본 논문은 IEEE SLT 2018에 게재된 논문(https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8639585)이다
한줄로 요약하면,
SincNet은 음성 피처 추출에 유리한 컨볼루션 신경망(Convolutional Neural Network)의 첫번째 레이어에 싱크 함수(sinc function)를 도입해 (1) 계산 효율성과 (2) 성능 향상을 보인 모델이다.
1 Introduction
1. 화자인식 연구 동향
Speaker recognition은 많은 분야에서 응용 (생체 인증, 법의학, 보안, 음성인식, 화자 구분)되고 있음
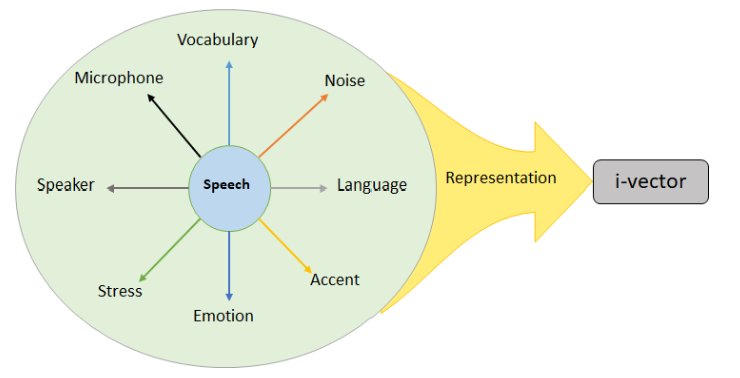
대다수의 최신 SOTA는 이전 SOTA인 GMM-UBMs (가우시안 혼합 모델-범용 백그라운드 모델)보다 더 나은 성능을 보인 음성 segment인 i-vector*에 기반을 두고 있음
딥러닝이 보인 성과들로는,
- Deep Neural Networks (DNNs)를 사용하여 i-vector frame 내에서 (1) Baum-Welch 통계를 계산하거나 (2) frame-level feature 추출한 연구들이 있었음.
- DNNs는 Speaker recognition 분야에서 직접적인 판별적 화자 분류 (direct discriminative)를 위해 제안되기도 하였음
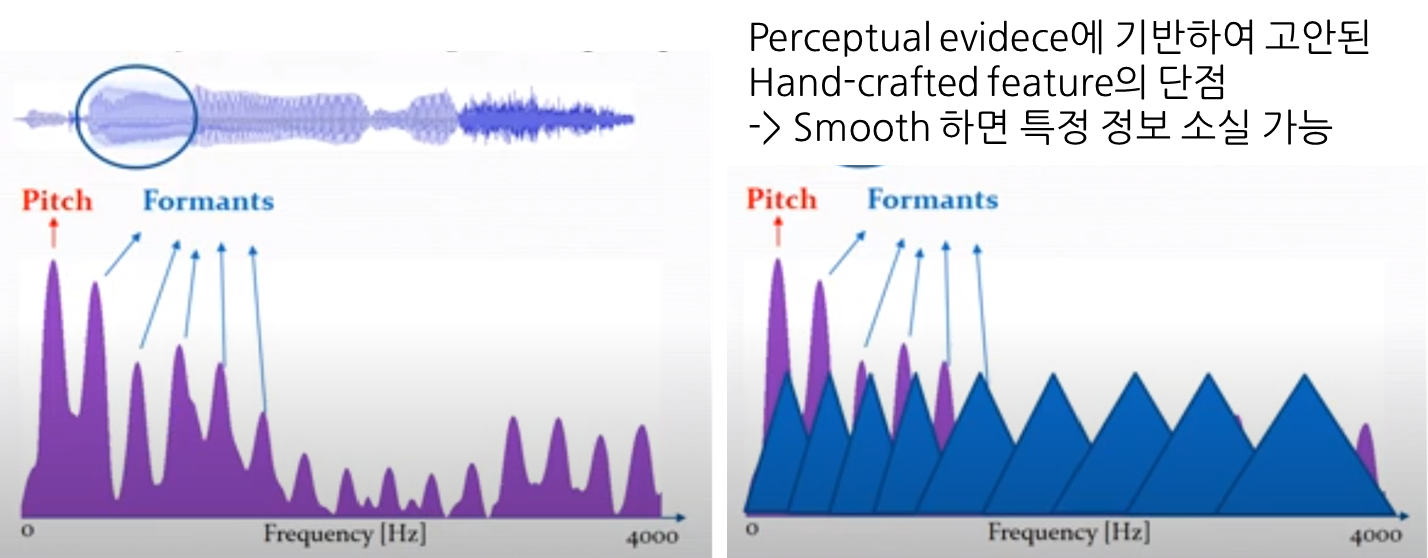
- 그러나 대다수의 방법들은 FBANK*, MFCC 계수와 같은 hand-crafted 기능을 사용
- 이런 features들은 perceptual evidence에서(hand-crafted 특성들이 인간 청각 시스템이 음성을 처리하는 방식을 모방하여) 고안되어, 이러한 특성이 모든 음성 관련 작업에 대해 최적인지 보장할 수 없다는 한계점이 있음
- 예를 들어 Standard features (e.g., FBANK, MFCC ..)들은 음성 스펙트럼을 부드럽게 만들어 음성의 전체적인 특성을 포착하려는 경향이 있음 -> 이는 중요한 narrow-band 화자 특성 (e.g., 음높이, 고조파)을 추출하는 데 방해가 될 수 있음.
- 이러한 단점을 완화하고자, 최근 연구는 네트워크에 직접 spectrogram bin 또는 raw waveforms을 제공하는 방식을 제안함. (인간청각시스템이 아닌 머신러닝 모델이 데이터를 처리하고 특성 추출하게 하자-> 효과적인 특성을 학습하자)
- 예를 들어, CNNs는 raw 음성 샘플을 처리하기 위한 효과적인 방법으로 강건한 representation 학습이 가능함
- 그러나 대다수의 방법들은 FBANK*, MFCC 계수와 같은 hand-crafted 기능을 사용
<Fig A. hand-crafted 방법이 가진 한계점>
2. 첫 번째 합성곱 층의 중요성
본 논문에서는, waveform-based CNNs에서 가장 중요한 부분 중 하나는 첫 번째 합성곱 층임을 강조함
- 첫 번째 합성곱 층은 (1) 원시 음성 waveform과 같은 높은 차원의 입력을 다루고, (2) 깊은 아키텍처를 사용할 때 발생하는 그레디언트 손실 문제에 더 영향을 많이 받는다는 특징을 가짐.
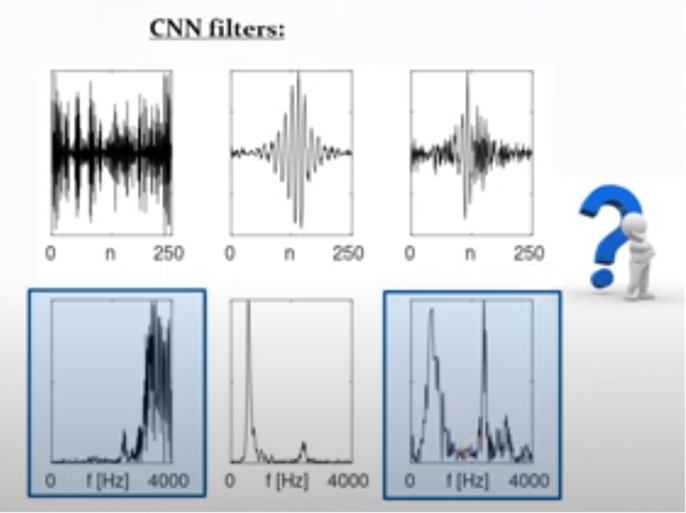
- 그러나 CNN에서 학습된 필터는-> 훈련 샘플이 적을 때 특히 noisy한 multi-band shape을 취함 (Fig B). => 이런 필터는 신경망에는 어느 정도 의미가 있지만, 음성 신호의 효율적인 표현에는 한계가 있음
<Fig B. 기존 CNN filters의 한계점>
multi-band shape는 여러 빈도 대역에서 활성화된 패턴을 뜻함 (아래 파란 상자 같은, noisy !)
CNNs의 결과물인, 파란색 표시된 결과들은 noisy하게 나온 결과물임.
3. 논문에서 제시한 SincNet (뒤 architecture에서 나옴)
CNN이 input layer에서 더 의미 있는 filter를 발견하는 데 도움을 주기 위해 SincNet은 그 filter shape에 일부를 더 추가하는 것을 제안 (= Inject prior knowledge on the filter shape)
- CNNs의 filter-bank 특성은 여러 매개변수에 따라 달라지지만 (CNNs는 필터 벡터의 각 요소가 직접 학습되는 구조로 작동)
- SincNet의 특징
- waveform을 매개변수화된 sinc 함수 집합과 함께 합성하며 이것은 band-pass filters를 구현함.
- 저주파 및 고주파 cut-off frequency는 데이터에서 학습된 필터의 유일한 매개변수임.
- 네트워크에게 결과 필터의 모양과 대역폭에 광범위한 영향을 미치는 high-level tunable(조정 가능한) 매개변수에 중점을 두도록 함
실험 결과
- training data (각 화자당 12-15초)와 short test sentences (2~ 6초까지 지속)에서 수행
- 여러 데이터셋에서의 결과는 SincNet이 CNN보다 더 빠르게 수렴하고 최종 작업 성능이 더 좋음을 입증
- 실험에서 SincNet은 i-vectors를 기반으로 한 전통적인 화자 인식 시스템보다 우수한 성능을 보임
i-vector? (참고)
- 화자 인식 때 쓰는 특징 벡터 (음성 신호 효과적으로 표현하려고)
- 음성 segment를 나타내는 고정차원의 벡터 (화자의 발음 특성을 나타낼 때 사용)
- 원리
- 화자 정보 누수를 막고자 -> speaker와 factor를 따로 모델링하자 !
- speaker, channel .. 모든 variability를 모두 하나의 subspace로 표현하는 것
- 음성 내에 있는 모든 정보를 비교적 작은 차원의 subspace (total variability subspace)에 표현하면 화자와 상관없는 정보 (예. channel)이 혼재할 수 있지만 speaker-dependent informantion도 보존되게 될 것이다
- 그래서 -> i-vector는 total variability 모델링이라고도 불림
(그냥 결론은 얻을 수 있는 모든 정보들, 상관없는 것까지 몽땅 넣어서모델링해서, 정보 누수를 막자 ! 이거네)- 수식과 더 많은 설명을 보고 싶다면... 여기로 ! 참고
FBANK? - "음성 신호의 스펙트럼을 효과적으로 표현하는 특성 추출 방법"
Filterbank의 줄임말로, 음성 신호를 주파수 영역으로 변환하는데 사용되는 특성 추출 방법임. FBANK은 음성 신호의 주파수 성분을 대표하는 일련의 주파수 대역에 대한 에너지를 포함하는데, 이는 음성 신호의 스펙트럼을 보다 압축된 형태로 표현할 수 있다는 특징을 가짐. 이러한 특성은 음성 신호를 처리하고 분류하는 데 사용되며, 주로 음성 인식 및 화자 인식과 같은 작업에 적용됨.
2 Architecture
여기 부분은 ratsgo를 많이 참고했다.
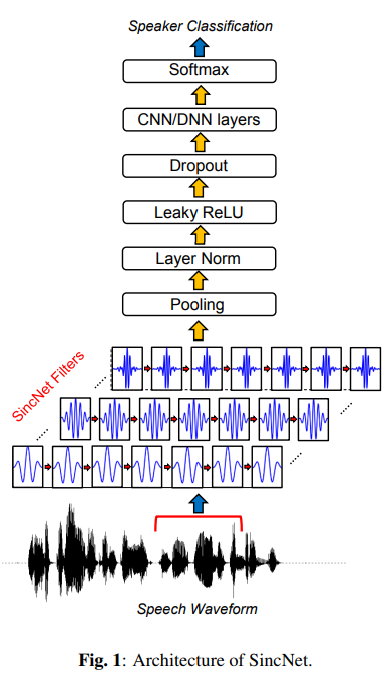
- SincNet은 음성 피처 추출에 첫번째 레이어가 가장 중요하다고 보고 해당 레이어에 싱크 함수(sinc function)로 컨볼루션 필터를 만듦
- 이들 필터들은 원래 음성(raw waveform)에서 태스크 수행에 중요한 주파수 영역대 정보를 추출해 상위 레이어로 보내고, 그 후 화자(speaker)가 누구인지 맞추는 과정에서 SincNet이 학습
2.1. 시간 도메인에서의 컨볼루션 연산
1.1 CNN이 시간 도메인에서의 컨볼루션 연산을 수행하는 방법
1.1.1 정의
필터는 시간 도메인에서의 1차원 벡터이며, 컨볼루션 연산의 정의는 다음과 같음 (1)
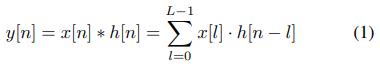
x[n] = 시간 도메인에서의 n 번째 raw wave sample
h[n] = 컨볼루션 필터(filter, 1D 벡터)의 n 번째 요소값
y[n] = 컨볼루션 수행 결과의 n 번째 값
L = 필터의 길이
=> 입력 신호 x와 필터 h를 내적하여 결과인 y를 계산하는 것을 뜻함 (1)
1.1.2 계산 방법
L = 3인 경우, 다음 계산 과정을 거침 (이 부분에 대한 자세한 내용이 ratsgo에 나와있습니다. )
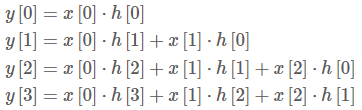
결론적으로, 컨볼루션 연산 결과물인 y 는 입력 시그널 x 와 그에 곱해진 컨볼루션 필터 h 와의 관련성이 높을 수록 커진다.
예를 들어, 만약 필터가 특정 주파수를 강조하는 역할을 한다면, 입력 신호의 해당 주파수 성분이 강조되게 된다. 따라서 컨볼루션 필터 (h)는 입력 신호의 특정 주파수 성분을 부각하거나 감쇄시키는 역할을 할 수 있다.
다시 말해, 컨볼루션 필터는 입력 신호에서 원하는 정보를 추출하거나 무시하는 데 사용되는데 이는 입력 신호의 특정 특징을 감지하고 분류하는 데 도움이 된다.
CNNs은 결론적으로, 각 필터에서 모든 elements를 학습함 (= learn all the elements of each filter)
1.2 SinCNet의 학습 방법
반대로 SincNet은 몇 개의 학습 가능한 매개변수 θ에만 의존하는 사전 정의된 함수 g를 사용하여 합성곱을 수행 (2): (= only learn the θ parameters of the predefined kernel) 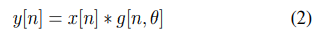
x[n] = 입력 음성 시그널(시간 도메인)의 n 번째 샘플
g = 그에 대응하는 컨볼루션 필터 값(스칼라)
y[n] = 컨볼루션 수행 결과 값
=> 이 때 g(*)를 어떻게 설정하는게 좋을까? "band-pass filter"
2.2 Bandpass Filter : Sinc Function
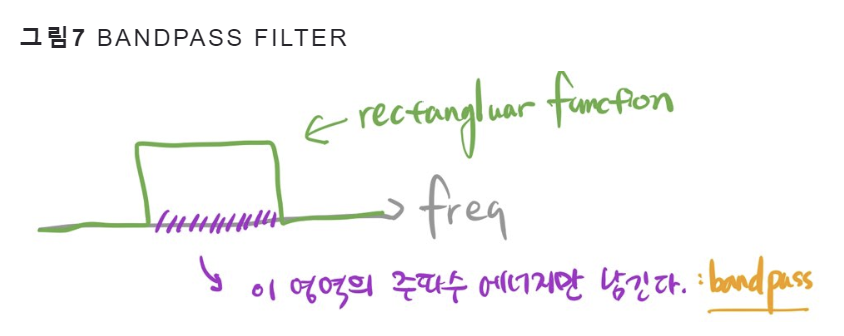
2.1 목적
음성 신호 x에서 문제 해결에 도움이 되는 주파수 영역대(band)는 살리고, 나머지 주파수 영역대는 무시하고 싶음. 이 때 특정 주파수 영역대만 남기는 역할을 하는 함수를 "bandpass filter"라 부름.
주파수 도메인에서 이런 역할을 이상적으로 할 수 있는 필터의 모양은 사각형(Rectangular) 모양임.
(이상적인 이유는 주파수 영역에서 간단하게 표현되어 필터의 동작 이해가 쉽고, 필터 계산이 간단하며 구현이 쉽기 때문임)
결론적으로, g를 정의하여 filter-bank를 사용하였으며, 이때 filter-bank는 rectangular bandpass filters 로 구성 됨
2.2 Sinc 함수
주파수(frequency) 도메인에서 bandpass filter의 크기는 일반적으로 두 개의 저주파수 필터 간의 차이 (즉 둘을 빼는 것)로 표현됨
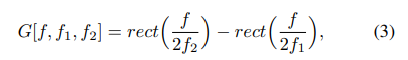
(3)에서 f1/f2는 각각 학습된 저주파/고주파 cutoff frequency*이며, rect(·)는 주파수 도메인에서의 직사각형 함수임.
헷갈리니까 다시 요약해보자
주파수 영역 = 신호를 주파수별로 분해하여 처리하는 것
일반적으로 두 개의 저주파수 필터 = 특정 주파수 대역의 신호를 통과시키는 필터
=> bandpass filter가 특정 주파수 대역을 강조하고 그 외의 주파수를 억제하는데 사용되는데, 이를 두 저주파수 필터 사이의 차이로 표현할 수 있다는 것임
cut-off frequencies?? = 차단 주파수 (참고)
- 필터 설계시 -3db가 되는 지점, 신호가 최대 gain에서 0.7배로 떨어지는 지점
- 필터에서 통과 대역과 차단 대역의 경계가 되는 주파수
2.3 주파수 도메인에서 time 도메인으로 돌아가기
역 푸리에 변환*을 사용하여 time domain으로 돌아가기 위해, reference function g는 다음과 같이 정의됨:
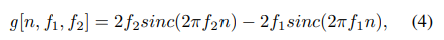
(4)에서 sinc 함수 는 sinc(x) = sin(x)/x로 정의됨.
time domain으로 돌아간다? (=주파수 도메인에서의 처리를 마치고 시간 도메인으로 돌아간다)
- 푸리에 변환 = 시간 도메인에서의 신호를 주파수 도메인으로 변환하는 과정
- 주파수 도메인에서 다루던 신호나 연산을 다시 시간 도메인으로 변환하는 것
- 주파수 도메인에서는 주파수를 기반으로 신호를 분석하고 처리하지만, 시간 도메인에서는 시간에 따른 신호의 변화를 직접적으로 살피기에 푸리에변환, 역푸리에변환을 사용해서 왔다갔다하는 것이 가능함
2.3.1 역/푸리에변환으로 돌아가는게 가능한 이유
주파수(frequency) 도메인에서 구형 함수(Rectangular function)으로 곱셈 연산을 수행한 결과는 시간(time) 도메인에서 싱크 함수로 컨볼루션 연산을 적용한 것과 동치(equivalent)이기 때문 (더 자세한 내용은 여기 ratsgo 참고!)
2.3.2 bandpass filter를 sinc 함수로 어떻게 적절히 자를까? -> Hamming window
이상적인 bandpass filter (즉, passband가 완전히 평평하고 stopband의 감쇠가 무한대인 필터)를 얻기 위해서는 무한한 수의 L이 필요
그러나 현실적으로 무한한 길이의 싱크 함수(=컨볼루션 필터)를 사용할 수 없기에 싱크 함수를 적절히 자르는 과정이 필요함
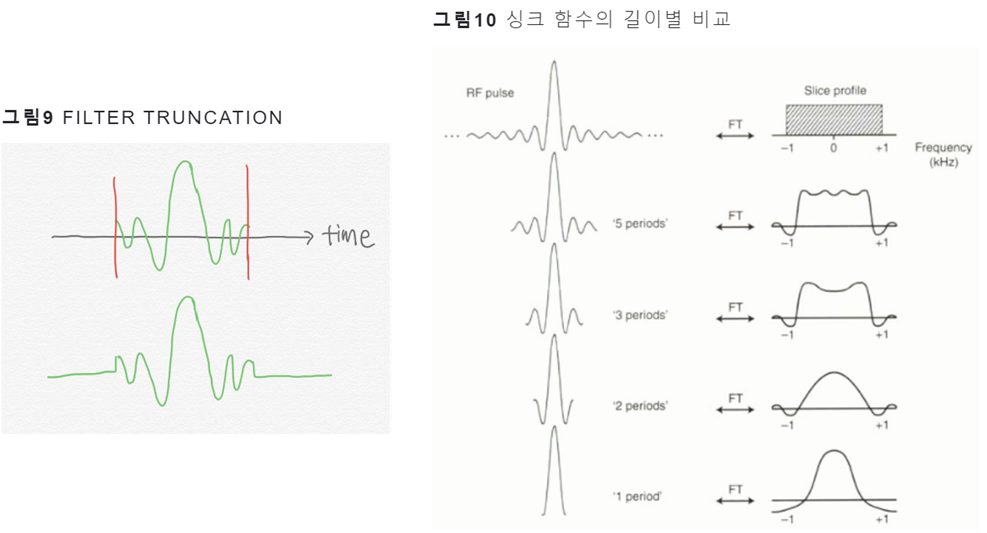
싱크 함수를 유한한 길이로 자르고 이를 푸리에 변환을 하면 그림10의 하단과 같은 모양이 됨. 이는 가장 이상적인 bandpass filter의 모양(사각형)에서 점점 멀어지는 구조로 이런 결과가 나오면 우리가 원하는 주파수 영역대 정보는 덜 포착하게 되고, 버려야 하는 주파수 영역대 정보도 일부 포착하게 됨.
이 문제를 완화하기 위해 windowing 사용, 이는 싱크 함수를 특정 길이로 자르기 보다는 해당 필터에 윈도우 함수를 사용해서 양끝을 스무딩하게 한다는 것임
본 논문에서는 고주파 selectivity를 수행하기에 적합한 'Hamming window'(8) 사용
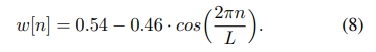 (논문에 따르면, 사실 실험 결과, Hann, Blackman Kaiser windows 같은 다른 함수를 채택할 때 유의미한 성능 차이가 없었다고 함..)
(논문에 따르면, 사실 실험 결과, Hann, Blackman Kaiser windows 같은 다른 함수를 채택할 때 유의미한 성능 차이가 없었다고 함..)
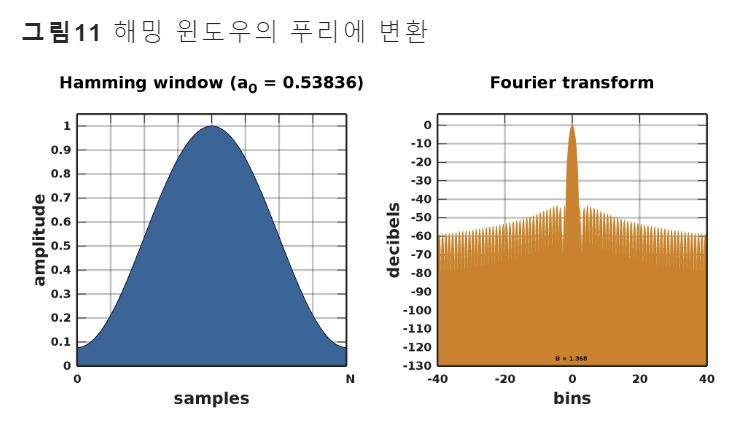
결론적으로 (그림 11)에서 볼 수 있듯이, 중심 주파수 영역대는 잘 포착하고 그 외 주파수 영역대는 무시하게 됨. 이는 유한한 길이의 싱크 함수를 사용하더라도 해밍 윈도우 기법을 사용하면 원하는 주파수 영역대 정보를 잘 살리고, 버려야 할 주파수 영역대 정보는 잘 버릴 수 있다는 것을 의미함
여기까지 SincNet 작동 방법 설명 끝 !!!! 한 번에 이제 쭉 설명을 해보겠습니다
2.3 SincNet 작동 원리
한 번에 보는 SincNet 작동 방법
SincNet은 푸리에 변환 (Fourier Transform) 없이 시간 도메인의 입력 신호를 바로 처리가 가능함 (2)
이 때 우리가 원하는 컨볼루션 필터 g(시간 도메인)의 이상적인 형태는 주파수 도메인에서 구형 함수(rectangular) 형태로 나타나야함
(3) 처럼 이상적인 Band Filter를 위해 특정 주파수 영역대( f/2f1 에서 f/2f2 사이)만 남기고 나머지 주파수 영역대는 무시해야 함
(논문에서 f가 무엇인지 얘기하지 않는데 ratsgo에 따르면 sample rate로 추정됨)
그 후 (3)을 주파수 도메인에서 시간 도메인으로 역푸리에변환을 통해 옮기면, (4)가 됨
=> 이 때, (4)에 정의된 싱크함수들을 SincNet의 첫번째 컨볼루션 레이어에 적용하는 것임
(4)에서 learnable parameter는 bandpass 범위에 해당하는 스칼라 값은 오로지 두 개로 f1, f2뿐임 (각각은 low cut-off frequency와 high cut-off frequency라 불림)
이때, f1 ≥ 0 , f2 ≥ f1을 보장하고자 저자들은 다음 제약을 둠 (컷오프수 주파수에 대한 제약) 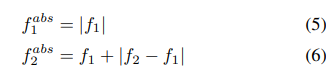
또한 유한한 길이의 싱크 함수를 써서 이상적인 bandpass filter 역할을 수행하지 못하는 문제점과 관련해 이를 극복하고자 해밍 윈도우(7)를 싱크 함수에 적용함
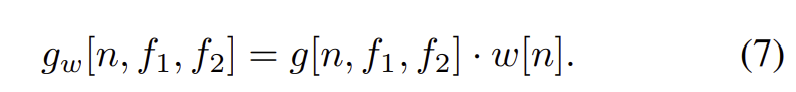
이를 통해 컨볼루션 필터의 양끝을 스무딩하게 됨
결론
- SincNet은 필터의 cutoff frequencies를 통해 다른 CNN 매개변수와 함께 최적화 가능
- Fig 1에 따르면 CNN pipeline (pooling, normalization, activations, dropout)은 첫 번째 sinc-based convolution 후에 사용 가능
- Multiple standard convolutional 또는 fully-connected layers를 스택으로 쌓아서 softmax 분류기와 함께 speaker classification를 수행 가능
2.4 Model Properties
논문에서는 4가지로 크게 나누어서 설명
1. Fast Convergence
- SincNet은 네트워크가 성능에 주요한 영향을 미치는 filter parameters에만 집중하도록 함
- 실제로 SincNet은 데이터에 적응할 수 있는 유연성을 유지하면서 필터 shape에 대한 지식을 활용 (이는 일반적으로 쓰는 feature extraction과 유사)
- 이러한 사전 지식은 filter characteristics을 학습하는 것을 훨씬 쉽게 만들어 SincNet이 더 나은 솔루션으로 빠르게 수렴하도록 도움
2. Few Parameters
- SincNet은 첫 번째 합성곱 층의 매개변수 수를 극적으로 줄임
- 예를 들어, 길이가 L인 F 개의 필터로 구성된 층을 고려한다면,
- CNN은 F × L 매개변수를 사용
- SincNet은 2F 고려
- F = 80, L = 100이라면,
- CNN에는 8천개의 매개변수가 필요, SincNet에는 160개 필요.
- 또한, 필터 길이 L을 두 배로 늘린다면, CNN은 매개변수 수를 두 배로 늘리고 (8천 개에서 16천 개로), 그러나 SincNet은 매개변수 수가 변경되지 않음 (길이 L에 관계없이 각 필터에는 매개변수가 2F로 사용).
3. Computational Efficiency
- 함수 g는 대칭적이어서 -> 필터의 한쪽만 고려하여 컨볼루션을 매우 효율적으로 수행할 수 있으며, 다른 반쪽의 결과를 상속함.
- 이로써 CNN보다 첫 번째 층 계산의 50%를 절약 가능.
4. Interpretability
첫 번째 합성곱 층에서 얻은 SincNet 특성 맵(feature map)은 다른 접근 방식보다 해석 가능하고 인간이 이해하기 쉬움. 실제로 filter bank*는 명확한 물리적 의미를 가진 매개변수에만 의존.
Filter bank?
- filter bank: 신호 처리에서 주파수 대역을 특정하기 위해 사용되는 필터들의 모음. 일반적으로 다양한 주파수 대역에서 신호의 특징을 추출하기 위해 사용.
- "물리적 의미를 가진 매개변수"란 필터 뱅크의 파라미터 중에서, 실제로 신호 처리의 물리적 특성을 나타내거나 설명하는 의미 있는 값들. 예시로 주파수 대역의 시작과 끝, 주파수 대역의 너비, 필터의 강도 등과 같은 값들이 있음. 이러한 매개변수는 특정 주파수 대역을 신호에서 강조하거나 억제하는 데 사용될 수 있으며, 이로써 필터링된 결과에 직접적인 영향을 미치게 됨
3. EXPERIMENTAL SETUP
다양한 말뭉치에서 평가되었으며 다양한 화자 인식 베이스라인과 비교함.
대부분의 실험을 Librispeech와 같은 공개 데이터를 사용하여 수행함 (깃허브)
3.1 Corpora
서로 다른 화자 수로 구성된 데이터셋에 대한 실험을 위해, 본 논문은 TIMIT(462명 화자, train chunk) 및 Librispeech(2484 명 화자) 코퍼스를 사용.
전처리
각 문장의 시작과 끝에 있는 비 음성 구간은 제거.
Librispeech 문장 중 125 ms 이상 지속되는 내부 침묵이 있는 경우 이를 여러 청크로 분할.
text-independent 화자 인식을 위해, TIMIT의 보정 문장 (즉, 모든 화자에 대해 동일한 텍스트를 발화한 문장)은 제거됨.
Librispeech의 경우, 각 화자에 대해 다섯 개의 문장이 훈련에 사용되었으며, 나머지 세 개는 테스트에 사용.
Librispeech의 경우, 훈련 및 테스트 자료는 각 화자의 훈련 자료를 12-15초 이용하고 테스트 문장은 2-6초 지속되도록 임의로 선택.
3.2 SincNet Setup
Setup 과정
- 각 speech sentence의 waveform은 200ms의 청크로 분할되어(10ms씩 겹침), SincNet에 공급됨
- 첫 번째 층은 (#Sec. 2) 길이가 L=251 샘플인 80개의 filter로 sinc-based 컨볼루션을 수행
- 그런 다음 SincNet은 길이가 5인 60개의 필터를 사용하는 두 개의 standard convolutional layer을 사용.
- layer normalization는 input samples 및 모든 convolutional layers (SincNet 입력 층 포함)에 모두 사용.
- 그 다음, 2048개의 뉴런으로 구성된 세 개의 fully-connected layers가 batch normalization로 정규화 (모든 은닉 층은 leaky-ReLU 비선형성을 사용)
- sinc-layer의 매개변수는 멜 스케일 cutoff frequencies를 사용하여 초기화되었고, 네트워크의 나머지 부분은 "Glorot" 초기화 방식으로 초기화됨
- Frame-level speaker classification은 softmax classifier로 대상 화자에 대한 후방 확률 세트를 제공
- sentence-level classification는 단순히 frame predictions을 평균화하고 average posterior을 최대화하는 화자에 대해 투표하여 얻어짐
Training 환경
학습에는 RMSprop optimizer(참고)를 사용했으며, lr = 0.001, α = 0.95, ε = 10^(-7), minibatch 128 사용
SincNet의 모든 초매개변수는 TIMIT에서 조정되었고, 이후 Librispeech에도 상속되었음.
Speaker verification system
speaker verification system은 두 가지 가능한 설정을 고려하여 speaker-id neural network에서 파생되었음.
- d-vector framework 고려: 마지막 은닉층의 출력을 기반으로 하고 test와 claimed speaker dvectors 간의 cosine distance를 계산
- 또한 대안으로, speaker verification system은 claimed identity에 해당하는 softmax posterior score 를 직접 사용 가능
(두 가지 접근 방식은 #Sec 4에서 더 다룸)
정확한 평가를 위해, 화자로부터 나온 각 문장에 대해 위조자로부터 10개의 문장이 무작위로 선택되었음. 이때 위조자는 speaker id network를 훈련하는 데 사용된 것과 다른 화자 pool에서 가져옴.
3.3 Baseline Setups
Baseline
- raw waveform을 통해 공급되는 CNN: 이들은 SincNet과 동일한 아키텍처를 기반으로 하지만 sinc-based 컨볼루션을 표준으로 대체함
- hand-crafted features: Kaldi toolkit으로 39개의 MFCC(13 static+∆+∆∆) 및 40개의 FBANK를 계산했음.
이러한 특징들은 25ms마다 계산되고 10ms의 겹침으로 형성되어 대략 200ms의 context window을 형성 (즉, 고려된 waveform-based neural network와 유사한 context)되었음.
FBANK 특징에는 CNN이 사용되었고, MFCC에는 MLP가 사용.
FBANK에는 Layer normalization가 MFCC에는 batch normalization이 사용.
Speaker verification experiment
i-vector baseline와 비교함
이때 i-vector은 SIDEKIT toolkit을 사용하여 구현.
또한 GMM-UBM, Total Variability (TV) matrix, PLDA은 Librispeech 데이터에서 훈련되었음 (GMM-UBM은 2048개의 가우시안으로 구성되고, TV 및 PLDA 고유 음성 행렬의 순위는 400)
4 Results
- SincNet과 CNN에 의해 학습된 필터를 비교.
- SincNet를 다른 경쟁 시스템과 speaker identification 및 verification tasks에서 비교.
4.1 Filter Analysis
1. Learned filters 확인
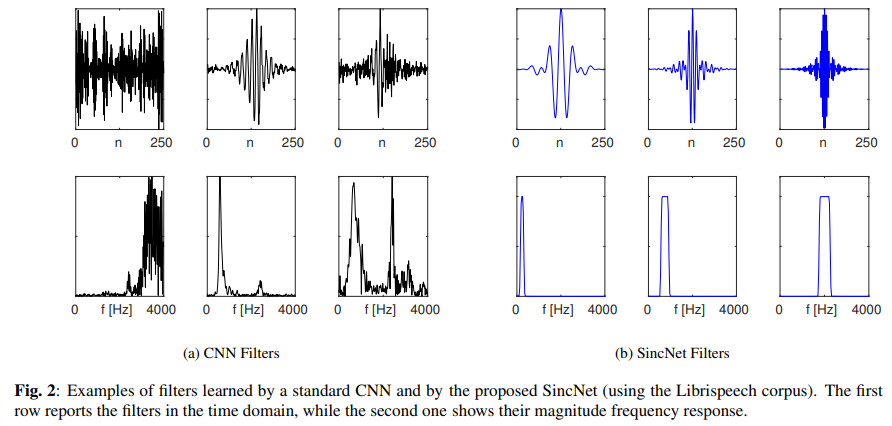
- 해당 분석은 네트워크가 실제로 무엇을 학습하는지에 대한 통찰력 제공하는데 도움이 됨
- Fig. 2는 Librispeech 데이터를 사용하여 CNN (Fig. 2a)과 SincNet (Fig. 2b)에 의해 학습된 필터의 몇 가지 예제임 (frequency response은 0~ 4 kHz 사이로 그림)
- 결과 해석
- CNN (Fig. 2a)은 항상 well-defined frequency response을 가진 필터를 학습하지는 않음.
- 경우에 따라 frequency response이 잡음처럼 보이기도 함 (Fig 2a의 첫 번째 필터),
- 다른 경우에는 다중 밴드 모양이 나옴 (Fig 2a의 세 번째 필터).
- SincNet (Fig. 2b)은 직사각형 밴드패스 필터를 구현하기 위해 특별히 설계되었기에, 더 의미 있는 결과 나옴
- CNN (Fig. 2a)은 항상 well-defined frequency response을 가진 필터를 학습하지는 않음.
2. 학습된 필터가 어떤 주파수 대역( frequency bands)을 다루고 있는가
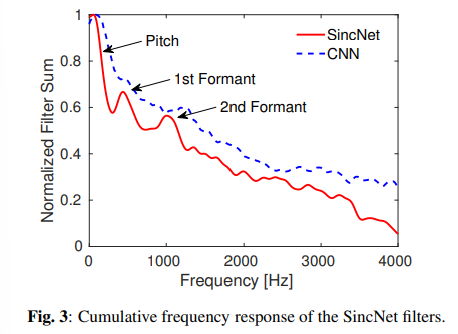
- Fig. 3은 SincNet과 CNN이 학습한 필터의 cumulative frequency response임.
- 결과
- SincNet에서 세 개의 주요 피크가 발견됨
- 첫 번째 피크는 음높이 영역에 해당 (남성의 평균 음높이는 133 Hz이고, 여성의 경우 234 Hz).
- 두 번째 피크 (약 500 Hz에 위치)는 주로 첫 번째 고조파를 캡처하며, 다양한 영어 모음에 대한 평균 값이 실제로 500 Hz임.
- 마지막으로, 세 번째 피크(900~1400 Hz 범위)는 /a/ 모음의 두 번째 고주파와 같은 중요한 두 번째 formant를 포착함
- 이런 filter-bank 구성은 SincNet이 speaker identification을 해결하기 위해 특성을 성공적으로 적응시켰음을 나타냄
- CNN은 그러한 의미 있는 패턴이 X
- CNN 필터는 주로 스펙트럼의 하위 부분에 집중하지만, 첫 번째 및 두 번째 formant에 맞는 피크가 명확하게 없음.
- Fig. 3에서 관찰할 수 있듯이, CNN 곡선은 SincNet 곡선 위에 위치.
- 실제로 SincNet은 평균적으로 CNN보다 더 선택적인 필터를 학습하며, 좁은 대역 (narrow-band) 화자 단서를 더 잘 포착 가능.
- SincNet에서 세 개의 주요 피크가 발견됨
4.2. Speaker Identification
1. SincNet과 CNN의 학습 곡선 비교
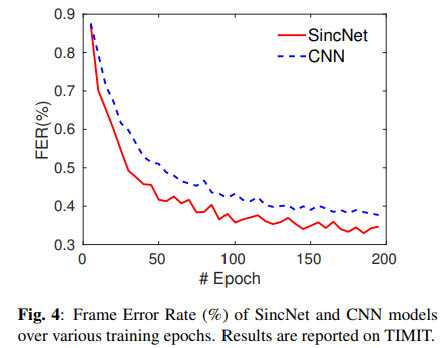
TIMIT 데이터셋에서 얻은 결과로, SincNet을 사용할 때 Frame Error Rate(FER%)이 빠르게 감소함
또한, SincNet은 더 나은 성능으로 수렴하여 CNN의 37.7%에 비해 33.0%의 FER을 달성함.
2. Sentence Error Rates (SER%) 결과
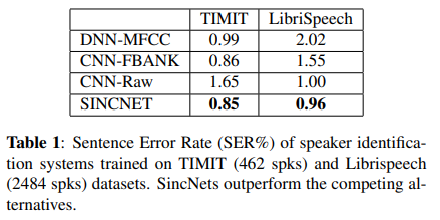
- 결과
- SincNet이 두 데이터셋에서 다른 시스템을 능가
- CNN-Raw(1.65)과 비교했을 때 SincNet(0.85)의 차이는 특히 TIMIT에서 큼
- 이는 SincNet이 적은 학습 데이터에서 효과적임을 나타냄
- LibriSpeech를 사용할 때 이 차이는 상대적으로 줄어들지만, SincNet이 여전히 더 빠른 수렴한다는 특징.
- CNN-FBANK는 TIMIT(0.86)에서 SincNet(0.85)과 비슷한 결과이지만, Librispech를 사용할 때 SincNet보다 성능 저조.
음성인식 모델의 디코딩 결과 평가하기
- SER은 전체 문장 갯수 가운데 ‘단어 하나라도 틀린 문장 갯수’의 비율을 나타내는 지표 (값이 작을 수록 성능 우수) (ratsgo 참고)
- EER: 오인식률(FAR, False Acceptance Rate)과 오거부율(FRR, False Rejection Rate)이 같아지는 비율 (값이 작을 수록 성능 우수) (tistory 참고)
- FER: 무선 데이터 전송 품질을 측정하는 데 사용되는 용어 blog

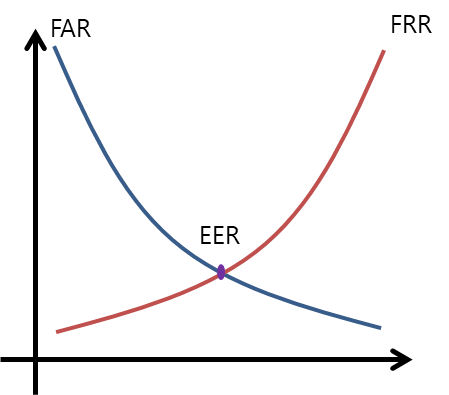
4.3. Speaker Verification
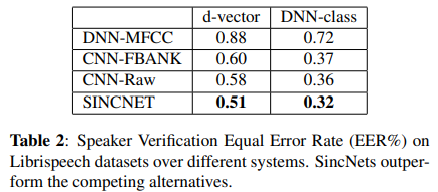
1. Librispeech에서 Equal Error Rate (EER%)
- 결과
- 모든 DNN 모델이 유수한 성능을 보여, 모든 경우에 EER이 1% 미만임.
- SincNet이 다른 모델보다 우수한 성능을 보이며, CNN 모델 대비 약 11%의 상대적인 성능 향상.
- DNN-class 모델은 d-벡터보다 훨씬 더 나은 성능을 보임.
- 나중의 접근법의 효과적인 부분에도 불구하고, 새로운 화자가 풀에 추가될 때마다 새로운 DNN 모델을 학습(또는 세밀 조정)해야 함.
- 이로써 이 접근법은 성능은 더 우수하지만, d-벡터보다는 덜 유연함.
2. standard i-vector에서의 실험
- 가장 우수한 i-vector가 EER=1.1%를 달성
- 보다 많은 학습 자료가 각 화자에 대해 사용되고, 보다 긴 테스트 문장이 사용될 때 i-vector가 우수한 성능을 제공한다고 알려져 있음.
- 이 작업에서 마주한 도전적인 조건에서는 신경망이 더 나은 일반화를 달성합니다.
Code Review
깃허브를 공부하고 싶었지만.. latsgo님의 도움을 받아 코드를 정리해봤다 (이건.. 내 깃허브에 올린다)
SincNet을 공부하고 느낀 후기
다음 Reference가 없었다면 너무 슬펐을 것 같다.
유튜브에 저자의 영상이 있으며, ratsgo에서 더 친절하게 SincNet을 설명해주고 있다 ! (그래도 어렵다)
음성은 정말 어렵다, SincNet이 학습하는 필터에서 피크가 발견되었다고 얘기하는 부분 (Fig3)이 있었는데, peak라고 할 수 있나.. 라는 생각이 문득 들었지만, 그래도 잘 작성된 아주 유명한 논문인게 틀림없다
이런 생각을 해낸 저자들,,, 참 대단하고도 멋있다 !
Relatd Work가 좀 더 자세했더라면 더 많이 배웠을 텐데, 사실 큰 내용이 없다 (정리는 뒤에.. 있다)
ratsgo 블로그에서는 CNN의 시간도메인에서 컨볼루션 연산 과정을 더 잘 다루고 있다, 그러나 여러 차례 읽어도 이해가 되지 않아, 그 부분에 대한 내용은 생략했다 (어쨌든 이건.. SincNet을 배우는게 목표니까 ㅎㅎ..)
| Reference
- https://www.youtube.com/watch?v=mXQBObRGUgk
- https://ratsgo.github.io/speechbook/docs/neuralfe/sincnet
etc.
그 외 본 발표를 준비하며 읽고 공부한 내용들이다.
Abstract
-
spaker rcognition에 딥러닝이 i-vecotor의 대안책이 되고 있음
-
CNN이 raw speech samples로 fed된 유망한 결과 나옴
-
standard hand-crafted features를 이용하는 것 대신에 CNN은 waveform에서 low-level의 speech representation을 학습함
- network가 중요한 narrow-band speaker 특성(pitch, formants)을 더 잘포착하도록 도움
- => 해당 목표를 성취하고자 적정한 neural network가 필요
-
본 논문은 CNN 아키텍쳐인 SinNet 제시
- 첫번째 convolutional layer가 더 의미있는 filter를 찾도록 함
- 각 필터의 모든 요소를 학습하는 기존의 CNN과 달리, low/high cutoff frequencies가 proposed method의 data에서 직접적으로 학습됨
- 이는 customized filter bank (desired application에 tuned된)를 이끌기에 매우 compact, effecient한 방법
-
실험 -> speaker identification , speaker verification task에서 수행
- 제시된 아키텍처가 더 빨리 수렴하고, raw waveforms에서 standard CNN보다 더 나은 성능 보임
Model Properties
Fast Convergence
- SincNet은 네트워크가 성능에 주요한 영향을 미치는 filter parameters에만 집중하도록 함.
- 실제로 natural inductive(귀납적인) bias를 구현하며, 데이터에 적응할 수 있는 유연성을 유지하면서 필터 shape에 대한 지식을 활용 (이 작업에 일반적으로 쓰는 feature extraction과 유사).
- 이러한 사전 지식은 filter characteristics을 학습하는 것을 훨씬 쉽게 만들어 SincNet이 더 나은 솔루션으로 빠르게 수렴하도록 도움.
Few Parameters
- SincNet은 첫 번째 합성곱 층의 매개변수 수를 극적으로 줄임.
- 예를 들어, 길이가 L인 F 개의 필터로 구성된 층을 고려한다면,
- standard CNN은 F × L 매개변수를 사용하고,
- SincNet은 2F 고려
- F = 80, L = 100이라면,
- CNN에는 8천개의 매개변수가 필요, SincNet에는 160개 필요.
- 또한, 필터 길이 L을 두 배로 늘린다면, CNN은 매개변수 수를 두 배로 늘리고 (8천 개에서 16천 개로), 그러나 SincNet은 매개변수 수가 변경되지 않음 (길이 L에 관계없이 각 필터에는 매개변수가 2F로 사용).
- optimization problem에 매개변수를 추가하지 않고도 많은 tap을 갖는 매우 selective 필터를 도출할 수 있는 가능성을 제공.
- 또한, SincNet의 간결함은 few sample 환경에서 적합
Related Work
이전 연구 동향
- low-level speech representation로 audio/speech를 CNNs로 생성하려는 연구
-
기존 동향
- 대다수 magnitude spectrogram feature 사용
- spectrogram이 기존의 hand-crafted features보다 더 많은 정보를 보존하지만, 중요한 하이퍼파라미터(duration, overlap, typology)에 대해서 careful한 tuning을 필요로 한다는 한계 있음
-
해결책 1
- 따라서 최근 방법들은, raw wavefrom을 직접적으로 학습하고자 함
- 이를 통해 feature extraction 단계를 완전 피하자!
- 이 방법은, speech에서 유망한 성능 보임 (emotion task, speaker recognition, spoofing detection, speech synthesis 등)
- 따라서 최근 방법들은, raw wavefrom을 직접적으로 학습하고자 함
-
해결책 2
- CNN 필터에 제약을 더하자 ! (SincNet과 유사한 관점으로)
- 예. specific band에서 작동하게 하기
- 이전 방법들과 달리, spectrogram feature에서만 작동하고 여전히 CNN filter의 모든 L elements를 학습함
- CNN 필터에 제약을 더하자 ! (SincNet과 유사한 관점으로)
-
본 논문과 가장 유사한 아이디어로는, spectrogram domain에서 작동하는 연구 (SincNet은 raw time domain waveform을 바로 고려)
본 연구
- CNN을 사용해서 raw wavefrom에서 time-domain audio processing을 위해 sinc filter를 사용
- speech recognition application까지 고려함 (이전 연구와 달리)
- SincNet에서 학습된 compact filter는 speaker recognition task에 적합함 (특히 realistic scenario에서)
CONCLUSIONS AND FUTURE WORK
- 직접 오디오 파형을 처리하는 신경망 구조 인 SincNet을 제안.
- 디지털 신호 처리에서 필터링이 수행되는 방식에서 영감을 받은 SincNet은 효율적인 매개변수화를 통해 filter shapes에 제약을 가함.
- SincNet은 어려운 speaker identification 및 verification tasks에서 널리 평가되었으며, 모든 고려된 코퍼스에 대한 성능 향상을 보여줌.
- SincNet 이점
- SincNet은 CNN보다 수렴 속도를 크게 향상시키고, 필터 대칭성의 활용으로 인해 계산 효율성도 높임.
- SincNet 필터의 분석 결과, 학습된 필터 뱅크가 음높이와 고조파와 같은 일부 알려진 중요한 화자 특성을 정확하게 추출하도록 조정되었음을 보여줌.
etc. related content
Finite Impulse Response (FIR) 필터
디지털 신호 처리에서 사용되는 필터 중 하나. 시스템의 응답이 유한한 시간 동안만 지속되는 경우에 사용. FIR 필터는 시간 영역에서 유한한 길이의 임펄스 응답을 가지고 있으며, 이 임펄스 응답이 시스템에 적용되는 입력 신호와 합성되어 출력을 생성합니다. FIR 필터는 시스템이 안정적이고 예측 가능하며 설계가 비교적 간단하다는 장점이 있습니다. 일반적으로 FIR 필터의 임펄스 응답은 샘플 수가 유한하기 때문에 그 시스템이 특정 시간에 대한 입력에 대한 반응이 제한되어 있습니다.
filter bank?
"filter bank"는 다양한 주파수 대역을 분리하거나 강조하는 여러 개의 필터로 구성된 그룹을 나타냄. 디지털 신호 처리에서, "filter bank"는 일련의 필터가 주파수 스펙트럼을 여러 개의 부분으로 분할하거나 특정 주파수 대역을 추출하는 데 사용됨. 이러한 "filter bank"는 일반적으로 서로 다른 주파수 대역에 대해 다른 필터를 적용하여 입력 신호를 처리합니다.
- "rectangular bandpass filters" = 직사각형 모양의 주파수 대역을 추출하는 필터로 이루어진 filter bank
- "bandpass filters" = 특정 주파수 대역의 신호를 통과시키고 다른 주파수 대역의 신호를 차단하는 필터.
- 이 필터는 일정 주파수 범위 내에서만 신호를 전달하고 다른 주파수는 차단하여 원하는 대역폭의 신호를 추출하거나 분리하는 데 사용됨. 즉, bandpass filters는 정해진 주파수 대역의 신호를 선택적으로 통과시키는 역할을 함
필터링 (참고)
- 저주파: 주파수 낮은 신호 (우리가 알아보기 쉬움)
- 고주파: 주파수 높은 신호, 예. 심박수, 호흡 수 처럼 빠르게 변하는 생체신호 (미세한 변화나 세부적인 특성)
- 예- 저주파 필터링
- 컷오프 주파수 이하의 주파수 성분만 통과시키고 그 이상은 차단해서, 신호의 저주파 성분은 보존하고 고주파 성분은 제거하는 필터링 기법 (우리가 원하는 저주파 신호는 남기고 원하지 않는 잡음은 제거 하는 것)
푸리에 변환
시간 도메인에서의 신호를 주파수 도메인으로 변환하는 과정. 이 변환은 주파수 성분들이 신호 안에 어떻게 분포하는지를 보여줌, 다양한 분야에서 사용되는데, 예를 들어 음성 처리에서는 주파수 도메인에서 필터링이나 스펙트럼 분석을 수행하는 데에 활용.



정리 엄청 디테일하게 잘 해주셨네요! 잘 보고 갑니다!