부스팅이란?
부스팅(Boosting)은 앙상블 모형 중 하나로 배깅이 부트스트랩 시 각 표본에 동일한 확률을 부여하는 것과 달리 잘못 분류된 표본에 더 가중치를 적용해 새로운 분류 규칙을 만들고, 이런 과정을 반복해 최종 모형을 만드는 알고리즘이다.
AdaBoost, GBM 같은 알고리즘이 나오면서 배깅보다 성능이 뛰어난 경우가 많다. 특히 XGBoost의 경우 Kaggle에서 상위 랭커들이 사용해 높은 인기를 얻은 알고리즘이다.
- AdaBoost
- GBM : XGBoost, Light GBM
adabag 패키지를 이용하면 Adaboost 알고리즘 수행이 가능하다.
Data Load
> install.packages('adabag')
> library(adabag)> train <- read.csv('ch6-2_train.csv', header=TRUE, stringsAsFactors=TRUE)
> test <- read.csv('ch6-2_test.csv', header=TRUE, stringsAsFactors=TRUE)
> str(train)
'data.frame': 240 obs. of 4 variables:
$ wing_length: int 238 236 256 240 246 233 235 241 232 234 ...
$ tail_length: int 63 67 65 63 65 65 66 66 64 64 ...
$ comb_height: int 34 30 34 35 30 30 30 35 31 30 ...
$ breeds : Factor w/ 3 levels "a","b","c": 1 1 1 1 1 1 1 1 1 1 ...부스팅
boosting() 함수를 이용하여 수행한다.
> boost <- boosting(breeds ~ ., data=train, type='class')변수 중요도
> boost$importance
comb_height tail_length wing_length
21.15480 41.27171 37.5734트리
> plot(boost$trees[[100]], main='Boosting-Adaboost', margin=0.1)
> text(boost$trees[[100]])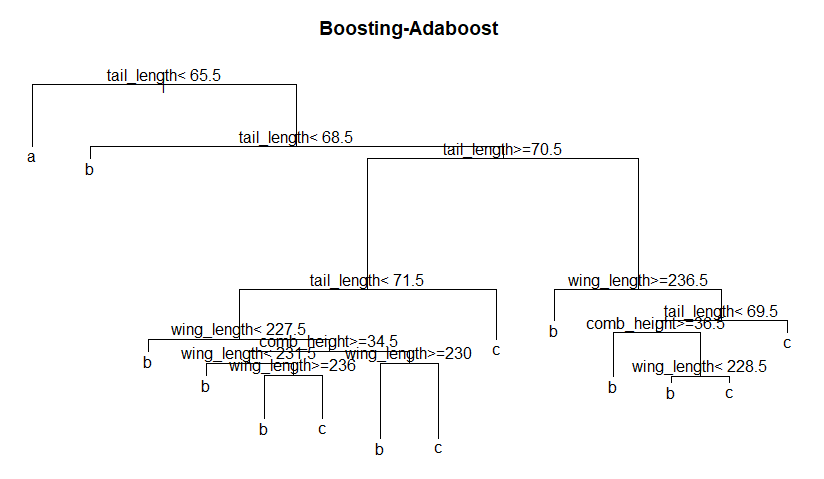
모델 성능 평가
> library(caret)
> pred <- predict(boost, newdata=test, type='class')
> test$pred <- as.factor(pred$class)
> confusionMatrix(test$pred, test$breeds)
Confusion Matrix and Statistics
Reference
Prediction a b c
a 20 1 0
b 0 18 1
c 0 1 19
Overall Statistics
Accuracy : 0.95
95% CI : (0.8608, 0.9896)
No Information Rate : 0.3333
P-Value [Acc > NIR] : < 2.2e-16
Kappa : 0.925
Mcnemar's Test P-Value : NA
Statistics by Class:
Class: a Class: b Class: c
Sensitivity 1.0000 0.9000 0.9500
Specificity 0.9750 0.9750 0.9750
Pos Pred Value 0.9524 0.9474 0.9500
Neg Pred Value 1.0000 0.9512 0.9750
Prevalence 0.3333 0.3333 0.3333
Detection Rate 0.3333 0.3000 0.3167
Detection Prevalence 0.3500 0.3167 0.3333
Balanced Accuracy 0.9875 0.9375 0.9625