Abstract
고차원 감각 입력으로부터 직접 제어 정책을 학습할 수 있는 첫 번째 딥러닝 모델을 소개한다. 이 모델은 Q-러닝 변형으로 훈련된 컨볼루션 신경망으로, 입력은 원시 픽셀이고 출력은 미래 보상을 추정하는 가치 함수이다. 이를 아키텍처나 학습 알고리즘의 조정 없이 Arcade Learning Environment의 7개의 Atari 2600 게임에 적용한 결과, 6개의 게임에서 이전 방식을 능가했으며, 3개의 게임에서는 인간 전문가를 뛰어넘었다.
Introduction
고차원 감각 입력(시각, 음성)으로부터 직접 에이전트를 제어하는 것은 강화 학습(RL)의 오래된 도전이다. 대부분의 성공적인 RL 응용 프로그램은 수작업으로 만든 feature와 선형 가치 함수에 의존했고, 이러한 시스템의 성능은 feature 표현의 품질에 크게 의존한다.
딥러닝의 발전으로 원시 감각 데이터에서 고수준 feature를 추출할 수 있게 되었으며, 이는 컴퓨터 비전과 음성 인식 분야에서 큰 성과가 있었다. 그러나 RL은 손으로 라벨링된 대량의 훈련 데이터를 요구하는 딥러닝 응용 프로그램과 달리, 희소하고 노이즈가 많은 지연된 스칼라 보상 신호로부터 학습해야 한다. 또한 RL에서는 독립되지 않고 상관된 상태 시퀀스와 계속해서 데이터 분포가 변경되는 문제도 존재한다. 논문에서는 컨볼루션 신경망이 이런 문제을 극복하여 복잡한 RL 환경에서 원시 비디오 데이터로부터 성공적인 제어 정책을 학습할 수 있음을 보여준다.
Q-러닝 알고리즘의 변형과 확률적 경사 하강법을 사용하여 가중치를 업데이트하며, 경험 재현 메커니즘을 통해 훈련 분포를 매끄럽게 한다. 네트워크는 게임별 정보나 수작업으로 설계된 시각적 특징을 제공받지 않았으며, 비디오 입력, 보상 및 종료 신호, 가능한 행동 집합만으로 학습했다. Atari 2600 게임(ALE 구현)에 적용한 결과, 네트워크는 7개의 게임 중 6개에서 이전의 RL 알고리즘을 능가했으며, 3개의 게임에서는 인간 전문가를 뛰어넘었다. 네트워크 아키텍처와 모든 하이퍼파라미터는 모든 게임에서 동일했다.
Background
에이전트는 각 시간 단계에서 행동을 선택하고, emulator는 이 행동을 받아 내부 상태와 게임 점수를 수정한다. 에이전트는 내부 상태를 관찰하지 못하고, 현재 화면을 나타내는 이미지와 게임 점수 변화를 나타내는 보상을 관찰한다. 현재 화면만을 관찰하기 때문에 과제는 부분적으로 관찰되며, 많은 에뮬레이터 상태가 인지적으로 중복되다. 따라서 행동과 관찰의 시퀀스를 고려하여 게임 전략을 학습한다.
강화 학습에서 에이전트의 목표는 미래 보상을 극대화하는 방식으로 행동을 선택하여 에뮬레이터와 상호작용하는 것이다. 미래 보상은 시간 단계마다 감소하며, 최적 행동 가치 함수 𝑄*(𝑠,𝑎)는 Bellman 방정식을 따른다:
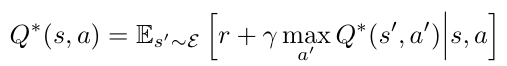
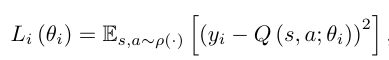
손실 함수를 확률적 경사 하강법으로 최적화하여 Q-러닝 알고리즘을 구현한다. 이 알고리즘은 모델 프리 방식으로, 에뮬레이터에서 샘플을 사용해 강화 학습 과제를 직접 해결한다. off-policy를 사용하여 상태 공간을 충분히 탐색하는 행동 분포를 따르며, a=max_a Q(s, a; θ)인 greedy 전략을 학습한다.
Related Work
강화 학습의 대표적인 성공 사례인 TD-gammon은 강화 학습과 자가 플레이로 학습하여 인간 수준을 뛰어넘는 backgammon 프로그램이다. TD-gammon은 Q-러닝과 유사한 모델 프리 강화 학습 알고리즘을 사용했으며, 다층 퍼셉트론으로 가치 함수를 근사했다. 하지만 다른 게임에 동일한 방법을 적용한 초기 시도는 성공적이지 못했다. 또한, Q-러닝과 비선형 함수 근사기를 결합하면 Q-네트워크가 발산할 수 있다는 문제로 선형 함수 근사기에 집중되었다.
최근에는 딥러닝과 강화 학습의 결합이 다시 주목받고 있으며, 비선형 함수 근사기를 사용하는 그래디언트 시차 방법으로 발산 문제를 일부 해결했다. 논문의 방식과 유사한 NFQ는 RPROP 알고리즘을 사용하여 Q-네트워크의 파라미터를 배치 업데이트로 최적화했지만, 논문에선 확률적 경사 하강 업데이트를 사용한다. Atari 2600 에뮬레이터를 강화 학습 플랫폼으로 사용한 초기 연구는 선형 함수 근사와 일반적인 시각적 특징을 적용했으며, 이후 더 많은 특징과 Tug-of-War 해싱을 사용하여 결과를 개선했다. HyperNEAT 진화 아키텍처는 각 게임에 대한 신경망 전략을 개발하여 Atari 플랫폼에 적용됐다.
Deep Reinforcement Learning

최근 컴퓨터 비전과 음성 인식의 돌파구는 매우 큰 훈련 세트에서 딥 뉴럴 네트워크를 효율적으로 훈련하는 데 기반을 두고 있으며, 원시 입력에서 직접 훈련하고 확률적 경사 하강법을 사용한 학습에서 가장 성공적이었다.
RGB 이미지에서 직접 작동하는 딥 뉴럴 네트워크에 강화 학습 알고리즘을 연결하고, 확률적 경사 업데이트를 사용해 효율적으로 훈련 데이터를 처리하는 것이 목표이다. 이를 위해 TD-Gammon과 달리 경험 재현 기법을 사용하여 에이전트의 각 시간 단계에서의 경험을 데이터 세트에 저장하고, 무작위로 추출한 경험 샘플에 Q-러닝 업데이트를 적용한다.
이 접근 방식은 데이터 효율성을 높이고 샘플 간의 상관관계를 줄여 학습 안정성을 향상시키며, 오프-정책 학습을 통해 파라미터의 진동이나 발산을 피할 수 있다. 그러나 메모리 버퍼가 중요한 전환을 구별하지 않고 균일한 샘플링을 사용하는 한계가 있다.
Preprocessing and Model Architecture
원시 Atari 프레임(210x160 픽셀, 128 색상 팔레트)은 계산적으로 부담이 되므로, 입력 차원을 줄이기 위해 전처리한다. RGB 이미지를 그레이스케일로 변환하고 110x84로 다운샘플링한 후, 84x84 영역을 잘라 최종 입력으로 사용한다. 알고리즘 1은 마지막 4개의 프레임에 이 전처리를 적용하여 Q-함수에 입력으로 제공한다.
각 행동에 대해 별도의 출력 유닛이 있는 신경망 아키텍처를 사용하여, 주어진 상태에서 모든 가능한 행동의 Q-값을 한 번의 네트워크 포워드 패스로 계산할 수 있도록 한다. 신경망의 입력은 84x84x4 이미지다. 첫 번째 은닉층은 16개의 8x8 필터로 stride 4로 컨볼루션하고, 두 번째 은닉층은 32개의 4x4 필터로 stride 2로 컨볼루션한다. 마지막 은닉층은 256개의 rectifier 유닛으로 구성된 완전 연결 층이며, 출력층은 각 유효 행동에 대해 하나의 출력을 가지는 완전 연결 선형 층이다. 이 접근 방식으로 훈련된 컨볼루션 네트워크를 Deep Q-Networks(DQN)라고 한다.
Experiments
7개 ATARI 게임에서 동일한 네트워크 아키텍처, 학습 알고리즘, 하이퍼파라미터 설정을 사용하여 실험했다. 게임별 정보를 포함하지 않고도 다양한 게임에서 작동할 수 있다. 훈련 중 보상의 규모 차이를 줄이기 위해 긍정적 보상은 1로, 부정적 보상은 -1로 고정했습니다. RMSProp 알고리즘과 미니배치 크기 32를 사용했으며, 𝜖-greedy 전략으로 처음 백만 프레임 동안 𝜖을 1에서 0.1로 감소시켰다. 총 천만 프레임 동안 훈련했으며, 최근 백만 프레임을 재생 메모리에 저장했다. 또한, 프레임 건너뛰기 기술을 사용하여 에이전트가 매 프레임이 아닌 매 k번째 프레임에서 행동을 선택하게 했다. 대부분의 게임에서 k=4를 사용했지만, Space Invaders에서는 k=3을 사용했다.
Training and Stability
지도 학습에서는 훈련 및 검증 세트에서 성능을 평가하여 모델의 진행 상황을 쉽게 추적할 수 있지만, 강화 학습에서는 훈련 중 에이전트의 진행 상황을 평가하기가 어렵다. 여러 게임에서 에피소드당 에이전트가 수집한 총 보상의 평균을 평가 지표로 사용했다. 이 지표는 매우 불안정하여 학습이 꾸준하지 않은 것처럼 보일 수 있다. 보다 안정적인 지표는 정책의 행동 가치 함수 𝑄로, 주어진 상태에서 정책을 따름으로써 얻을 수 있는 감소된 보상의 추정치를 제공한다. 훈련 시작 전에 고정된 상태 세트를 수집하고, 이 상태들에 대해 예측된 최대 𝑄의 평균을 추적한다. 예측된 평균 𝑄는 훈련 중 비교적 부드럽게 증가하며, 실험에서 발산 문제는 발생하지 않았다. 이는 논문의 방법이 강화 학습 신호와 확률적 경사 하강법을 사용하여 큰 신경망을 안정적으로 훈련할 수 있음을 나타낸다.

왼쪽 두 그래프는 훈련 중 평균 총 보상이 불안정하여 꾸준히 증가하는 것처럼 보이지 않지만 오른쪽 두 그래프는 에이전트가 얻은 평균 총 보상보다 예측된 평균 𝑄가 훨씬 더 부드럽게 증가함을 보여준다.
Visualizing the Value Function

guSeaquest 게임에서 학습된 가치 함수를 시각화한 것으로 적이 화면 왼쪽에 나타난 후(지점 A) 예측된 가치가 급상승하는 것을 보여준다. 에이전트가 적에게 어뢰를 발사하고, 어뢰가 적에게 맞기 직전(지점 B)에 예측된 가치가 최고조이다. 마지막으로, 적이 사라진 후 가치가 대략 원래 값으로 돌아갑니다(지점 C). Figu이는 논문의 방법이 비교적 복잡한 일련의 사건들에 대해 가치 함수가 어떻게 변하는지를 학습할 수 있음을 보여준다.
Main Evaluation
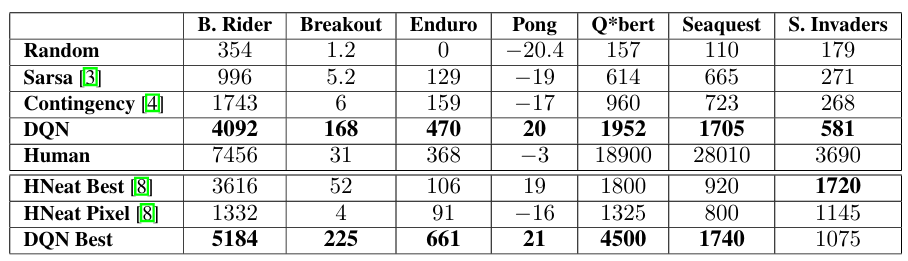
DQN 접근 방식을 Beam Rider, Breakout, Enduro, Pong, Q*bert, Seaquest, Space Invaders의 7개 ATARI 게임에서 테스트했다. 모든 게임에서 동일한 네트워크 아키텍처와 하이퍼파라미터 설정을 사용했다. 에이전트는 사전 지식 없이 원시 RGB 스크린샷만 입력으로 받아 물체를 스스로 감지해야 한다.
훈련 중 보상의 크기를 1 또는 -1로 고정하여 보상 구조를 단순화했다. RMSProp 알고리즘과 𝜖-그리디 전략을 사용하여 1,000만 프레임 동안 훈련했고, 재생 메모리에 최근 100만 프레임을 저장했다. 에이전트는 매 프레임이 아닌 매 4번째 프레임에서 행동을 선택하도록 했다.
DQN 접근 방식은 7개 게임 모두에서 다른 학습 방법을 크게 능가했으며, Breakout, Enduro, Pong에서는 전문가 인간 플레이어보다 더 나은 성능을 보였다. Q*bert, Seaquest, Space Invaders에서는 더 긴 시간 규모에 걸친 전략을 요구하기 때문에 아직 인간 성능에 미치지 못했다.
Conclusion
이 논문은 강화 학습을 위한 새로운 딥 러닝 모델을 소개하고, 원시 픽셀만 입력으로 사용하여 Atari 2600 컴퓨터 게임의 어려운 제어 정책을 마스터하는 능력을 보여주었다. 또한 확률적 미니배치 업 날짜와 경험 재생 메모리를 결합하여 RL을 위한 딥 네트워크 훈련을 용이하게 하는 온라인 Q-러닝의 변형을 제시했다. 테스트된 7개의 게임 중 6개에서 아키텍처나 하이퍼파라미터를 조정하지 않고도 최신의 결과를 제공했다
