Latent Retrieval for Weakly Supervised Open Domain Question Answering
Abstract
ODQA의 최근 연구들은 유용한 데이터를 가지고 이루어지는 강력한 지도 학습이나 유용한 데이터를 찾아오는 black-box 정보 검색 시스템으로 수행되고 있다. 이들은 최선책이 아닌데, 정답을 항상 찾을 수 있는 방법이 아니기 때문이다. 그리고 QA이라는 것은 원초적으로 IR과는 다르기 때문이기도 하다. 우리는 처음에 QA의 문자열 쌍을 가지고 IR 시스템이 없이도 reader와 retriever를 연결해서 학습하는 것이 가능함을 보일 것이다. 이러한 환경설정에서는 위키피디아에서 얻을 수 있는 모든 데이터를 latent variable로 간주한다. 이러한 latent variable을 처음부터 학습하는 것은 말이 안되기 때문에, 우리는 ICT를 가지고 retriever를 학습한다. 우리는 공개된 5개의 QA 데이터셋을 가지고 평가한다. 이 데이터셋은 질문자가 이미 답을 알고 있기 때문에 기존 부터쓰인 BM25 같은 IR 시스템만으로도 충분하다. 유저가 진정으로 정답을 찾고자 할 때는 retrieval을 학습하는 것이 중요하며 이는 BM25보다 EM에서 19점 이상의 차이를 낸다.
latent variable
- 직역하면 잠재 변수이며, 쉽게 말해 데이터의 특징을 나타낼 수 있는 변수이다. 이 변수는 딥러닝에서 고차원으로 존재할 가능성이 높으며, 이런 변수들의 집합의 분포가 위키피디아 데이터의 실제 분포와 동일하도록 학습하는 것이 목적이다.
이 데이터셋은 질문자가 이미 답을 알고 있기 때문에 기존 부터쓰인 BM25 같은 IR 시스템만으로도 충분하다.
- 질문자가 정답을 알고있다는 이야기는 지문속의 정답의 위치를 알고있다는 뜻이며, 이것을 알고있다면 지문에 있는 키워드들을 질문에 사용할 가능성이 높아진다. 그래서 BM25같은 Sparse Embedding이 큰 효과를 발휘하게된다.
1 Introduction
최근 독해 시스템의 발전으로 입력이 주어지지 않는 ODQA의 장점이 드러나게되었다. 이는 우리의 현실 문제에 있어서 훨씬 실용적으로 적용할 수 있게된다.
현재의 방법은 downstream task에 fine-tuned 되지 못하더라도 굉장히 많은 데이터를 다뤄야 하는 추상화된 정보 검색 시스템이 필요하다. DrQA에 의해 집계된 강력한 지도학습 데이터가 있다면 독해 모델은 SQuAD같이 DrQA의 질문-답변-지문 쌍으로 학습할 수도 있다. IR 시스템은 정답이 존재하는 지문을 가지고 정답을 생성해내는 모델의 성능을 평가할 때 사용한다. 얕은 지도 학습에서는 TriviaQA, SearchQA, Quasar같은 이러한 IR 시스템이 항상 정답이 존재하는 지문의 노이즈를 섞는 방식을 사용하기 때문에 깊은 지도 학습의 개념이 제거된다는 것이다.
이러한 방법들은 탐색해야할 범위와 헷갈리는 개념들을 줄이기 위해 IR을 이용한다. 그러나 QA는 기본적으로 IR과는 다르다. IR은 언어적이고 의미적으로 관련이 있는 것을 찾는것이다. 반면에 질문이라는 것은 유저들이 모르는 정보를 찾고싶어 하기 때문에 애매한(=under-specified) 개념을 가지고 질문하며 이를 위해 더욱 좋은 언어 이해 능력이 필요하다. 추상화된 IR 시스템에서 데이터를 가져오는 것 대신 우리는 직접적으로 QA 데이터를 가지고 retrieve를 학습해야만 한다.
이번 연구에서 최초로 ORQA 시스템을 도입한다. ORQA는 매우 많은 자료(이하 open- word 사용)에서부터 정답이 될 수 있는 글들을 가져오도록 학습하며 QA쌍으로 학습된다. 검색 능력을 개선시키기 위한 최근의 연구들은 꽤 성과과 있었지만 고작 주제가 정해진 자료(이하 closed- word 사용)에서만 성능이 개선될 뿐이었다. 검색부터 답변까지의(=end-to-end) 학습에서 가장 어려운 것은 retriever가 open corpus를 학습함에 있어서 처음부터 학습하는 것은 불가능한 일이라는 것이다. 그래서 IR은 합리적이면서 최선이 될 수 있는 차선책에서 시작한다.
우리 연구의 핵심은 retriever를 비지도학습 방법인 ICT로 사전 학습시킴으로써 end-to-end 학습이 가능하다는 것이다. ICT는 문장은 질문이 될 수 있고 문단은 지문이 될 수 있다. 질문이 있을 때 ICT는 batch 안에 있는 후보 지문들을 제외한, 질문에 대응하는 목표 지문을 선택해야한다. ICT 사전학습은 매우 강력한 초기화를 할 수 있도록 해서 retriever와 redaer가 연결된 ORQA model이 end-to-end 방식으로 fine tune할 수 있도록 한다.
Table 1
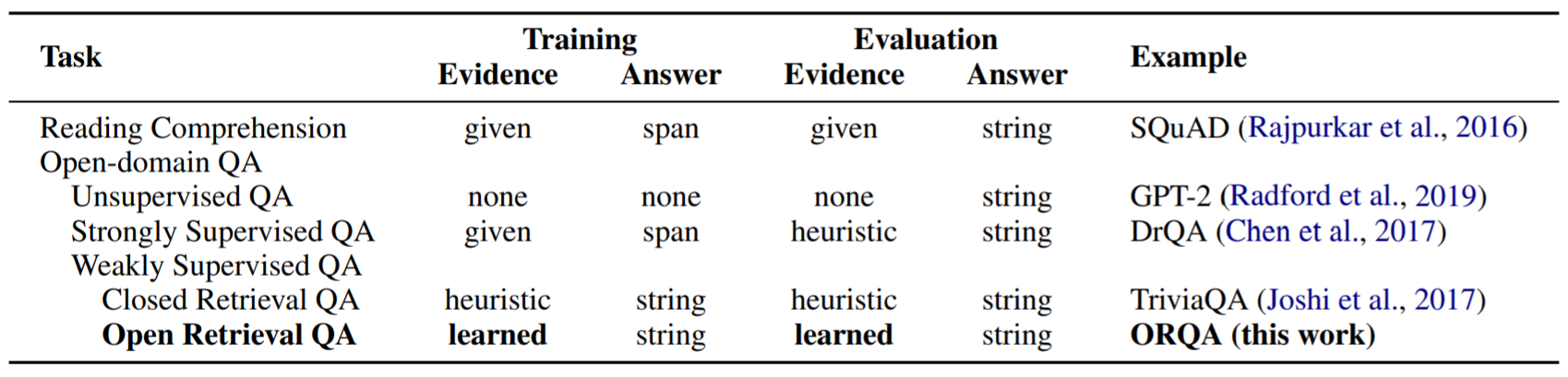
- 예제를 참고하는 방법에 따라 관련있는 tasks들로 비교한 결과이다. 휴리스틱한 지문들은 기존의 제한된 데이터셋 안에서 제한적인, 높은 성능을 IR 시스템을 가지고 관련있는 지문을 가져오는 일반적인 전략이다. ORQA에서는 QA쌍을 가지고 학습하며 목표 지문은 완전히 end-to-end 방식으로 학습된다. 이는 알고있는 정답의 주변 확률을 간단히 최적화시킴으로써 fine tune하게 된다.
이는 알고있는 정답의 주변 확률을 간단히 최적화시킴으로써 fine tune하게 된다.
- 정답의 확률은 1, 오답의 확률은 0으로 해서 최적화한다는 의미이다. 예측 정답들 중 한 정답의 확률이 매우 높으면 다른 정답들의 확률은 매우 낮아진다. 이러한 주변 확률을 이용해, 정답의 확률을 매우 높이면 오답의 확률이 매우 낮아지므로 이러한 방식으로 최적화를 진행한다.
ORQA는 5개의 QA 데이터셋을 가지고 평가된다. 질문자가 정답을 이미 알고있는 SQuAD나 TriviaQA같은 데이터셋은 IR 시스템에서 겪는 문제점을 그대로 겪게되며 BM25가 최고 성능을 내게된다. 반면, 정답을 모르는 상태로 제공된 질문 데이터셋인 NQ나 WebQ, CuratedTrec에서는 BM25보다 6~19점의 성능 차이를 내면서 학습된 retrieval이 얼마나 중요한지 보여준다.
2 Overview
이번 장에서 우리는 이전의 연구들과 작업물들을 비교하기 유용한 ODQA 개념과 우리가 제안한 모델을 소개한다.
2.1 Task
ODQA에서 input 는 질문을, output 는 answer를 의미한다. 독해와 달리 task에서 정의해주는 것이 아니라 모델이 결정해서 지문을 가져온다. 우리는 표 1에서 독해와 QA Task의 다양한 편차들을 비교했다.
평가는 DrQA에 나온 평가 방법을 그대로 따랐다. 소문자로 바꾸는 등의 최소한의 정규화를 거친 뒤 정답과 정확하게 매칭하는지를 평가했다.
2.2 Formal Definitions
많은 retrieval-based ODQA 구조의 포함되는 모델의 구성요소들의 몇가지 일반적인 정의를 소개한다.
모델은 정형화되지 않은 B개의 block으로 분리되는 text corpus의 관점으로 정의된다. 답변은 (b, s)로 유도되는데, 이 때 b는 이며 B개의 block으로 나뉠 때 각 block의 인덱스를 의미한다. 그리고 s는 b에 속해있는 text의 범위를 나타낸다. s범위 안에있는 시작과 끝 토큰의 인덱스는 각각 와 로 나타내진다.
모델은 함수 S(b, s, q)로 점수를 매기는데 이는 질문 q가 주어졌을 때 (b, s)로 유도되는 정답의 친절도를 의미한다. 일반적으로 이 평가 함수는 retrieval의 점수 와 reader의 점수 로 분리할 수 있다.
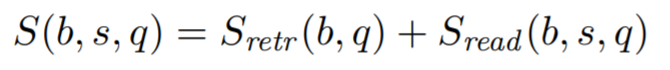
모델은 함수 S(b, s, q)로 점수를 매기는데 이는 질문 q가 주어졌을 때 (b, s)로 유도되는 정답의 친절도를 의미한다.
- 정답이 잘 유도되었다면 해당 질문에 잘 대답하므로 친절하다고 볼 수 있으며 그렇지 않을 경우 이상한 대답을 하게 되므로 불친절한 대답이라고 표현했다.
추론시에는 모델은 가장 높은 점수를 가진 정답을 반환한다.
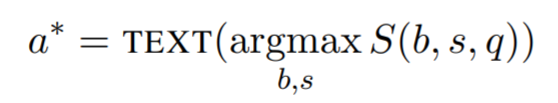
는 실제 정답과 예측 정답을 연결한다. ODQA의 주된 어려움은 OD의 넓은 범위를 모두 다룰 수 있냐는 것이다. 위키피디아 영어 말뭉치에 대한 우리의 실험에서 우리는 1.3천만개의 block을 고려했다. 이 block는 각각 2000개의 예상 정답 범위 s로 구성되어 있다.
2.3 Existing Piplined Models
현존하는 retrieval-based ODQA에서 추상화된 IR 시스템은 초기에 가까운 목표 지문을 여러개 고른다. 예를 들어 DrQA의 retriever 요소를 가지고 얻는 점수는 다음과 같이 정의된다.
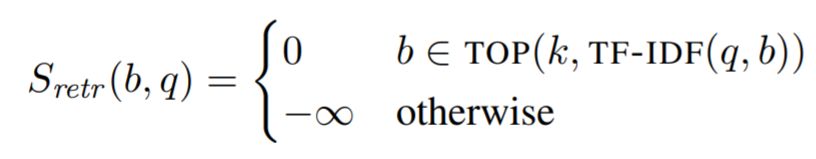
대부분의 DrQA의 방법을 따르는 연구들은 TF-IDF를 이용해 동일한 후보 지문을 사용했고 독해나 평가 방법에 대해서만 신경을 썼다. reading 점수 는 일반적으로, 지문이 주어지는 SQuAD 데이터셋을 사용해서 항상 정답이 존재하는 방법으로 학습이 되었다.
우리의 방법과 매우 밀접한 관련이 있는 연구에서는 에서는 readrer가 전체적으로 얕게 지도학습된다. retriever 시스템에 의해 가짜 모호함(=정답을 뽑기 위한 지문이 질문과 관련이 없을 때의 어려움)을 휴리스틱하게 제거하고 전처리가 된 지문을 우리의 정답 지문으로 사용하게된다.
3 Open-Retrieval Question Answering
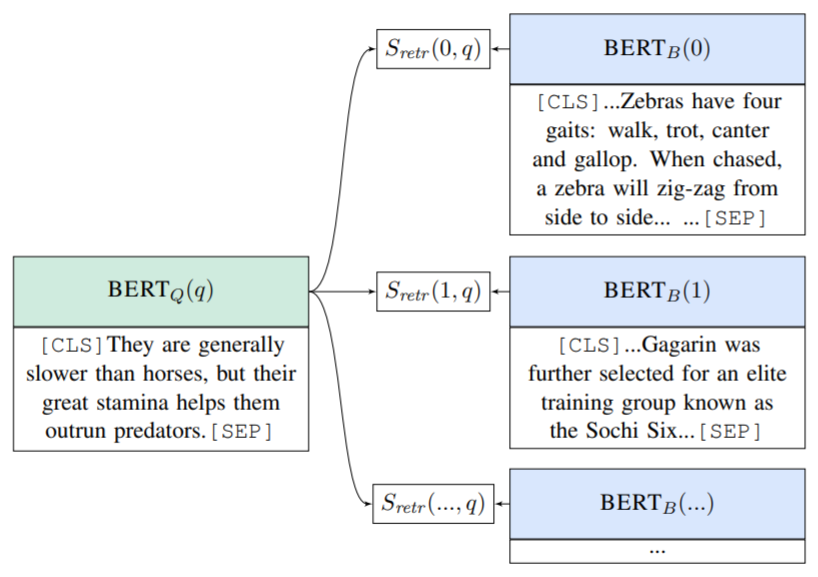
end-to-end 모델을 제안한다. 이 모델은 retriever와 reader가 연결되어 학습되고 그래서 이를 Open-Retrieval Question Answer를 줄인 ORQA 모델이라고 부르기로 한다. ORQA의 중요한 점은 이 모델의 표현력이다. black-box IR 시스템에 의해 제한된 예측 셋을 받는 것 대신, open corpus에서 어떤 텍스트든 검색할 수 있는 능력이 있다. ORQA가 예측값을 점수내는 방법은 그림 1에 그려져있다.
Figure 1
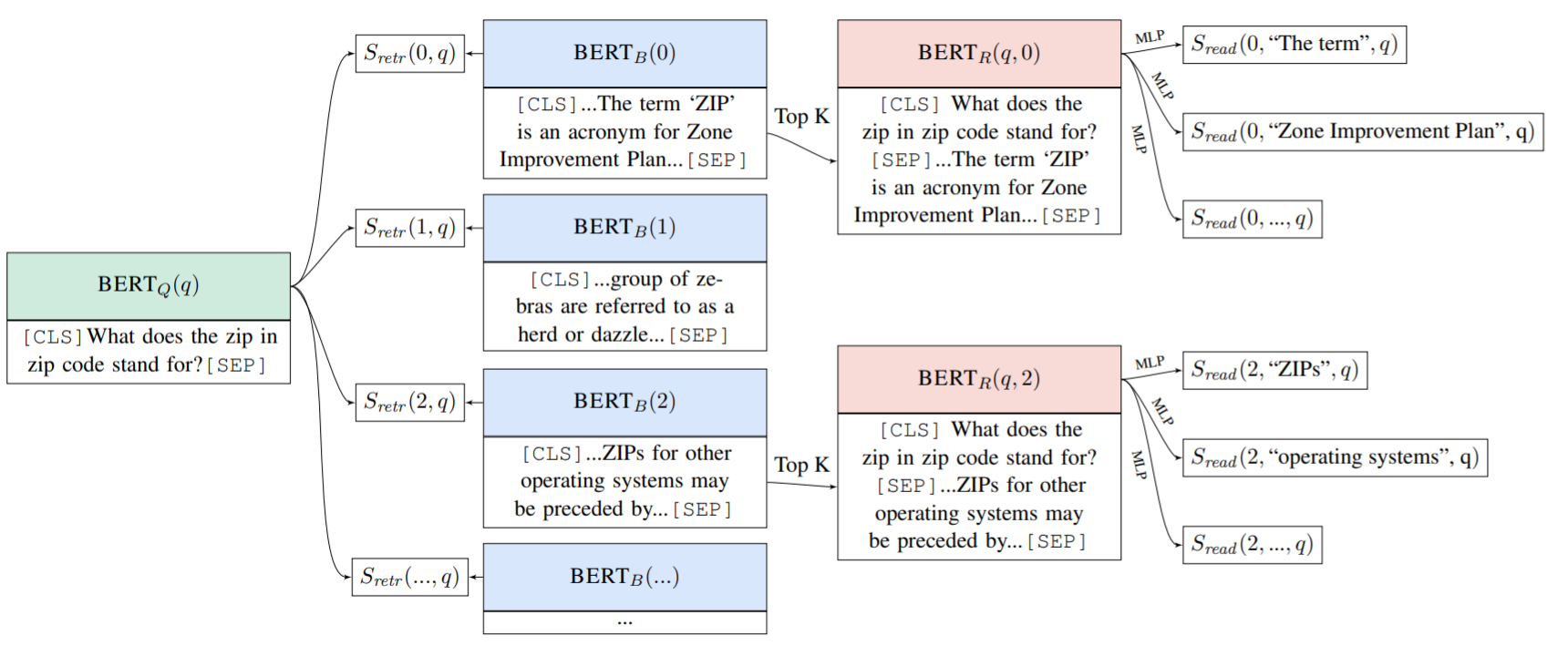
- ORQA의 개요이다. 질문 q가 주어졌을 때 가능한 모든 예측값(=answer derivations)의 부분집합이 표현된다. Retrieval 점수 는 BERT-based encoders의 결과를 내적하여 계산된다. 상위 점수의 목표 지문들은 question과 함께 연결되어 인코딩되며 해당 block의 부분 표현들이 다층 신경망을 통해 점수 가 매겨진다. 최종 연결 모델의 점수는 이다. 후보 지문들을 얻기 위해 IR 시스템을 사용하는 이전의 연구들과는 달리 우리는 위키피디아를 직접적으로 탐색하면서 학습한다.
전이 학습에서의 최근 트렌드는 모든 평가 요소를 BERT에서 얻는 것이다. 이 BERT는 양방향 트랜스포머 모델로서 비지도 학습 언어 모델 데이터로 pre trained 되었다. 우리는 reader의 구조적인 세부사항을 설정하기 위해 BERT 논문을 그대로 참고했다. 우리의 연구에서 관련있는 요소들은 다음의 함수들에서 소개한다.
버트 함수는 한 개 또는 두 개의 입력을 인자로 받고 입력 토큰이나 CLS 토큰에 해당하는 벡터를 반환받는다.
Retriever component
retriever가 학습되도록 retrieval score를 정의했으며 이는 질문 q와 지문 block b의 dense vector의 내적으로 정의된다.
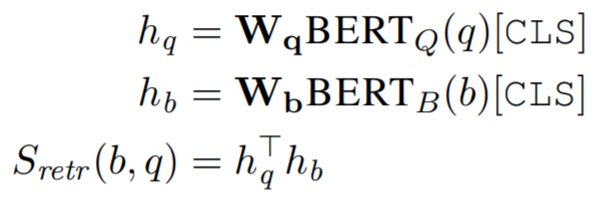
와 는 128차원의 벡터를 통해 BERT의 결과를 투영하는 파라미터이다.
Reader component
reader는 BERT에서 제안된 독해 모델을 변형한 span-based 모델이다.
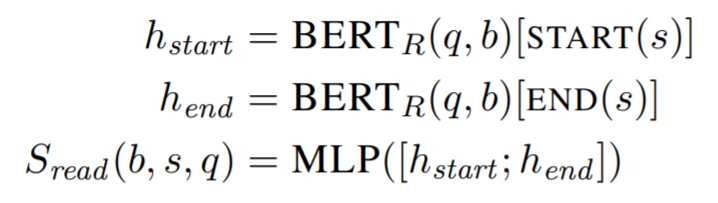
Lee et al. (2016)에서 span은 끝점들의 연결에 의해서 표현된다. 이러한 끝점은 시작점과 끝점이 상호작용할 수 있도록 다층 신경망에 의해 점수가 매겨진다.
Table 2

- 약한 지도학습의 결과물로 발생하는 spurious ambiguities의 예시이다. 좋은 evidence retrieval은 의미있는 학습 signal을 만들어낼 필요가 있다.
약한 지도학습의 결과물로 발생하는 spurious ambiguities의 예시이다. 좋은 evidence retrieval은 의미있는 학습 signal을 만들어낼 필요가 있다.
- 첫번째 예시에서 supportive evidence와 spurious ambiguity는 모두 Rene Descartes라는 단어를 포함하고 있기 때문에 좋은 evidence retrieval, 즉 Supportive Evidence는 자신과 모호한 지문을 구분할 수 있는 근거나 신호를 제공해줘야한다는 뜻이다. 이러한 signal이 없으면 구분할 수 없다는 것.
Inference & Learning Challenges
위에서 묘사되는 모델은 개념적으로는 간단하다. 그치만 추론과 학습은 매우 어려운데 그 이유는 다음과 같다. (1) open evidence corpus는 방대한 탐색 공간에서 이루어진다. (1.3천만개의 evidence block 이상) (2) 이러한 공간을 탐색할 때 corpus들은 전반적으로 잠재적이기 때문에 표준으로 사용하는 Teacher-Forcing 방법이 적용될 수 없다. 또한 잠재 변수 방법은 모호한 지문의 수가 매우 많기 때문에 일차원적으로 이를 적용하기는 쉽지 않다. 예를 들어보자, 표 2에서는 관련없는 위키피디아의 많은 지문들이 정답에 해당하는 seven을 포함하고 있다.
- 따라서, (1) 정답이 아닌 지문들에도 seven이 포함되어 있기 때문에, 단순히 example의 답으로 seven을 주는 teacher forcing이 적용되기가 어렵다는 것이다. (2) 잠재 변수가 어떠한 supoortive evidence의 분포를 표현하기에는, (분포가 잘 형성되었지만 모호한 지문이 뽑히는 반례가 많아지므로) 단순히 쉽게 적용하기는 어렵다는 것이다 (결국 이는 모양적으로는 분포가 잘 형성된 것 처럼 보이지만 결과적으로는 분포가 잘 형성되지 못했다는 것을 의미한다)
우리는 이러한 어려움을 4장에서 등장하는 비지도 사전 학습을 거친 retriever를 신중히 초기화하면서 해결해보고자 한다. 사전 학습된 retriever는 (1) 모든 evidence block을 미리 인코딩 할 수 있게해서 fine tuning시에 동적인데도 불구하고 빠른 tok-k retrieval을 가능하게 한다. (2) retrieval의 bias를 spurious ambiguities에서 supportive evidence로 조정할 수 있게한다.
4 Inverse Cloze Task
우리가 제안한 사전 학습 과정에서의 목적은 retriever가 비지도 학습 문제를 해결함에 있다. 이 문제는 QA에서 지문을 찾는것과 매우 밀접하게 비슷한 문제이다.
직관적으로 보면, 유용한 지문은 일반적으로 질문에서 언급한 개체나, 사건 그리고 관계등을 이야기하게 된다. 또 질문에서는 언급되지 않았던 답에 대한 부가 정보를 포함하기도 한다. 비지도 학습을 위한 question-evidence 쌍과 동일한 의미는 sentence-context 쌍이다. (sentence와) sentence의 context는 의미적으로 유사하며 sentence로 부터 손실된 정보를 추론할 수 있다.
Figure 2
- retrieval 사전학습에 이용되는 ICT의 예시이다. 무작위 문장(질문인척 하는)과 문장의 context(관련이 있는 context인 척 하는)가 text snippet(=단편, 한편의 글)으로 부터 주어진다. "얼룩말은 4개의 이동 패턴을 보인다 : 걷다가, 총총 걷다가, 구보 하듯이 걷다가 전속력으로 질주한다. 얼룩말은 일반적으로 말보다 느린 대신 매우 좋은 지구력이 있어서 포식자로부터 도망갈 수 있도록 한다. 쫓기게 되는 상황에서 얼룩말은 측면으로 지그재그로 움직인다..." 한 배치내에 있는 후보 지문들 중에서 관련이 있는 지문을 고르는 것이 목적이다.
이러한 직관을 따르고자, 우리는 retrieval module을 ICT로 사전학습하는 방법을 제안한다. 기본적인 Cloze task는 context에서 masking된 단어를 예측하는 데에 그 목적이 있다. ICT는 그 반대이다. (context를 주고 sentence를 예측하는 것이 아니라) sentence를 주고 context를 예측한다. 그림 2를 보자. 이러한 context를 결정할 수 있는 함수를 사용한다. 이 함수는 downstream의 retrieval에서 사용되는 것과 유사하다.
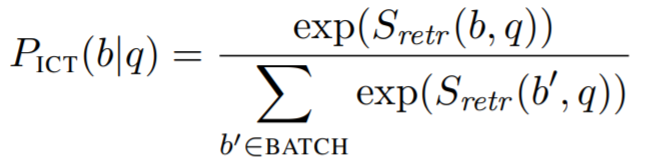
q는 질문인 척 하는 랜덤 문장이며 b는 q를 둘러싸고 있는 텍스트이다. BATCH는 한 배치내에서 evidence block들의 집합이며 negative sample로써 사용된다.
ICT의 중요한 점은 가짜 질문은 지문에는 등장하지 않기 때문에 단순한 word matching 보다 더 많은 학습을 필요로 한다는 것이다. 예를 들어 그림 2에 있는 가짜 질문은 명백히도 절대 얼룩말이라는 말을 안한다. 그렇지만 retriever는 반드시 zerbra에 대해 이야기하는 지문을 선택해와야 한다. 이러한 모호한 문장으로부터 의미를 추론할 수 있도록 하는 것이 기존의 IR과는 다른 QA의 특징이다.
그러나, retriever가 word matching을 하지 못하도록 하고 싶은 것은 절대 아니다. 어휘의 중복은 궁극적으로 retriever에게 매우 유용한 부분이다. 그러므로 우리는 데이터의 90%의 context에서 sentence를 제거함으로써 모델이 필요할 때는 추상적인 표현을 학습하면서 가능한 간단한 기술인 word matching 기법도 학습하도록 의도했다.
ICT 사전 학습은 두가지 목표를 이루어냈다.
1. 사전 학습시의 문장과 미세 조정시의 질문 사이의 환경 차이에도 불구하고 우리는 잠재 변수 학습을 발전시키기에 충분한 zero-shot evidence retrieval 성능을 기대하게된다.
2. 사전학습 때의 evidence block과 downstream의 evidence block에는 mismatch가 존재하지 않는다. 따라서, 추가적인 학습이 없더라도 block encoder 가 잘 작동한다고 예상한다.
사전 학습시의 문장과 미세 조정시의 질문 사이의 환경 차이에도 불구하고
- 사전 학습시의 질문은 문장의 일부분을 가져와서 사용한다. fine tuning시에 질문은 문장의 일부분이 아니며, 사용자가 생성한 문장이므로, 특정 context와의 연관성을 찾는 데에 있어서 더 난이도가 높을 수 있다.
zero-shot
- test때 learner가 훈련 중에 관찰되지 않은 클래스의 샘플을 훈련 중에 관찰된 샘플들의 특징을 조합해서 예측하는 것이다.
- 참고링크

이어지는 섹션에서는 inference와 ene-to-end 학습을 계산적으로 실현가능하게 할 수 있다는 점에서 이러한 두 가지 특징은 중요함을 다룰 것이다.
5 Inference
고정된 block encoder들은 retrieval을 위한 유용한 output을 제공했기 때문에 우리는 사전에 모든 block의 encoding을 계산할 수 있다. 결과적으로 방대한 양의 set of evidence blocks은 fine tuning시에 re-encoding될 필요가 없고, LSH와 같은 기존의 도구를 이용해 빠르게 최대 내적값을 찾기 위한 index로 미리 변환될 수 있다.
Locality Sensitive Hashing
미리 변환된 index를 이용하는 추론은 beam-search 작업을 거친다. 우리는 top-k evidence blocks을 찾고 이 blocks에 대해서만 reader score를 계산한다. 왜냐하면 reader score는 모든 evidence block과 reader score를 계산하기에는 비싼 연산이기 때문이다. 한번의 추론 시에는 top-k evidence block만을 고려하는 반면에, 이러한 과정은 question encoder가 QA data에 얕은 지도학습으로 fine-tuned되기 때문에 동적으로 바뀌게되며 이에 대해 6장에서 이야기 한다.
6 Learning
ICT는 중요한 zero-shot retrieval을 제공하기 때문에 학습은 상대적으로 간단하다. 우리는 answer derivations에 대한 분포를 우선 정의한다.
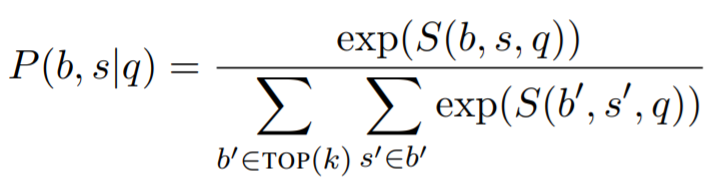
는 에서 뽑힌 상위 k개의 retrieved blocks을 의미한다. 우리는 실험에서 로 사용한다.
정답 a가 주어지면 우리는 (가능한 공간에서) 모든 예측 문장을 beam search로 찾고 이를 주변 로그 확률을 사용해 최적화한다.
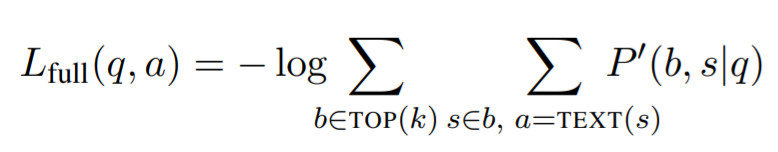
는 a가 범위 s와 정확하게 매칭되는지를 나타낸다.
좀 더 적극적인 학습을 수행하기 위해 우리는 더 많은 c개의 evidence block을 고려하는 대신, 계산비용이 저렴한 retrieval score만을 update하는 searly update를 도입했다.
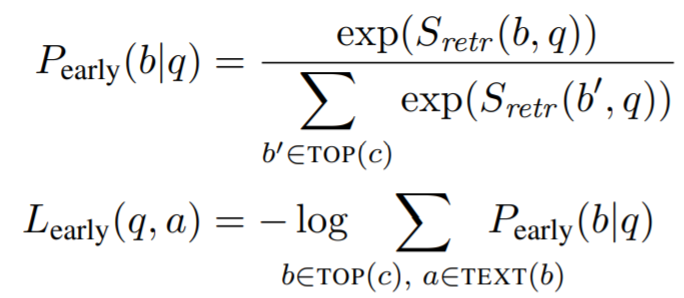
는 정답이 b에 포함되어 있는지를 나타내며 우리 실험에서는 을 사용했다.
최종 loss 함수는 두 개의 update로 결정된다.
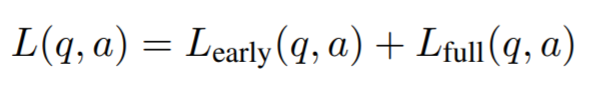
만약 answer과 전혀 매칭되지 않았을 때는 해당 example을 버린다. 우리는 random initialization으로 초기화 되었을 때는 대부분의 모든 example들이 버려질 것이라고 예상했는데, ICT 사전 학습 덕분에 실제로는 10% 미만의 데이터들만 버려졌다.
이전에 언급한 것처럼 evidence block encoder를 제외하고는 모든 가중치들을 fine-tuning했다. query encoder는 학습이 가능하기 때문에 모델이 어떤 evidence block을 가져올지에 대해 잠재적으로 학습할 수 있다. 이러한 표현력은 단지 evidence의 수를 늘려서 성능을 개선시키는 blackbox IR system과의 중요한 차이점이다.
7 Experimental Setup
7.1 Open Domain QA Datasets
우리는 5개의 QA 또는 RC 데이터셋을 가지고 학습 및 평가를 했다. 이 5개의 데이터셋은 모두가 open domain QA로 의도된 것은 아니었고, 그래서 우리가 DrQA와 같은 open format으로 변환했다. 각각의 open format으로 변환된 데이터는 하나의 질문과, 이와 관련된 정답으로 이루어져있다.
Natural Questiions
구글 서치로 집계된 질문들을 가지고 있다. open version으로 데이터셋을 모으기 위해서 질문에 대한 짧은 답만 취하고 나머지 evidence document는 버렸다. 많은 토큰들로 이루어진 정답은 종종 정식 답변보다는 말뭉치에서 추출된 형태와 가까웠기 때문에 우리는 5개의 토큰 이상의 답변은 모두 버렸다.
많은 토큰들로 이루어진 정답은 종종 정식 답변보다는 말뭉치에서 추출된 형태와 가까웠기 때문에
- "1 + 1은 몇인가요?" 라는 질문에 "안녕하세요, 날씨가 좋네요. 제가 이런 수학 문제를 정말 잘 풀거든요. 답은 아마도 2인 것 같습니다. 왜냐하면 손가락을..." 이라는 답변보다는 "2" 라는 답변을 취한다는 뜻이다.
Table 3

- 우리가 평가하는 데이터셋의 예시와 수치들이다. 데이터셋들은 open setting으로 설계된 것이 아니기 때문에 이를 수정했다. 그래서, 데이터셋의 원본과는 다소 차이가 있다.
WebQuestions
구글 제안 API로 얻은 질물 데이터이다. Freebase 커뮤니티에 의해 답변이 달아졌으며 개체의 표현(=단답형)으로 취했다.
CuratedTrec
Baudis and Sedivy´ (2015)에 의해 조직된 TREC QA 데이터의 QA 말뭉치이다. 실제 질문들에 대한 다양한 출처들로부터 질문을 얻었다. 예를 들면, 답변자가 evidence documents를 볼 수 없는 MSNSearch or AskJeeves logs에서.
TriviaQA
웹에서 얻은 trivia 질문-답변 쌍 모음이다. 필터링하지 않고 사용했으며 distantly supervised evidence를 삭제했다.
distantly supervised evidence를 삭제했다.
- 질문에 답변을 할 때는 답변자가 외부자료를 링크하거나 참고해서 답변을 하게 되는데 이 부분을 삭제했다는 뜻.
SQuAD
ODAQ를 위한 데이터셋이라기 보다는, 독해를 위해 설계되었다. 위키피디아 문단에서 정답 범위를 지정했고 질문은 지문에 있는 답으로 답변이 될 수 있는 질문을 하도록 교육받는 검수자가 질문을 작성했다.
development set이 없는 데이터셋은 무작위로 training set의 10%를 hold out 방식으로 development set으로 지정했다. test set은 공개되어 있지 않은 dataset은 traning data의 10%를 또 development로 사용하고 development dataset을 test로 사용했다. (이는 DrQA에서 제시한 방법이다) 표3에 데이터셋의 수치와 예시들이 요약되어있다.
7.2 Dataset Biases
다양한 QA 데이터셋을 평가하는 것은 중요하다. 왜냐하면 모든 현존하는 데이터셋은 저마다의 편향을 가지고 있고 이 편향 때문에 QA 시스템의 retrieval을 학습하는 데에 있어서 문제가 되기 때문이다. 이러한 편향들은 표 4에 요약되어있다.
NQ나 WebQ, CuratedTrec에서는 질문자가 미리 답을 알지 못한다. 이는 정확히 질문에 대한 정보를 찾는 진실된 분포를 반영한다. 그러나 만약 검수자는 정답을 분리해서 찾아야 한다. 이는 자동화 된 도구의 도움이 필요하며 이로인해 적당한 편향을 결과로부터 얻게된다
Table 4
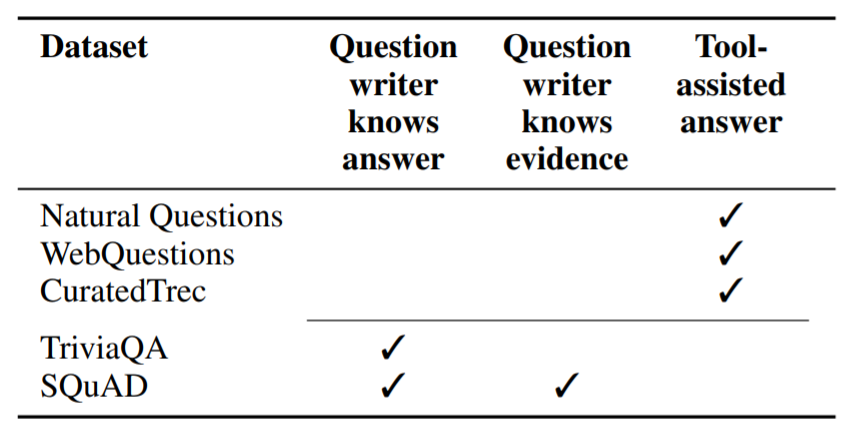
- 현존하는 QA 데이터셋의 편향 문제점이다. 이러한 편향은 질문과 정답 둘다와 관련이있다.
7.3 Implementation Details
Evidence Corpus
