📝 참고 사이트: 거꾸로 읽는 self-supervised-learning 파트 1
🔗 논문 링크: Unsupervised Deep Embedding for Clustering Analysis

Abstract
Clustering is central to many data-driven application domains and has been studied extensively in terms of distance functions and grouping algorithms. Relatively little work has focused on learning representations for clustering. In this paper, we propose Deep Embedded Clustering (DEC), a method that simultaneously learns feature representations and cluster assignments using deep neural networks. DEC learns a mapping from the data space to a lower-dimensional feature space in which it iteratively optimizes a clustering objective. Our experimental evaluations on image and text corpora show significant improvement over state-of-the-art methods.
Introduction
1. Clustering
- 데이터 분석과 시각화에서 핵심인 Clustering은 Cluster의 정의, 올바른 distance metric, 효율적인 그룹화, cluster 검증 등 다양한 관점에서 연구되어 왔다.
- 상대적으로 clustering을 위한 feature space의 unsupervised learning에 초점을 맞춘 연구는 적다.
- Distance(또는 dissimilarity)는 clustering에서 핵심 개념이다.
- Distance는 feature space에 데이터를 얼마나 잘 representation 하는지에 의존하며, 적절한 feature space를 선택하는 것이 중요하다.
2. Feature Representation and Cluster Assignments
- Raw data space나 shallow linear embedded space에서 clustering을 수행하는 기존의 방법과 달리, SGD(Stochastic gradient descent) backpropagation을 사용하여 clustering mapping을 학습하는 DEC(Deep embedded clustering)을 제안한다.
- Unsupervised learning 방법으로 feature representation과 cluster assignment를 동시에 해결하기 위해, 반복적으로 현재 soft cluster assignment에서 산출된 auxiliary target distribution으로 재정의하는 방법을 제안한다.
- 이 방법은 clustering 뿐만 아니라 feature representation 성능 또한 향상시킨다.
3. Contributions
- DEC의 성능은 hyperparameter 선택에 덜 민감하기 때문에 real data에 적용시 robustness 하다.
- Deep embedding과 clustering의 joint optimization을 수행한다.
- Soft assignment를 통해 cluster를 반복적으로 재정의한다.
- Clustering 정확도와 speed에 있어서 state-of-the-art 달성한다.
Related Works
1. K-means and Spectral clustering
- K-means와 GMM(Gaussian mixture models)은 모델 속도가 빠르고, 넓은 분야에서 적용할 수 있다. 하지만, 사용되는 distance metric은 raw data space에 제한되고, 고차원에서 비효율적이다.
- 고차원의 input space를 다루기 위해, cluster 분산을 최대화할 수 있는 저차원으로 차원축소하는 방법이 제안되었지만, linear embedding으로 복잡한 데이터에서 제한된다.
- Spectral clustering은 flexible distance metrics를 사용하고 고유값 분해를 deep autoencoder로 대체하여 성능을 향상시켰지만, full graph Laplacian matrix를 계산하기 때문에 메모리 소비가 증가하고 속도가 느린 단점이 있다.
2. Parameteric t-SNE
- Parameteric t-SNE는 deep neural network를 사용하여 embedding을 수행하고, 시간복잡도는 O(nlogn) 이다.
- Parameteric t-SNE에 영감을 받아 centroid-based 확률 distribution를 정의하고, auxiliary target distribution으로의 KLD(Kullback-Leibler divergence)를 최소화하여 cluster assignmnet 및 feature representation을 동시에 개선한다.
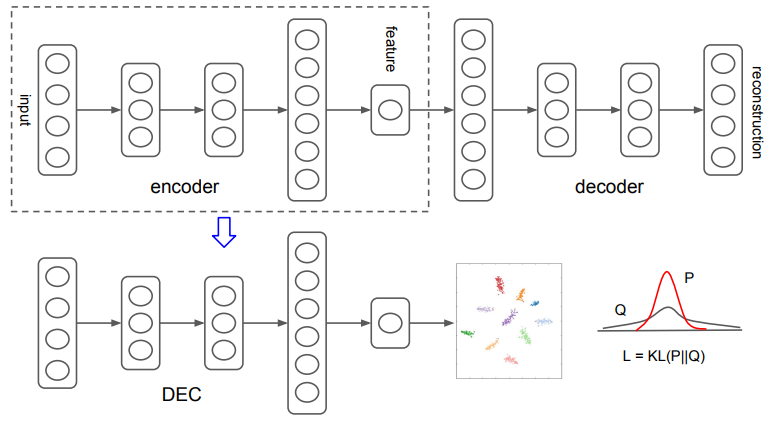
Deep Embedded Clustering
- Data space :
- Latent feature space
- Non linear mapping :
- Cluster 의 centroid:
- 제안된 알고리즘 DEC는 feature space 의 cluster centers와 parameter 를 동시에 학습한다.
- DEC는 (1) deep autoencoder를 사용하여 parameter를 initialization 하고, (2) auxiliary target distribution으로의 KLD 최소화를 반복하여 parameter를 최적화한다.
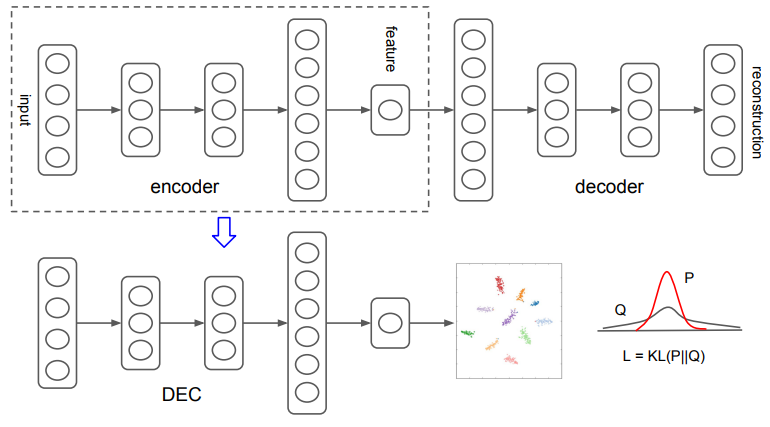
1. Parameter initialization
- 각 layer마다 autoencoder를 적용하여 학습하고, 이를 연결한 SAE(Stacked autoencoder) 를 사용한다.
- 각 layer는 denoising autoencoder를 사용하며, greedy layer-wise training을 수행한다.
- SAE의 reconstruction loss를 최소화 하도록 학습을 수행한 뒤, DEC의 data space와 feature space 사이를 mapping 하는 initial network로 SAE의 encoder를 사용한다.(Non linear mapping )
- K-means 알고리즘을 사용하여 feature space 에서 initial cluster centers를 정한다.
2. Clustering with KL divergence
- 앞선 과정을 통해 non linear mapping 과 initial cluster centers 가 주어지면, (1) embedded points와 cluster centroids간의 soft assignment 계산 (2) 업데이트 및 cluster centroids 재조정을 반복하여 unsupervised learning clustering을 수행한다.
2.1 Soft Assignment
- T-SNE에서 사용되는 student's t-distribution로 embedded point 와 간의 similarity를 계산한다.
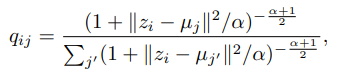
- 는 sample 가 cluster 에 할당될 확률로 해석될 수 있다 (즉, soft assignment).
2.2 KL Divergence Minimization
- Soft assignment가 high confidence 될 수 있도록 auxiliary target distribution 를 사용한다.
- (1) 강력한 예측 (cluster 성능), (2) high confidence assignment, (3) 각 centroid의 loss 정규화 세가지 목표와 함께 실험적으로 를 계산한다.
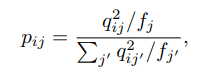
- 는 cluster의 데이터 개수 이며, 정규화를 위해 사용된다.
- 최종적으로 사용되는 loss는 와 의 distribution 차이가 최소가 되도록 하는 KLD를 사용한다.
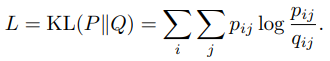
2.3 Optimization
- Cluster center 와 파라미터 를 학습하기 위해 SGD(Stochastic gradient descent)를 사용한다.
- 의 gradient는 의 feature space embedding과 cluster centers 를 중점적으로 다음과 같이 계산된다.
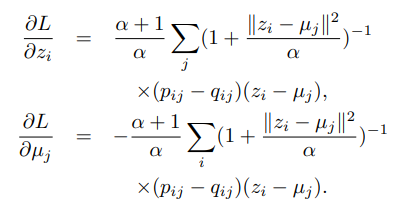
- 학습 과정에서 전체 cluster assignment 변화가 0.1% 이하 라면 학습을 종료시킨다.
Experiments
1. Dataset
- 이미지: MNIST (class 10), STL-10 (class 10)
- 텍스트: REUTERS (category 4)
2. Evaluation Metric
- Ground-truth categories의 숫자와 동일하게 culster의 수를 설정하고 unsupervised clustering accuracy를 계산한다.
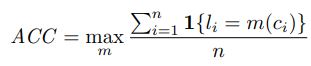
- 는 ground-truth label, 는 cluster assignment, 은 가능한 모든 mapping case
Results
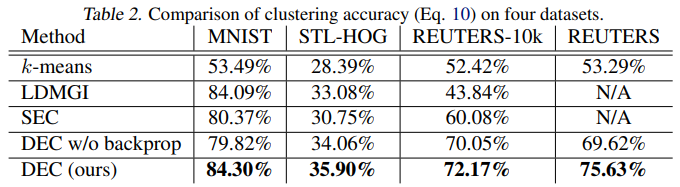
- Table 2.는 각 dataset에 대해 ACC 분류 성능을 나타낸 것으로, DEC 모델이 제일 좋은 성능을 보였다.
- DEC w/o 는 end-to-end 학습의 효율성을 확인하기 위해, DEC의 를 고정시키고 학습시킨 결과이다.
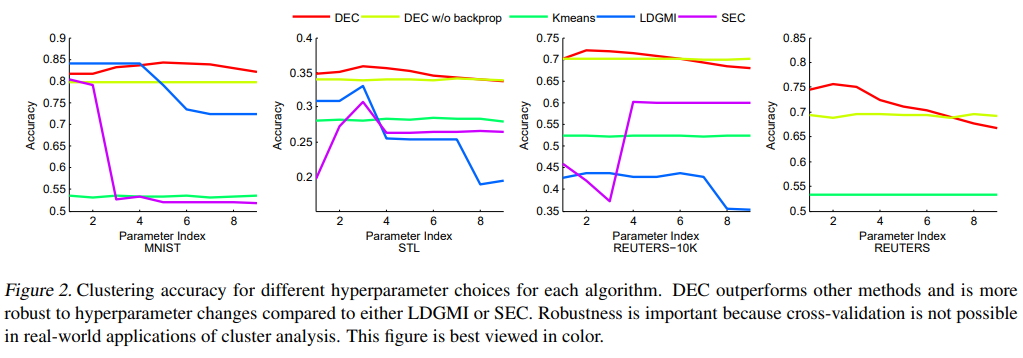
- Figure 2.는 hyperparameter에 따라 모델 성능의 민감도를 나타낸다.
- DEC 모델은 hyperparameter와 관계없이 일정한 성능을 보였다.

- Figure 3.은 각 cluster를 행별로 나타낸 결과이며, 왼쪽에서 오른쪽으로 갈수록 cluster center와 거리가 먼 것을 나타낸다.
- 4와 9를 어려워한 것을 알 수 있다.
Discussion
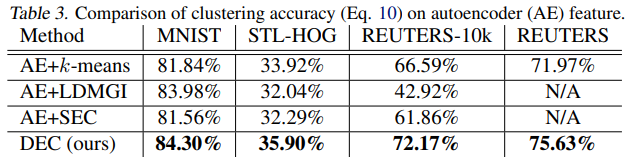
- Table 3.은 autoencoder를 수행했을 때와 비교한 결과이다.
- Autoencoder만을 사용한것 보다, KLD로 파인튜닝한 deep embedding의 성능이 더 좋은 것을 알 수 있다.
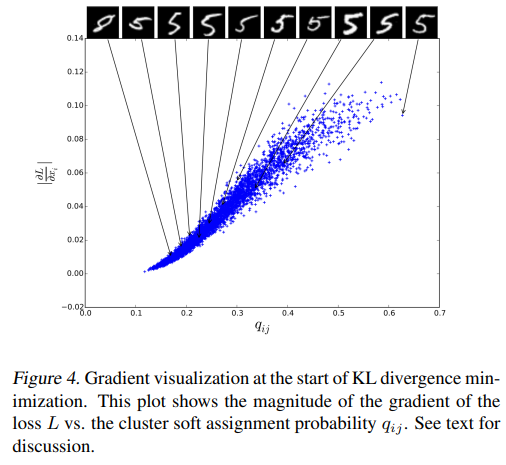
- Figure 4.는 Gradient와 cluster soft assignment 의 관계를 파악하기 위한 결과이다.
- Cluster center와 가까울 수록 (가 클수록) gradient가 더 크게 기여한다.
- 가 작을수록 더 모호해지며, 5를 8로 잘못 분류된 것을 알 수 있다.
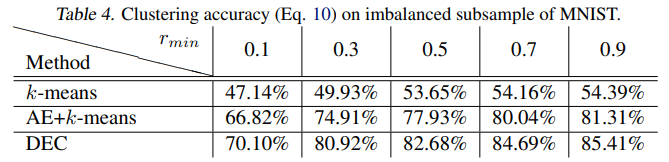
- Table 4.는 데이터 불균형에 따른 성능 비교 결과이며, 다른 모델에 비해 DEC는 데이터 불균형에 robust 한 것을 알 수 있다.
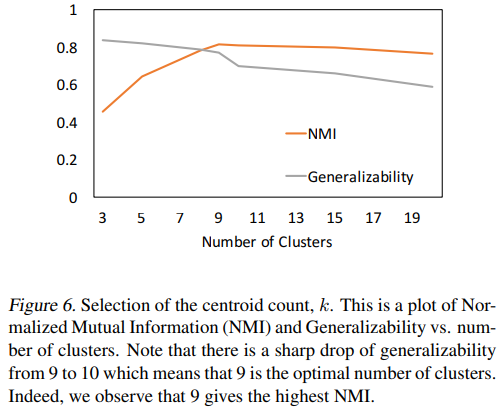
- 최적의 cluster 수를 결정하는 metric 두가지: (1) NMI (Normalized mutual information) (2) Generalizability 를 제안한다.
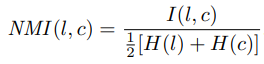
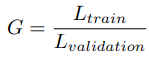
- 는 mutual information metric, 는 entropy, G는 training과 validation loss 비율을 나타낸다.
- 최적의 cluster 개수가 9인 것은 label 9와 4가 유사하기 때문이다.
Conclusion
- DEC는 clustering과 feature space 최적화를 공동으로 수행할 수 있다.
- Self-training target distribution을 사용하여 반복적으로 KLD를 최적화한다.
- 제안된 모델은 semisupervised self-training의 unsupervised extension이라 볼 수 있다. (Self-supervised learning)
- Groundtruth 없이 clustering에 특화된 representation을 학습하는 방법이다.
- Unsupervised 방식으로 cross-validation이 불가능하기 때문에 hyperparameter에 관계없이 향상된 성능과 robust를 제공한다.
- 데이터수에 대해 linear complexity가 있어 대규모 데이터셋으로 확장이 가능하다.
🙆🏻♂️ 논문을 읽고 나서..
- Real data에서 적용가능한 unsupervised 방식의 clustering 방법이 인상적이다.
- Validation을 통해 hyperparameter를 조정할 수 있다면 더 나은 모델이 될 수 있지 않을까.
- 가 target distribution이 될 수 있는 이유는 무엇일까. 🙋🏻♂️
- Cluster를 위한 모델이 아닌 데이터의 특징을 잘 설명할 수 있도록 representation에 중점을 두어 supervised learning의 성능을 높일 수 있다면? 🤷🏻♂️
