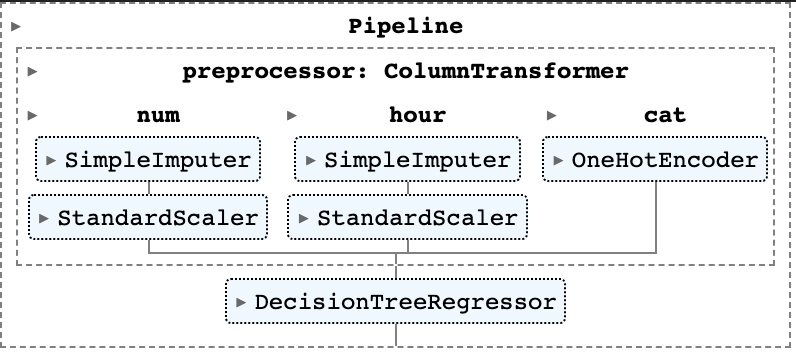
이번에는 Tree 관련 모델들로 주어진 데이터셋을 훈련시켜보고 이를 검증해보도록 하자. 저번 Transformation 데이터 분석 과정과 마찬가지로 scikit-learn의 Pipeline을 이용해 데이터 전처리부터 모델링까지의 파이프라인을 구성해보도록 하겠다. Da
6.따릉이 데이터 분석하기 (6) SVM
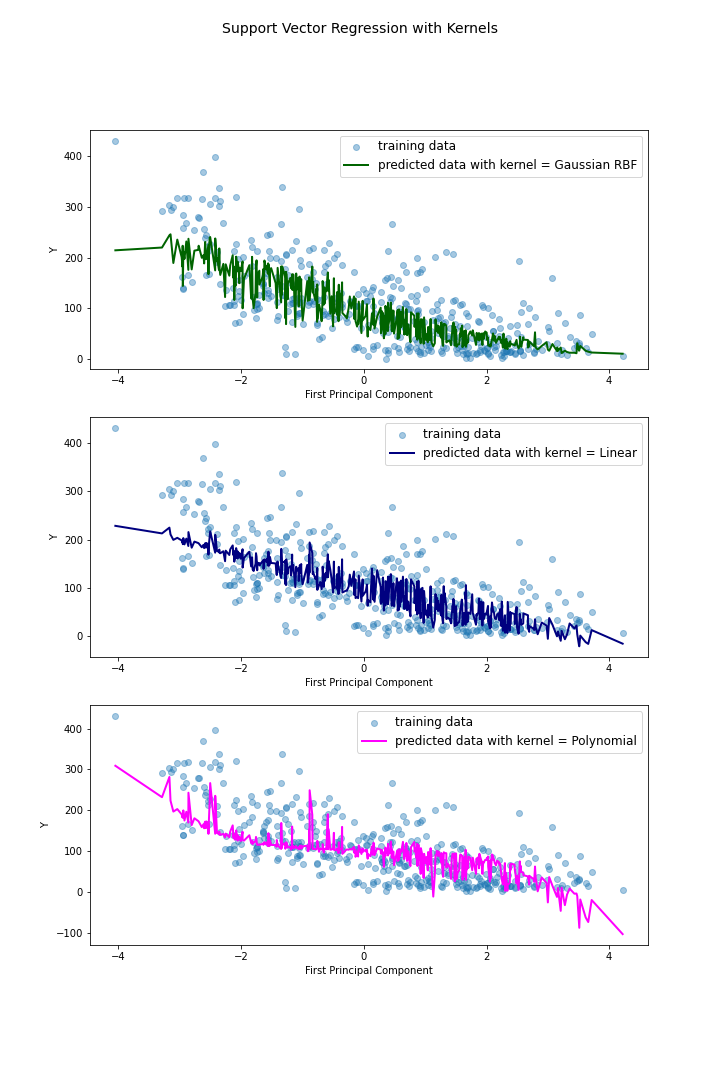
이번 글에서는 대표적인 머신러닝 모델인 SVM(Support Vector Machine)을 이용해 따릉이 이용 데이터의 분석을 진행해보도록 하자. 본래 SVM은 classification의 목적을 위해 고안된 기법으로, 데이터들의 레이블을 분류하는 기준이 되는 초평면을
7.따릉이 데이터 분석하기 (7) AutoML
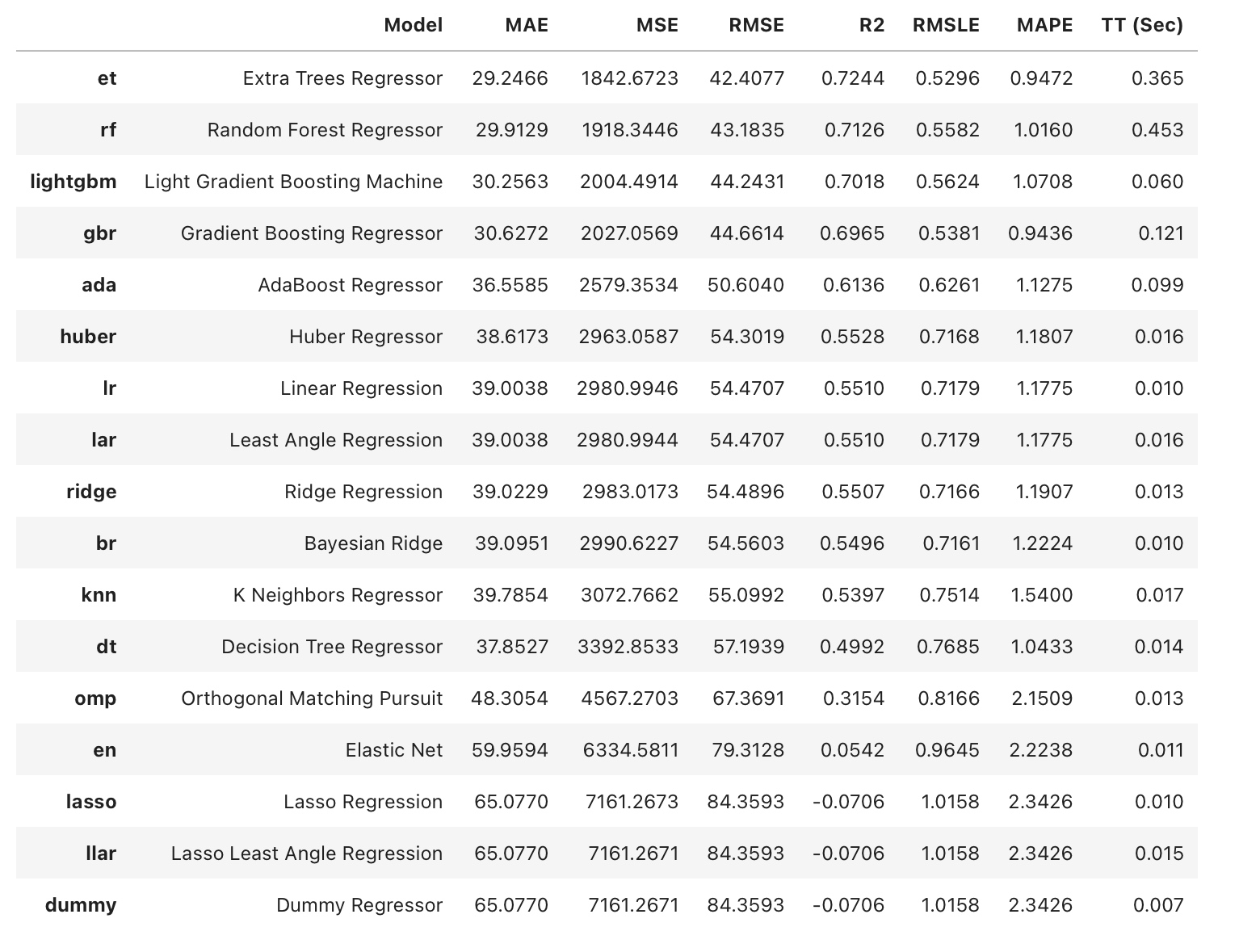
이번 게시글을 끝으로 데이콘의 따릉이 데이터 분석 관련 포스팅을 마치고자 한다. 마지막 내용은 AutoML을 다룰 것인데, AutoML이란 이전에 살펴본 여러 종류의 모델들을 선택하고, hyperparameter들을 최적화하는 일련의 모든 과정들을 자동화하는 방법을 총