이번에 리뷰하고자 하는 paper는 바로 'Learning Transferable Visual Models From Natural Language Supervision' 이라는 논문입니다. 본 논문은 너무나도 잘 알려져 있는 'CLIP'라고도 불립니다. 해당 CLIP의 뜻은 Contrastive Language-Image Pre-training라는 의미로 image classification task에서 성능을 높이고자 vision분야에서의 성능 개선을 시도한 연구가 아닌 caption 혹은 description을 통해서 성능 향상을 수행하고자 한 연구입니다. 특히 본 논문에 대해서 한 마디로 정의하자면 다음과 같습니다.
Image, Text pair 대용량 데이터셋을 활용한 Contrastive learning으로 zero-shot-transfer이 가능하다.
이제 본격적으로 본 논문에 대해서 리뷰를 수행해보도록 하겠습니다.
이번 리뷰 또한 유튜브 '거꾸로 읽는 SSL'님의 CLIP 리뷰 영상을 참고하여 진행했습니다.
Abstract
기존의 image classification 분야에서는 사전의 정의된 라벨링 즉, 학습 단계에서 활용한 사전 정의 카테고리를 기반으로 이미지의 클래스를 분류하는 downstream task에서의 연구들이 이루어지고 있었습니다. 이에 더 나아가 본 논문은 zero-shot task를 수행하기 위해서는 해당하는 image에 대한 caption이나 description이 text로 pair를 이루어 학습시키게 되면 성능 향상부터 일반화 성능 또한 향상된다고 이야기하고 있습니다. 즉, general한 Task에서 caption이나 description 정보를 image와 pair를 이루어 학습하여 image classification의 성능을 향상시키고 이에 더불어 downstream task에서 zero-shot transfer을 수행하고자 합니다.
이를 통해서 이전의 image classification 분야의 한계점인 데이터셋의 generality가 부족한 점을 해결하여 다양한 task의 representation을 반영할 수 있게 되었습니다. 더불어 새로운 데이터 학습이 필요한 경우, 관련된 추가 비용 없이 zero-shot 성능을 보장한 일반화된 사전학습 모델 개발에 기여하였습니다.
1. Introduction and Motivating Work
기존 Computer vision 분야에서 이루어진 연구 방식의 접근들은 앞서 설명한 것처럼 고정된 레이블 카테고리 내에서 학습이 이루어졌으며 이로 인한 generality가 부족하다는 점이 존재하였습니다. 이러한 한계점은 새로운 task에서 기존에 없던 레이블에 대해서 작업을 수행하기 위해서는 추가 작업들이 이루어져야 합니다.
NLP 분야에서 raw text로부터 직접 학습하는 사전 훈련 방식이 성공적인 기여를 수행했습니다. 특히, 이에 더 나아가 기존의 데이터셋에서 더 나아가 웹에서 얻을 수 있는 다양한 텍스트를 반영한 데이터셋으로 훈련을 한 결과, 성능이 성공적으로 향상한 연구들이 이어져 오고 있습니다.
Vision 분야에서 본 논문의 제안 이전부터 image와 text의 쌍을 이루어 학습을 시키고자 하는 노력들이 이루어져왔습니다. 하지만 이러한 초기 연구들의 경우, 일반적인 benchmark의 성능보다 훨씬 낮은 성능을 보여주었고, 이러한 연구들은 단순히 image와 text의 쌍을 이루어 학습을 시키고자 하는 Concept에 대한 증명을 위한 연구에서 머물렀습니다. 특히, ImageNet zero-shot에서 11.5%의 정확도를 기록하였습니다.
CLIP는 이전의 이루어진 연구들의 접근 방향성과 기존의 Image classification 분야에서의 한계점을 해결하고자 합니다. 먼저, 인터넷에서 공개적으로 사용가능한 방대한 이미지-텍스트 데이터를 활용하여 이전의 NLP 분야의 성공적인 연구 접근 방식을 활용하고자 했습니다. 더불어 CLIP는 어떤 캡션이 어떤 이미지와 pair를 이루는지에 대한 간단한 사전훈련으로 기존의 benchmark에서 높은 성능을 보여줬으며 특히, 기존의 Concept에 대한 증명을 위한 연구 수준에서 머물렀던 zero-shot 분야에서도 성능 향상을 이루었습니다.
2. Approach
Natural Language Supervision
이미지와 해당하는 이미지를 설명하는 자연어를 Patir로 학습하고자 합니다. 즉, 해당 이미지에 대한 caption 혹은 description을 통해서 이미지에 대한 representation을 학습할 수 있게 합니다. 이러한 방식은 Naural Language를 label로 활용함으로 인터넷에 존재하는 방대한 데이터를 추가 비용 없이 활용이 가능한 장점이 존재하게 됩니다. 즉, 인터넷에 a black dog with white spots라고 검색했을때, 다양한 이미지들에 대한 검색 결과가 나오게 되는데 이는 해당 문장의 representation에 대해서 다양한 해석과 학습에 의한 결과임을 알 수 있으며 이러한 점들을 추가 비용 없이 활용이 가능하단 점입니다.
해당 접근 방식으로 CLIP의 기본적인 개념을 설명하자면 자연어에 기저에 있는 supervision을 활용하여 시각적 인식 학습에 활용하고자 하는 것입니다. 이를 통해서 자연어로부터 단순히 representation만을 학습하는 것이 아닌 해당 언어들과 이미지의 relation을 학습할 수 있기 때문에 이로부터 유연한 zero-shot transfer이 가능함을 이야기하고 있습니다.
더불어 zero-shot transfer에서 유연성 확보와 CLIP의 vision encoder, text encoder의 경우 대규모 데이터셋을 요구하게 됩니다. 그렇기에 인터넷에서 수집할 수 있는 정보들을 최대한 활용하여 이러한 enviroment에 대한 setting을 수행하게 됩니다.
Efficient Pre-training Method
Image classification 분야에서 NLP 분야의 성공적인 기여를 한 Transformer를 CNN과 함께 학습하는 연구들이 이루어졌습니다. 이에 대표적인 모델로는 VirTex가 존재하며 해당 모델은 pre-trained Image captioning task를 목표로 수행되어진 연구입니다. 그러나 이러한 초기 연구 방향성들의 한계점으로 너무 큰 모델 사이즈와 긴 학습 시간 소요가 존재하였습니다.
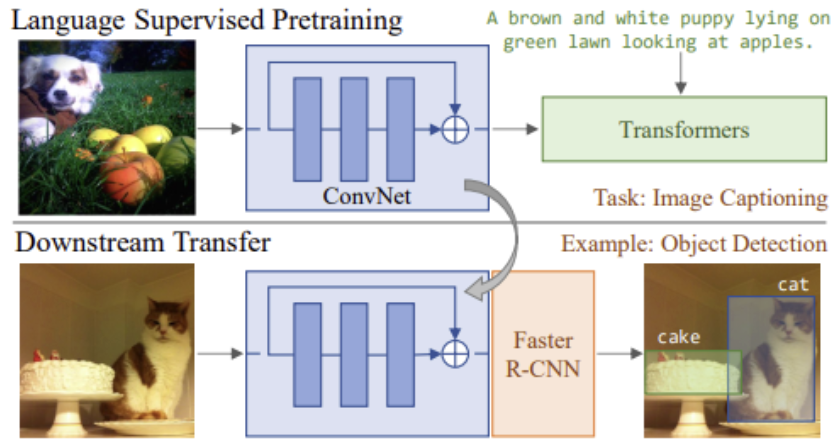
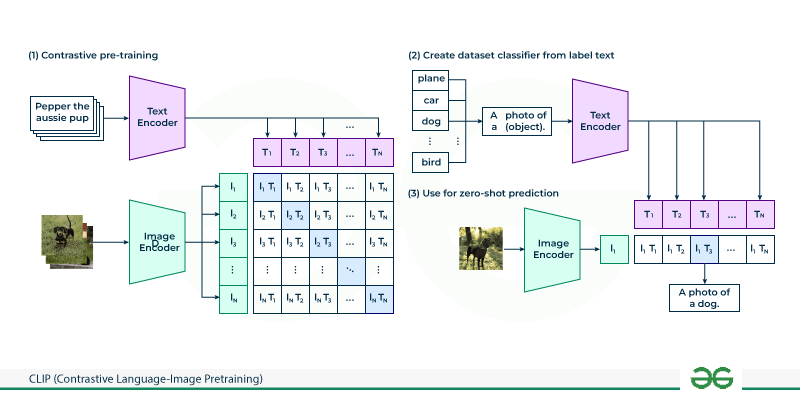
그렇기에 본 논문에서는 위 사진처럼 Contrastive learning을 활용하여 이미지와 텍스트의 pair에 대해 유사도를 학습하고자 하였습니다. 이를 통해서 Downstream Task로의 transfer 성능 또한 추가적인 작업 없이 수행이 가능하게 하고자 하였습니다.
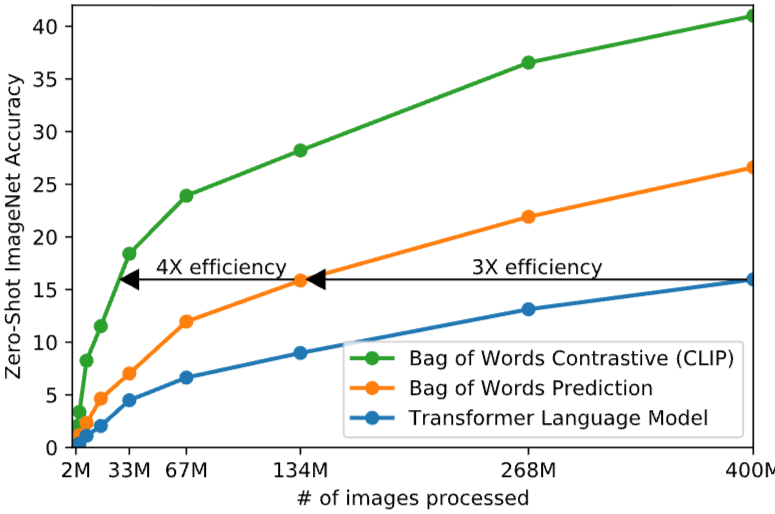
위의 그래프는 Image와 Text의 관계성에 대해서 학습을 모델의 학습 속도와 함께 비교한 그래프입니다. 기존의 Beg of words prediction보다 Transformer 언어 모델은 약 3배 느린 것을 볼 수 있습니다. 하지만 본 논문에서 제안하고 있는 CLIP를 보시게 되면 Transformer 언어 모델보다 약 7배 정도 빠른 것을 확인할 수 있습니다.
3. Method
본 논문에서는 Method라는 섹션은 없으나 설명의 편의를 위해서 Method를 따로 빼서 작성해보도록 하겠습니다.
1. Contrastive pre-training
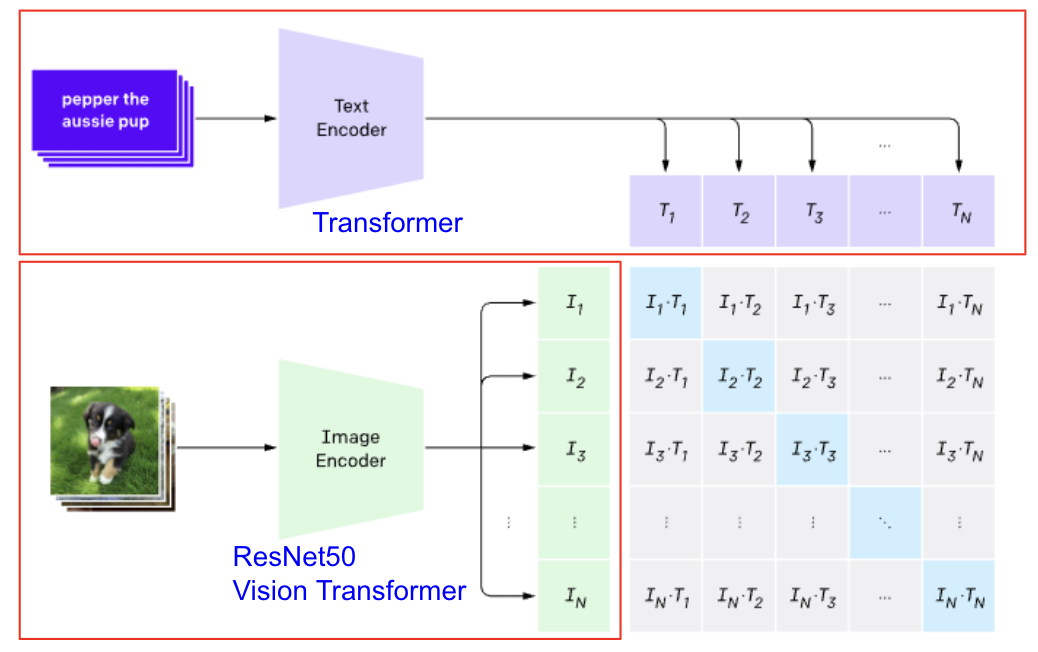

I_f = image_encoder(I)
T_f = text_encoder(T)N개의 이미지, 텍스트를 각각 Encoder를 통과 시켜 Embedding vector에 대해서 계산을 수행하게 됩니다. 이때, 여기서 N은 batch 사이즈를 의미하고 있으며 CLIP의 특징 중 하나는 해당 Batch 사이즈가 엄청 큰 것을 확인 할 수 있습니다.
먼저 Image encoder부터 확인해보겠습니다. ResNet 기반의 인코더는 ResNet-50을 기반으로 합니다. 특히, 개선이 이루어진 ResNet-D를 적용하였으며 Antialiased rect-2 blur pooling을 사용했단 점과 Gloal average pooling 레이어를 attention pooling mechanism으로 대체하였습니다. 해당 attention pooling은 이미지의 gloal average pooling에 기반한 query로 Transformer의 multi-head QKV Attention 단일 layer로 구현됩니다. ViT의 경우, 이전에 리뷰했던 ViT mechanism을 그대로 따르고자 하였으며 Patch와 positional embedding에 추가적으로 layer Normalization을 추가하였습니다.
이제 Text encoder에 대해서 확인해보겠습니다. Transformer 기반으로 이루어졌으며 약간의 architecture가 수정되었습니다. 먼저, 63M 파라미터, 12 레이어, 512-wide, 8개의 어텐션 헤드를 가진 기본 크기 모델을 사용하고 있으며 49,152개의 word size를 가지게 됩니다. 더불어 계산 효율성 측면에서 이점을 가져가고자 sequence length의 경우, 76으로 제한하여 사용하고 있습니다.
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)각각의 모달리티에 해당하는 인코더를 거친 feature에 대해서 이들을 Multi-modal embedding space에 투영하기 위해서 projection matrix와 연산을 하여 임베딩 공간의 차원에 linear projection을 수행하고자 합니다. 이후, l2_normalize를 통해서 길이를 최대 1로 만들게 됩니다. 이는 이후에 수행하는 코사인 유사도 계산시 내적이 곧 유사도 값이 되도록 하기 위해서 수학적 트릭을 활용한 것입니다.

logits = np.dot(I_e, T_e.T) * np.exp(t)이후, 이미지와 텍스트의 embedding vecotr에 대해서 cosine similarity 계산을 수행하게 되며 batch 사이즈에 해당하는 정방행렬에 대해서 1개의 Positive pair와 N-1개의 Negative pair가 생성되어집니다. 즉, 앞서서 L2 정규화가 수행되어진 이미지와 텍스트의 embedding vector에 대해서 내적을 수행하고 코사인 유사도를계산한 때, 정규화로 인해서 내적의 값이 유사도 값이 되도록 하였습니다.
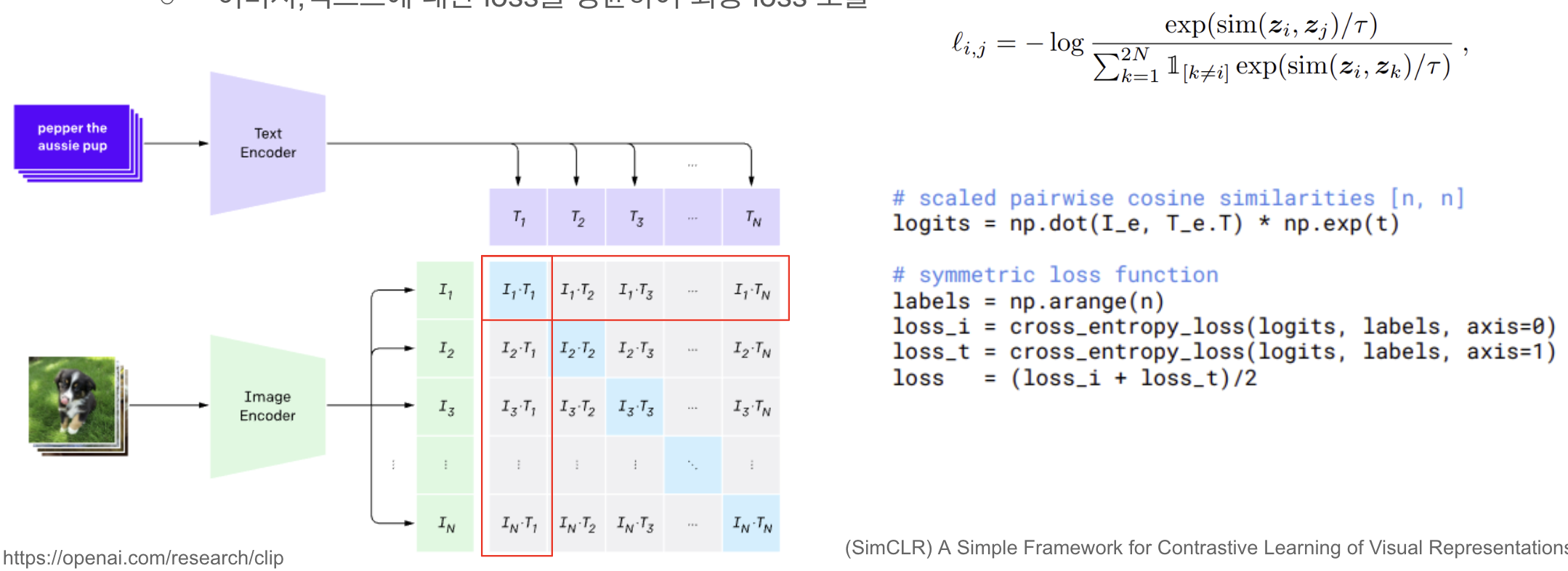
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2마지막으로 이미지와 텍스트에 대한 Cross-entropy loss를 계산하게 됩니다. 이후, 이미지와 텍스트에 대한 loss를 서로 더한 다음에 나눠 평균을 구해 이를 최종 loss로 활용하고자 합니다.
2. (Inference) Dataset classifier from label text
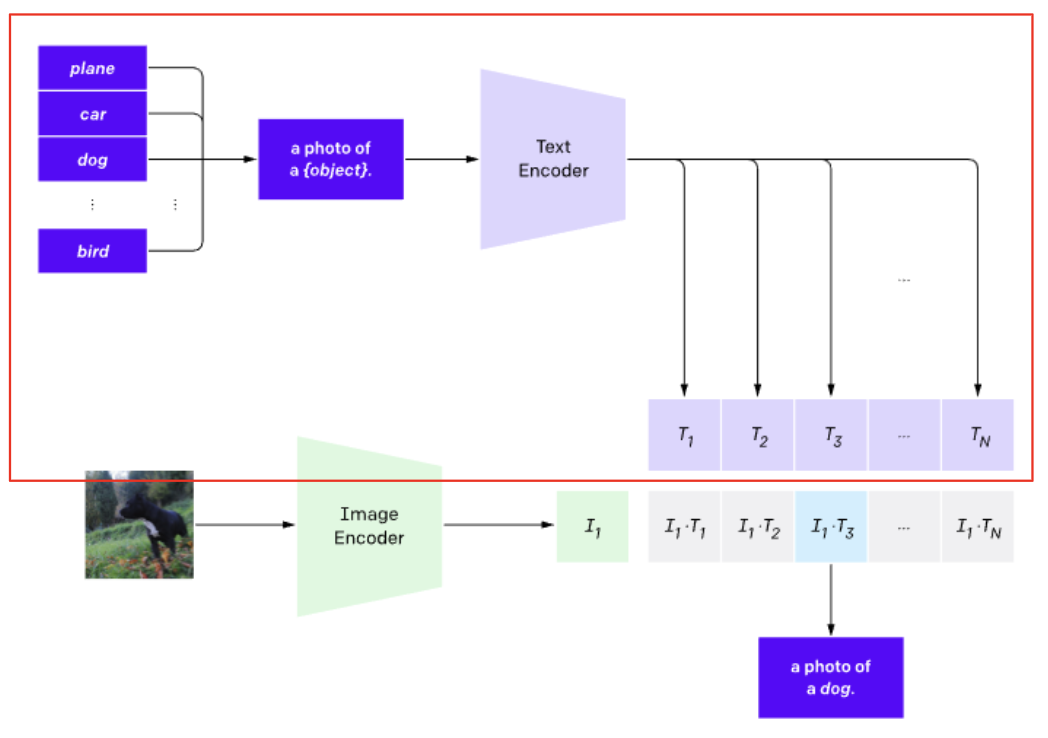
이전까지 Training에 대해서 알아봤습니다. 해당 섹션에서는 이를 실제로 추론하는 과정에 대해서 확인해보도록 하겠습니다. 분류하고자 하는 class label들에 대해서 prompt engineering을 수행하게 됩니다. 이때 여기서 이야기하고 있는 prompt engineering은, 기존의 class label들이 plane, car, dog와 같이 단어로 이루어져있는데 이걸 문장으로 바꾸고자 하는 것입니다. 예를 들어 기존의 class label이 plane이었다면 이를 'a photo of a {object}'로 바꾸고자 합니다. 이러한 문장들을 텍스트 인코더로 넘긴 다음에 text embedding을 추출하게 됩니다. 이때, prompt engineering이 Image classification 성능을 좌우할 정도로 상당히 중요한 작업입니다. 단어보다는 문장으로 구성하는 것이 해당 이미지에 대한 Desripcion 성격이 부여되기 때문에 해당 과정을 수행하게 됩니다.
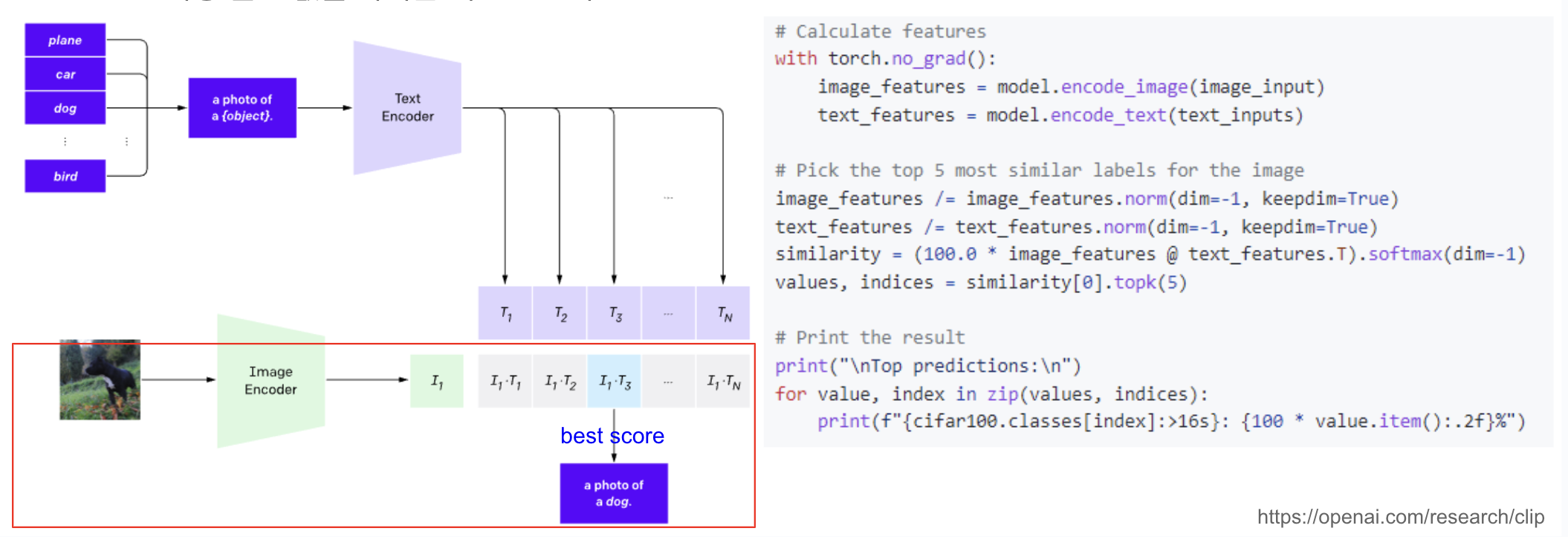
이후, 입력 이미지를 image encoder를 통해 embedding vector를 계산합니다. 이렇게 prompt engineering을 통한 Text embedding과 image의 embedding vector를 모두 구하게 되었으며 이들의 cosine similarity를 계산하게 됩니다. 최종적으로 이 중 가장 높은 값을 가지고 있는 텍스트를 선택하게 됩니다.
Experiments
Settings
CLIP는 위에서 저희가 리뷰했듯이 image encoder와 text encoder로 구성되어 있습니다. 특히, Text encoder의 경우 Transformer를 활용했으나 Iamge encoder의 경우, 다양한 모델을 활용하고 있습니다. 먼저, ResNet50 series를 활용했으며(ResNet-50, ResNet-101, ResNet-50 x 4, ResNet-50 x 16, ResNet-50 x 64) ViT model(ViT-B/32, ViT-B/16, ViT-L/14)를 활용했습니다. 여기서 주의하실 점음 ViT의 경우, 모델 사이즈가 커짐에 따라 patch size를 작게 한 것을 볼 수 있습니다. 이전 리뷰에서 이야기했듯이 patch 사이즈가 작게 되면 그만큼의 sequence length가 증가하게 됩니다. 이로 인해서 컴퓨팅 연산량이 증가하게 되지만 이는 그만큼 detail하게 보기 때문에 성능 향상으로 이어지게 됩니다.
본 논문에서는 CLIP Best model을 기준으로 이야기하고 있으며 구성은 다음과 같습니다.
Image encoder: ViT - L, patch size: 14
Text encoder: Transformer(63M params, 21 - layers, 8 - multi head attention)
Input size = 336 x 336
1. Zero-shot Transfer
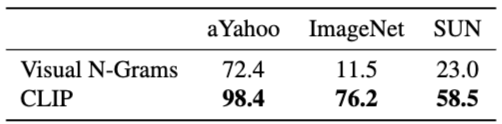
Visual-N-Grams와 CLIP의 Zero-shot transfer 성능을 비교하고자 합니다. Visual-N-Grams는 이미지와 짝을 이루는 텍스트 문서에 명사 및 형용사 N-gram을 예측하여 이미지 표현을 학습하는 초기 연구 중 하나입니다. 모든 데이터셋에서 CLIP가 압도적은 성능 향상을 기록하였습니다. 이는, 웹에서 가지고 온 방대한 크기의 자연어 데이터셋과 prompt engineering에서 비롯된 결과임을 시사하고 있습니다.
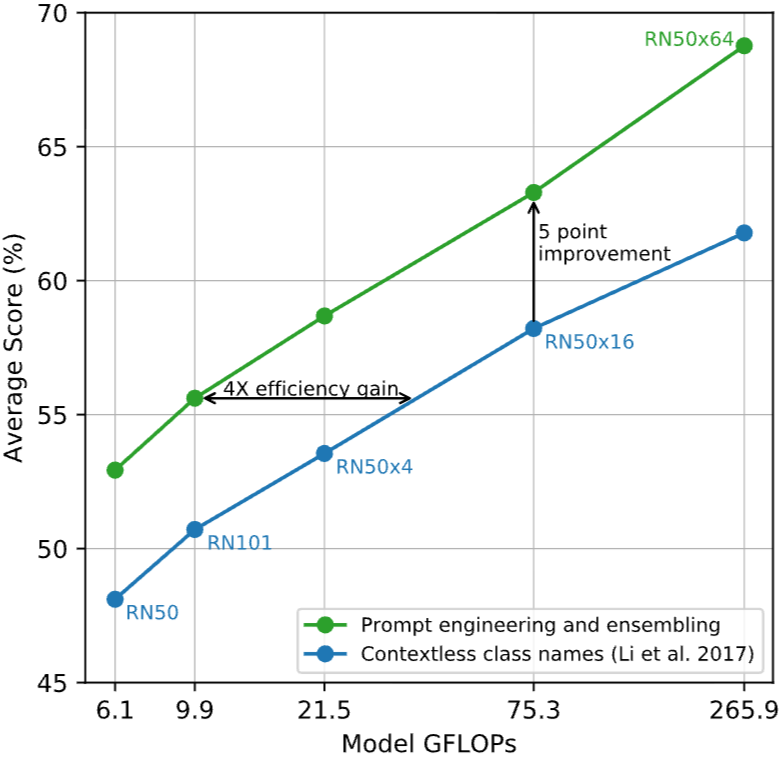
특히, 위 사진을 보시게 되면 Prompt Engineering & ensembling에 대한 연구 결과입니다. 총 80가지의 Prompt를 적용시켰으며 예를 들어, a photo of a samll {object}, a photo of a big {objec} 등이 있습니다. 특히, Embedding space에서 ensembling을 적용하였으며 모델의 연산량 즉, 모델 사이즈가 커질 수록 성능이 향상되고 있음과 함께 Prompt Engineering이 얼마나 성능에 중요한 영향을 주는지를 확인할 수 있습니다.
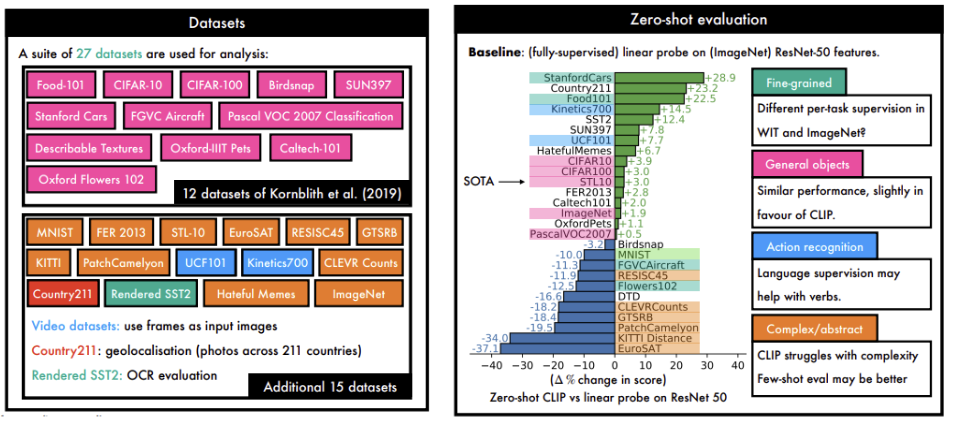
Zero-shot Transfer 성능이 generality가 있는 dataset에서는 성능 향상을 보여줬으며 오히려 Downstream Task나 resolution이 매우 작은 데이터셋들에 대해서는 성능이 오히려 하락한 모습을 보여줬습니다.
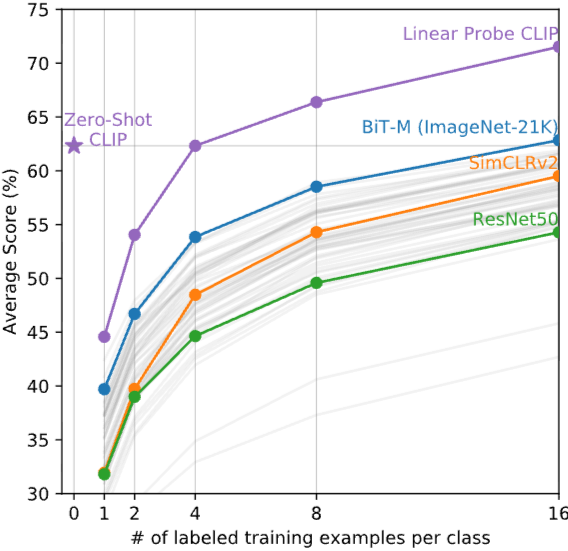
다음은 Zero-shot과 Few-shot linear probesdml 성능 결과를 비교하고자 합니다. 이때, linear probes는 이미지 인코더로부터 embedding vector를 추출하고 이를 logistic regression classifier을 수행하여 즉, 선형 분류기를 통해서 최종 출력을 구하게 됩니다. 본 논문에서 제한하고 있는 zero-shot 성능이 이전까지 선행되었던 연구들의 few shot 성능과 비교했을 때 더 효율적임을 확인할 수 있으며 오히려 애매한 few shot의 경우 오히려 zero-shot보다 성능이 좋지 않았음을 볼 수 있습니다.
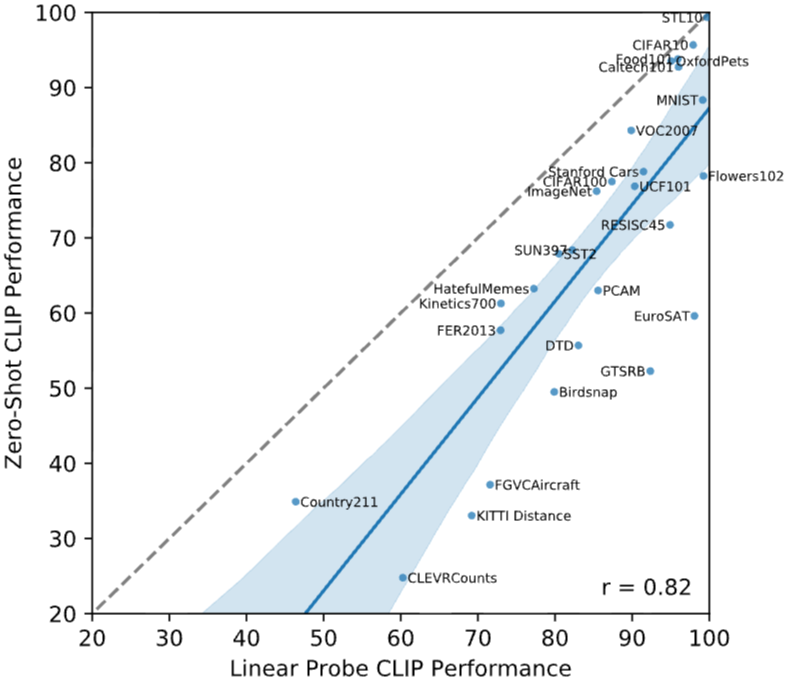
여기서 회색 점선은 zero-shot 성능과 lienar probe의 성능이 동일한 것을 의미하고 있습니다. 이때, 그림을 자세히 보시게 되시면 몇몇 Task에서 zero shot 성능이 linear probe와 동일한 경우도 존재하고 있음을 볼 수 있지만 그럼에도 대부분의 Task에서 아직까지는 lienar probe의 성능이 더 좋음을 볼 수 있습니다.
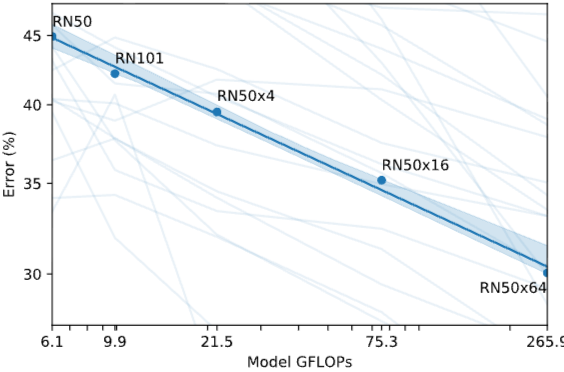
또한 모델의 사이즈가 커지면 커질수록 연산량이 커짐과 동시에 정확도는 꾸준히 상승하고 있음을 확인할 수 있습니다.
2. Representation Learning
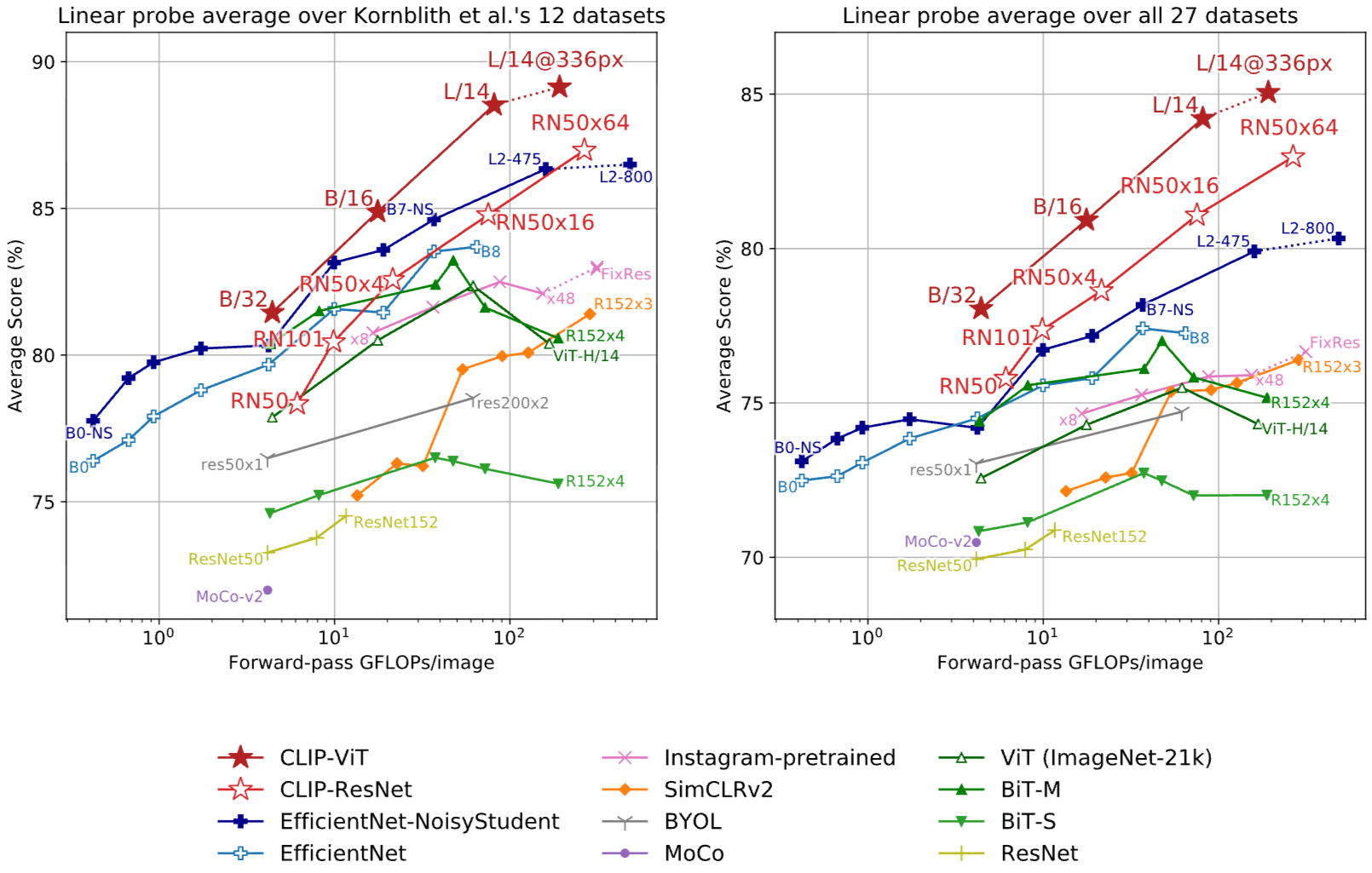
이미지 크기에 따른 성능 그래프를 나타냈으며 CLIP이 경우, ViT와 ResNet에 대해서 모두 표현하고 있습니다. 이 두 CLIP에서 모두 전반적으로 계산 복잡도가 커짐에 따라서 성능이 꾸준히 향상하고 있음을 확인할 수 있었으며 ViT 계열의 접근 방식이 ResNet보다 더 높은 성능을 보여주고 있습니다. 더불어 이전에 수행되어진 연구들의 접근 방식에서 연산량이 커짐에 따라서 성능이 꾸준히 상승하는 것이 아니라 일정 수준에서 하락 혹은 횡보를 보이고 있음도 확인할 수 있습니다.
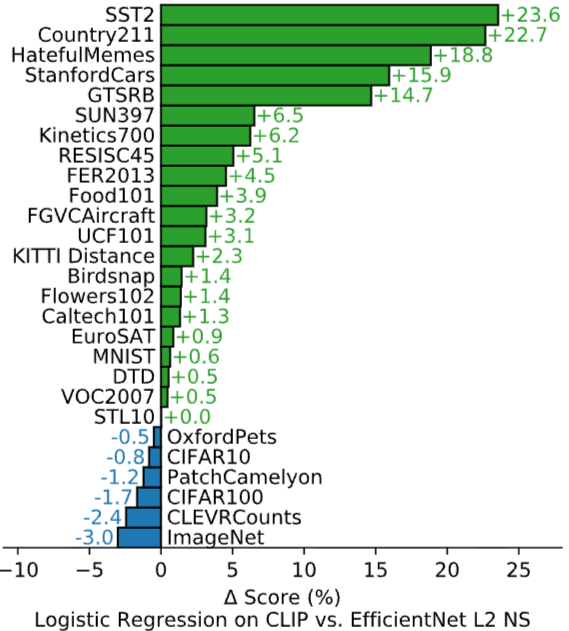
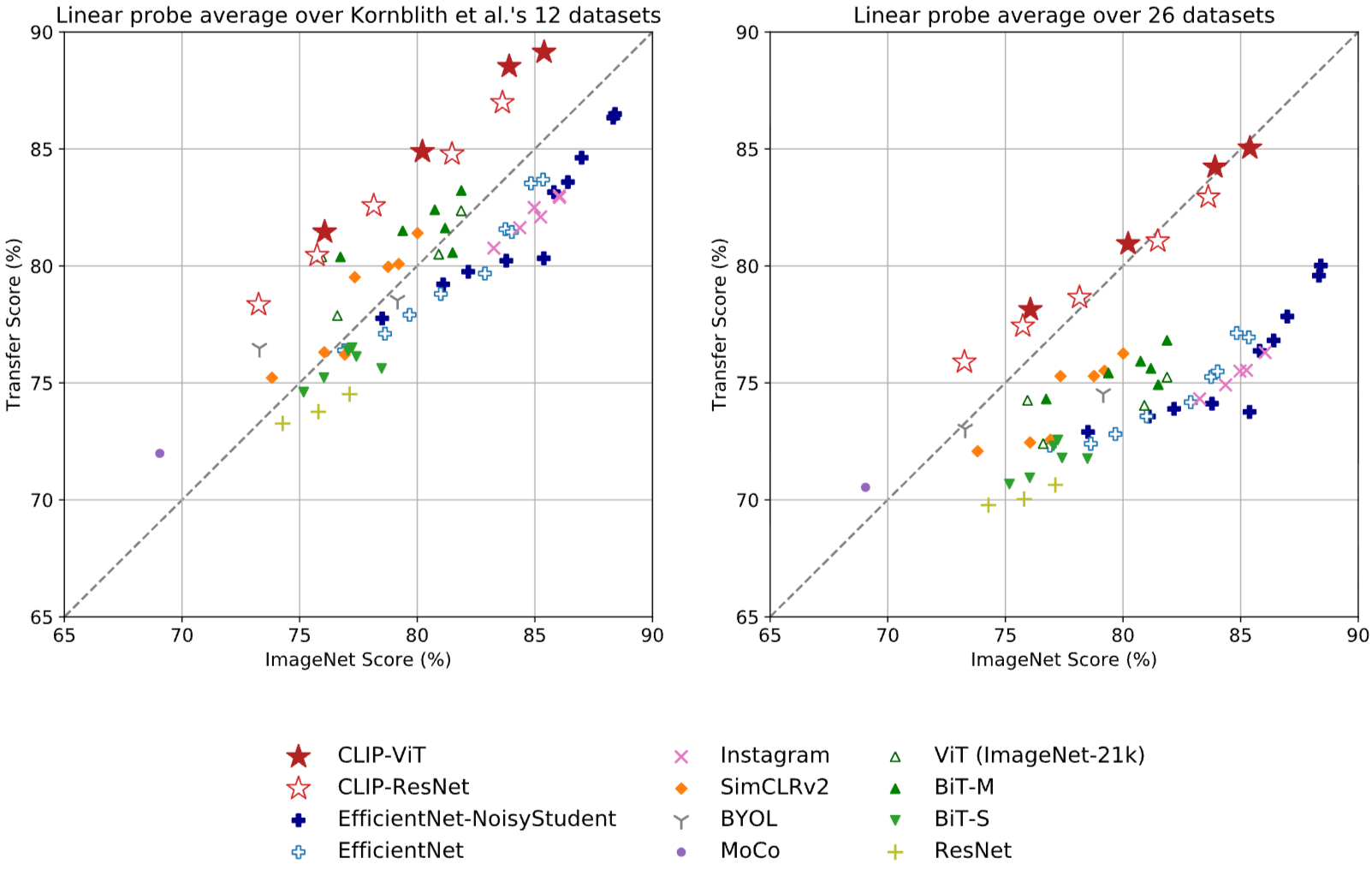
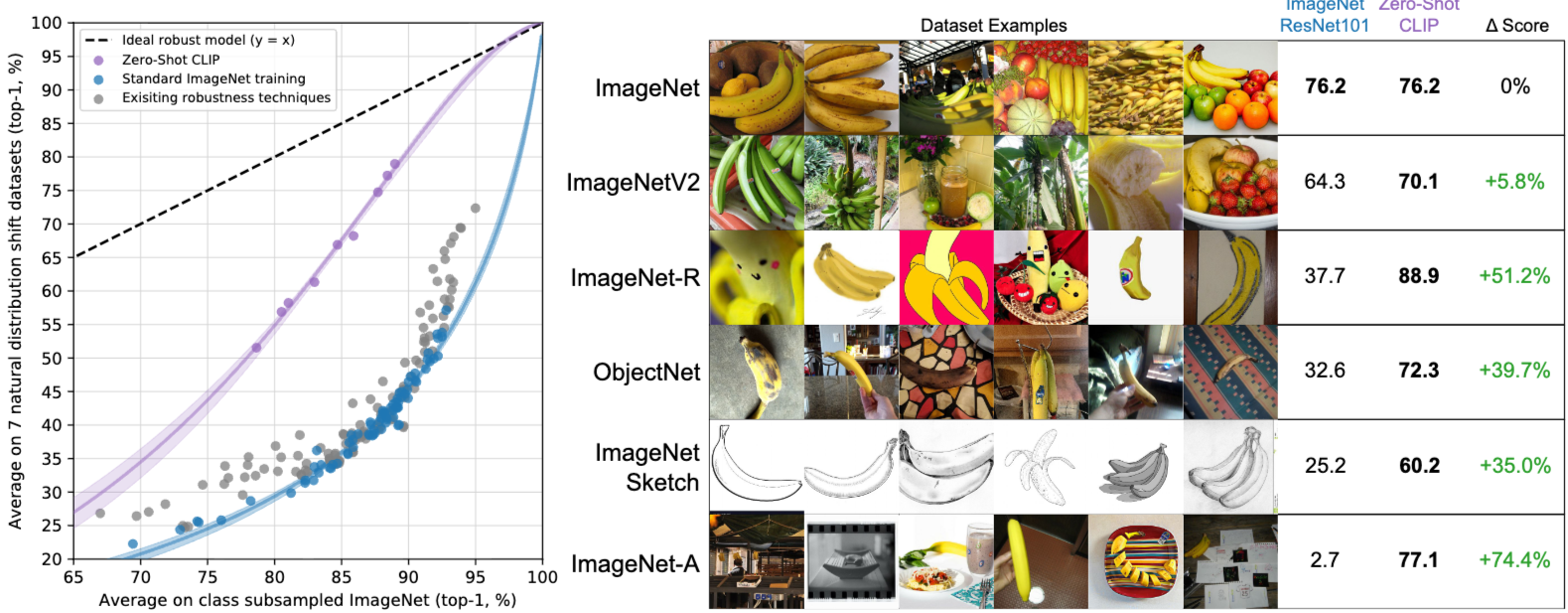
위 결과들은 광범위한 다운스트림 작업에서 CLIP가 뛰어난 전이 학습 능력을 가질 수 있음을 보여줍니다. 이는 기존의 ImageNet과 같은 특정 데이터셋에만 의존하는 사전 학습 방식의 한계를 극복하고, 다양한 시각적 개념을 이해하는 데 있어 Natural Language에서 supervision을 추출하여 representation을 이해하고 학습하는 것이 중요함을 시사하고 있습니다.
이외에도 다양한 실험 결과들이 존재하지만 다양한 시각적 개념을 이해하는 데 있어 Natural Language에서 supervision을 추출하여 representation을 이해하고 학습하는 것이 중요함을 시사하고 있음에 대해서 이야기하고 있습니다.
Contributes
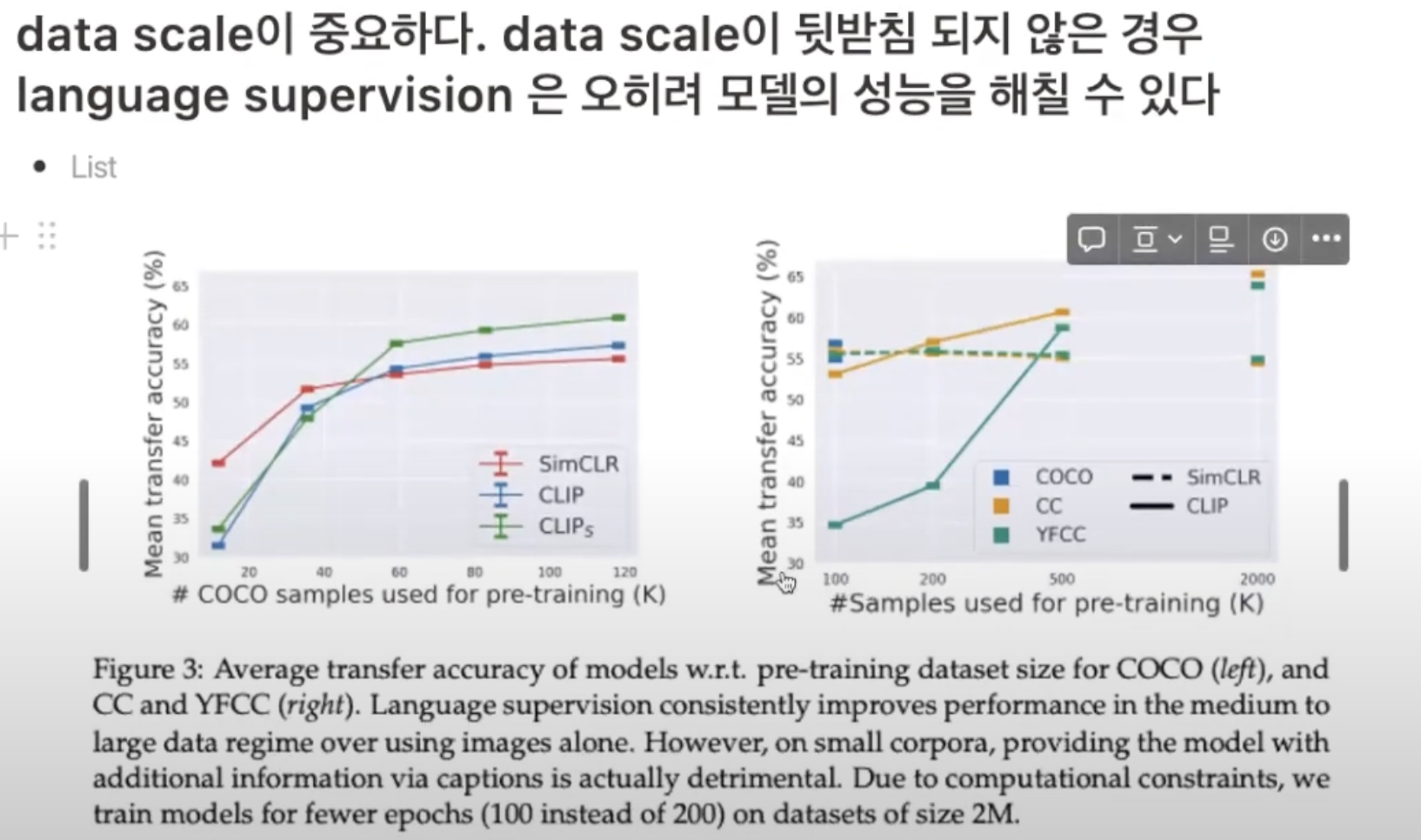
CLIP에서 Text로부터 Supervision을 추출하고 이를 이미지의 representation으로 이해하고 학습하는데 Data Scale이 중요함에 대해서 이야기하고 있습니다. 오히려 데이터셋의 스케일이 작은 경우 language의 supervision에 대해서 학습이 제대로 이루어지지 않기 때문에 CLIP의 경우, Data Scale가 상당히 중요함을 알 수 있습니다.

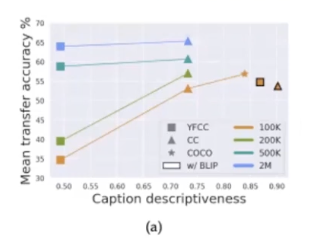
더불어 Prompt engineering에서 caption의 중요성에 대해서 이야기하고 있습니다. 단순히 단어로 되어있는 caption보다 문장으로 구성된 caption의 성능이 더 좋으며 더 자세하고 상세하게 표현된 cpation이 더 성능이 좋음에 대해서 이야기하고 있습니다. 특히 스케일이 작은 데이터셋에서 해당 description은 매우 중요한 역할을 차지하고 있습니다. 하지만 그렇다고 해서 이미지 한장당 여러 caption이 존재하는 것은 오히려 성능 하락의 원인이 될 수도 있습니다. 본 논문에서는 하나의 이미지의 10개의 caption이 존재하는 경우, saturation 된다고 이야기 하고 있습니다.
Conclusion
본 논문의 CLIP 제안으로 general한 model을 만들어 놓고 다양한 downstream task에서 준수한 성능을 기록하였습니다. 이 과정에서 대규모 데이터셋 구축과 image classification의 성능 향상을 위해서 text의 supervision을 학습하고 이를 기반으로 image와의 representation에 대해서 contrastive learning을 통해서 유연함과 성능을 갖출 수 있었습니다. 하지만 이러한 접근에도 불구하고 아직 성능 측면에서 개선되어야 하는 부분들이 많이 남아 있음에 대해서 이야기하며 본 논문은 마무리하고 있습니다.
이렇게 CLIP 논문에 대해서 함께 리뷰해봤습니다. 틀린 점도 있겠지만 언제나 피드백 주시면 감사하겠습니다!
