2022년 현재, 전세계에 약 19억개의 웹사이트가 존재한다.
대부분의 인터넷 사용자는 원하는 정보를 취득하기 위해 Google같은 검색사이트를 이용한다. 따라서, 내가 만든 웹사이트가 인터넷 사용자들에게 이용되고 싶다면 검색사이트들이 사용하는 검색엔진에서의 노출이 매우 중요하다.
Search Engine Optimization(SEO)를 통해서 검색엔진이 본인의 웹사이트를 검색하기 알맞은 구조로 웹사이트를 조정하기도 하는데, 이것은 기본적으로 검색엔진이 웹사이트 정보를 어떻게 수집하는지 아는 것으로부터 시작된다.
검색엔진은 Robot이라는 프로그램을 이용해 매일 전세계의 웹사이트 정보를 수집하는 크롤링을 한다. 그리고 검색 사이트 이용자가 검색할 만한 키워드를 미리 예상하여 검색 키워드에 대응하는 인덱스를 만들어 둔다.
인덱스를 생성할 때 사용되는 정보는 검색 로봇이 수집한 정보인데 결국 웹사이트의 HTML 코드이다. 즉, 검색 엔진은 HTML 코드 만으로 그 의미를 인지하여야 하는데 이 때, Semantic element를 해석하게 된다.
HTML으로 작성된 document는 컴퓨터가 해석할 수 있는 메타데이터와 사람이 사용하는 자연어 문장이 뒤섞여 있다. 아래 코드를 보면 1행과 2행은 브라우저에서 동일하게 표시된다. 이는 h1 태그의 디폴트 스타일이 1행과 같기 때문이다.
<font size="6"><b>Hello</b></font>
<h1>Hello</h1>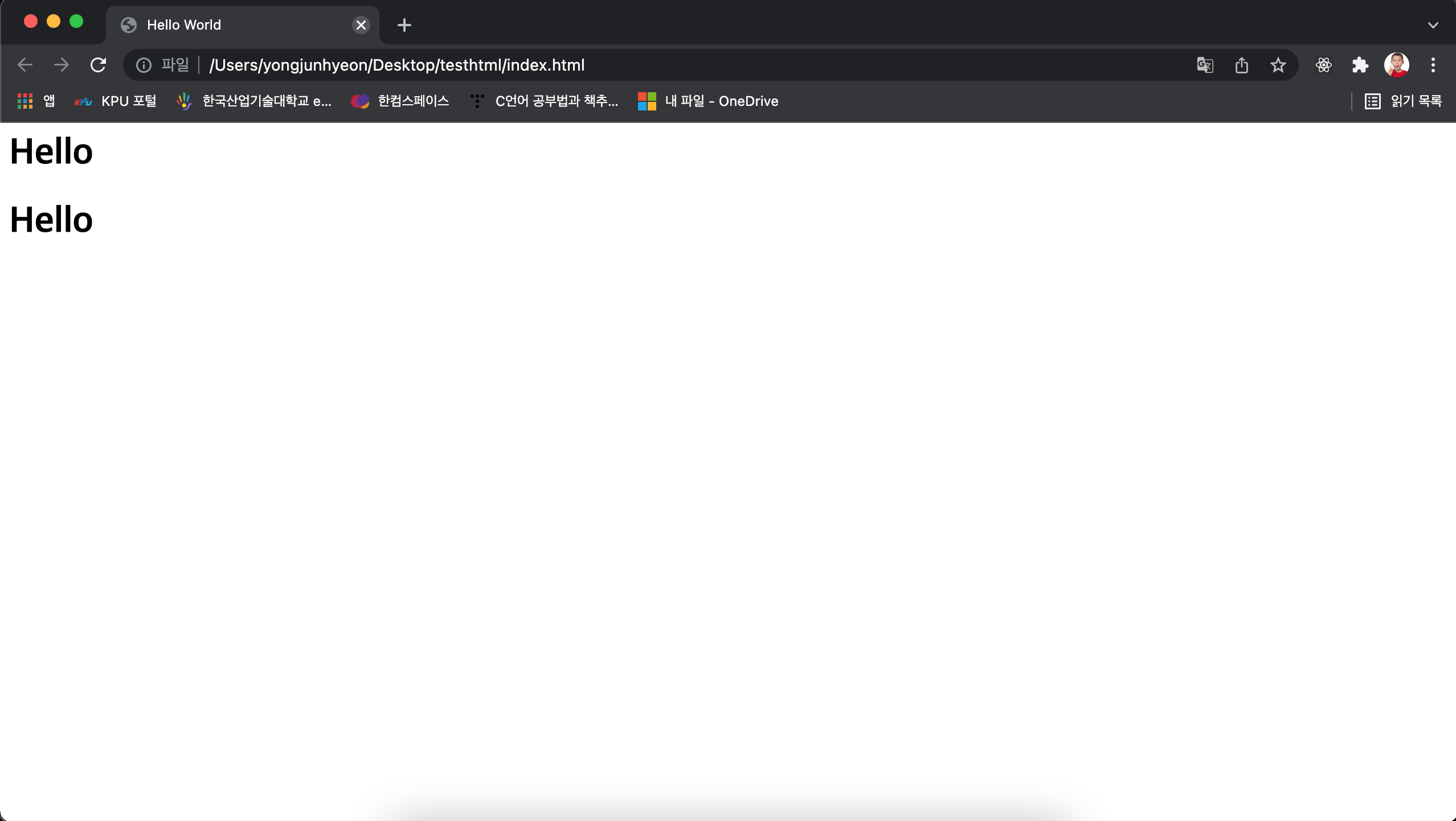
1행의 element는 의미론적으로 어떤 의미도 가지고 있지 않다. 즉, 코드만 보고는 의미를 파악하기 어렵다. 개발자가 의도한 element의 의미를 명확하게 나타내지 않고 다만 폰트 크기와 볼드체를 지정하는 메타데이터만을 브라우저에게 알리고 있다.
그러나 2행의 element는 가장 상위 레벨의 header이라는 의미를 내포하고 있어서 개발자가 의도한 element의 의미가 명확히 드러나고 있다. 이것은 코드의 가독성을 높이고 유지보수를 쉽게한다.
검색엔진은 대체로 h1 element 내의 content를 웹문서의 중요한 제목으로 인식하고 인덱스에 포함시킬 확률이 높고, 사람도 제목임을 인식할 수 있다.
Semantic element로 구성되어 있는 웹페이지는 검색엔진에 보다 더 의미론적으로 문서 정보를 전달할 수 있고 검색엔진 또한 semantic element를 이용하여 보다 더 효과적인 크롤링과 인덱싱이 가능해졌다.
즉, semantic tag란 브라우저, 검색엔진, 개발자 모두에게 content의 의미를 명확히 설명하는 역할을 한다. semantic tag에 의해 컴퓨터가 HTML element의 의미를 보다 명확히 해석하고 그 데이터를 활용할 수 있는 semantic web이 실현될 수 있다.
Semantic web이란 웹에 존재하는 수 많은 웹페이지들에 메타데이터를 부여하여, 기존의 잡다한 데이터 집합이었던 웹페이지를 '의미'와 '관련성'을 가지는 거대한 데이터베이스로 구축하고자 하는 발상이다.
HTML element는 의미론적으로 봤을 때, 두 종류의 element로 나뉜다.
non-semantic element: content에 대하여 어떤 설명도 하지 않는 element이다. div, span 등semantic element: content의 의미를 명확히 설명하는 element이다. form, table, img 등
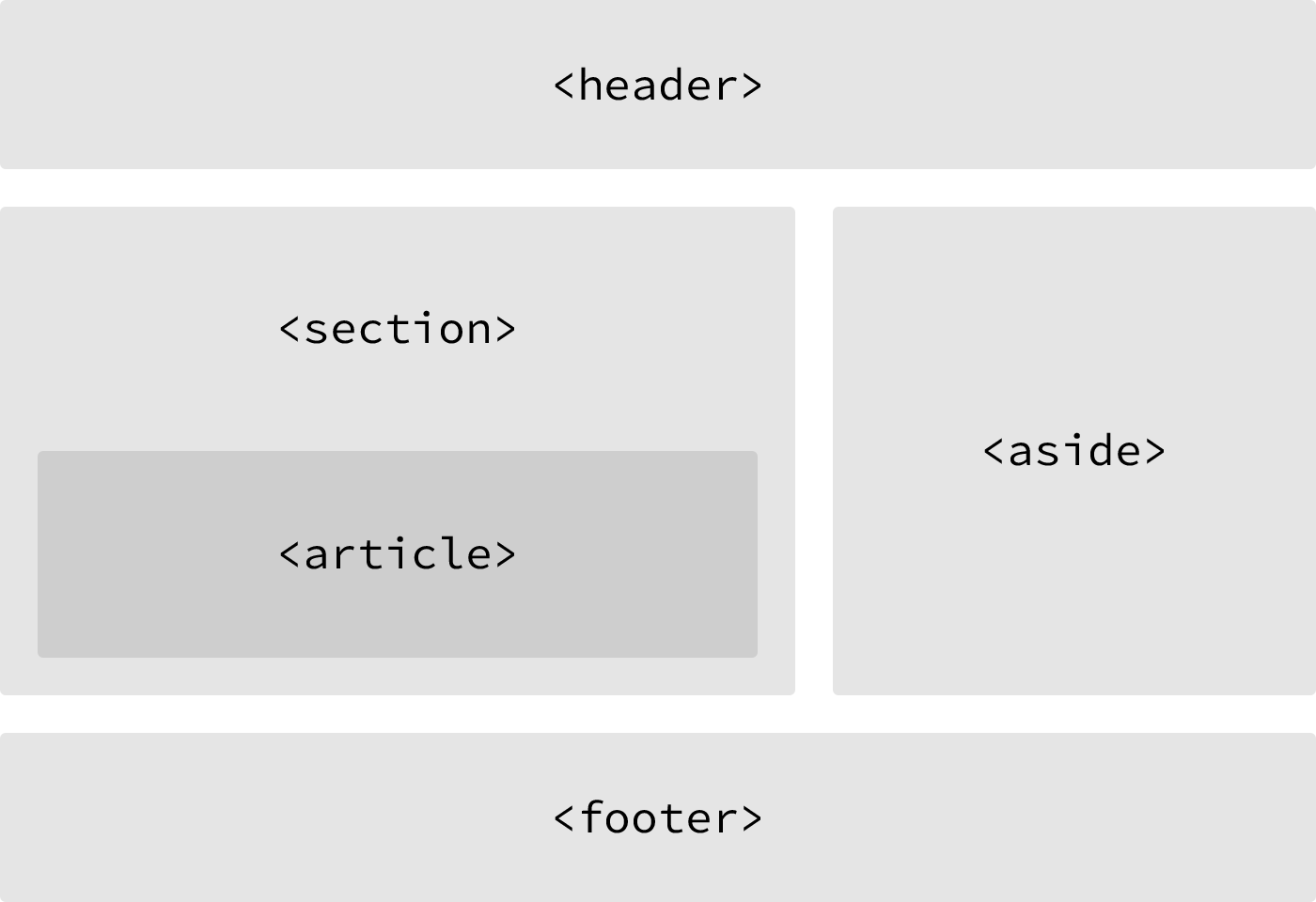
HTML5에는 새롭게 추가된 semantic tag들이 있다.
header: 헤더를 의미한다.nav: 내비게이션을 의미한다.aside: 사이드에 위치하는 공간을 의미한다.section: 본문의 여러 article을 포함하는 공간을 의미한다.article: 본문의 주 내용이 들어가는 공간을 의미한다.footer: 꼬릿말을 의미한다.
참고문헌
