서론
도입하게 된 계기
- 프로젝트에서는 하나의 서버와 하나의 DB로 구성이 되어있다.
- 하나의 DB에서 CRUD 연산 작업을 모두 수행하고 있다.
- 본능적으로 뭔가 위험해 보인다고 생각은 하긴 했다…
본론
DB를 1개 이상 더 만들자
- DB가 1개 뿐이라 고장이 나면 전체 서비스가 마비가 되는 것을 단일 장애점(Single Point of Failure, SPOF)라고 부른다.
- 그래서 저는 생각했습니다. 하나뿐인 DB가 문제가 생겨서 서비스를 할 수 없다면 2개 이상에 DB를 두어 1대가 고장 났을 때 다른 1대로 운영을 하게 만드는 건 어떨까 생각했다.
- 즉, 2대라면 1개는 운영용 DB 1개는 예비용 DB로 운영용 DB가 문제가 생겼을 때 빠르게 예비용 DB로 바꾸는 것이다.
- 우리는 위와 같은 장비를 추가하여 확장하는 방식으로 스케일 아웃이라고 한다.
- 위와 같은 데이터 복제를 MySQL, MariaDB에서는 Replication이라는 것으로 지원을 해준다. 아래는 그에대한 내용이다.
DB Replication이란?
- 두 개의 이상의 DBMS 시스템을 1개의 Mater와 N개의 Slave로 나눠서 동일한 데이터를 저장하는 방식이다.
DB Replication의 목적
- 데이터베이스 리플리케이션은 기본적으로 데이터 안정성을 위함입니다.
- 어떠한 원인으로 인해 데이터가 손상되었을 때, 가장 기초적인 대처는 가장 최신의 백업본을 복구하여 사용하는 것입니다.
- 리플리카 서버는 ‘아주 약간의 딜레이가 있긴 하지만’ 거의 실시간으로 마스터 서버와 동일한 데이터를 갖고 있기 때문에, 장애 복구 시 데이터 소실이 최소화됩니다.
- 리플리카 서버는 마스터 서버로 승격이 가능하기에, 마스터 서버로 승격시켜 기존 마스터 서버를 대체하는 방식으로 복구가 진행됩니다.
- 리플리카 서버를 마스터 서버로 승격한 후, 이 새로운 마스터 서버에 대한 리플리카 서버를 생성하면 복구가 완료됩니다.
DB Replication 동작 원리
- Replication은 기본적으로 비동기 복제 방식을 사용하고 있습니다.
- Master 노드에서 변경되는 데이터에 대한 이력을 로그에 기록하면 Relication Master Thread가 비동기적으로 이를 읽어서 Slave쪽으로 전송하여 반영한다.
DB Replication 처리 방식
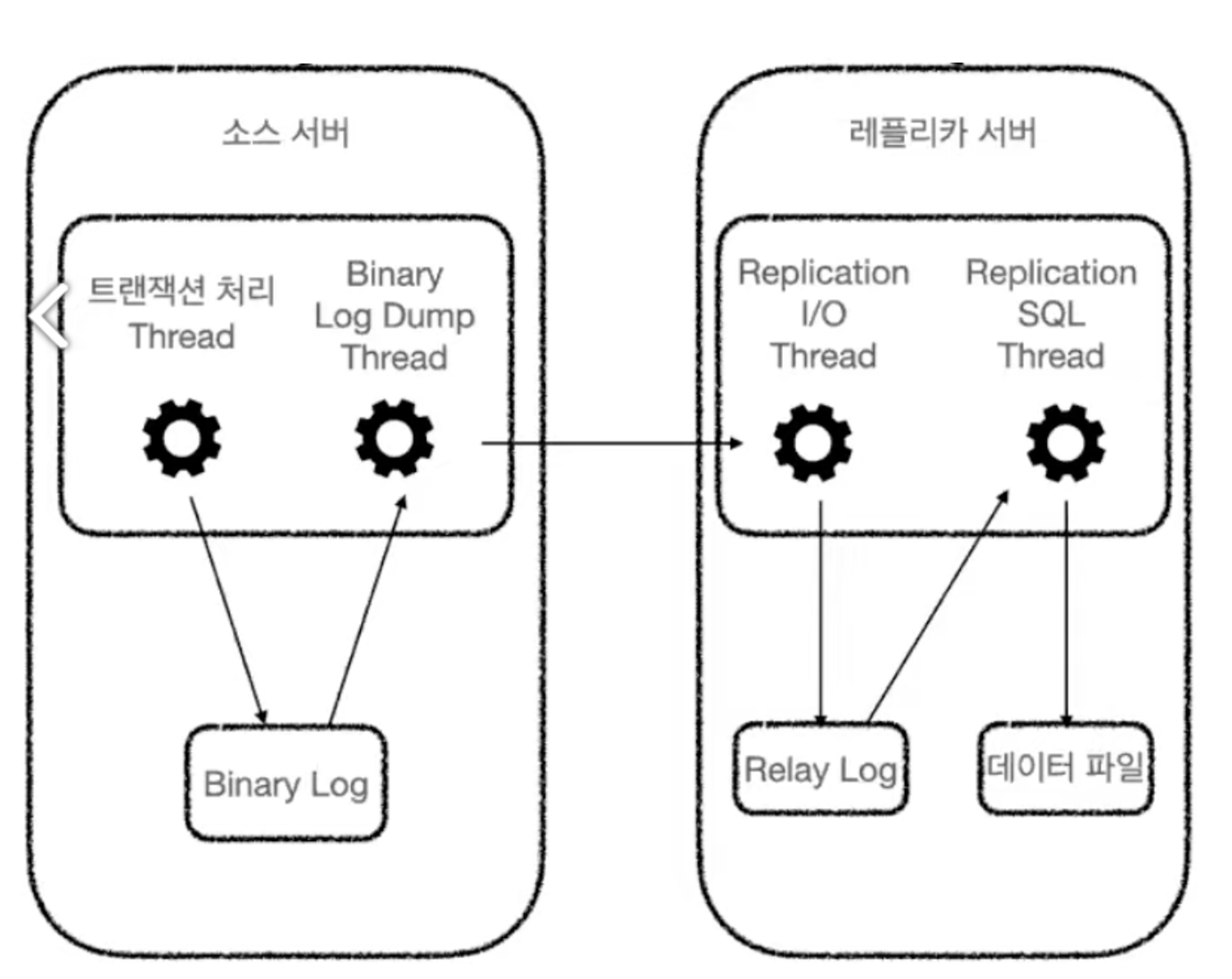
- Binary Log Dump Thread
- 이 스레드는 소스(마스터) 서버에서 실행되며, 바이너리 로그(binlog)를 레플리카(슬레이브) 서버로 전송하는 역할을 한다.
- 레플리카 서버가 소스 서버에 연결되면 소스 서버에서 내부적으로 이 스레드를 생성한다.
- Replication I/O Thread
- 레플리카 서버에 존재하며, 소스 서버에서 전송된 바이너리 로그 이벤트를 가져와서 레플리카 서버의 로컬 파일(릴레이 로그)로 저장하는 역할을 한다.
- 복제가 시작될 때 이 스레드가 생성되고, 복제가 종료되면 스레드가 종료된다.
- Relay Log
- 레플리카 서버가 소스 서버로부터 받은 바이너리 로그 이벤트를 파일로 저장한 것이다.
- Replication SQL Thread
- 레플리카 서버에 존재하며, 릴레이 로그 파일에 저장된 이벤트들을 읽고 실행하여 데이터베이스의 상태를 소스 서버와 동일하게 유지한다.
바이너리 로그(binlog) 란?
- 바이너리 로그는 MySQL(MariaDB)에서 데이터 변경을 기록하는 시스템으로, 모든 변경사항(DDL, DML)을 순서대로 추적한다.
- 이 로그는 데이터 복제 및 복구를 위해 사용되며, 시스템의 데이터 변경 이력을 추적하는 데에도 활용된다.
- 바이너리 형식으로 저장되어 효율적인 데이터 관리를 가능하게 하며,
mysqlbinlog와 같은 도구를 통해 관리된다.
DB Replication의 장점
- 가용성 향상
- 주 데이터베이스에 문제가 생겼을 때, 복제된 데이터베이스(슬레이브)를 이용해 서비스를 지속할 수 있다.
- select 성능 향상
- 대게 read 작업은 자원을 많이 소비 합니다. Replication을 구성하면 N개의 Slave를 가질 수 있기 때문에 Read에 대한 부하가 그만큼 분산 된다.
- 데이터 백업
- Master의 내용을 복제하기 때문에 데이터 베이스를 지워 먹는다고 하더라도 Slave 중 하나를 Master로 활용하면 되기 때문에 데이터를 백업하는 용도로도 사용할 수 있다.
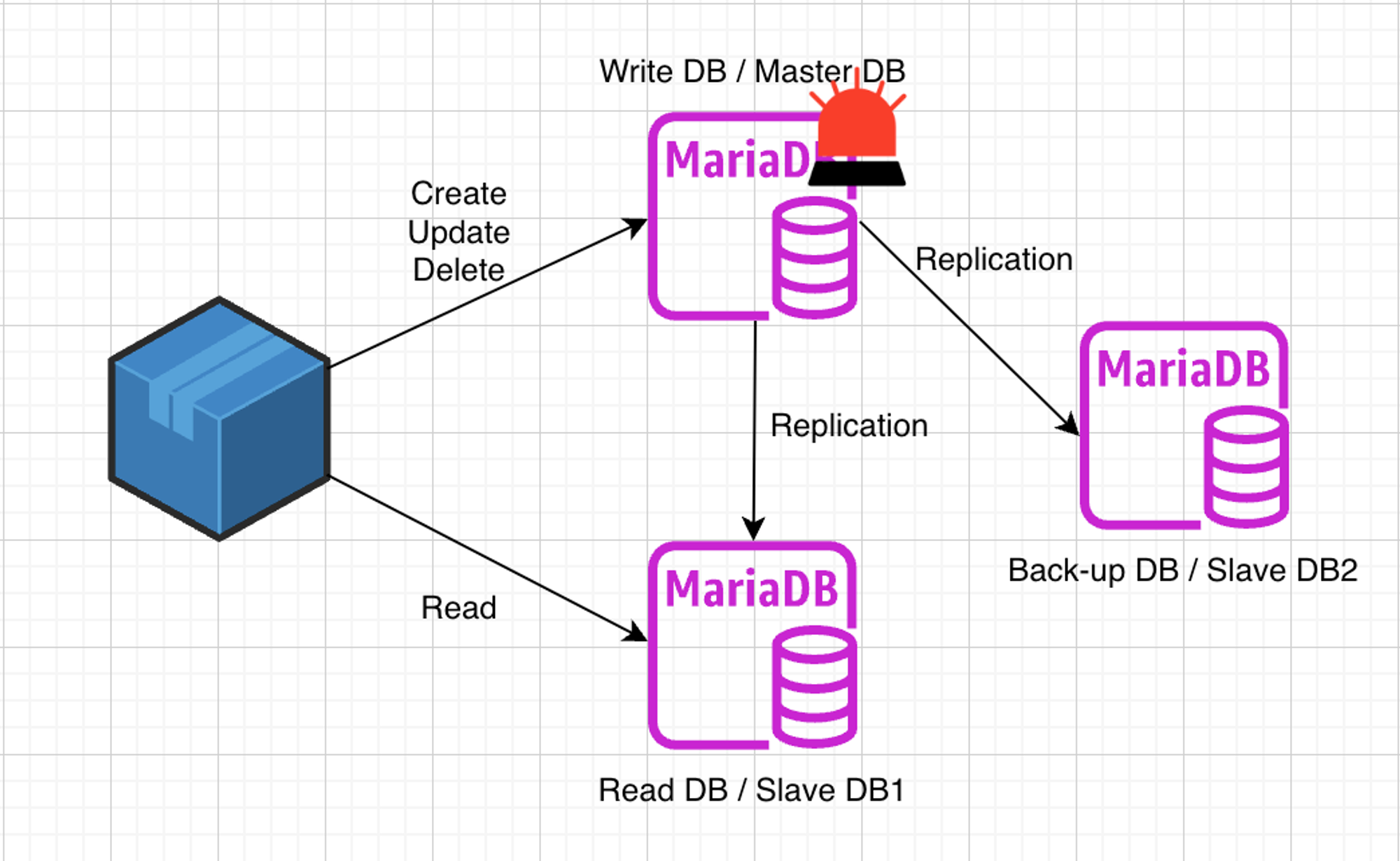
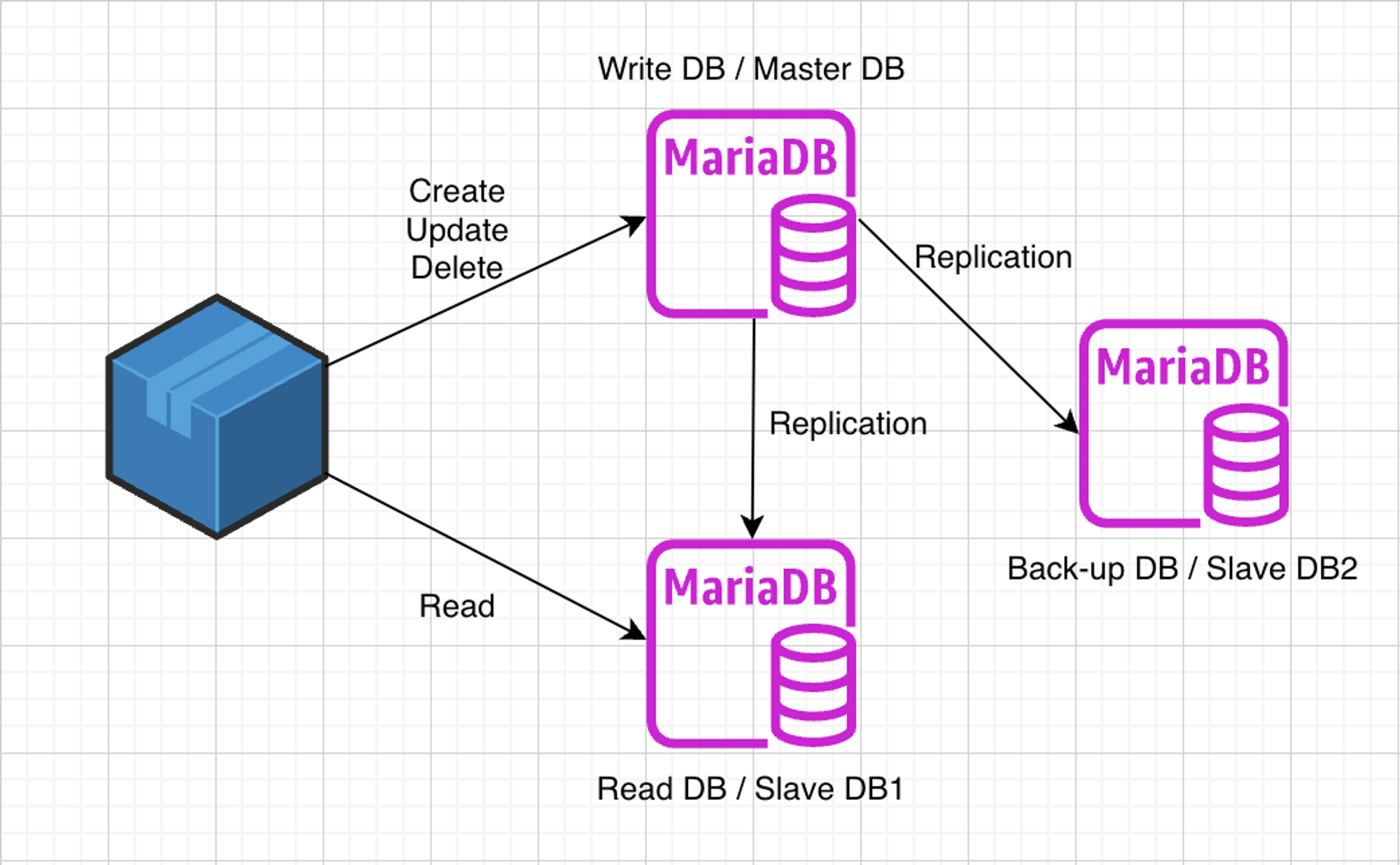
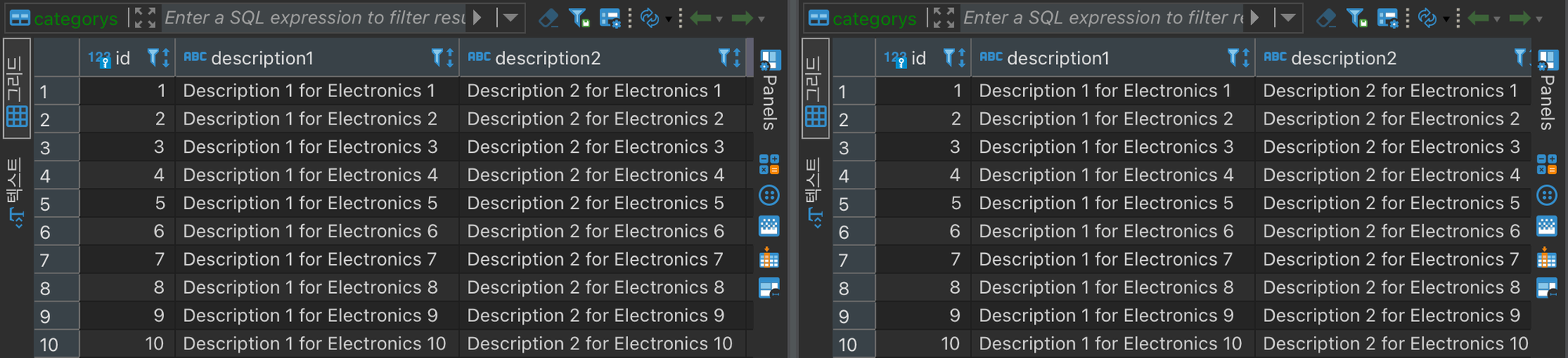
DB Replication 응용
- 나는 아래와 같은 아키텍처로 구상할 것이다. 그 이유를 설명하겠다.
- 데이터베이스 복제(Database Replication)를 활용하여 CQRS(Command Query Responsibility Segregation) 패턴을 적용한 구조를 보여주고 있다.
- 이러한 구조를 만든 이유는 CUD와 R에 대해 분리해 부하를 분산시킬 수 있기 때문이다.
- 그리고 Write, Read DB 두개 중 하나라도 고장이 난자면 나머지 한 곳으로 트래픽을 감당하기 어렵기 때문에 백업용 DB를 승격시키는 것도 고려하였다.
- 이러한 형태를 멀티 레플리카 복제 구성이라고 한다.
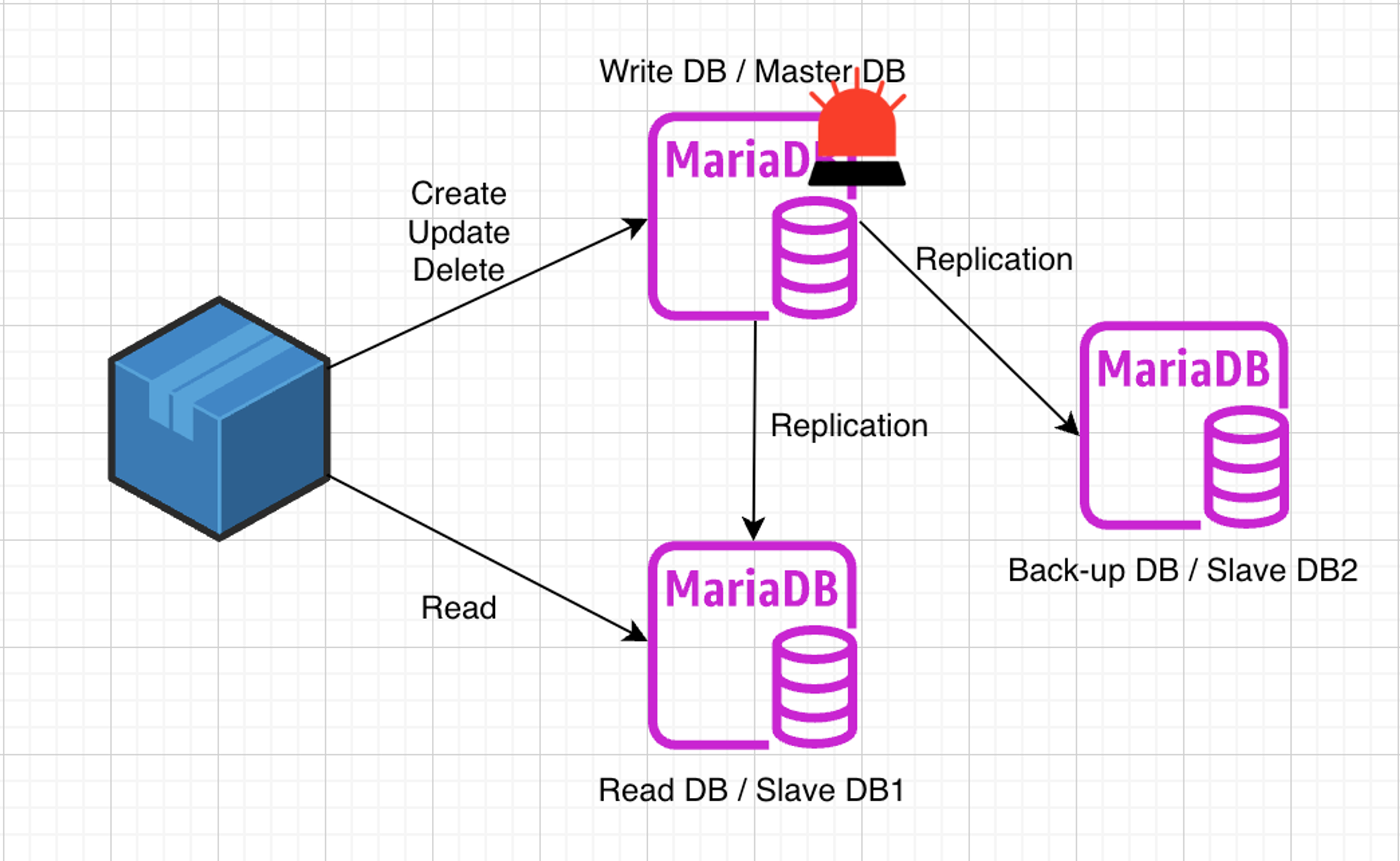
1개의 Master DB, 2개의 Slave DB
- 프로젝트 구조 및 버전
- Docker
- MariaDB 11.0.1
- 기본적으로 도커로 이미지를 내려받고 컨테이너를 실행하였다. 총 3개 (1 + 2)
docker container run -d -p 3306:3306 -e MYSQL_ROOT_PASSWORD=6548 --name dockerMariadb1 mariadb docker container run -d -p 3307:3306 -e MYSQL_ROOT_PASSWORD=6548 --name dockerMariadb2 mariadb docker container run -d -p 3308:3306 -e MYSQL_ROOT_PASSWORD=6548 --name dockerMariadb3 mariadb - MasterDB Setting
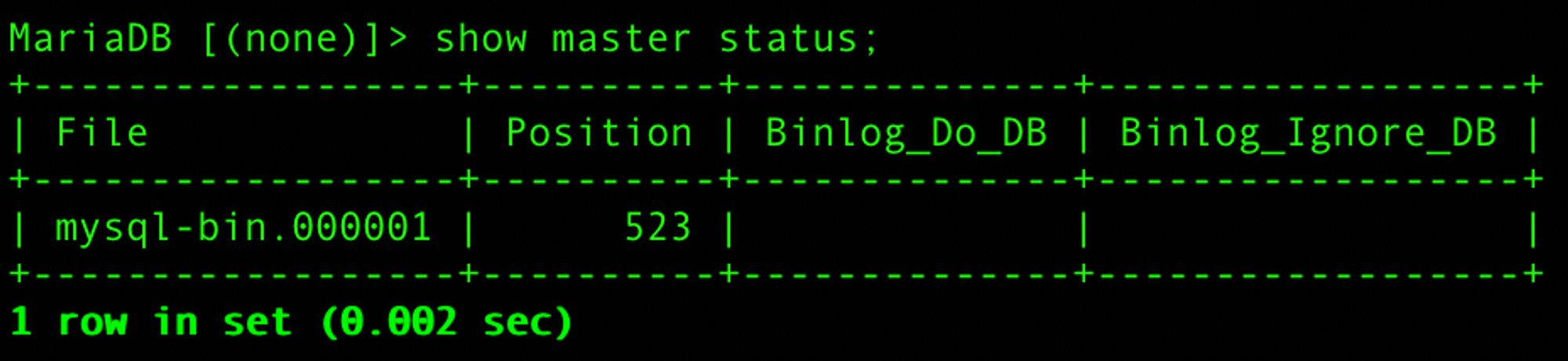
docker exec -it dockerMariadb1 /bin/bash apt update; apt install vim; vi /etc/mysql/my.cnf // 밑에서 추가될 부분 설명 docker restart dockerMariadb1 docker exec -it dockerMariadb1 /bin/bash mariadb -u root -p grant replication slave on *.* to 'repl_user'@'%' identified by 'p@ssw0rd'; show master status;vi /etc/mysql/my.cnf→ 제일 밑에 추가하기[mysqld] log-bin = mysql-bin server-id = 1 binlog_format = row expire_logs_days = 2grant replication slave on *.* to 'repl_user'@'%' identified by 'p@ssw0rd';grant replication slave:REPLICATION SLAVE권한을 부여한다. 이 권한은 레플리카(슬레이브) 서버가 마스터 서버로부터 데이터를 복제하는 데 필요하다.on *.*: 모든 데이터베이스의 모든 테이블에 대해 권한을 부여한다.to 'repl_user'@'%':repl_user라는 사용자 이름으로 어떤 호스트(%)에서든지 연결을 허용한다.%는 모든 호스트를 의미하는 와일드카드이다.identified by 'p@ssw0rd':repl_user의 비밀번호를p@ssw0rd로 설정한다.
show master status;→ MariaDB에서 현재 마스터 서버의 복제 상태를 보여주는 명령이다.
- Slave1,2 Setting
docker exec -it dockerMariadb2 /bin/bash apt update; apt install vim; vi /etc/mysql/my.cnf // 밑에서 추가될 부분 설명 docker restart dockerMariadb2 docker exec -it dockerMariadb2 /bin/bash mariadb -u root -p CHANGE MASTER TO MASTER_HOST = '123.45.6.7' , MASTER_PORT=3306 , MASTER_USER='repl_user' , MASTER_PASSWORD='p@ssw0rd' , MASTER_LOG_FILE='mysql-bin.000001' , MASTER_LOG_POS=523 , MASTER_CONNECT_RETRY=10; start slave; SHOW SLAVE STATUS\G;vi /etc/mysql/my.cnf→ 제일 밑에 추가하기[mysqld] log-bin = mysql-bin server-id = 2 // Slave2는 3으로 두면 된다. binlog_format = row expire_logs_days = 2 read_only = 1 // Slave DB는 읽기만 처리하므로 Read_Only로 둔다.CHANGE MASTER ~~~- `MASTER_HOST = '123.45.6.7'` → 마스터 서버의 호스트 주소이다.
MASTER_PORT = 3306→ 마스터 서버가 리스닝하고 있는 포트 번호이다.MASTER_USER = 'repl_user'→ 복제를 위해 사용될 마스터 서버의 사용자 계정 이름이다.MASTER_PASSWORD = 'p@ssw0rd'→ 위 사용자 계정의 비밀번호이다.MASTER_LOG_FILE = 'mysql-bin.000001'→ 복제를 시작할 마스터 서버의 바이너리 로그 파일 이름이다. show master status;로 확인한 값이다.MASTER_LOG_POS = 523→ 바이너리 로그 파일 내에서 복제를 시작할 위치(오프셋)이다. show master status;로 확인한 값이다.MASTER_CONNECT_RETRY = 10→ 연결 실패 시 재시도할 시간 간격(초)이다. 이 경우, 레플리카는 연결 실패 후 10초마다 마스터 서버에 재연결을 시도한다.
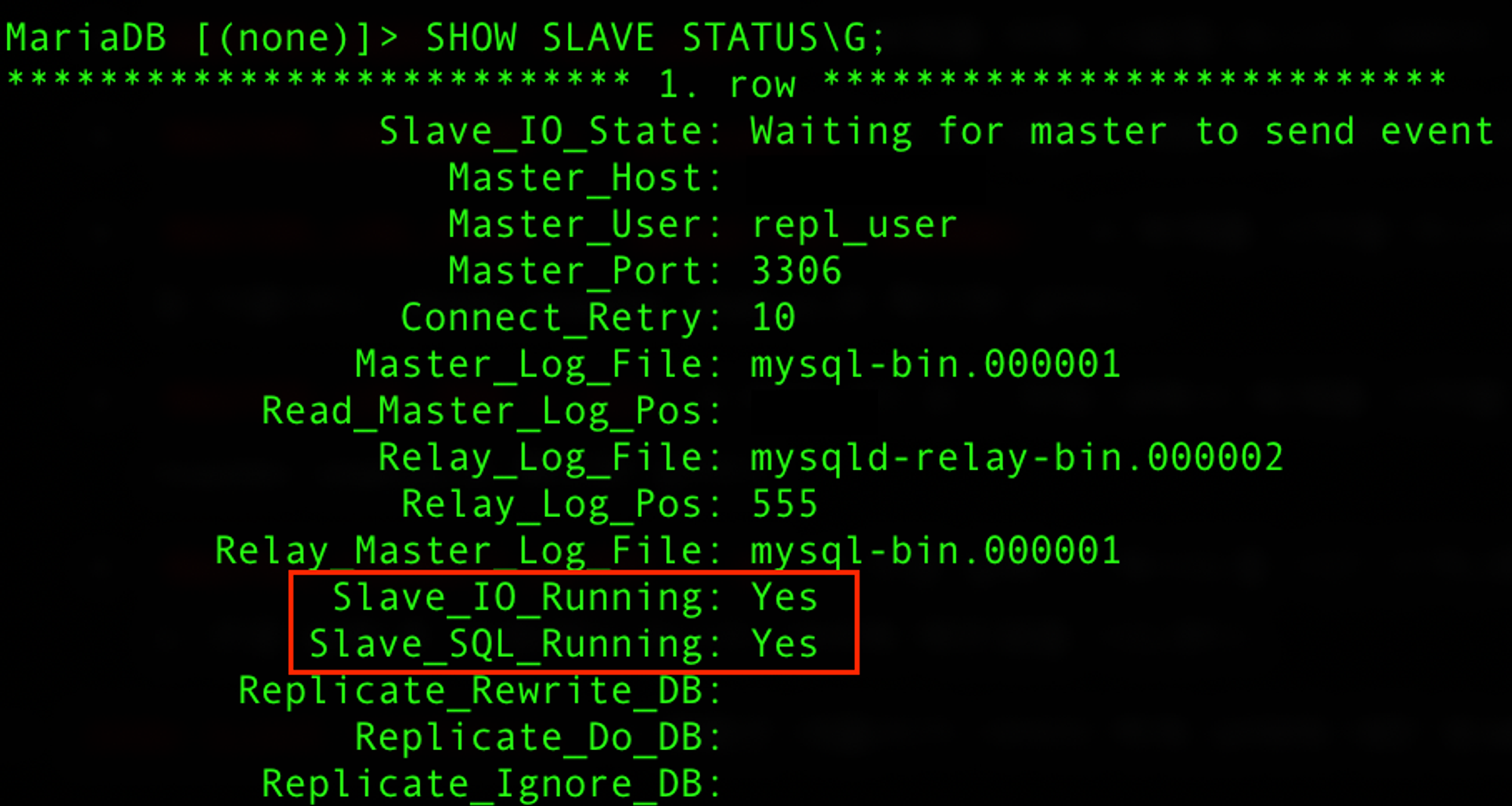
SHOW SLAVE STATUS\G;→ 명령은 레플리카 서버의 복제 상태에 대한 정보를 보여준다.
- Slave_IO_Running, Slave_SQL_Running 두가지 모두 Yes로 뜨면 성공적으로 Master와 연결된 것이다.
실제 복제 테스트
- 실제로 Master DB에 Dummy Data 몇개를 넣어서 테스트를 진행해보겠다.
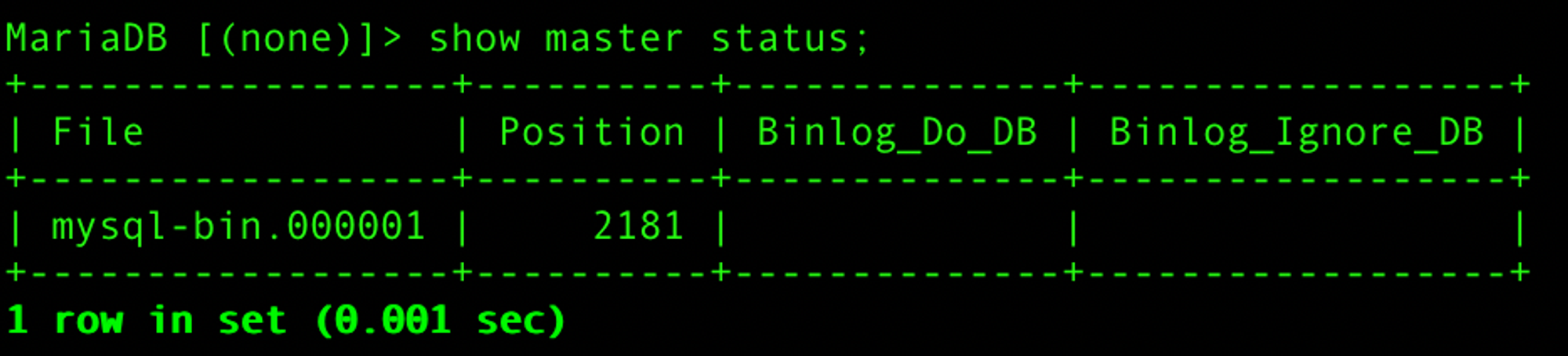
- 몇개 정도 데이터를 넣어두고 Master DB에 상태를 다시금 확인해 보았다.
- 확인해보니 Position에 값이 증가한걸 볼수 있다.
- 여기서 Position은 바이너리 로그 파일(mysql-bin.000001) 내에서의 위치를 나타낸다.
- 즉, 이 숫자(2181)는 바이너리 로그 파일 내에서 변경 사항이 기록된 지점의 바이트 오프셋을 의미한다.
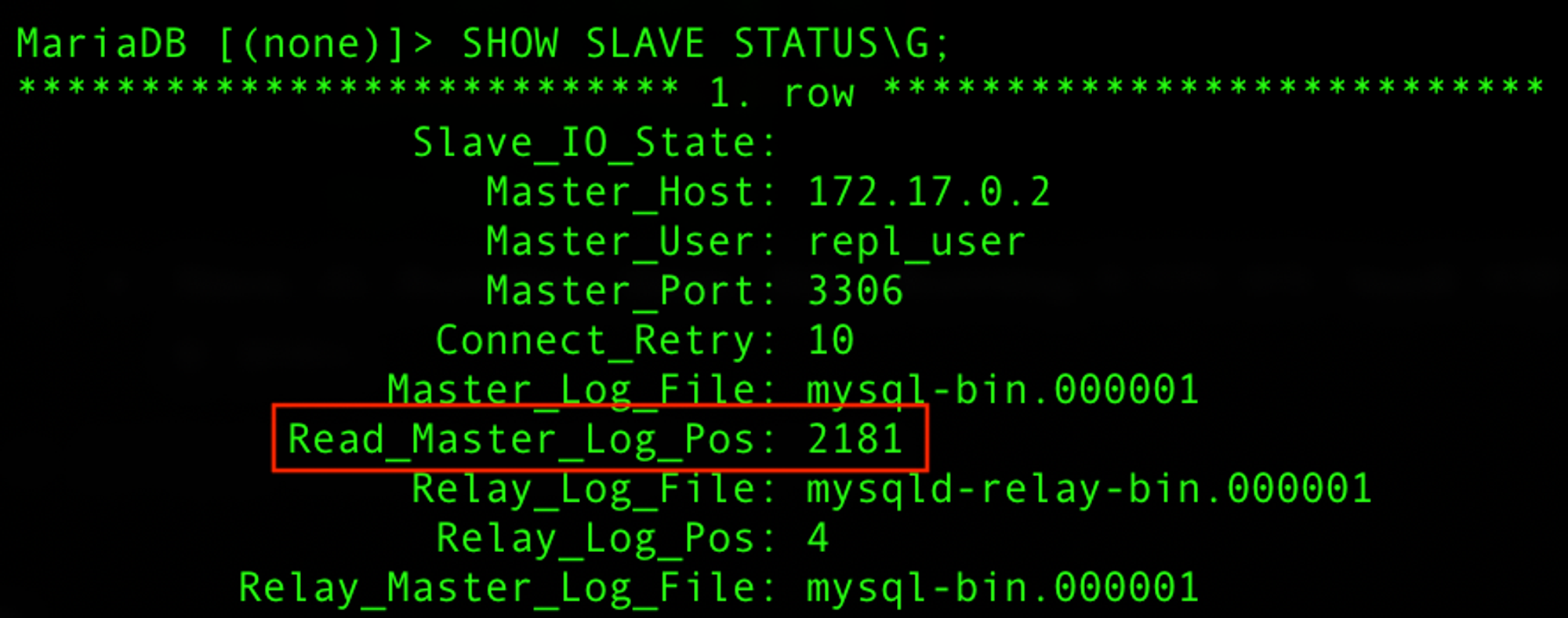
- 또한 Slave DB도 상태를 확인해보았다.
- 동일하게 Master DB와 똑같이 증가하여 동일한 숫자를 나타내고 있다.
- 물론 Position이 동일한 값이라도 직접 데이터로 확인해보겠다.
- 위와 같이 동기화가 잘 된 것을 확인할 수 있다.
바이너리 로그 파일 위치 기반 복제 (우리가 진행한 방식)
- 설명 중간에 내가 이런말을 한적이 있을 것이다. “바이너리 로그 파일 내에서 변경 사항이 기록된 지점의 바이트 오프셋” 이라고 해당 문장은 다음과 같은 뜻을 가지고 있다.
- 레플리카 서버에서 소스 서버의 바이너리 로그 파일명과 파일 내에서의 위치(Offset 또는 Position)로 개별 바이너리 로그 이벤트를 식별해서 복제가 진행되는 형태이다.
- 바이너리 로그 파일 위치 기반 복제에서는 이벤트 하나하나를 소스 서버의 바이너리 로그 파일명과 파일 내에서의 위치 값(File Offset)의 조합으로 식별한다. EX) 파일명(mysql-bin.000001) + 파일 오프셋(2181)
- 바이너리 로그 파일 위치 기반 복제에서는 모든 MySQL 서버들이 고유한 server-id 값을 가지고 있어야 한다.
- 그렇기에 Master는 대게 1이고, 나머지 Slave는 2, 3, 4 등등 고유한 값을 가지고 있다.
바이너리 로그 파일 위치 기반 복제의 문제점
- 밑과 같은 상황이 발생했다고 가정해보자
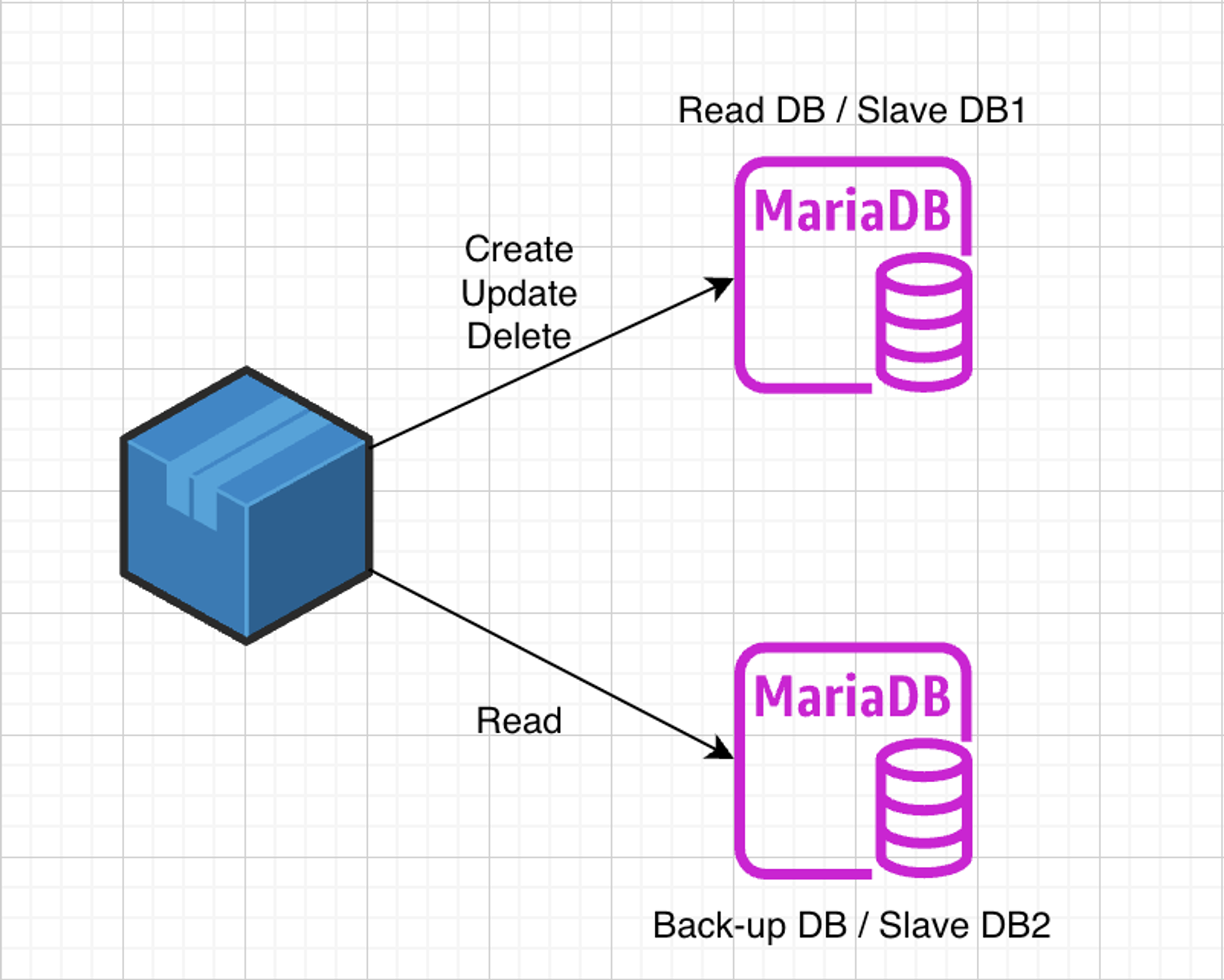
- 지금 Master DB에 문제가 생겨 Slave DB1을 Master DB로 승격시키고, Slave DB2를 Slave DB1이 했던 역할을 해야하는 상황이다.
- 지금 Master DB에 문제가 생겨 Slave DB1을 Master DB로 승격시키고, Slave DB2를 Slave DB1이 했던 역할을 해야하는 상황이다.
- 우리는 기존에 해왔던 방식인 Master DB에서 바이러니 로그 파일명과 파일 오프셋을 가지고 마이그레이션을 진행하려고 했다.
- 근데 큰 문제가 생겼다.
- 우리가 백업용(예비용)으로 두었던 DB는 Master DB와 Replication이 30분 늦고 있었던 것이었다.
- Slave DB1은 DB 스펙이 좋아 동기화를 잘 해주고 있었지만, 백업용(예비용) DB는 당연 백업용이라 스펙이 낮은 상태라 Replication이 30분이나 뒤쳐지고 있었다.
- 이게 왜 큰 문제인지 의아해 할 수 있을 것이다. 우리는 기존 사용했던 방식인 바이너리 로그 파일 위치 기반으로 해도 되지 않을까라는 생각을 할 것이다.
- 우리가 사용하던 Master DB에서는 이제 서버가 Shut Down된 상태이고 만일 접속한다고 하더라도 명령어 입력에 꽤나 오랜 시간이 걸릴 것이다.
- 그래서 Slave DB1은 이미 완벽하게 동기화가 완료된 상태이니, Slave DB1에 바이러니 로그를 확인하여 Slave DB2로 마이그레이션 하는 것이 어떤가 생각해보았다. → 바이너리 로그 파일 위치 기반 복제
- 위 방식은 내 머리속에 나온 구상이었고, 이 방식은 도입이 절대 불가능하다…
- 왜냐하면 Master DB에 대한 동일한 이벤트를 처리한다고 해서 레플리카(Slave1, Slave2)에서도 동일한 파일, 동일한 위치에 저장된다는 보장이 없기 때문이다. →
Real MySQL 8.0책에 나온 구문입니다.
- 따라서 위 내용을 종합하자면 Master DB가 사용할수 없는 경우 Slave DB1을 Master DB로 승격하는 것은 가능하나 Slave DB2가 아직 완벽한 동기화가 안 된 상태에서 Master DB가 아닌 Slave DB1에 대한 바이러니 로그로 Replication을 할순 없다.
- 위에 대한 단점을 보안하기 위해 등장한 것이 글로벌 트랜잭션 ID 기반 복제이다.
Global Transaction IDentifier (GTID)
- 레플리케이션에 참여하고 있는 모든 서버들이 이벤트에 대해 동일한 식별자를 가지도록 하는 방식이이다.
- 이때 이벤트에 부여된 식별자를 GTID(Global Transaction IDentifier)라고 한다.
- GTID를 사용하면 위와 같은 장애 상황에서 GTID를 통해 이벤트를 식별할 수 있으므로, 새로운 소스 서버로부터 레플리카가 곧바로 동기화를 시작할 수 있게 된다.
- GTID를 사용하게 되면 아래와 같이 바이러니 로그 파일명, 오프셋은 다르지만 모든 DB에 GTID가 동일한 것을 볼 수 있다.
- Master DB
GTID 바이너리 로그 파일명 바이너리 로그 오프셋 0-0-1 binart-log.000001 232 0-0-2 binart-log.000001 444 0-0-3 binart-log.000001 1023 - Slave DB1
GTID 바이너리 로그 파일명 바이너리 로그 오프셋 0-0-1 binart-log.000002 40230 0-0-2 binart-log.000002 41232 0-0-3 binart-log.000002 49801 - Slave DB2
GTID 바이너리 로그 파일명 바이너리 로그 오프셋 0-0-1 binart-log.000003 123456 0-0-2 binart-log.000003 162331 0-0-3 binart-log.000003 190021
- Master DB
- 우리는 이제 Master DB가 사용하지 못하더라도 Slave DB1에 GTID 값으로 Slave DB2에 대해서 Replication이 가능한 상태로 만들수 있다. 물론 동기화 즉시 자동으로 마이그레이션이 된다.
1개의 Master DB, 2개의 Slave DB (GTID)
- 검색해보면 알겠지만 MySQL에 대한 래퍼런스는 정말 많은데..MariaDB에 대한 래퍼런스는 정말 없다..꽤나 고생을 했다.
- 역시 이렇게 래퍼런스가 없을 땐, 공식 문서만한게 없다!! 공식 문서가 정말 친절하게 잘 나와있어서 그나마 영어만 해석하면 금방 풀 수 있을 것이다.
- 우리가 해야할 Task들을 미리 정리해두고 시작해보자.
- Master DB가 문제가 있으니 Slave DB1, Slave DB2 둘다 Master DB 와의 연결을 끊는다.
- Slave DB1이 이제 Master DB로 승격이 되니 my.cnf 파일에
read_only = 1를 삭제한다. - 설정파일을 건들였으니 Docker Container를 재시작한다.
- Master DB로 승격된 Slave DB1에서 GTID를 찾고 Slave DB를 등록하기 위해 권한 부여를 해준다.
- Master DB로 승격된 Slave DB1에 GTID를 확인한다. (확인용)
- Slave DB가 Master DB에 연결할 수 있게 Master DB에 대한 정보를 입력한다.
- Slave DB를 시작하고 Replication이 되었는지 확인한다.
- Master DB가 문제가 있으니 Slave DB1, Slave DB2 둘다 Master DB 와의 연결을 끊는다.
- Slave DB1, Slave DB2에 각각
Stop Slave;를 입력한다.
- Slave DB1, Slave DB2에 각각
- Slave DB1이 이제 Master DB로 승격이 되니 my.cnf 파일에
read_only = 1를 삭제한다.- 기존에 아래와 같이 작성했던 부분에서 마지막 줄인 read_only만 삭제해준다.
[mysqld] log-bin = mysql-bin server-id = 2 // Slave2는 3으로 두면 된다. binlog_format = row expire_logs_days = 2 read_only = 1 // Slave DB는 읽기만 처리하므로 Read_Only로 둔다. - 물론 Slave DB2는 read_only로만 사용할거기에 가만 두어도 된다.
- 기존에 아래와 같이 작성했던 부분에서 마지막 줄인 read_only만 삭제해준다.
- 설정파일을 건들였으니 Docker Container를 재시작한다.
Docker Restart “도커 컨테이너 이름”으로 재시작해준다.
- Master DB로 승격된 Slave DB1에서 GTID를 찾고 Slave DB를 등록하기 위해 권한 부여를 해준다.
grant replication slave on *.* to 'repl_user'@'%' identified by 'p@ssw0rd';→ 기존 사용했던 Master DB와 동일한 권한으로 진행하였다. 이건 사용하기 나름이다.- 즉시 적용을 위해
FLUSH PRIVILEGES;를 입력해준다.
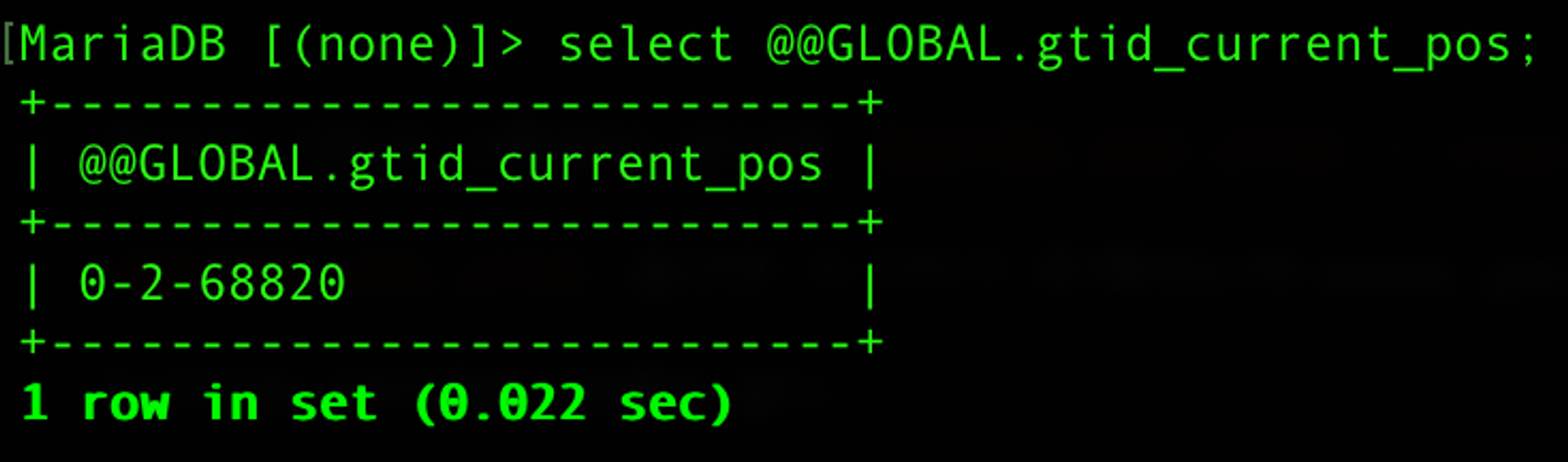
- Master DB로 승격된 Slave DB1에 GTID를 확인한다. (확인용)
- Master DB로 승격된 Slave DB1에서
select @@GLOBAL.gtid_current_pos;GTID를 찾아준다.
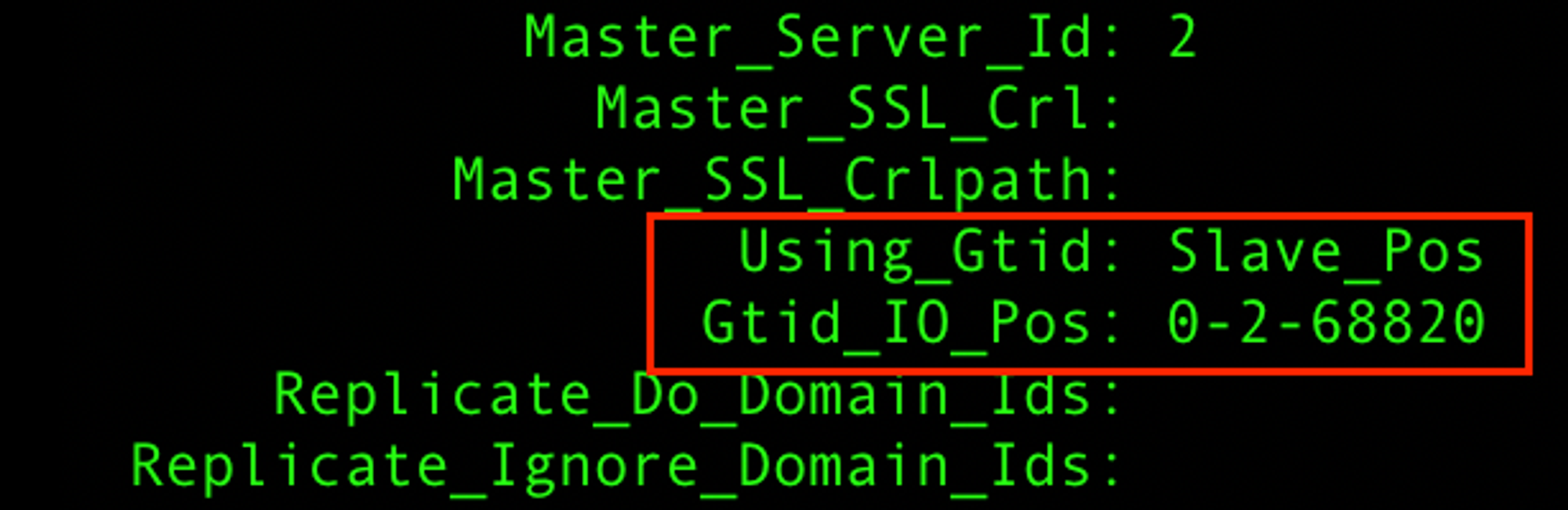
- Master DB로 승격된 Slave DB1에서
- Slave DB가 Master DB에 연결할 수 있게 Master DB에 대한 정보를 입력한다.
- 위에서 권한을 부여한대로 입력해준다.
CHANGE MASTER TO MASTER_HOST = '172.17.0.3' , MASTER_PORT=3306 , MASTER_USER='repl_user' , MASTER_PASSWORD='p@ssw0rd' , MASTER_USE_GTID = slave_pos; - 여기서 기존과 다른점이 있다면
MASTER_USE_GTID = slave_pos;이다. MASTER_USE_GTID옵션은 두가지가 존재하는데 slave_pos, current_pos이 있다.- 두가지의 차이점은 아래와 같다.
- slave_pos
- 용도 : slave_pos는 레플리카가 자신이 마지막으로 처리한 GTID 위치에서 복제를 재개하도록 설정한다.
- 적용 상황 : 이 옵션은 기존 레플리카가 중단되었다가 다시 시작할 때 유용하다. 이는 레플리카가 마지막으로 처리한 위치를 기반으로 이후의 변경사항을 계속해서 복제하게 한다.
- 동작 방식 : 레플리카는 자신의 GTID 위치를 기반으로 마스터와 동기화하며, 이전에 복제하지 않은 트랜잭션부터 복제를 시작한다.
- current_pos
- 용도: current_pos는 레플리카가 마스터의 현재 GTID 위치에서 복제를 시작하도록 설정한다.
- 적용 상황 : 이 옵션은 마스터의 최신 상태를 복제하고 싶을 때 사용된다. 예를 들어, 새 레플리카를 설정하거나 기존 레플리카를 마스터의 현재 상태와 동기화하고자 할 때 유용하다.
- 동작 방식 : 레플리카는 마스터의 현재 GTID 위치로부터 시작하여, 이후 발생하는 모든 변경사항을 복제합니다.
- slave_pos
- 따라서 우리는 처음부터 다 복사할것이 아니라 slave_pos로 설정해두었다.
- 위에서 권한을 부여한대로 입력해준다.
- Slave DB를 시작하고 Replication이 되었는지 확인한다.
start slave;로 시작하고SHOW SLAVE STATUS\G;로 확인해보았다.
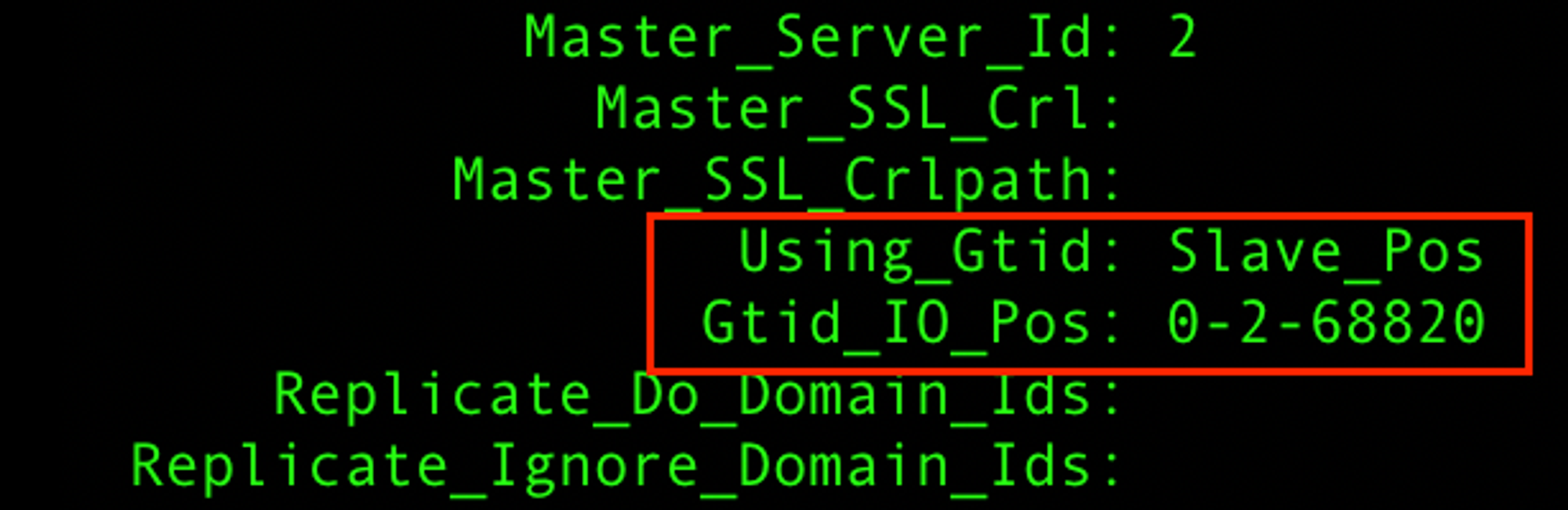
- 위에 Master DB에서 확인했던 GTID 위치로 등록된 걸 확인할 수 있었다.
- 역시나 데이터 마이그레이션도 끊긴 시점부터 잘 된걸 확인할 수 있었다.
결론
어려웠던 점
- MySQL은 책도 많고 래퍼런스도 많아서 금방 따라 했을 것 같은데…MariaDB는 진짜 래퍼런스가 많이 없었다.
- 그래서 공식문서를 파악하고 이해하는데 시간이 꽤나 걸린 것 같다..
다시금 영어공부의 중요성이…😮💨
- 기술 스택을 셀렉할 땐 그 기술 스택에 대한 트레이드 오프와 사이드 이펙트는 무엇이 있는지 잘 알아보고 판단하자..미래의 나야…
후기
- 중간에 글이 길어질까봐 생략한 부분이 있는데 바이너리 로그 파일 위치 기반 복제에서 멈췄을 때 수동으로 복제하는 방법에 대해서 쓸까말까 고민하다가 안 썼다..
- 왜냐하면 더 좋은 방법이 있는데 굳이? 라고 생각했기 때문이다.
- 직접 두 방식 모두 경험해본 바로 수동 복제는 해야할게 너무 많아진다…
- 그리고 힘이 들 땐 언제나 우리와 함께하는 공식 문서를 파악해보자
- 100개의 블로그 글보다 1개의 공식 문서가 더 큰 파급효과를 가져다줄 수도 있다.
- 아마 2부도 있을수도..?

지나가는 개발자