[ASR]PASE: Learning Problem-agnostic Speech Representations from Multiple Self-supervised Tasks & PASE+
Speech (ASR/TTS)
paper: PASE, PASE +
code: https://github.com/santi-pdp/pase
Reference: https://ratsgo.github.io/speechbook/docs/neuralfe/pase
PASE
1. Introduction
- Background:
- Unsupervised learning
- Deep learning 기술 발전에 있어서 좋은 representation을 뽑는 게 굉장히 중요함. But, 제한된 데이터, 제한된 downstream task로 학습하면 bias 생기고, 한정적일 가능성 클 것이여!
- So, unlabeled data 가지고 knwledge 추출하는 unsepervised learning!
- ex) autoencoders, boltzmann machines
boltzmann machines?
- Self-supervised learning
- using outcomes as tagged labeled
- Unsupervised learning
- Challenge:
- Speech signal의 특징
- high dimensional
- long
- variable-length sequences
- complex hierarchical structure (phonemes, syllables, words, etc)
- Speech signal의 특징
- Approach:
- (1) 앙상블 뉴럴 네트워크 모델을 가지고,
- (2) 여러가지 self-supervised downstream task 문제를 해결해서,
- good speech representation을 discover하자!
- Implication:
- (1) 여러가지 task를 수행하면서 dirrerent view or soft constraint를 파악 할 수 있음. 행여 모든 task가 도움이 되진 않더라도 subset of them은 도움이 될 수 있을 것.
- (2) 여러가지 task를 수행하면서 다방면으로 도움되는 feature를 학습할 수 있을 것.
- Method -
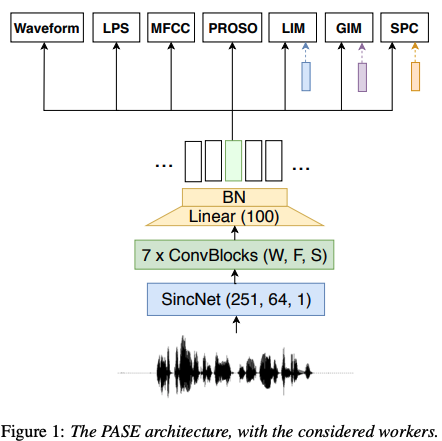
Problem-agnosticspeechencoder (PASE):- process: raw signal => encoder => worker
- 쉽게 설명해보자면, origianl signal의 특징을 잘~ 뽑을 수 있게, encoder (regressors)에서 나온 feature를 worker(descriminator)를 통해 다양한 형태의 signal로 변형을 하는 multi-task learning을 진행! 그래서 나중엔 encoder만 가지고 pre-trained 모델로 활용 가능!
- Results:
- 기존 hand-crafted features 능가 => Waveform에서 바로 유의미한 representation 추출 가능
- 학습할 때 clean한 데이터로 했음에도 불구하고, noisy한 데이터 들어와도 잘하더라!
- Contribution:
- parallelizable
- universal speech feature extractor 첫 시도
- pre-trained 모델로 사용 가능
- code 제공
2. Problem-agnostic Speech Encoder
2.1 Encoder
매우 Simple! input (waveform) 받아서 SincNet -> 7개 Conv layer -> Batch Normalization 끝!
-
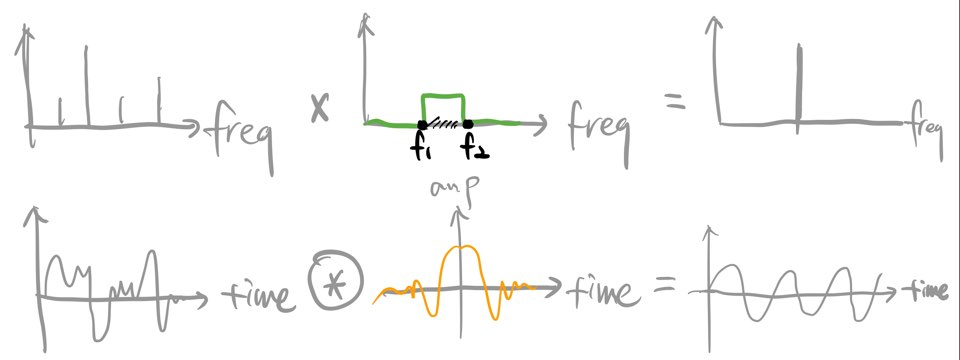
(1) SincNet : rectangular band-pass filters 사용하는 sinc function 적용해서 waveform을 convolution함
- 효과: f1, f2 값만 parameter로 두어서 계산 훨씬 줄임
- setting: kernel width W =251, filter F=64, Stride S=1
SincNet 이해 안된 부분 해결!! (ref: https://ratsgo.github.io/speechbook/docs/neuralfe/sincnet)
- 의문점: 주파수값 두개만 설정하면 된다는 게 왜 효과적인가? conv layer에서 filter가 각 element별로 곱해진다는 개념가진 알겠는데, 이게 주파수 개념에서는 filter가 어떻게 곱해진다는지가 이해가 안됐다!!!!
- 1) 사람의 음성이 여러 waveform으로 되어있다는 것을 간과

- 2) 수식에서 1과 0의 의미 파악 제대로 안했음
- 0곱해서 없애버린다는 거군? 맨끝에는 바로 0 안하고 1/2로 살려두는거구나!!! smoothing

- 0곱해서 없애버린다는 거군? 맨끝에는 바로 0 안하고 1/2로 살려두는거구나!!! smoothing
- 3) rec(t) => sin(x)/x 역변환관계 간과: 역변환으로 표현되니까 똑같이 없애버린다는 뜻이 되는거군!

- 1) 사람의 음성이 여러 waveform으로 되어있다는 것을 간과
추가: 왜 y축을 기준으로 뒤집어서 내적하는 것과 같은지?!?!
이건 convolution (뒤집는거) Vs correlation (안뒤집는거)의 차이라고 한다! 필터가 좌우대칭이면 계산 결과가 같을 순 있으나, 용도, 해석이 다를 수 있다.
ref: 설명 블로그 -
(2) 7 Convolutional blocks
- W = {20, 11, 11, 11, 11, 11, 11}
- F = {64, 128, 128, 256, 256, 512, 512}
- S = {10, 2, 1, 2, 1, 2, 2}
-
(3) Linear layer : 사이즈 맞추려고
- W = 1: 512 => 100 dim으로
-
(4) Batch normalization + PReLu activation
-
추가:
아 뭔소리지 일단 넘어가..- overlapping sliding window
- decimation: 신호처리에서 sampling rate 줄이는 행위
- featuer vector dimension N = T/160 (T samples)
- at 16kHZ에서 10ms stride랑 동일하다!
- the receptive field of the encoder = 150ms
- overlapping sliding window
2.2 Workers
7가지 self-supervised task 실시
- Regression workers
- (1) Waveform:
- input을 waveform으로 변형!
- decoder: 3 deconvolutional bocks with strides [4,4,10] => encoder representation을 160 f로 upsampling.
- MLP +256 PReLU
- Loss: L1
- (2) LogPower Spectrum (LPS): hamming window of 25ms, step size 10ms, 1025 frequency bins per time step으로 계산
- (3) MFCC: extract 20 coefficients from 40 mel filter banks
- (4) Prosody(emotion recognition 쪽에서 prosody라는 feature로 많이 사용):
- (i)interpolated logarithm of the fundamental frequency,
- (ii) vocied/unvoiced probability,
- (iii) zero-crossing rate,
- (iV)energy
- (1) Waveform:
-
Binary discrimination tasks
signal보단 abstraction을 학습할 수 있어서! (=> 오 이렇게 해석할 수 있구나)
trainig pool에서 negative, positive sampling strategy를 적용.
loss: minimizing L, positive는 가깝게, negative는 멀게
(wave2vec training 기법 느낌이구먼!)

-
(1) Local info Max (LIM):
-
goal: local 정보 학습
sample method anchor x_a random sentence 추출 positive x_p x_a와 같은 sentence에서 추출 negative x_n 다른 speaker의 random한 sentence
-
-
(2) Global info max (GIM)
-
goal: local보단 global에 집중!해서 input 시퀀스에서 high level 정보를 학습하길 희망.
sample method anchor x_a long random chunk of 1s 안에서 random utterance의 모든 PASE-encoded frame의 평균값 (모든 speaker들의 1초를 평균낸다는건가?) positive x_p x_a와 같은 sentence에서 다른 random chunk를 가져온다. negative x_n 다른 sentence에서 random chunk
-
-
(3) Sequence predicting coding (SPC)
-
goal: sequential order of the frames and the signal causality. longer time context 정보 학습할 수 있길 희망.
sample method anchor x_a single frame positive x_p randomly extracted from its 5 consecutive future frames negative x_n randomly extracted from its 5 consecutive past frames -
current-frame receptive field (150ms) 안에서는 sampling 하진 않음! x_a에서 최소 500ms 떨어져있는 곳에서 구함!
-
-
2.3 Self-supervised Training
- total loss : average of each worker cost
- weight 다 같음. total loss로 optimization함
- MSE loss
- setting
- Adam 30 epochs
- mini-batches of 32 waveform chunks
- 각각은 16k samples corresponding to 1s at a 16kHz sampling rate.
- train; 150 epochs
2.4 Usage in Supervised Classification Problems
어떻게 prtrained model로서 사용될 수 있느냐!
- encoder을 frozen해서 standard feature extractor로 사용.
- finetuning
- scratch 부터 spupervised learning 하기
3. Corpora and Tasks
- trainig data
- LibriSpeech dataset: 2484 speakers의 데이터셋에서 랜덤하게 15s 학습 데이터 골랐음
- Task
- (1) Speaker identification (Speaker-ID)
- VCTK dataset: 109 speakers with different English accents
- 더 어렵게 하기 위해서 각 speaker별로 11초 데이터만 가져옴
- (2) Speech emotion classification (Emotion)
- INTERFACE dataset: 3h for training, 40min for validation, 30min for test.
- (3) Automatic speech recognition (ASR)
- TIMIT dataset: phoneme representations
- DIRHA dataset: 더 noisy한 데이터
- WSJ-5k corpos
- DNN-HMM 모델 사용, DNN으로 encoder 학습 (context-dependent phones 예측), HMM decoder가 retrieve sequence.
- (1) Speaker identification (Speaker-ID)
4. Results
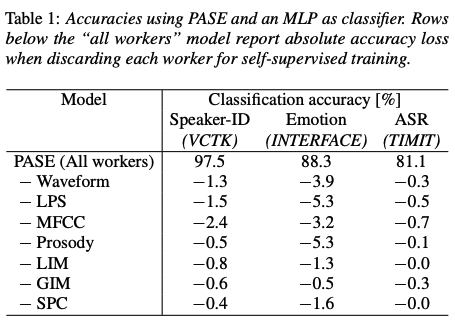
4.1 Worker Ablation
-
worker 성능 확인하기 위해서, 전체에서 worker 하나씩 없애면서 학습을 진행함. 뭐가 빠졌을 때 성능이 제일 떨어졌는지 확인 필요!
-
모든 workers 다 썼을 때 제일 좋은 성능!
-
MFCC: 전반적으로 다 좋음. low-level, prior knowledge를 잘 담았나봄
-
prosody: emotion과 관련된 feature라서 영향 큼 (intonation, voice 관련이라)
-
ASR에선 큰 영향 없는건 왜일까? decoding이 잘못된건가?!
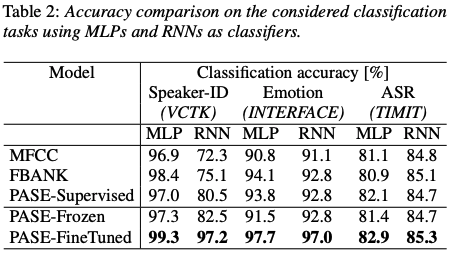
4.2 Comparison with Standard Features
왜 위에랑 같은 성능이 없지..? ????
4.3 Transferability
- noise 껴도 잘하나? DIRHA 데이터셋 자체 노이즈 심함!
- 잘함
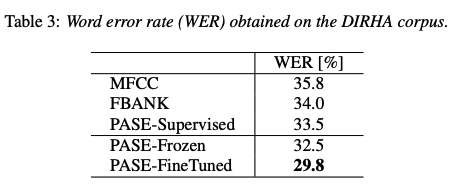
5. Coclusion
PASE +
1. Introduction
-
Goal
PASE에서 부족했던 noise and reverberation (잔향) 문제를 다뤄보겠다! => denoisingreverberation (잔향):
소리가 전파될 때 벽 같은 곳에 부딪쳐서 반사되거나 흡수되서 신호가 오기도 함.
그런데 신호마다 잔향 정도가 달라서 방해될 수 있음. 잔향이 많으면 반복되는 소리가 들리는 것 같음. -
PASE에 비해 달라진 점!
- (1) ASR task에 focus
- (2) An online speech distortion module: clean data를 일부러 왜곡
- (3) Encoder: quasi-recurrent neural network (QRNN)
- (4) Downstream Task 추가
- (5) better 성능
2. Self-supervised Learning with PASE+
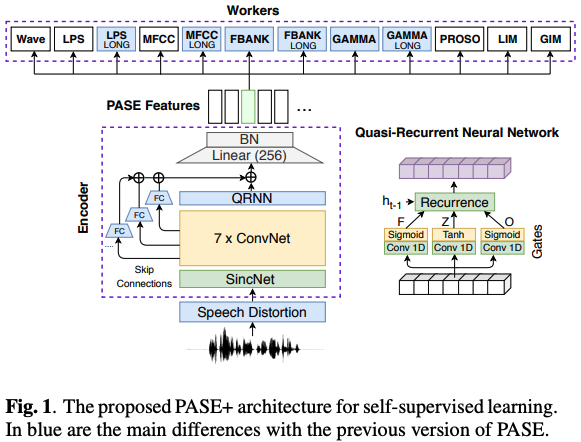
2.1 Online speech contamination
- 모든 input에 대해 p확률 만큼으로 distortion 진행
- p는 ablation study 통해서 정함

2.2 PASE+ encoder
추가된 사항
-
Skip connections
- 각 conv에서 나온 애들 sum해서 마지막에 추가로 더해줌 (transformer의 add+norm 같군)
- gradient flow를 향상시키고, 서로 다른 level에서의 abstraction representation을 확보하기 위함.
-
Quasi-RNN
- long-term dependencies 효율 높이기 위해서 마지막에 적용.
- QRNN: multiplicative gates 들이 1D conv + recurrent pooling function을 최소화함
QRNN gates는 이전 step의 영향을 받지 않고, parallel하게 계산 가능!논문을 제대로 안봐서 정확히 파악한 건 아니지만, 수식적으론 LSTM처럼 forget gate, output gate 이런거 계산하지만, 개념적으로는 약간 transfomer 구조 같다는 느낌을 받음. mask conv 통해서 미래 정보 말고 과거 정보까지만 받아서 계산하고, element wise해서 한번에 계산하고. 등등
paper (ICLR 2017): https://arxiv.org/pdf/1611.01576.pdf
- RNN의 Sequence order 처리 + CNN의 병렬작업
- result: sentiment classification task LSTM과 성능 비슷, 속도 3배 fast

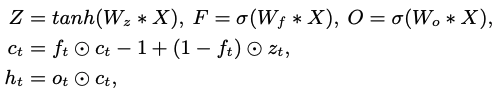 ref: https://housekdk.gitbook.io/ml/ml/nlp/qrnn
ref: https://housekdk.gitbook.io/ml/ml/nlp/qrnn
2.3 Workers
- Regression Tasks (추가된 것)
- (1) Adding more features: 40 FBANKS, 40 Gammatone
- (2) Estimating longer context: 7 neighbor frame 까지 예측하기
- (3) Estimating feature on longer windows: 200ms window로 확장
- Binary Tasks
- SPC 사라짐 (PASE에서 결과보면 효과 없었음)
4. Results
4.1 Model Ablation

4.2 Comparison with Standard Speech Features
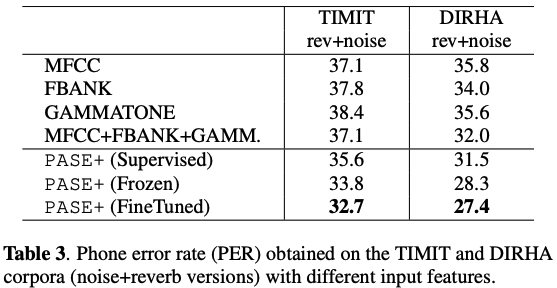
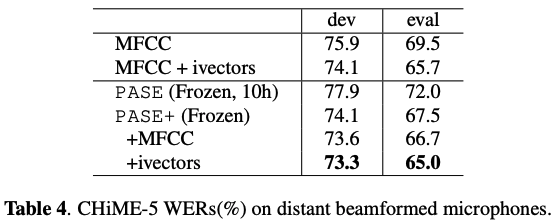
원래 나온거에 mfcc랑 ivector 더 해서 실험
Coclusion
PASE, PASE+는 self-supervised learning + multi-task down stream task 통해서 효과적인 feature extractor 구축!
What if
- Strength:
- 간단 명료 잘 썼다.
- Weakness:
- 실험이 빈약!wave2vec 이런 애들이랑은 왜 비교 실험 안했지..? wave2vec 2020이고, 얘네는 2019,2020인뎅
- PASE+에서는 workers나 distortion 기법들의 ablation study 진행을 안했다! 궁금~
study 진행하면서 modality는 다르지만 모델들이 맞닿아 있는게 보임! 역시 근본은 NLP? ㅎ_ㅎㅋㅋㅋㅋ
Code
https://github.com/santi-pdp/pase/blob/master/train.py
codebase 시각화
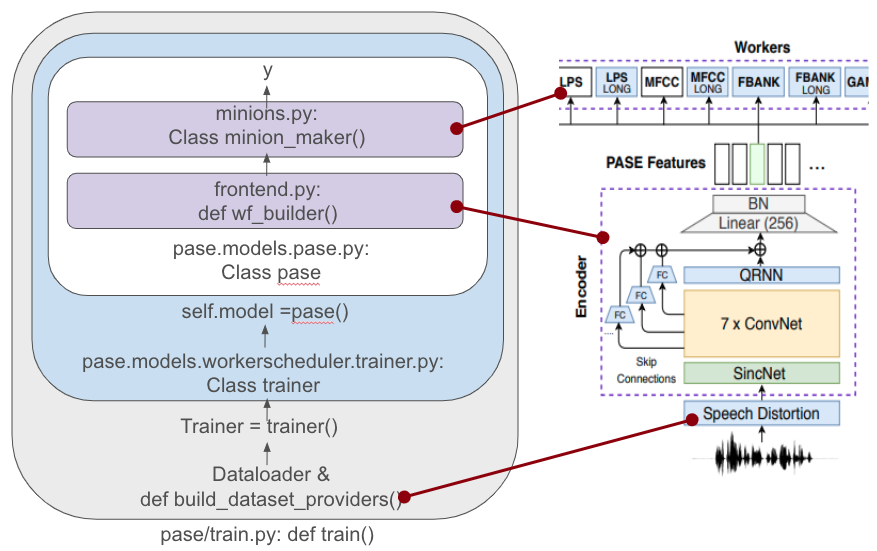
디테일
-
distortion 예시

-
encoder 예시
-
기본 conv(여러개중 하나)
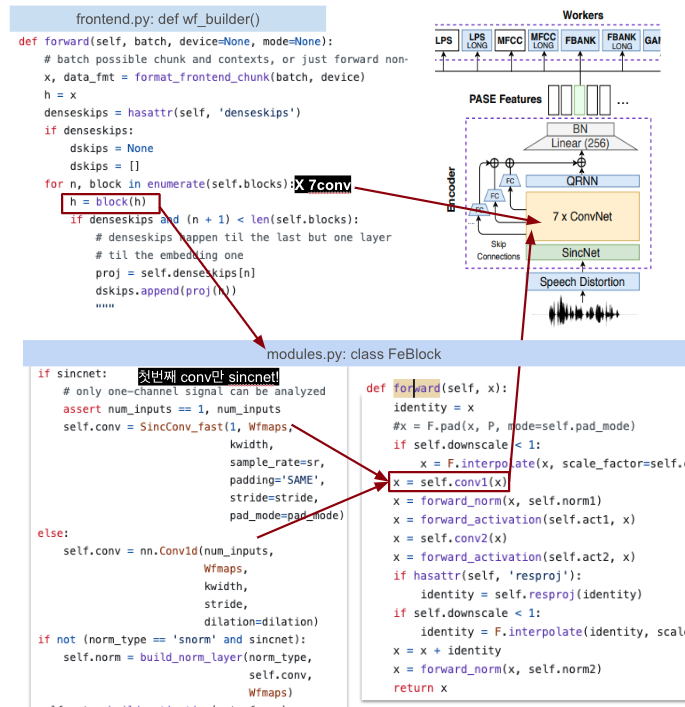
-
skip connections
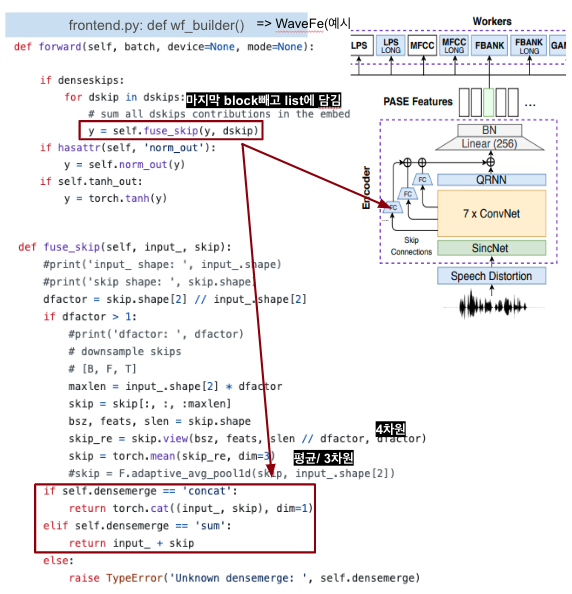
-
-
decoder 예시

-
training
class pase에서 모든 worker들 loss 다 구해다가 마지막에
worker_scheduler.py의 def backprop_scheduler()에서 다 합함!


논문을 보고 이해하지 못했던 부분들을 포스팅으로 이해하네요!! 좋은 정리 글 감사합니다