
코로나 시절과 ChatGPT 발표 이후, 머신러닝이니 LLM이니 인공지능 광풍이 불고 있습니다. 단순히 기업이 제공해주는 AI 서비스를 사용하기 보다는, 직접 하나 만들어 볼까 하는 생각이 들 때가 있습니다. 그래서 오늘은 부담 없이 시작하기 좋은 예제로 학습해보고자 합니다.
머신러닝 입문에서 빠지지 않는 MNIST 손글씨 숫자 데이터셋으로, 숫자(0~9)를 분류하는 모델을 학습하고 파일로 저장까지 해보겠습니다. 코드 길이는 10줄 남짓이지만, 데이터 로드 → 전처리 → 모델 학습 → 저장이라는 기본 흐름은 다 들어 있습니다.
1. 간단한 학습 코드
먼저 전체 코드를 한 번 보고, 아래에서 줄마다 상세히 살펴보겠습니다. 파일명은 train_model_28.py 정도로 저장해 두면 좋겠습니다.
# train_model_28.py
import joblib
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
# 1. 데이터 불러오기
X, y = fetch_openml("mnist_784", version=1, return_X_y=True, as_frame=False)
y = y.astype(int)
# 2. 파이프라인 및 모델 설계
model = make_pipeline(
StandardScaler(with_mean=False), # 0이 많은 데이터에서 메모리/속도 측면에 유리
LinearSVC(verbose=1) # 학습 로그 출력
)
# 3. 모델 학습
model.fit(X, y)
# 4. 학습된 모델 저장
joblib.dump(model, "digit_model_28.joblib")
print("saved")물리적인 코드 줄 수는 짧긴 하지만 학습 스크립트 한 번 돌려서 모델 파일 뽑기까지는 이 정도로 충분합니다.
2. 개발 환경 세팅
코드를 세세하게 살펴보기에 앞서서 패키지 설치를 해야합니다. 필요한 패키지는 세 개입니다. 아래의 명령어를 활용하여 패키지를 설치하여 줍니다. 가상환경을 먼저 세팅하고 진행하면 좋겠습니다.
pip install numpy scikit-learn joblib- numpy: 배열/수치 연산
- scikit-learn: 데이터셋 로드, 전처리, 모델 학습
- joblib: 학습된 모델 저장/로드
3. 라이브러리 임포트
본격적으로 코드를 살펴보겠습니다. 라이브러리 임포트 부분은 아래와 같습니다.
import joblib
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC여기서는 크게 세 가지가 중요합니다.
fetch_openml: MNIST를 내려받아X, y로 받기make_pipeline: 전처리 + 모델을 한 덩어리로 묶기joblib: 학습 결과를 파일로 저장하기
4. MNIST 다운로드
그 다음은 데이터를 불러오는 부분입니다.
X, y = fetch_openml("mnist_784", version=1, return_X_y=True, as_frame=False)
y = y.astype(int)MNIST는 0부터 9까지의 손글씨 숫자를 모아 만든, 머신러닝 입문에서 가장 많이 쓰이는 데이터셋 중 하나입니다. 이미지 분류를 아주 작은 규모로 경험해보기 좋아서, 빠르게 기초 예제을 만들 때도 자주 등장합니다.

4.1 MNIST 상세 정보
- 구성: 총 70,000장(학습 60,000장 + 테스트 10,000장)
- 이미지 크기: 28×28 픽셀, 흑백 1채널
- 픽셀 값: 대체로 0~255 범위의 명암값. 0에 가까울수록 검은색, 255에 가까울수록 흰색에 가까움
- 라벨: 0~9의 숫자 클래스 10개
4.2 X, y는 어떤 형태인가
fetch_openml("mnist_784")는 각 이미지를 28×28로 주는 대신, 학습이 편하도록 길이 784짜리 벡터로 펴서 제공합니다.
- X: (70000, 784) 형태의 2차원 배열. 한 행이 이미지 한 장
- y: 길이 70,000짜리 레이블 배열
즉, mnist_784라는 이름은 28×28을 펼친 784차원 입력이라는 의미입니다.
4.3 왜 y를 int로 바꾸는가
OpenML에서 내려받은 y는 종종 문자열로 들어옵니다. 분류 자체는 문자열이어도 되지만, 뒤에서 평가 지표를 쓰거나 혼동행렬을 그릴 때는 정수형이 더 다루기 편해서 y.astype(int)로 고정해 둡니다.
4.4 fetch_openml을 쓸 때 알아두면 좋은 점
- 첫 실행은 다운로드가 필요: 인터넷 속도나 OpenML 상태에 따라 시간이 걸릴 수 있습니다.
- 캐시 사용: 한 번 받아두면 이후에는 로컬 캐시를 재사용하는 경우가 많습니다.
- 메모리 사용량: MNIST는 크기가 아주 큰 편은 아니지만, 배열 형태로 로드하면 작업 환경에 따라 꽤 메모리를 씁니다. 노트북에서 돌릴 때는 다른 무거운 프로그램을 좀 닫아두는 게 편합니다.
- 데이터 타입: 내려받은 X의 dtype은 상황에 따라 float로 들어올 수 있습니다. 이 글에서는 스케일링을 적용하므로 그대로 진행해도 문제 없습니다.
이제 데이터가 준비됐으니, 전처리와 모델을 파이프라인으로 묶어 학습을 진행해 보겠습니다.
5. 파이프라인과 전처리
model = make_pipeline(
StandardScaler(with_mean=False),
LinearSVC(verbose=1)
)여기서 핵심은 전처리와 모델을 묶어서 한 번에 관리한다는 점입니다. 나중에 예측할 때도 같은 전처리를 자동으로 적용할 수 있어서 실수가 줄어듭니다.
5.1 StandardScaler 사용 이유
MNIST 픽셀 값은 0~255 범위입니다. 이런 입력에서 스케일 조정은 학습 안정성/속도에 도움 되는 경우가 많습니다.
5.2 with_mean=False의 의미
MNIST는 배경이 대부분 0이라서 0이 많은 편입니다. StandardScaler가 평균을 빼기 시작하면(기본값) 0이었던 값들이 0이 아닌 값으로 바뀌면서, 내부 표현이 촘촘해져 메모리/연산 비용이 늘어날 수 있습니다. 그래서 평균을 빼지 않도록 with_mean=False를 둡니다.
6. LinearSVC와 verbose
파이프라인의 두 번째 단계는 LinearSVC입니다. 이름 그대로 선형(Linear) SVM 분류기이고, scikit-learn에서는 빠르고 단단한 기준 모델로 많이 씁니다.
6.1 SVM이란
분류 문제에서 클래스 사이를 가르는 경계를 찾는 모델입니다. SVM은 그중에서도 경계를 가능한 넓은 여백(margin)으로 잡으려는 성질이 있고, 그래서 데이터가 어느 정도 잘 정리되어 있으면 생각보다 성능이 잘 나옵니다.
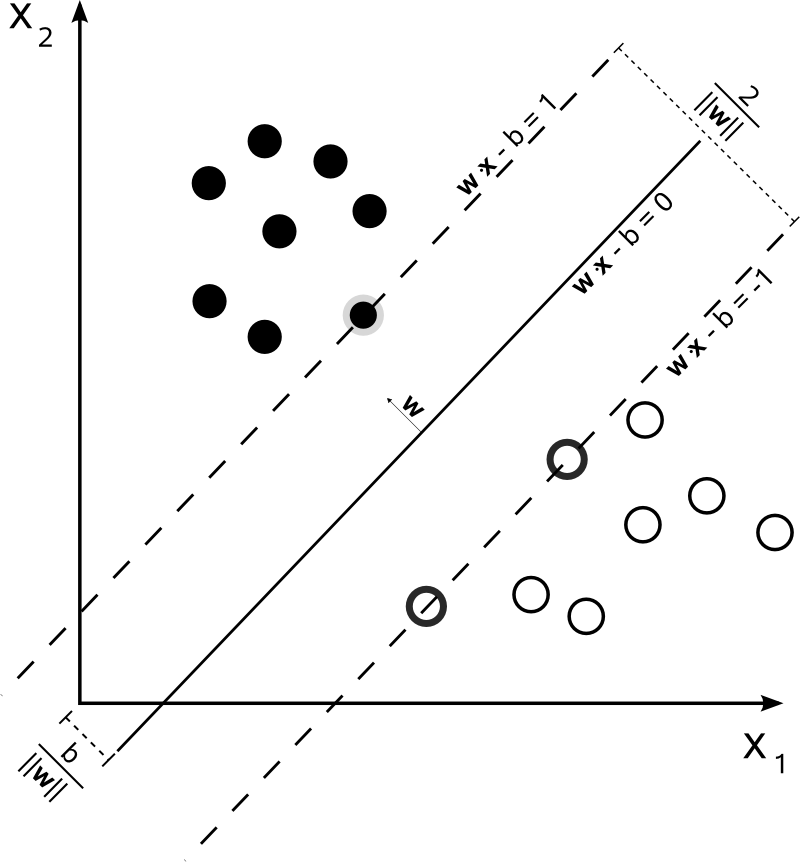
MNIST는 입력이 784차원(28×28)이라 차원이 꽤 높습니다. 이런 경우 선형 모델이 의외로 잘 먹히는 편이고, 학습/예측 속도도 빠릅니다.
6.2 LinearSVC를 고른 이유
- 학습이 비교적 빠름: 딥러닝처럼 GPU가 꼭 필요하지 않고, CPU로도 학습 가능
- 기준 모델로 좋음: 일단 되는 모델을 먼저 만들어두면, 이후 전처리/모델 교체의 효과를 비교하기가 쉬워짐
- 설명이 가능함: 완벽히 해석 가능한 모델은 아니지만, 적어도 선형 결합으로 분류한다는 직관이 있음
6.3 추가 사항
지금 글에서는 최대한 단순하게 두었지만, 실제로 돌리다 보면 아래를 고려해야 할 상황이 올 수 있습니다.
-
수렴 경고(ConvergenceWarning): 데이터/환경에 따라 반복 횟수가 부족하다는 경고가 뜰 수 있음. 이 때는 아래의 방법을 검토해보아야 함
max_iter를 늘리기C(규제 강도)를 조정- 전처리를 조금 더 안정적으로 만들기
-
생각보다 긴 학습 시간: MNIST 전체 7만 장을 그대로 학습하면 꽤 걸릴 수 있음. 빠르게 감만 볼 거면 일부 샘플만 뽑아서 시작하는 것도 방법.
6.4 verbose=1 이란
LinearSVC(verbose=1)verbose는 학습 로그를 출력하는 옵션입니다. MNIST처럼 데이터가 많으면 학습이 한동안 조용히 돌아가서 멈춘 건가 싶을 때가 있는데, 로그가 나오면 진행 중이라는 걸 확인할 수 있습니다.
로그가 너무 많으면 verbose=0으로 끄면 되고, 반대로 학습 상태를 더 보고 싶으면 값을 올려볼 수도 있습니다.
7. 학습
이제 실제 학습을 돌려보겠습니다.
model.fit(X, y)
학습은 이 한 줄로 끝납니다. 다만 실제로 돌려보면 어디서 얼마나 걸리는지, 돌아가고 있는 게 맞는지, 너무 오래 걸리면 어떻게 할지 같은 현실적인 포인트들이 생깁니다. 이 부분을 조금 보강해두면 시행착오가 줄어들 수 있습니다.
7.1 fit에서 실제로 일어나는 일
- 파이프라인 1단계
StandardScaler가 입력 X로 스케일링 기준을 계산 - 계산한 기준으로 X를 변환
- 파이프라인 2단계
LinearSVC가 분류 경계(가중치)를 학습
즉, fit 한 번으로 전처리 기준 + 모델 파라미터가 같이 만들어집니다. 그래서 저장할 때 파이프라인 통째로 저장하는 게 편합니다.
7.2 예상보다 긴 학습 시간
MNIST 전체(70,000장)를 한 번에 학습하면 PC 사양에 따라 꽤 걸릴 수 있습니다. 처음에는 아래처럼 샘플을 조금만 뽑아서 감을 보는 것도 방법입니다.
# 빠른 테스트용(선택): 처음 10,000개만으로 먼저 학습
X_small = X[:10000]
y_small = y[:10000]
model.fit(X_small, y_small)일단 돌아가는 걸 확인한 뒤 전체 학습으로 늘리면, 디버깅이 훨씬 수월합니다.
7.3 수렴 경고가 뜨는 경우
LinearSVC는 데이터/환경에 따라 수렴(최적화 완료) 전에 반복이 끝나서 경고가 뜰 수 있습니다. 이때는 보통 아래 중 하나로 해결합니다.
max_iter늘리기C조정하기(규제 강도)
예시
model = make_pipeline(
StandardScaler(with_mean=False),
LinearSVC(verbose=1, max_iter=5000, C=1.0)
)여기서 C는 클수록 규제가 약해지고(모델이 더 자유로워지고), 작을수록 규제가 강해집니다. 처음에는 기본값으로 두고, 경고가 반복되면 max_iter부터 올려보는 편이 안전합니다.
7.4 학습이 제대로 됐는지 빠르게 확인하는 방법
학습 직후에 아주 간단히라도 확인하고 넘어가면 좋습니다.
print("train score:", model.score(X[:2000], y[:2000]))이 점수는 대충은 맞추는지 보는 용도입니다. 제대로 된 평가는 다음 단계에서 학습/테스트를 나눠서 하게 됩니다.
8. 모델 저장
이제 학습이 끝났으니 모델을 파일로 저장해 보겠습니다.
joblib.dump(model, "digit_model_28.joblib")
print("saved")학습이 끝나면 모델을 파일로 저장해 둬야 다음에 다시 학습하지 않고 바로 사용할 수 있습니다.
scikit-learn 모델은 pickle로도 저장할 수 있지만, numpy 배열이 포함된 경우 joblib이 더 편하고 빠른 편이라 자주 씁니다.
9. 저장한 모델로 예측하기
오늘 글의 핵심 코드는 모델을 학습시키고 저장하는 것(Training)까지였습니다. 그렇다면 이렇게 저장된 .joblib 파일은 나중에 어떻게 써먹을 수 있을까요?
새로운 파이썬 파일(예: predict.py)을 만들어서 다음과 같이 활용할 수 있습니다. 이것이 바로 우리가 만든 AI를 서비스에 적용하는 '추론(Inference)' 단계입니다.
이번 파트에서는 이미지 파일(사진/스캔/그림판 캡처 등) 을 읽어서 테스트해 보겠습니다. 핵심은 입력 이미지를 MNIST 형태(28×28, 흑백, 0~255)로 맞춘 뒤 784로 펼친다 입니다.
아래 사진과 같이 그림판을 활용하여 숫자를 하나 그려서 digit.png 라는 파일로 저장하였습니다.

9.1 준비
이미지 처리를 위해 Pillow가 필요합니다.
pip install pillow9.2 예측 코드 예제
아래 코드는 digit.png 파일을 읽어 예측합니다.
- 숫자는 화면에서 가운데에 크게 오도록 하는 게 유리합니다
- MNIST는 대체로 검은 배경 + 밝은(흰색) 숫자 형태라서, 반대로 되어 있으면 자동으로 뒤집도록 처리했습니다.
# predict_image.py
import joblib
import numpy as np
from PIL import Image, ImageOps
MODEL_PATH = "digit_model_28.joblib"
IMAGE_PATH = "digit.png" # 테스트할 이미지 파일 경로
model = joblib.load(MODEL_PATH)
# 1) 이미지 로드 → 흑백 변환
img = Image.open(IMAGE_PATH).convert("L")
# 2) 여백/배경 정리(선택)
# 너무 어두운 배경이 섞이면 성능이 떨어질 수 있어서, 자동 대비 보정을 살짝 넣어둡니다
img = ImageOps.autocontrast(img)
# 3) 28x28로 리사이즈
# MNIST는 28x28 기준이라 일단 맞춥니다
img = img.resize((28, 28))
# 4) numpy 배열(0~255)로 변환
arr = np.array(img, dtype=np.float32)
# 5) MNIST와 배경/글자 밝기 방향 맞추기
# 평균이 높으면(전체가 밝으면) 흰 배경일 가능성이 커서 반전합니다
if arr.mean() > 127:
arr = 255 - arr
# 6) (1, 784)로 펼치기
x = arr.reshape(1, -1)
pred = model.predict(x)[0]
print(f"예측 결과: {pred}")
9.3 잘 안 맞을 때 체크리스트
- 숫자가 너무 작거나 한쪽에 치우쳤는지
- 배경에 노이즈가 많은지(종이 질감, 그림자, 테이블 무늬)
- 숫자 색이 너무 옅은지(연필로 살짝 쓴 사진은 대비가 약해서 불리합니다)
- 여러 숫자가 같이 찍혔는지(이 모델은 한 장에 숫자 하나를 가정합니다)
이 예제는 가볍게 돌려보는 버전이라, 실전 수준으로 가려면 중앙 정렬(무게중심 이동), 이진화(threshold), 크롭/패딩 같은 전처리를 더해주는 게 효과가 큽니다.
10. 마무리
오늘 한 건 단순합니다. MNIST를 받아서, 전처리 붙이고, 선형 분류기로 학습하고, 모델 파일로 저장했습니다. 비록 최신 유행하는 딥러닝 코드는 아닐지라도, LinearSVC와 Pipeline의 조합은 실제 현업에서도 정형 데이터나 베이스라인 모델을 만들 때 사용되는 강력하고 검증된 방법론이라고 합니다.
코드가 짧아도 이 흐름을 직접 한 번 돌려보면 다음 단계가 훨씬 쉬워집니다.
AI 모델 학습의 다음 단계로는 아래 정도를 해보면 좋겠습니다.
- 모델 평가하기:
train_test_split모듈을 사용하여 데이터를 학습용/테스트용으로 나누고,accuracy_score로 내 모델이 몇 %의 정확도를 가지는지 직접 측정해보기 - 알고리즘 교체하기:
LinearSVC자리에RandomForestClassifier나 다른 알고리즘을 넣어서 파이프라인을 실행해 보고 성능을 비교해보기 - 딥러닝으로 넘어가기: 머신러닝의 기초를 다졌으니, 이제 텐서플로우(TensorFlow)나 파이토치(PyTorch)를 이용해 이 손글씨 데이터를 인공신경망(CNN)으로 더 정확하게 분류하는 방법을 학습해보기
다음 글에서는 방금 제시한 모델 학습의 다음 단계가 아닌, 오늘 학습한 모델을 FastAPI로 서빙하고 Vue.js로 테스트하는 예제를 만들어보도록 하겠습니다.
