서론
쓰게된 이유
- 원래 2부를 쓸까 말까 하다가 Replication Topology에 대해 설명과 내가 어떤 구조를 왜 선택했는지 쓰면 좋을 것 같아서 쓰게 되었다.
- 아마 긴글이 되진 않을 것 같긴한데, 누군가에게 도움이 됐으면 하는 바람이다.
- 모든 내용은 Real MySQL 8.0(2)에 대한 내용이라 얼추 믿고 봐도..? 되지 않을까 한다.
- 만약 틀린 부분이 있다면 댓글 남겨주세여..ㅎㅎ
본론
Replication Topology
- 싱글 레플리카(Slave) 복제
- 멀티 레플리카(Slave) 복제
- 체인 복제
- 듀얼 소스(Master) 복제
- 멀티 소스(Master) 복제
싱글 레플리카(Slave) 복제
- 싱글 레플리카(Slave) 복제 1
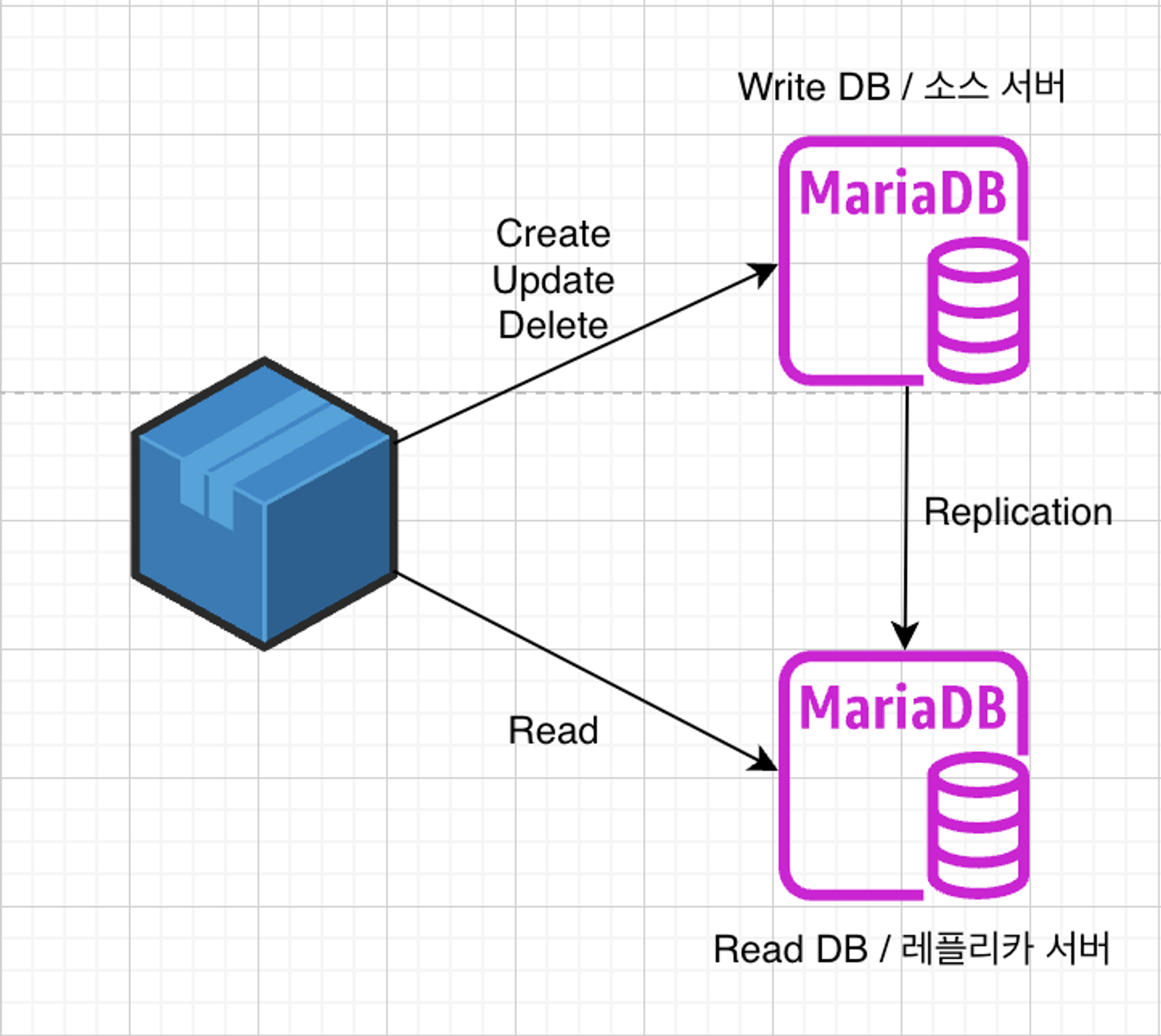
- 싱글 레플리카 복제는 하나의 소스 데이터베이스와 하나 이상의 레플리카 데이터베이스로 구성된다.
- 모든 쓰기 작업은 마스터에서 이루어지고, 슬레이브는 이를 복제받아 읽기 쿼리를 처리한다.
- 장점 : 설정이 간단하며, 데이터 백업과 읽기 부하 분산에 효과적이다.
- 단점 : 마스터 서버에 장애가 발생하면 복제 시스템 전체에 영향을 줄 수 있다.
- 싱글 레플리카(Slave) 복제 2
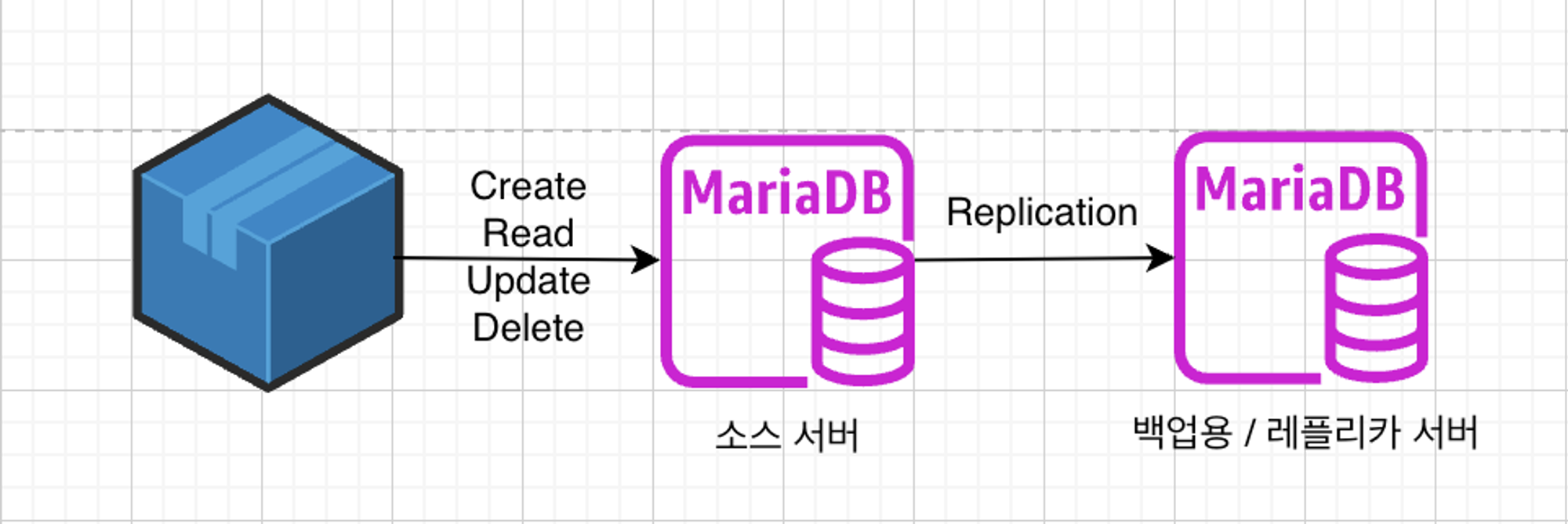
- 싱글 레플리카 복제는 하나의 소스 데이터베이스와 하나 이상의 레플리카 데이터베이스로 구성된다.
- 싱글 레플리카(Slave) 복제 1 처럼 CQRS를 나눈것이 아닌 백업용 레플리카 서버를 따로 두어 에 단점인 단일 장애점(Single Point of Failure, SPOF)을 개선할 수 있다.
- 장점 : 레플리카 서버는 소스 서버에 문제가 발생했을 때 마스터로 승격이 되어 쿼리를 계속 처리할 수 있다.
- 싱글 레플리카(Slave) 복제로 둘거면 백업용으로 레플리카로 구성하는 것이 좋아보인다.
멀티 레플리카(Slave) 복제
- 멀티 레플리카(Slave) 복제
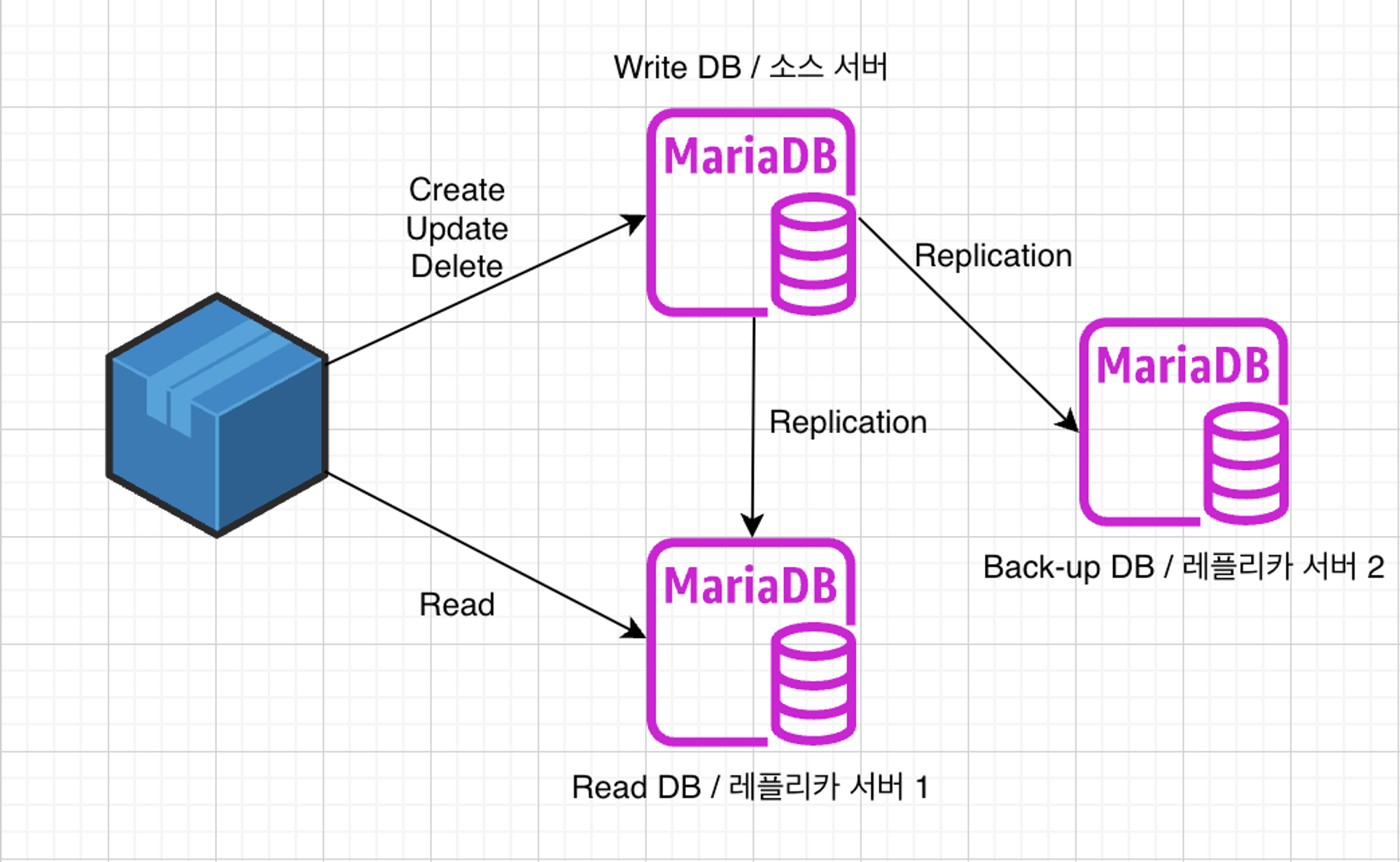
- 멀티 소스 레플리카는 여러 개의 소스 서버로부터 데이터를 복제받는 두개 이상의 레플리카로 구성됩니다.
- 각 소스는 독립적으로 쓰기 작업을 처리하며, 레플리카는 여러 소스로부터 데이터를 복제하여 읽기 요청을 처리합니다.
- 이렇게 읽기와 쓰기를 나눈 것은 대부분의 서비스는 쓰기 작업보다 읽기 작업이 1:9로 많기 때문이다.
- 또한 하나는 백업용으로 두는 것이 운영상 좋은 이점들이 많다. → 소스 서버가 문제가 생겼을 시 소스로 승격이 가능하기 때문이다.
- 복잡한 데이터 흐름과 충돌 해결, 동기화 문제를 관리해야 하며, 싱글 레플리카 복제보다 레플리카 관리가 더 복잡해집니다.
체인 복제
- 체인 복제
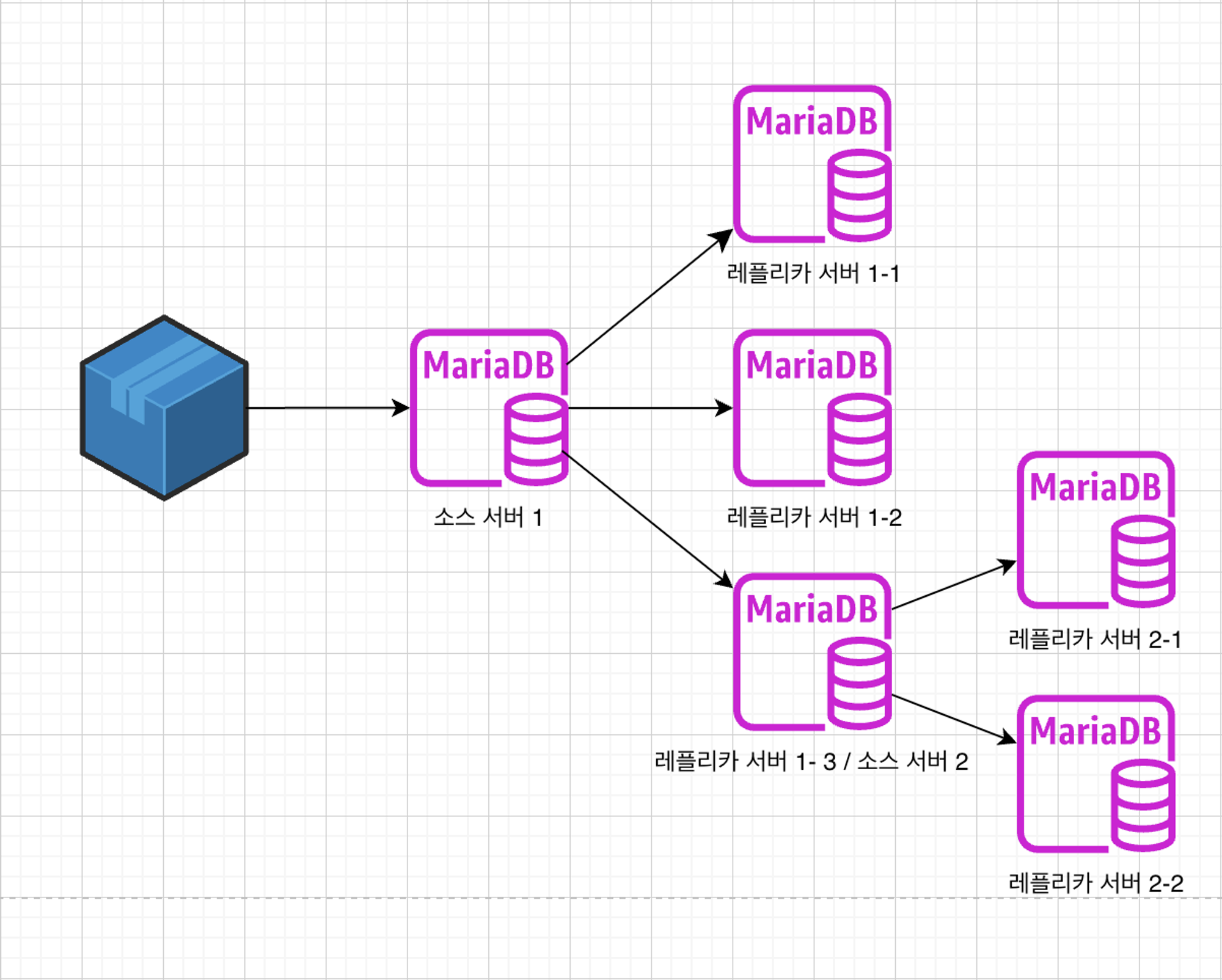
- 이렇게 트리처럼 들어간 레플리카에 대해서는 이유가 있는데, 소스 서버 1이 존재하고 레플리카가 소스 서버 1에 대해 10개 정도 된다고 가정한다면, 소스 서버 1에서 리플리카 서버들로 이벤트를 전송하는 작업 자체가 부하로 작용할 수도 있다.
- 그래서 이러한 사태를 방지하기 위해 트리처럼 깊게 들어간 레플리카를 볼 수 있을 것이다. 체인 복제는 데이터베이스 서버들이 선형적 또는 계층적 체인 구조로 배치되어, 각 서버는 바로 앞의 서버로부터 데이터를 복제합니다.
- 확장성이 좋으며, 데이터 백업 및 복구, 읽기 부하 분산에 유용합니다.
- 체인의 길이가 길어질수록 지연 시간이 증가하고, 체인 중 한 노드에 장애가 발생하면 그 뒤의 노드에 영향을 줍니다.
듀얼 소스(Master) 복제
- 듀얼 소스 복제

- 듀얼 소스 복제는 두 개의 마스터 서버가 서로의 데이터를 복제하는 구조이다.
- 각 마스터는 자신의 쓰기 작업을 처리하면서 동시에 다른 마스터의 데이터도 복제한다.
- 두 마스터 서버 간의 데이터 동기화를 통해 높은 가용성과 데이터의 일관성을 제공한다.
- 데이터 충돌과 복잡성을 관리하기 위한 추가적인 메커니즘이 필요하며, 구성이 복잡해진다.
- 쓰기 성능 개선을 위한 듀얼 소스 복제를 많이 사용한다고?
- 듀얼 소스 복제 구성은 사실 쓰기 성능을 개선하는 용도로는 그다지 효과적이지는 않다고 한다.
- 서로의 쓰기 요청을 자신의 데이터베이스에 반영하는 작업이 발생하기 때문이다.
- 예를 들어 어떤 객체의 ID가 Auto Increment이고 두명이 거의 동시에 저장을 요청했다면, DB에 각각 동일한 ID로 저장이 될테고 복제하는 과정중에 중복키 에러가 발생할 것이다.
- 따라서 쓰기 성능을 개선하고 싶다면 샤딩(sharding)을 권장한다.
- 샤딩은 다음에 다뤄보도록 하겠다.
멀티 소스(Master) 복제
- 멀티 소스 복제
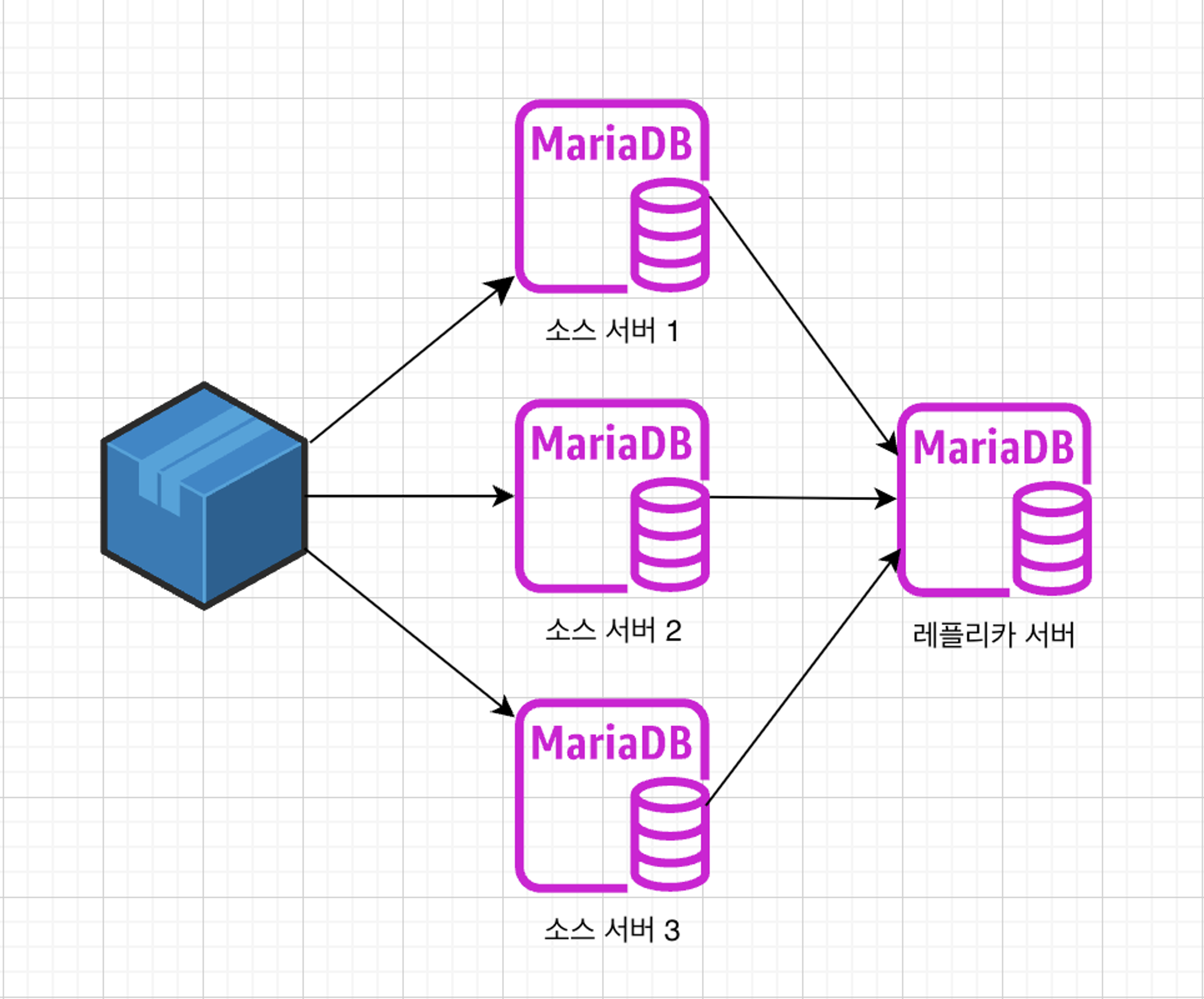
- 멀티 소스 복제는 여러 개의 소스 서버로부터 데이터를 복제 받는 하나 이상의 레플리카로 구성된다.
- 각 소스는 독립적으로 쓰기 작업을 처리하며, 레플리카는 여러 소스로부터 데이터를 복제하여 읽기 요청을 처리한다.
- 각 소스는 독립적으로 쓰기 작업을 처리하며 → 아마 이 부분이 샤딩을 사용했을 것이라고 판단이 든다.
- 다양한 데이터 소스로부터 데이터를 집계하고 통합하는 데 유용하며, 여러 소스로부터 데이터 복제를 통해 정보의 다양성과 풍부함을 제공한다.
- 복잡한 데이터 흐름과 충돌 해결, 동기화 문제를 관리해야 하며, 레플리카 관리가 더 복잡해집니다.
내가 선택한 Replication Topology
- 지금 회사 프로젝트에서는 체인 복제처럼 디테일한 복제는 필요 없다고 생각하였고, 멀티 소스 복제는 메인 DB가 1개인 우리 상황에 맞지 않다고 생각했다.
- 또한, 듀얼 복제는 아직 동시성을 확실하게 컨트롤하지 못하는 나에겐 사이드 이펙트가 발생할 것으로 우려되고 싱글 레플리카 복제는 언제는 문제가 생기면 전환한다고 하지만 이건 원초적인 해결방법이 아닌 것 같았다.
- 따라서 나는 멀티 레플리카 복제를 선택하였고 도입을 완료한 상태에서는 아직 한번도 서버가 죽은것이 없긴 하다.
- 만약 죽더라도 이미 에러 메뉴얼은 충분히 만들어두고 연습해둔 상태라 괜찮을 것 같다..ㅎㅎ
결론
후기
- 여러므로 이번에 DB에 대해 배운게 정말 많은 것 같다.
- 사실 DB에 대한 인프라적인건 궁금해 한적이 없기에 거의 밑바닥부터 시작했더니 조금 힘들었지만 나름 많이 배운것 같다.
- 아마 다음 DB 관련된 포스팅은 샤딩이 되지 않을까 싶다.
- 왜냐면 일단 지금도 소스(마스터) DB는 1개 이므로 대용량을 처리하기엔 역부족이라고 생각이 든다.
- 앗 그리고 2023 회고에 대해 올릴 것이다!!! 🤗🤗🤗

지나가는 개발자