(작성중)
선형 기저 함수 모델
기저함수(Basis Function)
가장 기본적인 선형 모델 을 고려하자.
이고 이 모델의 파라미터는 이다. 위 함수는 파라미터 와 입력 데이터 모두에 대해서 선형이다.
에 대해 비선형인 함수를 만들고 싶다면, 일반화된 식으로 다음과 같이 표현할 수 있다.
추가된 함수 를 기저함수라고 부르며, 이 함수의 도입으로 기존에는 선형 식이었던 함수가 에 대해 비선형 함수가 될 수 있다. 그러나 에 대해서는 여전히 선형임을 기억하자.
표기의 편리성을 위해 로 정의하고 좀 더 간략한 식으로 기술하기도 한다.
-
다항식 기저함수
-
가우시안 기저함수
-
시그모이드 기저함수
최대우도와 최소제곱법(Maximum Likelihood and Least Squares)
에러함수가 가우시안 노이즈를 가정할 때 최대우도로부터 유도될 수 있다는 것을 살펴보았다. 이를 조금 더 자세히 알아보자. 우리가 예측하려고 하는 타겟값 가 다음과 같은 분포를 가진다고 하자.
- 는 결정론적 함수(deterministic)
- 은 가우시안 분포 를 따르는 노이즈 확률변수
- 따라서 t의 분포는
제곱합이 손실함수로 쓰이는 경우, 새로운 가 주어졌을 때 의 최적의 예측값은 의 조건부 기댓값임을 알고있다. 가 위의 분포를 따르는 경우 조건부 기댓값은 다음과 같다.
파라미터인 를 찾기 위해 최대우도추정법을 사용하자.
입력값은 이고 출력값은 이다. 로그 우도함수는 다음과 같다.

따라서 로그 우도함수를 최대화시키는 값은 로 주어진 제곱합 에러함수를 최소화시키는 값과 동일하다.
위 식을 에 대해 미분하고 좌변을 0으로 두고 풀면 의 최적값을 구할 수 있다.
위 식을 normal equations라고 부른다. 이 때 사용되는 는 크기의 행렬로 디자인 행렬(design matrix) 이라고 한다.
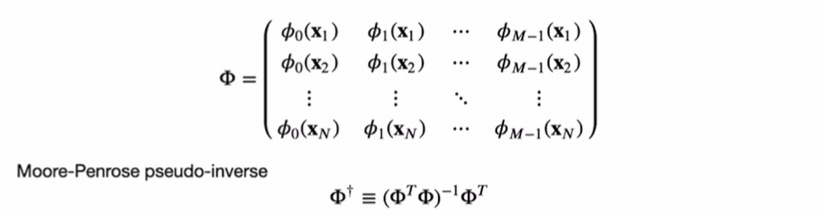
-
편향 파라미터
를 함수에서 분리해 기술한다면 에러 함수가 다음과 같이 변하게 된다.
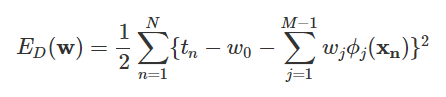
이 식이 로 인해 0이 된다고 하면,
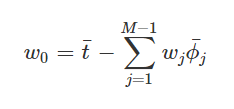
즉, 에러함수를 최소로 만들어낼 수 있는 값의 의미를 살펴보면, 실제 얻어지는 샘플들의 타겟 값들의 평균과 기저함수에 가중치를 곱하여 얻어진 결과의 평균값의 차이를 보정하는 역할을 하게 된다. -
노이즈 의 최적값
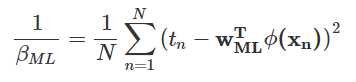
최소 제곱법의 기하학적 의미(Geometry of Least Squares)
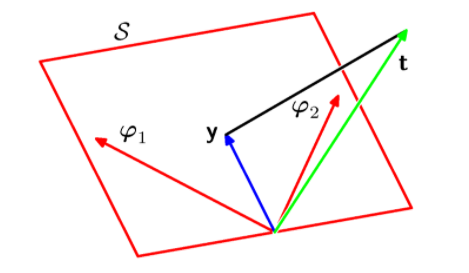
결국 우리가 구하고자 하는 것은 벡터가 놓일 수 있는 공간 로부터 실제 결과 값 벡터 사이에 가장 가까운 거리를 가지는 한 점을 찾는 것이다.
시퀀스 학습 (Sequential learning)
-
배치학습 vs 온라인학습
전체 데이터를 한번에 사용해서 처리하는 배치학습과는 다르게, 데이터가 순차적으로 입력될 때 모델의 파라미터를 학습하는 방법을 온라인학습(시퀀스학습)이라고 한다. 데이터가 순차적으로 입력됨에 따라서 구해야 할 파라미터 값이 계속해서 갱신되어야 한다. -
Stochastic Gradient Decent
에러함수를 로 정의하여 파라미터가 업데이트되도록 식을 만들 수 있다.

여기서 는 데이터가 반복적으로 입력된 횟수, 는 학습률(learning rate) 파라미터이다.
규제화된 최소제곱법(Regularized Least Squares)
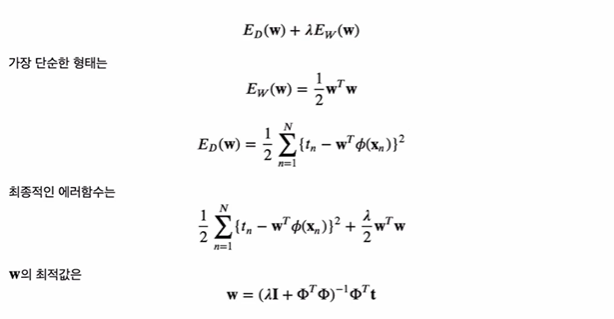
-
일반화된 규제화
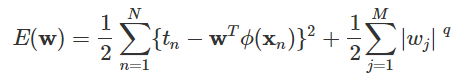
-
인 경우를 Lasso 모델이라고 한다.
Constrained minimization 문제로 나타낼 수 있다.
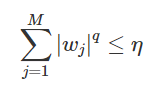
편향-분산 분해(Bias-Variance Decomposition)
베이지안 선형회귀(Bayesian Linear Regression)
