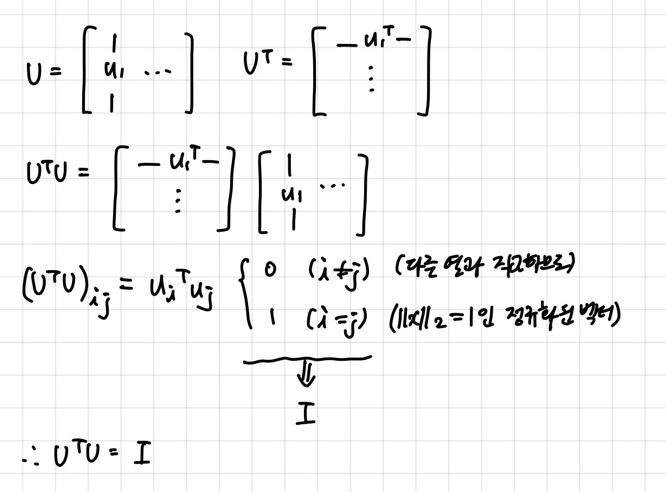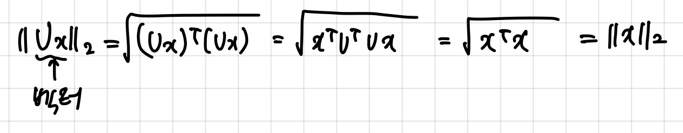정방행렬 A가 AT와 동일할 때 대칭행렬이라고 부른다. A=−AT일 때는 반대칭(anti-symmetric)행렬이라고 부른다.
AAT는 항상 대칭행렬이다. (AAT)T=(AT)TAT=AAT
A+AT는 대칭, A−AT는 반대칭이다.
A=21(A+AT)+21(A−AT)
대각합 (Trace)
정방행렬 A∈Rn×n의 대각합은 tr(A)로 표시(또는 trA)하고 그 값은 ∑i=1nAii이다. 대각합은 다음과 같은 성질을 가진다.
대각합의 성질
- For A∈Rn×n, trA=trAT
- For A,B∈Rn×n, tr(A+B)=trA+trB
- For A∈Rn×n,t∈R, tr(tA)=ttrA
- For A,B such that AB is square, trAB=trBA
- For A,B,C such that ABC is square, trABC=trBCA=trCAB, and so on for the product of more matrices (여러 행렬의 곱이 정방행렬일 때, cycle을 따라서 순서를 바꾸어 곱해도 그 대각합은 같다.)
numpy의 trace 속성으로 대각합 구하기
A = np.array([[100,200,300],[10,20,30],[1,2,3],])
np.trace(A)## output# 123
Norms
벡터의 norm은 벡터의 길이로 이해할 수 있다. l2 norm (Euclidean norm)은 다음과 같이 정의된다.
∥x∥2=∑i=1nxi2
numpy.linalg로 norm 구하기
import numpy.linalg as LA
LA.norm(np.array([3,4]))## output# 5.0
∥x∥22=xTx(자기자신과의 내적값)임을 기억하라.
lp norm ∥x∥p=(∑i=1n∣xi∣p)1/p
Frobenius norm (행렬에 대해서 정의) ∥A∥F=∑i=1m∑j=1nAij2=tr(ATA)
- 증명
A = np.array([[100,200,300],[10,20,30],[1,2,3],])
LA.norm(A)## output# 376.0505285197722
np.trace(A.T.dot(A))**0.5## output# 376.0505285197722
선형독립과 Rank (Linear Independence and Rank)
벡터들의 집합 {x1,x2,…,xn}⊂Rm에 속해 있는 어떤 벡터도 나머지 벡터들의 선형조합으로 나타낼 수 없을 때 이 집합을 선형독립(linear independent)이라고 부른다.
역으로 어떠한 벡터가 나머지 벡터들의 선형조합으로 나타내질 수 있을 때 이 집합을 (선형)종속(dependent)이라고 부른다.
Column Rank
- 행렬 A∈Rm×n의 열들의 부분집합 중에서 가장 큰 선형독립인 집합의 크기
Row Rank
- 행렬 A∈Rm×n의 행들의 부분집합 중에서 가장 큰 선형독립인 집합의 크기
rank의 성질
- 모든 행렬의 column rank와 row rank는 동일, rank(A)로 표시
- For A∈Rm×n, rank(A)≤min(m,n). If rank(A)=min(m,n), then A is said to be full rank.
- For A∈Rm×n, rank(A)=rank(AT).
- For A∈Rm×n,B∈Rn×p, rank(A+B)≤min(rank(A),rank(B)).
- For A,B∈Rm×n, rank(A+B)≤rank(A)+rank(B).
numpy.linalg의 matrix_rank를 사용해서 쉽게 구할 수 있다.
역행렬 (The Inverse)
정방행렬 A∈Rn×n의 역행렬 A−1은 A−1A=I=AA−1을 만족하는 정방행렬(∈Rn×n)이다. A의 역행렬이 존재할 때, A를 invertible 또는 non-singular하다고 말한다.
역행렬의 성질들
- A의 역행렬이 존재하기 위해선 A는 full rank여야 한다.
- (A−1)−1=A
- (AB)−1=B−1A−1
- (A−1)T=(AT)−1
numpy.linalg의inv로 역행렬을 구할 수 있다.
직교 행렬 (Orthogonal Matrices)
xTy=0가 성립하는 두 벡터 x,y∈Rn를 직교(orthogonal)라고 부른다. ∥x∥2=1인 벡터 x∈Rn를 정규화(normalized)된 벡터라고 부른다. 모든 열들이 서로 직교이고 정규화된 정방행렬 U∈Rn×n를 직교행렬이라고 부른다.
직교행렬의 성질들
- UTU=I
- UUT=I (이건 밑에서 증명)
- U−1=UT (UTU=I=UUT이 성립하며 이것은 역행렬의 정의와 동일)
- ∥Ux∥2=∥x∥2 for any x∈Rn
치역(Range), 영공간(Nullspace)
벡터의 집합({x1,x2,…,xn})에 대한 생성(span)
벡터 xi들의 (모든 실수 ai에 대한)선형조합으로, 벡터들의 집합이므로 공간을 이룬다.
span({x1,x2,…,xn})={v:v=∑i=1nαixi,αi∈R}
행렬의 치역 (range)
행렬 A∈Rm×n의 치역 R(A)는 A의 모든 열들에 대한 생성(span)이다.
R(A)={v∈Rm:v=Ax,x∈Rn}
영공간 (nullspace)
행렬 A∈Rm×n의 영공간(nullspace) N(A)는 A와 곱해졌을 때 0이 되는 모든 벡터들의 집합이다.
N(A)={x∈Rn:Ax=0}
중요한 성질
- n차원 내 임의의 한 점 w는 u∈R(AT)와 v∈N(A)의 합으로 표현 가능하다. {w:w=u+v,u∈R(AT),v∈N(A)}=RnandR(AT)∩N(A)={0}
R(AT)(n차원)와 N(A)(n차원)를 직교여공간(orthogonal complements)라고 부르고 R(AT)=N(A)⊥라고 표시한다.
투영 (projection)
R(A)위로 벡터 y∈Rm의 투영(projection)은
Proj(y;A)=argminv∈R(A)∥v−y∥2=A(ATA)−1ATy
UTU=I인 정방행렬 U는 UUT=I임을 보이기
- U의 치역은 전체공간(R(A)=Rn)이므로 임의의 y에 대해 Proj(y;U)=y이어야 한다.
- 모든 y에 대해 U(UTU)−1Uy=y이어야 하므로 U(UTU)−1UT=I이다.
- 따라서 UUT=I이다.
행렬식 (Determinant)
정방행렬 A∈Rn×n의 행렬식(determinant) ∣A∣ (또는 detA)는 다음과 같이 계산할 수 있다.
음/양의 준/정부호
- 대칭행렬 A∈Sn이 0이 아닌 모든 벡터 x∈Rn에 대해서 xTAx>0을 만족할 때, 양의 정부호(positive definite)라고 부르고 A≻0(또는 단순히 A>0)로 표시한다. 모든 양의 정부호 행렬들의 집합을 S++n으로 표시한다.
- 대칭행렬 A∈Sn이 0이 아닌 모든 벡터 x∈Rn에 대해서 xTAx≥0을 만족할 때, 양의 준정부호(positive sesmi-definite)라고 부르고 A⪰0(또는 단순히 A≥0)로 표시한다. 모든 양의 준정부호 행렬들의 집합을 S+n으로 표시한다.
- 대칭행렬 A∈Sn이 0이 아닌 모든 벡터 x∈Rn에 대해서 xTAx<0을 만족할 때, 음의 정부호(negative definite)라고 부르고 A≺0(또는 단순히 A<0)로 표시한다.
- 대칭행렬 A∈Sn이 0이 아닌 모든 벡터 x∈Rn에 대해서 xTAx≤0을 만족할 때, 음의 준정부호(negative sesmi-definite)라고 부르고 A⪯0(또는 단순히 A≤0)로 표시한다.
- 대칭행렬 A∈Sn가 양의 준정부호 또는 음의 준정부호도 아닌 경우, 부정부호(indefinite)라고 부른다. 이것은 x1TAx1>0,x2TAx2<0을 만족하는 x1,x2∈Rn이 존재한다는 것을 의미한다.
-Positive definite 그리고 negative definite 행렬은 full rank이며 따라서 invertible이다.
Gram Matrix
임의의 행렬 A∈Rm×n이 주어졌을 때 행렬 G=ATA를 Gram matrix라고 부르고 항상 positive semi-definite이다.
만약 m≥n이고 A가 full rank이면, G는 positive definite이다.
고유값 (Eigenvalues), 고유벡터 (Eigenvectors)
정방행렬 A∈Rn×n이 주어졌을 때, Ax=λx,x=0을 만족하는 λ∈C를 A의 고유값(eigenvalue) 그리고 x∈Cn을 연관된 고유벡터(eigenvector)라고 부른다.
우리가 찾는 최적의 D는 다음과 같다. D∗=argminD∥E∥F2subjecttoDTD=Il R을 다시 정리하고 식을 풀어보자. diTdi=1이므로 벡터들 d1,…,dl이 XTX의 가장 큰 l개의 고유값에 해당하는 고유벡터들일 때 ∑i=1ldiTXTXdi이 최대화된다.