따릉이 데이터 분석하기 (7) - AutoML
이번 게시글을 끝으로 데이콘의 따릉이 데이터 분석 관련 포스팅을 마치고자 한다. 마지막 내용은 AutoML을 다룰 것인데, AutoML이란 이전에 살펴본 여러 종류의 모델들을 선택하고, hyperparameter들을 최적화하는 일련의 모든 과정들을 자동화하는 방법을 총칭하는 단어이다. 사실 최근 비즈니스 실무 영역에서는 AutoML이 대세로 자리잡아가는 추세라고 한다. 이전까지는 머신러닝 모델을 선택하고 하이퍼파라미터를 튜닝하기 위해 많은 시간을 소비해야 했으나, AutoML로 이러한 과정을 자동화하여 데이터사이언티스트들은 데이터의 수집, 전처리, 실험 설계 등 분석의 본질적인 성능을 끌어올릴 수 있는 영역에 좀 더 집중하게 되는 것이다. 뿐만 아니라, 비전공자나 다른 분야(서비스 기획, PM 등)에 종사하는 사람들도 간단한 코드 몇줄로 쉽게 모델링 과정을 제공받을 수 있다는 점에서 AutoML은 충분히 매력적인 기술이다(물론 데이터사이언스 전공자에게는 사실 기쁜 소식은 아니다😂). AutoML은 다양한 환경에서 제공하는데, 여기에서는 Python에서 사용할 수 있는 사이킷런 기반의 pycaret 패키지를 이용해 AutoML이 작동하는 전반적인 과정을 살펴보고자 한다. 참고로, AutoML은 컴퓨팅 자원을 상당히 요구하기 때문에, 코딩은 로컬 환경에서 진행하더라도 GPU나 TPU를 지원하는 Colab 환경에서 학습을 진행하는 것이 좋다. 필자도 Colab에서 실습을 진행했다.
데이터 준비 및 전처리
패키지 로드 및 데이터 준비과정은 생략하기로 하고(Full code 참고), 우선 전처리 파이프라인을 다음과 같이 설정했다. 사실 AutoML의 경우 전처리를 별도로 진행하지 않아도, 범주를 자동으로 선택하고 데이터 분포에 맞게끔 변수변환을 진헹하거나, one-hot encoding 등도 알아서 진행해주기 때문에 아래와 같은 파이프라인을 스스로 만들지 않아도 된다.
# Data Preprocessing
numeric_features = list(df_X.columns.drop(['precip','hour']))
numeric_transformer = Pipeline(
steps=[("imputer",SimpleImputer(strategy='median')),("scaler",StandardScaler())]
)
hour_feature = ['hour']
hour_transformer = Pipeline(
steps=[("imputer",SimpleImputer(strategy='most_frequent'))]
)
cat_feature = ['precip']
cat_transformer = Pipeline(
steps=[("imputer",SimpleImputer(strategy="most_frequent"))]
)
preprocessor = ColumnTransformer(
transformers=[
("num", numeric_transformer, numeric_features),
('hour', hour_transformer, hour_feature),
("cat", cat_transformer, cat_feature)
]
)
pycaret은 scikit-learn 기반의 모듈이지만 직접 파이프라인을 구현하지 않으므로, 전처리 과정은 preprocessor을 이용해 직접 데이터를 transform 해야 한다.
X_train_p = pd.DataFrame(preprocessor.fit_transform(X_train))
X_val_p = pd.DataFrame(preprocessor.fit_transform(X_val))pycaret은 모델 설정 과정에서 반응변수 및 예측변수가 모두 포함된 데이터프레임을 요구한다. 따라서 Transformed 된 예측변수들과 반응변수 벡터를 하나의 데이터프레임으로 다음과 같이 만들었다.
# Preprocessed data > to whole Dataframe
data_train = pd.concat([X_train_p,pd.Series(y_train)],axis=1)
data_test = pd.concat([X_val_p,pd.Series(y_val)],axis=1)
columns = numeric_features+hour_feature+cat_feature+['y']
data_train.columns = columns
data_test.columns = columns
data_train # 1021 * 10 columnsAutoML Modeling
pycaret은 다음과 같이 setup 함수를 이용해 어떠한 조건으로 AutoML을 진행할 것인지 설정만 해주면 모든 준비가 끝난다.
# Pycaret env setup
reg_auto = setup(
data = data_train, target = 'y', session_id = 100,
normalize = True, transformation = True, transform_target = True, ## Response Variable normalize
categorical_features=['precip'],
remove_multicollinearity = True, ## 다중공선성 제거
multicollinearity_threshold = 0.90,
silent = True, use_gpu = True, log_experiment = True, experiment_name = 'logs' # 기타 세팅
)첫줄에서는 데이터프레임과 타겟 변수(반응변수)를 지정해주었다. 또한, session_id는 사이킷런의 random_state와 같이 학습과정의 randomness를 제어하게끔 해주는 변수이다. 둘째줄의 normalize는 변수의 정규화를 진행할 것인지 설정하는 것인데, 앞서 정규화를 파이프라인으로 처리했지만 여기서도 일단 True로 설정했다. transformation = True는 데이터가 정규분포 형태를 취하도록 로그변환 등을 수행하도록 하는 변수이며, transform_target은 타겟 변수에 대한 정규변환을 의미한다.
네번째 줄의 remove_multicolinearity는 다중공선성을 일으키는 예측변수를 제거할 것인지 설정하는 변수인데, 다음 threshold 변수에서 그 기준치를 설정한다(0.9). 이밖에도, pca = True 를 설정하여 차원축소를 진행할 것인지, remove_outliers = True를 설정하여 이상치를 제거할 것인지 등을 별도로 설정할 수 있다.
이를 바탕으로, compare_models 함수를 이용해 regression에 사용되는 약 20개의 모델 종류에 대해 모델링 결과를 얻을 수 있다. 아래 코드는 각 모델에 대한 10-fold cross validation을 실행하여 RMSE를 기준으로 가장 성능이 좋은 모델 순으로 결과를 정렬한다.
best = compare_models(sort = 'RMSE', fold = 10) # 10-fold CV
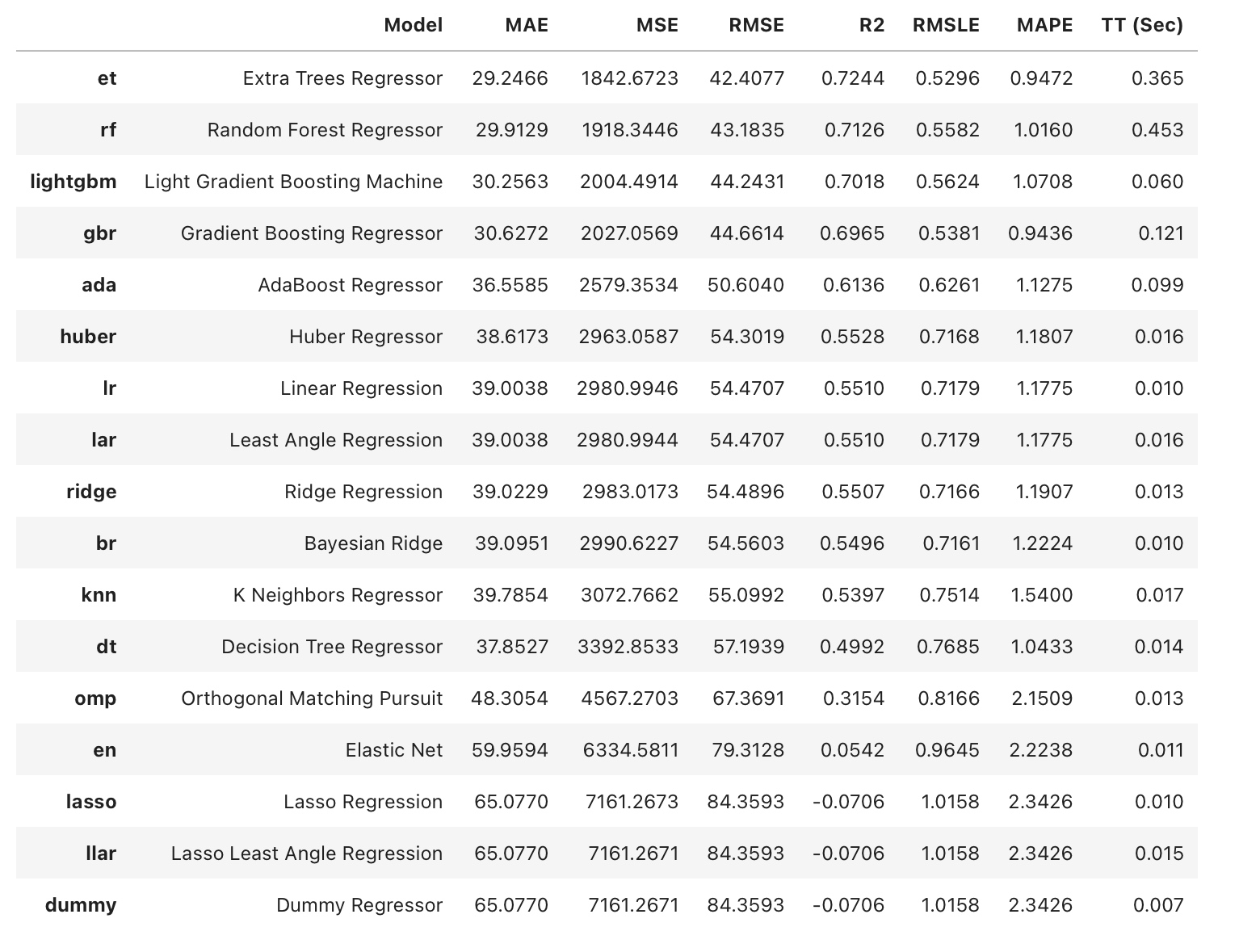
위 그림과 같은 결과를 얻을 수 있다(실제 Colab에서의 실행 결과). 실행 결과 Tree 기반의 모델이(GBM 포함) 상대적으로 성능이 우수하게 도출되었는데, 실제로 이전까지 직접 모델링 한 추세들과 대략 일치함을 확인할 수 있었다. 이 결과를 바탕으로, 이번에는 우수한 결과를 나타낸 특정 모델(Light GBM)에 대한 Tuning 과정을 살펴보도록 하자.
Specific Modeling
우선 앞선 setup 과정을 바탕으로 다음과 같이 구체적인 light GBM 모델을 만들 수 있다.
lightgbm = create_model('lightgbm', fold = 10) # 10-fold CV이때, print(lightgbm) 코드로 모델을 출력하면 아래와 같이 모델에서 설정된 hyperparameter들과 각종 설정값에 대해 살펴볼 수 있다.

이는 아직 구체적인 모델 lightgbm에 대해서는 하이퍼파라미터 튜닝이 이루어지지 않은 상태인데, 아래 코드로 하이퍼파라미터 튜닝을 자동으로 실행할 수 있다.
tuned_lightgbm = tune_model(lightgbm)코드를 실행하면 10-CV 결과를 얻을 수 있고(생략), 앞선 코드와 같이 모델을 print해 하이퍼파라미터 및 설정값을 확인할 수 있다.
Plots
또한, Regression 결과와 관련해 pycaret은 손쉽게 확인할 수 있는 일부 plot들을 제공하고 있다. 대표적으로 아래와 같은 residual plot, prediction error plot, feature importance plot(참고)을 얻을 수 있다.
# Residual Plot
plot_model(tuned_lightgbm, plot="residuals")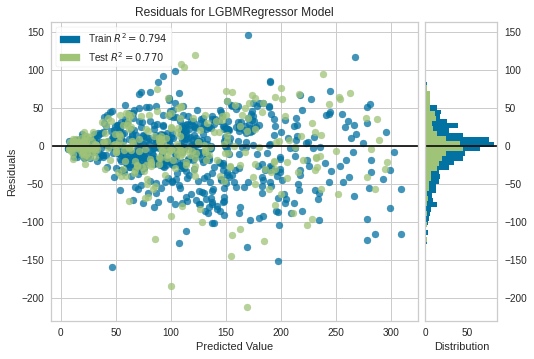
# Prediction Error Plot
plot_model(tuned_lightgbm, plot="error")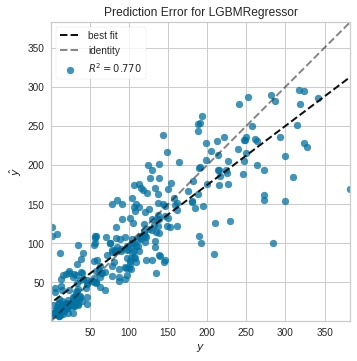
# Feature Importance Plot
plot_model(tuned_lightgbm, plot="feature")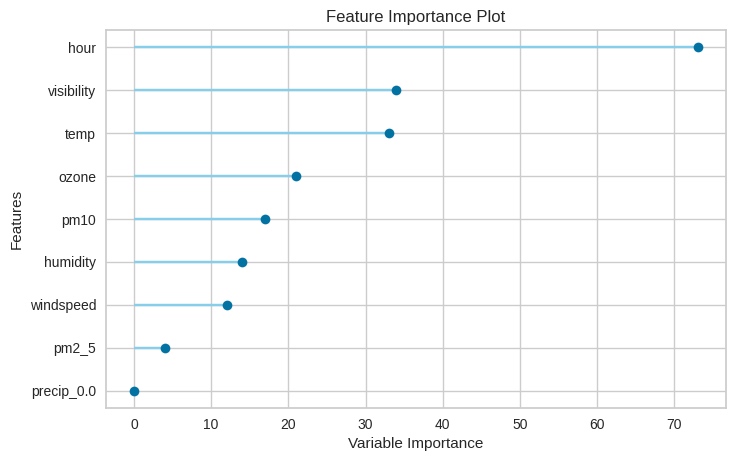
Final Model
마지막으로, 이렇게 얻은 모델을 바탕으로 train-test split을 이용해 또다른 학습 과정을 거치는 finalize_model 함수를 적용하면 다음과 같이 최종 모델을 얻을 수 있다.
# Model Finalizing
final_lightgbm = finalize_model(tuned_lightgbm)
print(final_lightgbm)또한, 최종 모델로 초기 설정했던 validation 데이터 셋에 대해 검증 오차를 구해보면 다음과 같다. 먼저, 아래 코드를 통해 검증 데이터셋에 대한 예측값(Label)이 추가된 데이터프레임을 얻을 수 있다.
# Test dataset Prediction
test_predictions = predict_model(final_lightgbm, data = data_test)
test_predictions.head(5)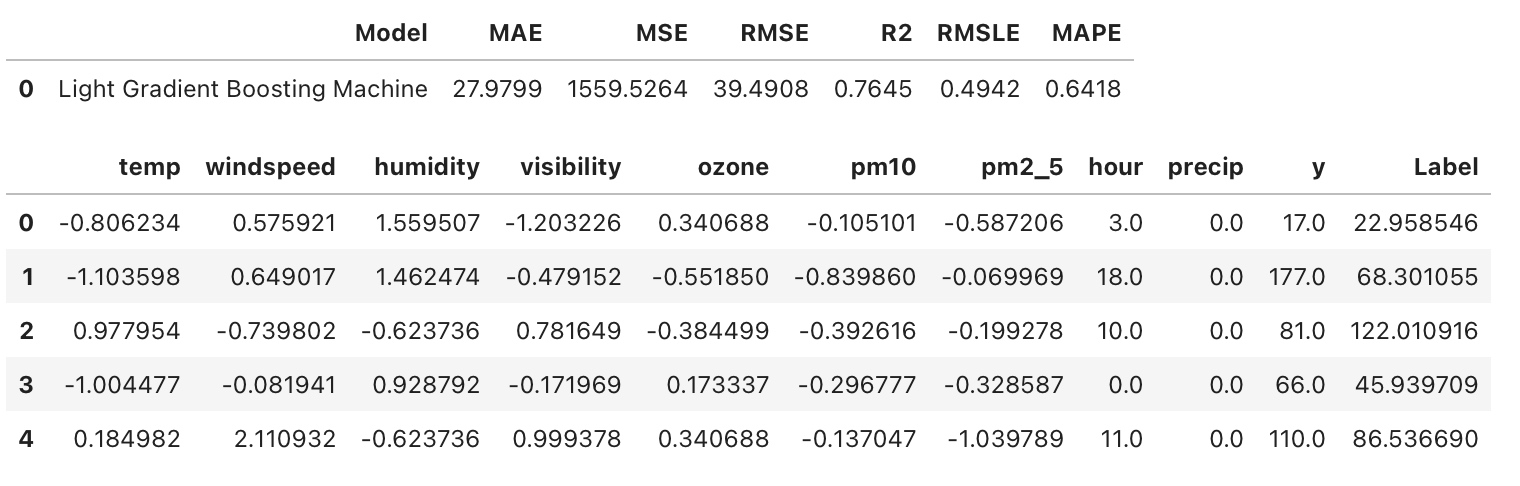
Validation dataset(data_test) 에 대한 최종 metric은 다음과 같이 계산할 수 있다.
# Check Metric
from pycaret.utils import check_metric
check_metric(test_predictions.y, test_predictions.Label, "RMSE") # 39.4908Reference
- Pycaret 공식 문서 : https://pycaret.org
- Full Code on Github : https://github.com/ddangchani/project_ddareungi/blob/main/AutoML.ipynb
