4.3 개선판 word2vec 학습
4.3.1 CBOW 모델 구현
CBOW (Continuous Bag-of-Words)
: 주변 단어들을 이용하여 중심 단어를 예측하는 모델
개선된 CBOW
: class SimpleCBOW에서 Embedding 계층과 Negative Sampling Loss 계층을 적용했음
Embedding Layer
: 입력 데이터를 처리하는 역할
- 각 단어의 인덱스를 입력으로 받아 해당 단어를 임베딩 벡터로 변환
- 해당 단어의 의미를 담고 있으며, 모델의 학습 과정에서 최적화됨
Negative Sampling Loss 계층
: Word2Vec에서 사용되는 손실 함수
- 모델이 주변 단어를 예측하는 데 사용되는 중심 단어와 함께, 무작위로 선택된 단어들 중에서 실제 단어가 아닌 것으로 간주되는 Negative Samples(부정적 샘플)을 구분하여 모델의 학습을 수행함
- 모델이 단어 간의 유사도를 학습하고, 새로운 단어가 주어졌을 때 해당 단어와 가장 유사한 단어를 예측할 수 있도록 함
- 기존의 Softmax Cross-Entropy Loss보다 계산 속도가 빠름
- 데이터 셋이 큰 경우에도 학습이 가능함
- 구현 방법
1. 중심 단어와 주변 단어의 임베딩 벡터를 내적하여 점수를 계산한다.- Negative Samples에서 선택한 단어들과 중심 단어의 임베딩 벡터를 내적하여 점수를 계산한다.
- 중심 단어와 실제 주변 단어 사이의 점수가 Negative Samples와의 점수보다 높아지도록 모델을 학습한다. (Binary Cross-Entropy Loss를 사용하여 손실 함수를 정의함)
# coding: utf-8
import sys
sys.path.append('..')
from common.np import * # import numpy as np
from common.layers import Embedding
from ch04.negative_sampling_layer import NegativeSamplingLoss
class CBOW:
def __init__(self, vocab_size, hidden_size, window_size, corpus):
V, H = vocab_size, hidden_size
######################################
# vocab_size : 어휘수
# hidden_size : 은닉층의 뉴런수
# corpus : 단어 ID 목록
# window_size : 맥락의 크기
######################################
# 가중치 초기화
W_in = 0.01 * np.random.randn(V, H).astype('f')
W_out = 0.01 * np.random.randn(V, H).astype('f')
# 계층 생성
self.in_layers = []
for i in range(2 * window_size):
layer = Embedding(W_in) # Embedding 계층 사용
self.in_layers.append(layer)
self.ns_loss = NegativeSamplingLoss(W_out, corpus, power=0.75, sample_size=5) # Negative sampling loss 계층 사용
# 모든 가중치와 기울기를 배열에 모은다.
layers = self.in_layers + [self.ns_loss]
self.params, self.grads = [], []
for layer in layers:
self.params += layer.params
self.grads += layer.grads
# 인스턴스 변수에 단어의 분산 표현을 저장한다.
self.word_vecs = W_in
def forward(self, contexts, target):
h = 0
for i, layer in enumerate(self.in_layers):
h += layer.forward(contexts[:, i])
h *= 1 / len(self.in_layers)
loss = self.ns_loss.forward(h, target)
return loss
def backward(self, dout=1):
dout = self.ns_loss.backward(dout)
dout *= 1 / len(self.in_layers)
for layer in self.in_layers:
layer.backward(dout)
return None4.3.2 CBOW 모델 학습 코드
pytorch를 이용하여 신경망 학습을 수행하는 코드
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
# CBOW
class CBOW(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(CBOW, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.linear1 = nn.Linear(embedding_dim, hidden_dim)
self.linear2 = nn.Linear(hidden_dim, vocab_size)
def forward(self, inputs):
embedded = self.embedding(inputs)
embedded_sum = torch.sum(embedded, dim=0)
out = self.linear1(embedded_sum)
out = self.linear2(out)
log_probs = nn.functional.log_softmax(out, dim=0)
return log_probs
# NegativeSamplingLoss
class NegativeSamplingLoss(nn.Module):
def __init__(self, num_embeddings, embedding_dim, negative_samples=5):
super(NegativeSamplingLoss, self).__init__()
self.negative_samples = negative_samples
self.embedding_dim = embedding_dim
self.embeddings = nn.Embedding(num_embeddings, embedding_dim)
self.log_sigmoid = nn.LogSigmoid()
self.reset_parameters()
def reset_parameters(self):
self.embeddings.weight.data.normal_(0, 1/self.embedding_dim**0.5)
def forward(self, input_vectors, target_vectors):
batch_size, vector_size = input_vectors.shape
negative_samples = torch.tensor(
np.random.choice(
len(self.embeddings.weight),
size=(batch_size, self.negative_samples),
replace=True
),
dtype=torch.long
)
if target_vectors.is_cuda:
negative_samples = negative_samples.cuda()
input_embeddings = self.embeddings(input_vectors)
target_embeddings = self.embeddings(target_vectors)
negative_embeddings = self.embeddings(negative_samples)
input_vectors = input_embeddings.unsqueeze(2)
target_vectors = target_embeddings.unsqueeze(2)
negative_vectors = negative_embeddings.neg().unsqueeze(1)
positive_loss = self.log_sigmoid(target_vectors.bmm(input_vectors).squeeze()).mean()
negative_loss = self.log_sigmoid(negative_vectors.bmm(input_vectors).squeeze()).mean()
loss = -(positive_loss + negative_loss)
return loss
# 학습 데이터, 하이퍼파라미터 정의
train_data = [("The cat sat on the mat".split(), ["cat", "sat", "on", "the"])]
word_to_ix = {}
for sent, _ in train_data:
for word in sent:
if word not in word_to_ix:
word_to_ix[word] = len(word_to_ix)
window_size = 2
embedding_size = 10
hidden_size = 100
negative_samples = 5
batch_size = 1
max_epoch = 10
# 모델, 손실 함수, 최적화 함수 정의
model = CBOW(len(word_to_ix), embedding_size, hidden_size)
loss_function = NegativeSamplingLoss(len(word_to_ix), embedding_size, negative_samples)
optimizer = optim.SGD(model.parameters(), lr=0.001)
# 학습
for epoch in range(max_epoch):
total_loss = 0
for context, target in train_data:
context_idxs = [word_to_ix[w] for w in context]
target_var = torch.tensor([word_to_ix[target[i]] for i in range(len(target))], dtype=torch.long).view(-1, 1)
for i in range(window_size, len(target)-window_size):
model.zero_grad()
context_var = torch.tensor(context_idxs[i-window_size:i+window_size+1], dtype=torch.long)
log_probs = model(context_var)
loss = loss_function(log_probs, target_var)
loss.backward()
optimizer.step()
total_loss += loss.item()
print("Epoch %d, average loss %.2f" % (epoch, total_loss / len(train_data)))대용량 데이터셋(ex. PTB) 학습 시 가중치를 꺼내 나중에 이용할 수 있도록 pkl 파일로 저장한다!
4.3.3 CBOW 모델 평가
단어 유추(word analogy)나 단어 유사도(word similarity) 평가를 사용한다.
- 모델이 학습한 임베딩 벡터를 numpy 배열로 추출한다.
# 모델 학습 후 평가를 위해 임베딩 벡터 추출
embedding_weights = model.embedding.weight.detach().numpy()- 추출한 임베딩 벡터를 이용하여 단어 유추나 단어 유사도를 평가한다.
단어 유사도 평가
- dog이 puppy보다 cat과 더 유사하다는 것을 예측하는 문제
from sklearn.metrics.pairwise import cosine_similarity
# 두 단어 간 코사인 유사도 계산
def word_similarity(word1, word2, embedding_weights):
emb1 = embedding_weights[word_to_ix[word1]]
emb2 = embedding_weights[word_to_ix[word2]]
sim = cosine_similarity([emb1], [emb2])[0][0]
return sim
# 유사도 평가 데이터셋
similarity_dataset = [
("dog", "puppy", "cat", "kitten"),
("dog", "puppy", "car", "engine"),
("blue", "color", "book", "page"),
("blue", "color", "car", "vehicle"),
("tree", "forest", "house", "city"),
("tree", "forest", "bird", "sky"),
("man", "woman", "king", "queen"),
("man", "woman", "brother", "sister"),
("man", "woman", "dad", "mom")
]
total_sim_score = 0.0
for word1, word2, word3, word4 in similarity_dataset:
sim_score = word_similarity(word2, word1, embedding_weights) - word_similarity(word4, word3, embedding_weights)
total_sim_score += sim_score
# 평균 유사도 점수 출력
print("Average similarity score: %.4f" % (total_sim_score / len(similarity_dataset)))거리가 가장 가까운 단어들 추출
단어 유추 평가
import torch
import numpy as np
def evaluate_word_analogy(model, word_pairs, word_to_idx, idx_to_word, k=3):
##################################
model : CBOW
word_pairs : 유추 문제를 생성하기 위한 단어 쌍 리스트
word_to_idx, idx_to_word : 단어와 인덱스간 매핑을 나타내는 딕셔너리
k : 유사한 단어 개수 설정
##################################
correct = 0
for word_pair in word_pairs:
a, b, c, d = word_pair
a_idx = word_to_idx.get(a, None)
b_idx = word_to_idx.get(b, None)
c_idx = word_to_idx.get(c, None)
d_idx = word_to_idx.get(d, None)
if None in [a_idx, b_idx, c_idx, d_idx]:
continue
a_vec = model.embeddings(torch.tensor([a_idx], dtype=torch.long)).squeeze(0)
b_vec = model.embeddings(torch.tensor([b_idx], dtype=torch.long)).squeeze(0)
c_vec = model.embeddings(torch.tensor([c_idx], dtype=torch.long)).squeeze(0)
d_vec = model.embeddings(torch.tensor([d_idx], dtype=torch.long)).squeeze(0)
query_vec = b_vec - a_vec + c_vec
scores = torch.mm(model.embeddings.weight, query_vec.unsqueeze(1)).squeeze(1)
_, indices = torch.topk(scores, k=k, dim=0)
if d_idx in indices:
correct += 1
accuracy = correct / len(word_pairs)
print(f"Accuracy: {accuracy:.4f}") # 정확도 계산벡터의 덧셈, 뺄셈을 이용해 벡터 공간에서 각 단어의 관계성을 유추하여 유추 문제 해결
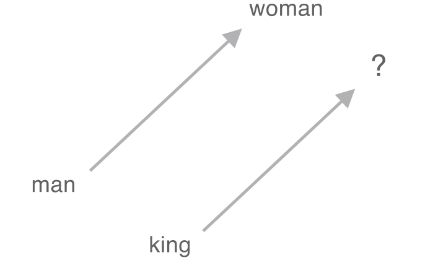
Word2vec 분산 표현을 사용하면, 단어의 의미뿐만 아니라 문법적인 패턴도 파악 가능하다. 대용량 데이터셋을 사용할수록 모델의 정확도는 점점 향상된다.
