Syllabus
- Introduction
- Data-Centric AI vs. Model-Centric AI
- Label Errors
- Dataset Creation and Curation
Data-centric Evaluation of ML Models- Class Imbalance, Outliers, and Distribution Shift
- Growing or Compressing Datasets
- Interpretability in Data-Centric ML
- Encoding Human Priors: Data Augmentation and Prompt Engineering
- Data Privacy and Security
Introduction
page: https://dcai.csail.mit.edu/lectures/data-centric-evaluation/
Lab: https://github.com/dcai-course/dcai-lab/blob/master/data_centric_evaluation/Lab%20-%20Data-Centric%20Evaluation.ipynb
What we've learnt?
- Model-Centric AI Vs. Data-Centric AI
- Confident Learning & Label errors
- Dataset Creation and Curation
What we are going to learn?
Machine Learning performance 향상시키기
- Evaluation of ML models
- 특정 subpopulation에서 성능이 안나오는 것 handling하기
- 개별적인 datapoints가 모델에 미치는 영향 측정하기
A Recap of Multi-class Classification
- goal:
- 학습 데이터 D를 이용해서 모델 M을 학습시켜서, feature x를 얻었을 때, 해당 데이터셋의 predicted class probabilites를 제공
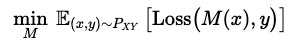
- 학습 데이터 D를 이용해서 모델 M을 학습시켜서, feature x를 얻었을 때, 해당 데이터셋의 predicted class probabilites를 제공
- Key assumptions:
- test 시 (여기서는 deployment라고 말함)에 보게 되는 데이터는 학습 데이터 D랑 같은 분포에서 나온 것이다!
- 학습 데이터 (x,y)는 independent하고, identically distributed (독립항등 분포 => 각 사건이 다른 사건에 영향을 미치지 X)
- 각 데이터는 단 하나의 클래스에 속한다 (cf. multi-label class classification)
- 고려해야할 점
- "other" 클래스를 포함해라!
- 만약에 클래스 나뉜게 애매~하다 싶으면 재정의 해라 (e.g., laptop & computer)
- 데이터에 ordering 문제가 있는지 확인! (데이터가 한쪽에 치우쳐져 있으면 배치 잘 섞여 있는게 좋으니께..?)
Evaluation of ML models
loss function
모델 평가방법은, 어떤 모델을 적용할 지 고민하는 것 보다 더 중요한 문제임!
loss function: 새로운 데이터 x의 라벨값을 얼마나 잘 예측하는지 확인할 때 사용
1. 예측 값 (y^hat):
- accuracy precision, recall 등
- 모델이 예측한 값이 얼마나 자주 ground truth랑 매칭이 되는지를 측정
- directly하게 모델을 평가하는 방식
- 예측 확률 (p_k):
- log loss, AUROC, calibration error 등
-똑같은 feature x를 가진 예시들이 반복해서 샘플링된다고 할때, 이제 예측된 y가 각 클래스 value들을 얼마나 정확하게 추정하는지 측정 - 예측된 클래스 확률은 in asymmetric reward (비대칭적 보상) settings에서 최적 결정 내리는 데 유용
- 이게 무슨 말인지 몰라서 chatgpt한테 물어봤다!
암 검진 결과를 예측하는 경우, 거짓 양성은 실제로는 암이 없는데도 암이 있다고 오진한 경우를 의미합니다. 이 경우, 거짓 양성의 결과가 거짓 음성보다 훨씬 더 큰 부정적인 영향을 줄 수 있으며, 이는 비대칭적 보상 설정의 예시입니다. 거짓 음성이 더 나쁜거 아냐? 암이 있는데 없다고 하는게 더 안좋은 거 같은댐..? 무튼 이것도 둘이가 1:1이 아니라 이거지? 그럼 이때! 위에서처럼 딱딱 나눠서 매칭하는 것보다 확률값을 구하는게 낫다~ 이거구만?
- 이게 무슨 말인지 몰라서 chatgpt한테 물어봤다!
Challenge
이렇게 딱 하나의 값으로 summarize해가지고 이 모델의 성능을 평가하는 건 좋지 않음.
예를 들어, 신용 카드 거래의 사기 vs 비사기 분류할 때 그냥 accuracy만 보면 안되는 이유는??
바로!! 데이터의 불균형이 발생할 수 있으니까! 일반적으로 사기 거래는 비사기 거래보다 훨씬 적은 비율을 차지. 만약 모델이 모든 거래를 비사기로 분류한다고 해도, 전체적인 정확도는 99%로 매우 높은 값을 가질 것임.
해결책 예시
- 정밀도(precision), 재현율(recall), F1 점수(F1 score) 등의 평가 지표 추가로 사용
- held-out-training해가지고 loss 평균을 낸다거나,
- 각 class별로 loss를 구한다거나,
- confusion matrix 등을 확인할 수 있음
그 외 발생할 수 있는 문제들
- 실제로 홀드아웃된 데이터를 사용하지 않는 경우 (데이터 누수): 평가용 데이터는 평가때만 써야하는데, 학습 때 써버리면 안된다!
- 어노테이션 오류: 평가 결과에 편향을 일으킬 수 있음.
Underperforming Subpopulations
2018년 연구에서, 어느 얼굴인식 서비스가 백인 남자 대상으로는 error rate가 0.8퍼인데, 흑인 여성의 경우엔 34.7퍼센트였음.
https://news.mit.edu/2018/study-finds-gender-skin-type-bias-artificial-intelligence-systems-0212
여성의 얼굴은 인식 못하는데, 하얀 마스크 쓰니까 인식해버림


원인
데이터나 모델이 bias하겠지..?? (언급된 사항은 없음.. 있을까하고 제목 적었는데 따로 말하진 않음)
해결책
모델이 특정 데이터 슬라이스에 성능이 아주 bad하게 나왔을 때, 학습하기 전에 slice 정보를 삭제해준다면 이런 문제가 해결될까?
NOPE! 하나의 정보를 지웠다고 해도, 여전히 그 정보랑 관련있는 다른 feature들이 predictor로 사용되고 있어서 계속해서 상관관계가 나타날 수 있음. 그래서 아예 정보를 무시하는 것보다 최소한이라고 고려하는 게 나음!
data slice (=cohorts, subpopulations, subgroups: 공통의 특징을 공유하고 있는 하위 집단 (인종, 성별, 나이, 등등)
- 평가 방법:
가장 간단한 방법은 그냥 각 슬라이스 마다 홀드아웃 데이터를 만들어가지고 각각 loss 계산해서 평균내는 것.
- 특정 슬라이스에 대해 모델 성능 높이는 방법:
- higher fitting capacity를 가지고 있는 flexible한 ML model 사용
- e.g. neural network with more parameters
- 아래 그림을 보면, feature들이 nonlinear할 때 선형 모델로 binary classification을 한다면?!! 선형 모델은 이를 잘 포착하지 못하니까 한 그룹에 대한 예측 정확도를 높일려면, 다른 그룹에 대한 정확도는 낮아질 수 밖에 없음. low-capacity 모델들은 그룹간에 트레이드오프 accuracy가 발생함.
- 그래서 NN모델 처럼 high-capacity한 모델들을 사용하면 이런 tradeoff 안만들어도 되어서 더 정확한 예측할 수가 있음!
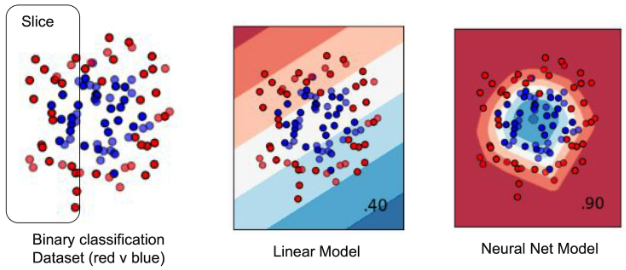
-
성능 잘 안나오는 소수의 서브그룹 데이터들 Over-sample or up-weight (가중치 높이기)
아래 그림처럼 한 공간에 두 하위 그룹이 겹치게 있다면? 어떤 모델이여도 잘 예측하는 거 힘들 걸? 또 tradeoff 생길 수 밖에! 그래서 이때는 트레이드오프가 생기긴 하겠지만 오랜지에 가중치를 둬버리는 거임.
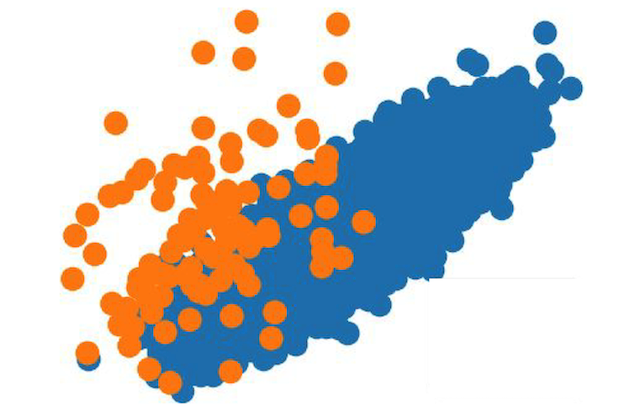
-
데이터 추가 수집 해버리기!
down-sampling같은 거 해서 확실히 많은 게 더 좋더라~ 이런 게 나오면 더 수집하면 좋음. -
feature 같은 거 더 뽑아서 그 그룹을 더 잘 설명할 수 있게 하자!
Discovering underperforming subpopulations
일부 데이터에는 문서 또는 이미지 같이 명확한 슬라이스가 없을 수 있음. 이 경우 모델이 성능이 떨어지는 subgroup을 어떻게 확인할 수 있을까?
1. error analysis: 어떤거 틀렸는지 확인
2. 큰 loss로 틀린 애들끼리 clustering을 해가지고 어떤 특징으로 묶이는지 파악
3. Domino slice discovery method
기존의 clustering 방식은 두 데이터 간에 거리가 얼마나 벌어져있는지만 고려하면되는데, Domino slice discovery method는 loss-value도 확인해서 특징들을 파악한다.
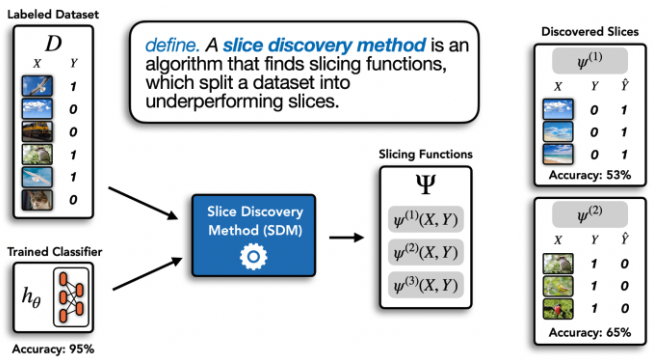
Why did my model get a particular prediction wrong?
예시
- 우리 모델은 제대로 예측했는데, 라벨링이 잘못되어 있는 경우
- 애초에 데이터가 잘못되었거나 (e.g. 너무 흐림), 아니면 어떤 클래스에도 속하지 않는 경우
- outlier (학습 데이터에 비슷한 경우가 없었음)
- 모델 자체가 테스크를 수행하는 데 좋은 모델이 아님. 이를 파악해보려면, 데이터셋의 가중치 높이거나, 중복해서 똑같은 데이터 포함시켜서 훈련했을 때도 예측 잘 못하는지 확인해본다! 데이터셋으로 어려우면 모델의 파라미터 등을 조정해서 해볼 수 있음.
- 똑같은 feature를 가졌는데, 서로 라벨이 다른 경우. 이럴 때는 모델 적으로 어떻게 해볼 수 없고, 그냥 데이터 수나 feature 크기를 늘리는 수 밖에 없음. calibration 기술이 useful한 예측 확률 뽑는 데 좋을 수도!
해결책 (1,2,3번 예제에 대한 해결책)
- 틀린 라벨을 바로 잡기
- other 클래스를 만들든지, 버려버렷!
- 훈련 셋에 절대절대 없다면 얘도 버려버렷. 아니면 비슷한 데이터를 훈련에 넣어줘야함. 전처리를 잘해서 이상치를 없애든가, 가중치를 조절하등가..... cleanlab처럼 ood 없앨 수 있게 해줘도 good
Quantifying the influence of individual datapoints on a model
Influence function
: 특정 데이터가 모델에 얼마나 영향을 미치는가?!
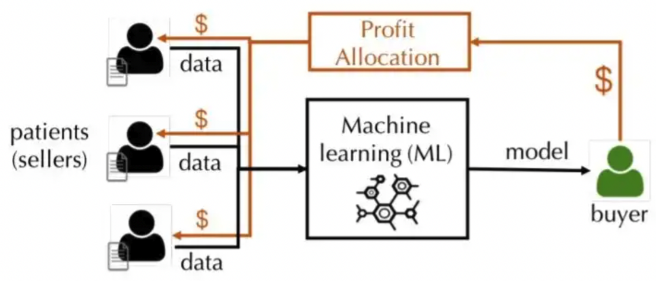
우리가 buyer고 병원으로부터 데이터를 제공받는다고 가정해봅시다! 우리는 병원에 얼마를 주는 게 적절할까?
모두 동일하게 줄 수도 있지만, 그럼 더 값어치 있는 데이터를 제공해준 거면 고려해줘야하지 않겠수? 예를 들어 데이터 라벨링이 너무 많으면 우리는 추가비용이 드니까!!!
(이때 어떤식으로 change를 했냐에 따라서 어떻게 정량화할지 달라진다. 보통 예측값이 어떻게 달라졌는지 보거나, 모델의 성능이 얼마나 달라졌는지 본다.)
Influence는 모델에 가장 큰 영향을 미치는 데이터 포인트를 찾아내줌.
라벨링 잘못된 데이터가 두개 있다할 때, 영향력이 더 큰쪽의 값을 수정하는 게 훨씬 더 모델 개선 효과 있음.
Leave-one-out (LOO) influence
데이터 포인트 (x,y)가 포함된 subset에서 해당 데이터포인트의 LOO influence는 어느정도냐?
보려고 하는 데이터 하나씩 빼서 성능이 얼마나 달라졌는지 확인해본다.
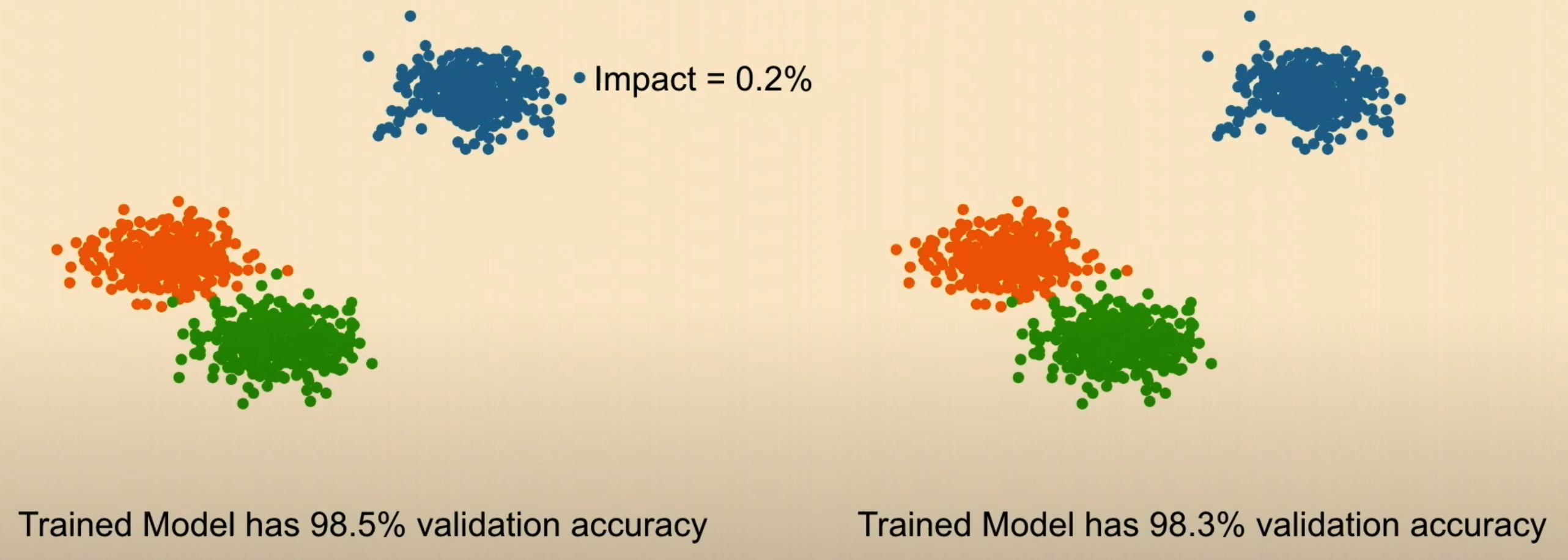
but! 100개 데이터 이미 있는데 한개 뺐다고 해서 영향에 큰 영향이 있다고 할 순 없음!
Data Shapely
데이터 포인트 (x,y)가 원래 데이터 세트에서 뿐만 아니라, 나머지 다른 데이터 subset에서도 어떤 역할을 하는지도 고려함! (얘가 이 그룹에선 이만큼 영향이 있는데, 저쪽에서는 이만큼만 있을 수 있음)
그래서 해당 데이터 포인트를 포함한 모든 subset에서의 LOO influence를 계산한 다음에 평균을 내봅니다!
만약에 완전 똑같은 데이터 A,B 두 개가 있는데, 한 개만 삭제하면 성능이 그냥 똑같은데, 둘다 삭제하면 성능이 엄청 떨어짐! 이때 A,B 두개의 데이터에 대한 influence를 구해본다면?
=> LOO influence: 데이터 포인트 하나만 삭제한 후에 성능 비교를 하니까 크게 영향을 안미침!
=> Data Shapely: subset 중에서 두개 다 포함되어있을 때, 같은 데이터 포인트는 모두 삭제해버리니까 엄청 크게 성능 떨어질 것임.
Approximate influence via Monte-Carlo
근데! 우리가 이 데이터들 다 하나씩 해가지고 훈련하면 너무 expensive하지 않겠습니까? 그래서 대안책으로 approximate합니다.
몬테카를로 방법은 반복된 무작위 추출을 이용하여 함수의 값을 수리적으로 근사하는 알고리즘을 부르는 용어
- 원래의 훈련 데이터셋에서 (노 반복) T개의 서로 다른 데이터 부분집합 D을 추출.
- 각 데이터 셋(D_t)에 대해서 모델 (M_t)을 훈련시키고, held-out-valudation data에 대한 accuracy를 구한다. (a_t)
- (x,y) 데이터포인트의 value를 구하기 위해서, (x,y)가 포함된 subset과 포함하지 않은 subset을 사용했을 때의 모델 성능을 구해서 비교한다!
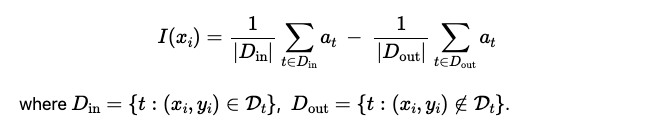
Accuracy here could be replaced by any other loss of interest.
- 추가 예시들!
-
Regression setting: Cook's Distance
Nguyenova, L. A little closer to Cook’s distance. Medium, 2020.
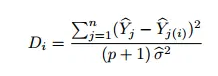
Cook's D는 i번째 데이터 포인트를 모델에서 제거하고 회귀를 다시 계산해서 뽑음. 회귀 모델의 모든 값들은 해당 데이터 포인트를 제거한 후에 변경이 감지되었는지를 관찰 -
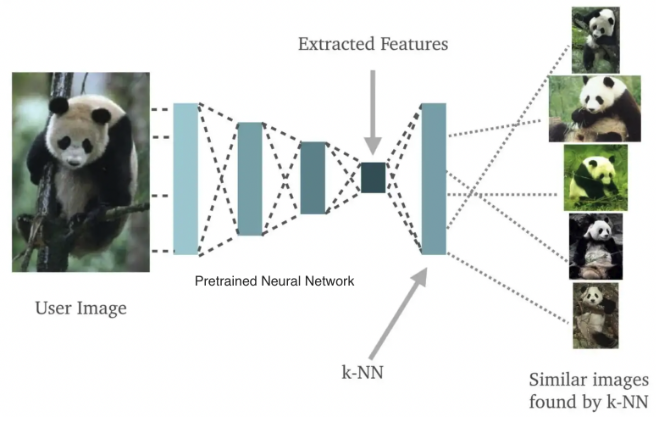
Classification setting: O(n \log n) time (복잡도 구하기)
사전 훈련된 신경망을 사용하여 모든 데이터를 임베딩한 후, 임베딩 뽑아서 KNN (K-Nearest Neighbors) 분류기를 적용. 그런 다음 KNN이 비슷한 이미지를 찾아줌. 그럼 이 데이터가 다른 비슷한 이미지 얼마나 잘 찾는지, 얼마나 대표하는 특징을 가졌는지 알 수 있구나?

알고리즘 소요 시간 : 시간 복잡도 - 자료의 수 n이 증가할 때 시간이 증가, n에 비례하는 연산
알고리즘 메모리 사용량 : 공간 복잡도
일반적으로 입력 크기에 따라 복잡도 달라지는 걸로 본다.
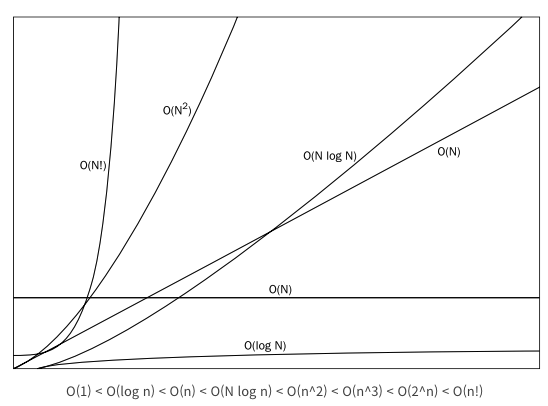
출처: https://blog.tomclansys.com/50
-
Code
데이터로드
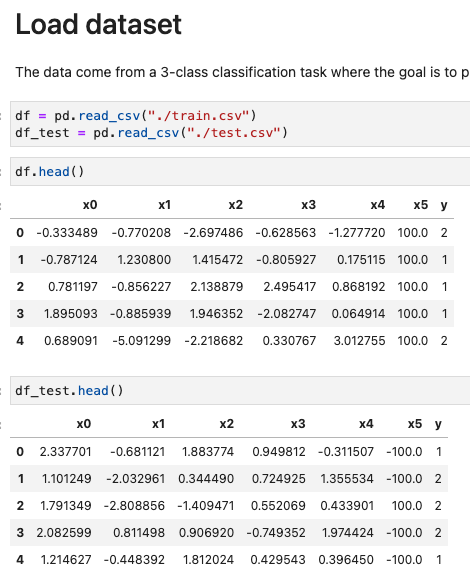
- task:
클래스는 총 3개, x0~x5 값을 가지고 y값 맞추기!

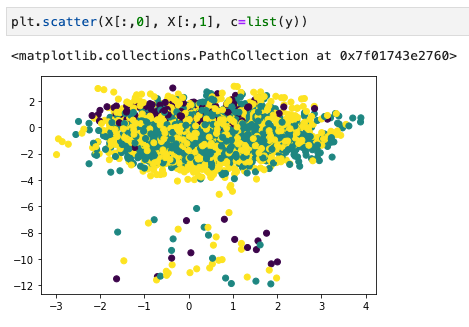
Improve ML Model via data-centric techniques
- Evaluation: Balanced_accuracy
Balanced_accuracy:
The balanced accuracy in binary and multiclass classification problems to deal with imbalanced datasets. It is defined as the average of recall obtained on each class.

EX 1:
-
goal: to produce a model that has much better test accuracy
강의에서 제시된 다양한 아이디어를 고려해서 X와 y를 적절히 변경! 그런 후 더 성능 높은 모델 만들어라! -
데이터 확인
- 컨퓨전 메트릭스 뽑아보니까 0번 클래스를 진짜 못맞추잖아?

- 봤더니 0번 데이터 갯수가 다른 클래스에 비해 엄청 적네
- 컨퓨전 메트릭스 뽑아보니까 0번 클래스를 진짜 못맞추잖아?
-
idea 1: normalize?
- 데이터 피쳐들의 standard deviation을 뽑아봤음. x5가 뭔가 다른애들에 비교해서 통통튀네?

- 그럼 그냥 없애버려! 그랬더니 성능이 12프로나 상승!

- 데이터 피쳐들의 standard deviation을 뽑아봤음. x5가 뭔가 다른애들에 비교해서 통통튀네?
-
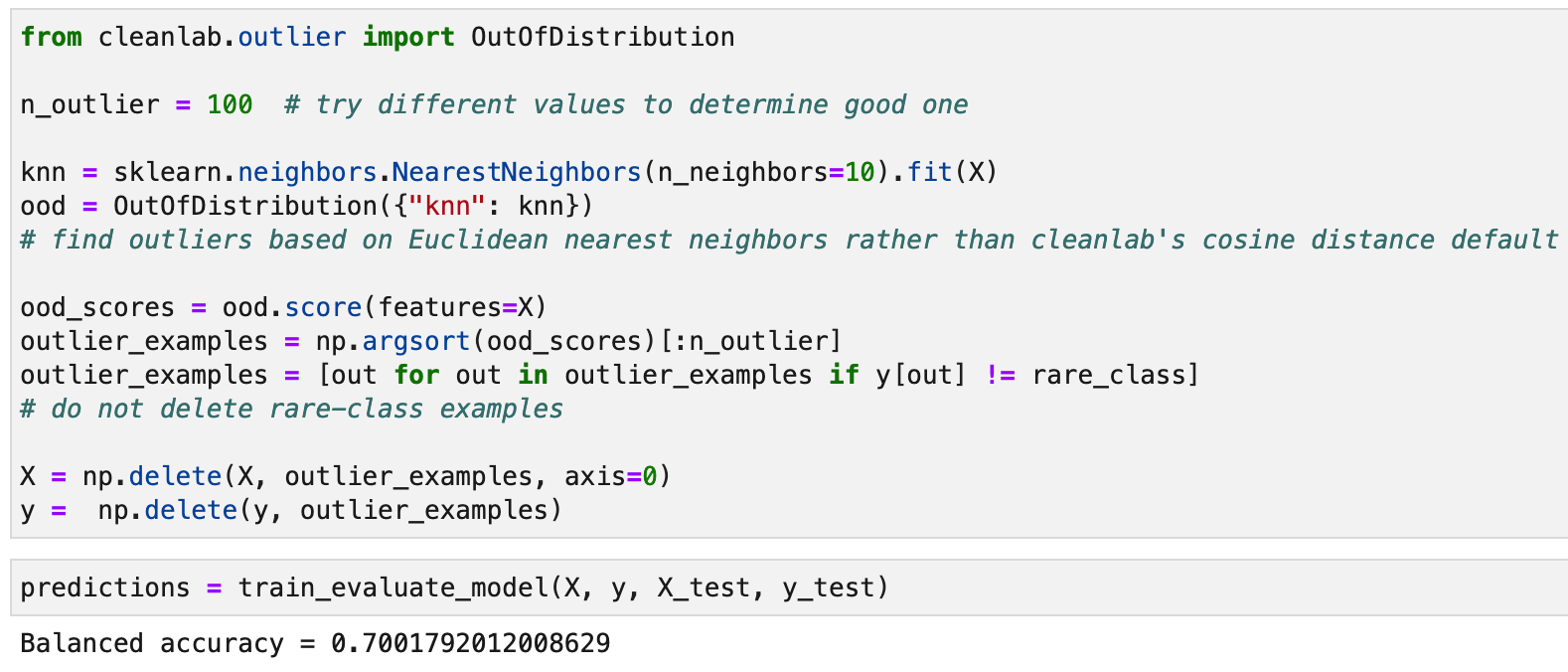
idea 2: outlier 없애기. cleanlab이 잘해주는 구만! 오 rare_class는 없애지 말라고도 했네? 이번엔 성능이 아주 조~금 올랐음.
-
idea 3 : up-sample
- 83까지 올랐습니다!!

- 83까지 올랐습니다!!
Review
데이터 포인트의 influence 구하는 것도 궁금했는데, 이거 관련해서는 실습을 안했네! 시간 날때 따로 찾아보자
