📝 참고 사이트: 거꾸로 읽는 self-supervised-learning 파트 1
🔗 논문 링크: Deep Adaptive Image Clustering

Abstract
Image clustering is a crucial but challenging task in machine learning and computer vision. Existing methods often ignore the combination between feature learning and clustering. To tackle this problem, we propose Deep Adaptive Clustering (DAC) that recasts the clustering problem into a binary pairwise-classification framework to judge whether pairs of images belong to the same clusters. In DAC, the similarities are calculated as the cosine distance between label features of images which are generated by a deep convolutional network (ConvNet). By introducing a constraint into DAC, the learned label features tend to be one-hot vectors that can be utilized for clustering images. The main challenge is that the ground-truth similarities are unknown in image clustering. We handle this issue by presenting an alternating iterative Adaptive Learning algorithm where each iteration alternately selects labeled samples and trains the ConvNet. Conclusively, images are automatically clustered based on the label features. Experimental results show that DAC achieves state-of-the-art performance on five popular datasets, e.g., yielding 97.75% clustering accuracy on MNIST, 52.18% on CIFAR-10 and 46.99% on STL-10.
Introduction
1. Image Clustering
- content-based annotation과 image retrieval 분야에서 image clustering이 적용되고 있다.
- K-means와 agglometrative clustering 알고리즘이 사용되어 왔지만, 이는 미리 distance metric을 정의해야하는 어려움이 존재한다.
- 최근에 Autoencoder를 사용한 deep unsupervised feature learning 방법이 연구되고 있지만, upsupervised 방법의 pre-training 이 후 전통적인 clustering 방법을 적용하는 multi-stage 방법에는 몇가지 한계가 존재한다.
- Multi-stage는 학습이 번거롭다.
- Representation은 unsupervised feature learning 이후 고정된다.
- Clustering 과정에서 representation을 더 이상 개선할 수 없다.
2. Proposed Method
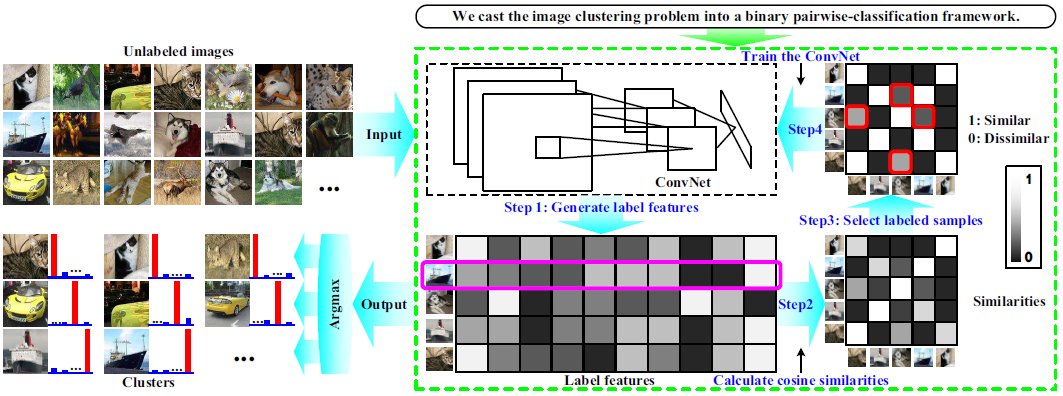
- Single-stage ConvNet 기반 Deep Adaptive Clustering(DAC) 방법을 제안한다.
- 이미지 쌍이 같은 cluster에 속하는지 판단하기 위해, binary pairwise-classification 문제로 접근한다.
- 제약조건을 추가하면서, 학습된 feature는 one-hot vector 형태가 된다.
- Ground-truth 유사도를 알지 못하기 때문에, 모델 최적화를 위해 alternating iterative 방법인 Adaptive Learning 알고리즘을 적용한다.
- 각 interation 동안, 쌍을 이룬 image간의 추정된 유사도가 고정된 ConvNet 기반으로 먼저 선택된다.
- DAC는 선택된 labeled sample을 사용하여 ConvNet을 supervised 방식으로 학습한다.
- 모든 sample이 학습에 사용되고, binary pairwise 분류 성능이 더 이상 개선되지 않을 때 수렴된다.
- 마지막으로, 이미지는 label feature의 가장 큰 response로 clustering 된다.
Related Work
1. Data Clustering
- 크게 3가지 방법으로 나눌 수 있다.
- Distance-based
- Density-based
- Connectivity-based
2. Image Representation
- low-level feature를 encoding 하는 전통적인 방법이 있다.
=> 이는 종종 scene과 개체의 모양 변화로 어려움을 겪는다. - Unsupervised feature learning 은 input을 reconstruction하면서 feature representation을 학습하는데, Autoencoder방법과 deep generative model방법이 있다.
=> 생성된 representation 기반으로 clustering 결과를 즉시 얻을 수 없다.
3. Combination
- Feature learning과 clustering을 single-stage로 결합하는 여러 방법이 제안되었다.
- Deep embedded clustering (DEC)는 cluster의 centroid를 학습한다.
=> Pre-training이 필요하다는 불편한 점이 있다. - Joint unsupervised learning (JULE)는 KNN에서 초기화한 clustering을 기반으로 agglometrative clustering과 feature learning을 공동으로 수행한다.
=> 서로 다른 이미지 사이의 거리를 정의하는 것은 어렵기 때문에, 복잡한 이미지 데이터에 대해 성능이 저하된다.
- Deep embedded clustering (DEC)는 cluster의 centroid를 학습한다.
4. Sample Selection
-
머신러닝에서 더욱 효율적인 모델 학습을 위해 학습 샘플을 선택하는 방법이 연구되고 있다.
- Boosting algorithm은 다양한 모델에서 학습한 데이터셋에서 임의로 부분 샘플을 선택하고, 이들을 통합하여 가장 성능이 좋은 분류기를 만든다.
- Curriculum learning은 비교적 쉬운 샘플을 우선 사용하고, 점진적으로 복잡한 샘플을 학습에 사용한다.
-
=> 위의 두가지 방법은 labeled data에 동작되는 제약이 있다.
Deep Adaptive Clustering Model
1. Binary Pairwise-Classification for Clustering
-
Clustering을 이미지 쌍이 같은 cluster에 속하는지에 대한 여부를 학습하는 binary 문제로 재정의 한다.
- input: (unlabed images)
- output: (unkown binary variable)
-
Objective function:
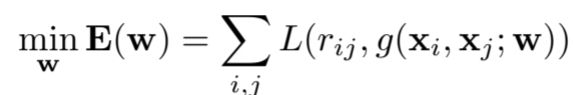
-
은 와 는 추정된 유사도 의 loss, 는 학습 파라미터
-
위의 식에서 두가지 이슈가 있다.
- 오직 추정된 유사도 에서 와 의 cluster를 얻을 수 없다.
- 는 이미지 clustering 과정에서 알 수 없다.
2. Labeld features under Clustering Constraint ()
- 이미지 쌍의 유사도 측정()를 측정하기 위해 label feature 를 도입한다.
- 는 k차원 label feature이다(k는 cluster 개수).
- 이미지 clustering에 보단 유용한 정보를 학습하기 위해 label feature 에 제약 조건을 적용한다.
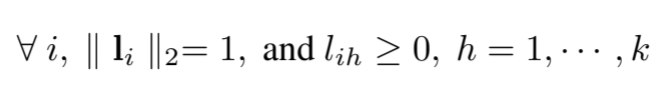
- ll ll 는 -norm이며, 가 0 이상의 값을 갖도록 제약조건을 주게 되면, cosine similarity 연산을 내적 연산으로 치환이 가능하다.
- 따라서, 는 mapping function 과 함께 다음과 같이 나타낼 수 있다.
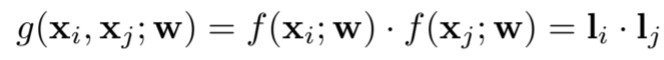
- label feature의 제약 조건으로, 는 k개의 one-hot vector로 나타낼 수 있으며, 이는 이미지 clustering 으로 할당 할 수 있게 된다.
3. Labeld Training Samples Selection ()
- 를 알지 못하기 때문에, labeled training sample을 선택하는 전략이 필요하다. (sample: )
- ConvNets은 다음 두가지 특징이 있다.
- ConvNets이 학습되지 않았다면, initialized ConvNets의 filter는 edge detectors 역할을 하기 때문에, low-level feature를 포착할 수 있다.
- ConvNets가 이미 학습되었다면, high-level feature를 생성할 수 있다.
- 위의 두가지 특징을 기반으로 를 다음과 같이 정의한다.
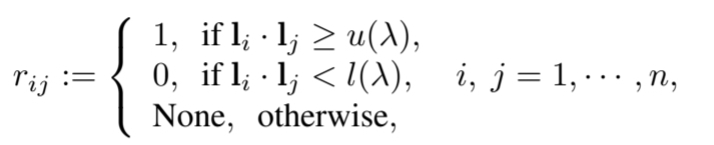
- 는 선택을 제어하는 adaptive parameter 이고, 와 는 각각 유사도와 비유사도의 labeled sample 선택을 위한 threshold이다.
- 인 sample은 학습에서 제외된다.
- clustering이 쉬운(likelihood가 높은) sample이 먼저 선택 되어 rough cluster pattern을 발견하도록 하는, curriculum learning 방법을 적용한다.
- Clustering 과정이 진행되면서, 학습된 ALL-ConvNet은 더욱 효과적인 label feature를 추출하고 더욱 정제된 cluster pattern을 발견하기 위해 점차 더 많은 sample이 추가된다.
- 이를 위해 는 점차 증가하게 되고, 는 감소하고 는 증가하게 되며, 모든 sample이 학습에 사용되었을 때 와 가 같아진다.

- 가 1이면 sample 은 선택되고, 0이면 선택되지 않는다.
- 는 penalty term이며, penaltyterm이 감소하면서, 모든 sample이 학습에 사용될 때까지 더 많은 sample이 선택된다.
Deep Adaptive Clustering Algorithm
1. Adaptive Learning
- Objective function 를 최적화 하기 위해 Adaptive learning (alternating iterative optimization)을 적용한다.
- Feature label 의 restraint을 구현하기 위해, mapping function layer에 restraint을 설정한다.
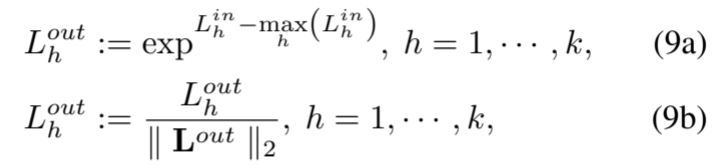
- 과 은 restraint layer의 input과 ouput이다.
- 는 (9a) 제약조건에 의해 모든 요소가 [0, 1]에 매핑되고, (9b) 에 의해 단위 벡터로 제한된다.
- 학습 파라미터 와 는 교대로 최적화된다.
- 와 이 정해지면 (),
- supervised 문제가 된다.
- 와 는 의 메모리 문제가 발생하기 때문에, batch 단위 학습이 요구된다.
- 가 고정되면,
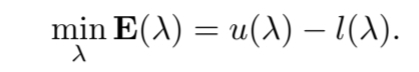
- 경사하강법에 따라 가 update 된다.
- 학습에 sample이 점차 추가되면서 는 증가하게 된다.
- 와 이 정해지면 (),
2. Label Inference for Image Clustering
- Label feature는 제약조건에 의해 one-hot vector가 되며, 결과적으로 이미지는 가장 큰 response에 clustering이 이루어 진다.
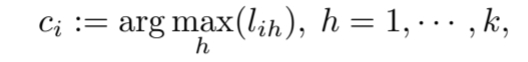
DAC 알고리즘을 요약하자면,
- Adaptive learning 알고리즘을 통해 최적화 된다.
- Fixed ConvNet에서 sample을 선택하는 것과, 선택된 sample 기반으로 학습하는 것을 반복한다.
- 모든 sample이 학습에 사용되었을 때, 알고리즘은 수렴된다.
- 이미지는 label feature에서 가장 큰 response로 clustering 된다.
Experiments
1. Image CLustering
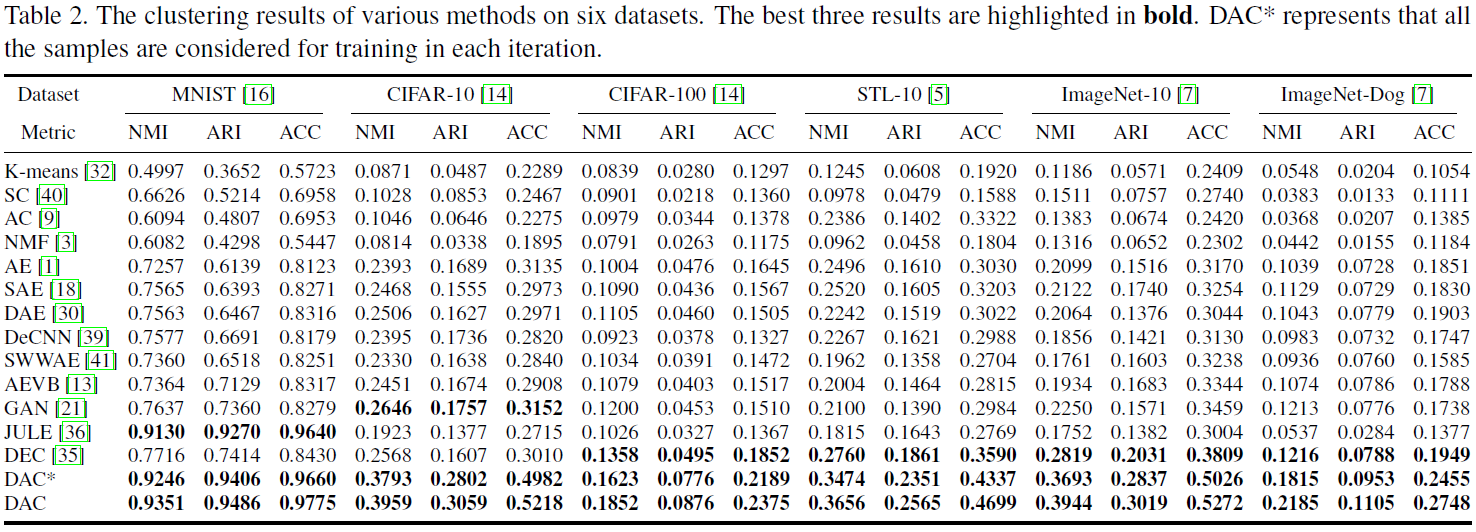
- Table 2에서 DAC는 NMI, ARI, ACC 세가지 평가 지표에서 가장 좋은 성능을 보였다.
- Representation 기반 clustering(AE, AEVB)는 전통적인 방법(K-means, SC) 보다 더 나은 성능을 보였다.
=> 이미지 clustering에서 representation learning이 중요한 역할을 한다. - Single-stage 방법(End-to-end)이 더 우수한 representation learning을 가능하게 한다.
- 제안된 모델은 복잡하고 큰 규모의 이미지 데이터셋에서 잘 동작한다.
- Adaptive learning의 효과를 확인하기 위해, DAC(not Adaptive learning) 의 성능을 비교한다.
=> DAC는 임의로 sample이 선택되기 때문에 noise가 있는 sample이 활용된다.
=> DAC*와 달리 DAC는 정교한 cluster pattern으로 시작하여 결과적으로 clustering 성능을 향상시킬 수 있다.

- Table 3은 clustering tractics를 평가하기 위한 결과이다.
- DAC기반으로 학습된 label feature에 전통적인 방법을 사용한것이 기존 방법보다 더 나은 성능을 보인다.
- 또한, DAC는 label feature에서 가장 큰 response를 찾기만 하면 되기 때문에, 더 간결하다.

- 이미지가 동일한 cluster에 속하는 경우 동일한 label feature에서 뚜렷하게 활성화된다.
- 제안된 방법은 시각적 특징의 단순한 조합이 아닌, 상위 수준의 feature를 학습한다.
=> airliner와 airship 등 복잡한 이미지도 구분이 가능하다.
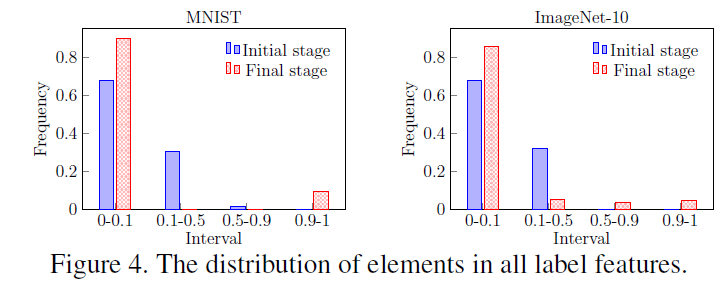
- Figure 4는 Clustering 제약조건의 효과를 확인하기 위한 결과이다.
- 학습된 label feature의 요소를 4개의 간격으로 분리하여 계산한다.
- 초기 단계에서 label label feature의 주요 요소는 [0,0.1) 및 [0.1, 0.5)에 있으며, 최종 단계에서 [0,0.1) 및 [0.9,1]에 있다.
- 이는 학습된 label feature가 sparse하며 0또는 1에 밀집 된 것을 알 수 있고, 이는 clustering을 위해 one-hot 벡터를 학습하려고 시도하는 목표에 부합한다.
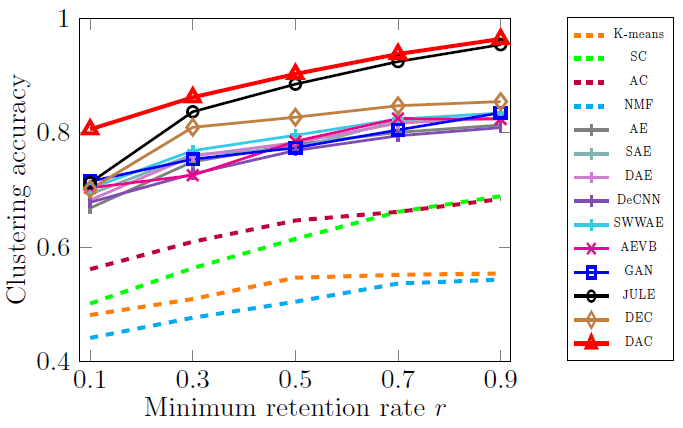
- 제안된 방법이 다른모델에 비해 imabalance에 강하다.
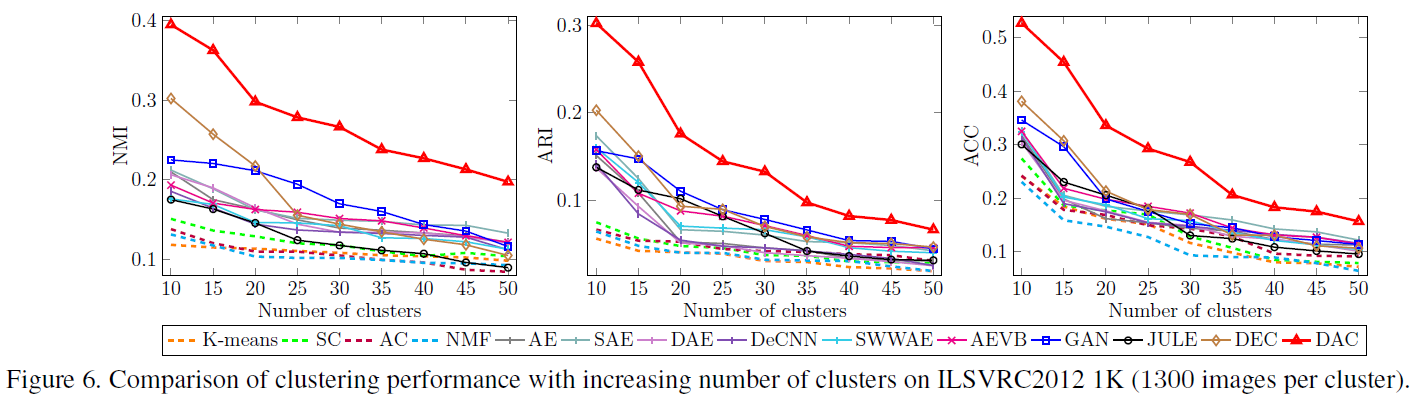
- Clustering의 수가 증가할수록 일반적으로 성능이 저하되는데, 이는 더 많은 불확실성이 유발되기 때문이다.
- 다른 방법에 비해 DAC는 다양한 cluster를 처리할 수 있는 적절한 기능을 가지고 있음을 보여준다.
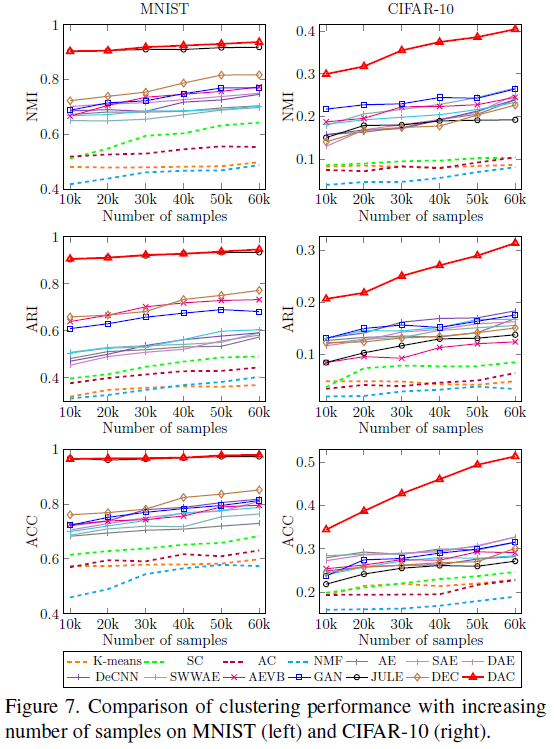
- Figure 7은 Sample 수의 영향을 관찰하기 위한 결과이다.
- 복잡한 데이터일수록 데이터의 개수에 영향을 미치며, 제안된 모델이 더욱 빠르게 증가하는 것을 알 수 있다.
Conclusion
- Single-stage 방법으로 ConvNet기반 방법을 제안한다.
- 제약조건과 함께 binary-pairwise 유사도 분류 방법을 제안한다.
- 제안된 방법은 복잡한 대규모 이미지를 처리할 수 있음을 보여준다.
🙆🏻♂️ 논문을 읽고 나서..
- Unsupervised clustering 방식을 end-to-end로 풀어낸것이 인상깊었다.
- DEC 는 multi-stage 방식인 것에 비해 DAC는 single-stage 방식으로 더 나은 성능을 보였다.
- 유사도를 binary문제가 아닌 regression 문제로 변형시켜서 보다 유연한 모델을 만들 수 있을까? 🤷🏻♂️
- MNIST 데이터셋을 제외한 실험에서의 성능이 충분하지 않은데 이를 해결하기 위해서는 어떻게 해야 할까? 🙋🏻♂️
