--32.양방향LSTM(bi-LSTM).ipynb--
개체명 인식
RNN 이나 LSTM 은 일반 신경망과 다르게 시퀀스 또는 시계열 데이터 처리에 특화되어 은닉층에서 과거의 정보를 기억할 수 있습니다. 그러나, 순환 신경망의 구조적 특성상 데이터가 '입력 순' 으로 처리되기 때문에 이전 시점의 정보만 활용할 수 밖에 없는 단점이 존재합니다. 문장이 길어 질수록(시퀀스가 길어질수록) 성능이 저하될 수 밖에 없습니다. 다음 예문을 봅시다
ios 앱 [ ]은 맥북이 필요합니다
ios 앱 개발은 맥북이 필요합니다
한국어를 사용하는 우리에겐 어렵지 않게 빈칸에 들어가는 단어를 유추해낼수 있다. 그러나 일반적인 RNN 이나 LSTM 에서는 'ios' 와 '앱' 이라는 단어만 가지고 빈칸에 들어갈 '개발' 이라는 단어를 유추해 내기엔 정보가 매우 부족하다.
문장 앞부분보단, 뒷부분에 중요한 정보가 존재하기 때문입니다.
따라서! 자연어 처리에서 입력 데이터의 '정방향' 처리만큼 '역방향' 처리도 중요합니다!
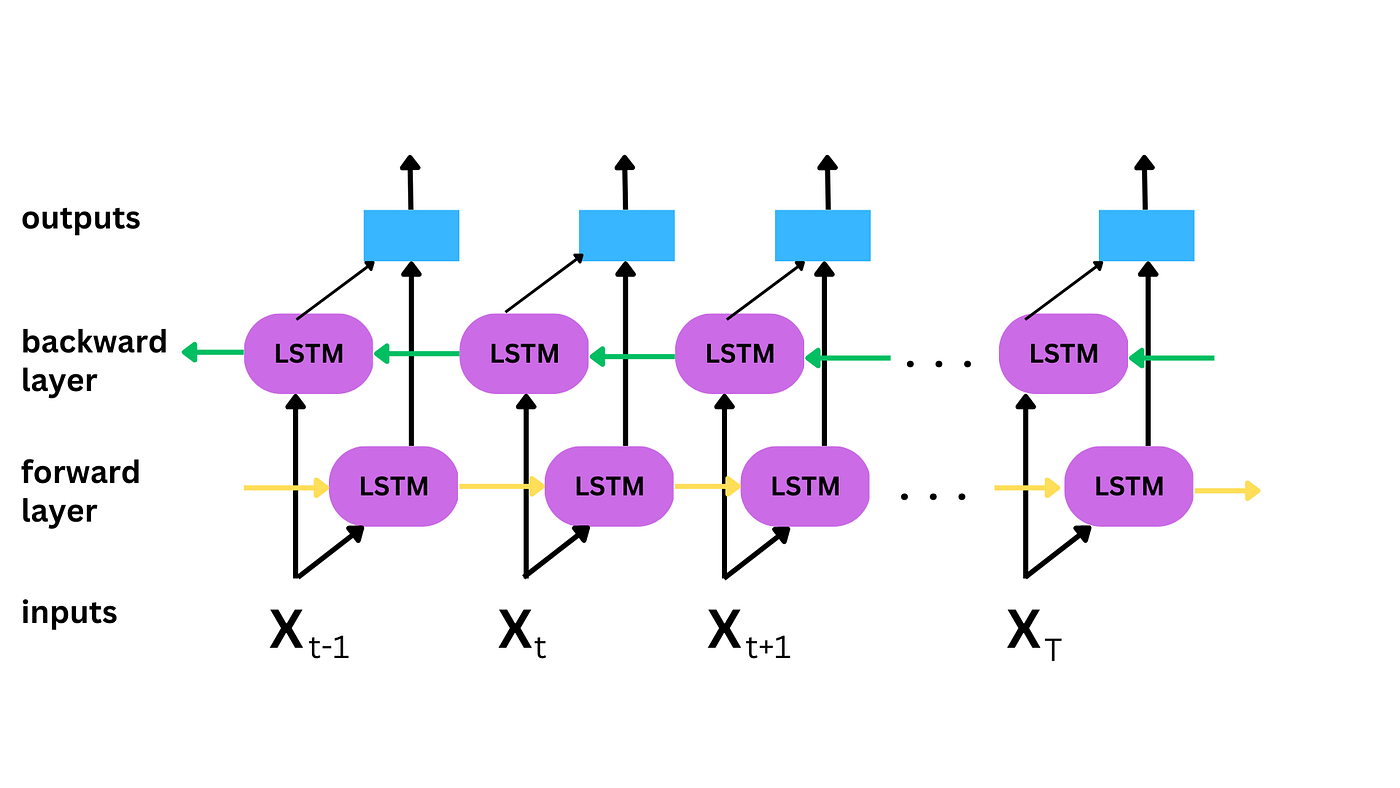
양방향 LSTM (Bidirectional LSTM) 은 기존 LSTM 계측에 역방향으로 처리하는 LSTM 계층을 하나 더 추가해 양방향에서 문장의 패턴을 분석할수 있도록 구성되어 있습니다. 입력 문장을 양방향에서 처리하므로 시퀀스 길이가 길어진다 하더라도 정보 손실 없이 처리가 가능
import numpy as np
from random import random
import os
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Bidirectional, LSTM, Dense, TimeDistributed, Input
시퀀스 생성
def get_sequence(n_timesteps) :
0 ~ 1 사이의 랜덤 시퀀스 생성
X = np.array([random() for _ in range(n_timesteps)])
클래스 분류기준
limit = n_timesteps / 4.0
y= np.array([0 if x < limit else 1 for x in np.cumsum(X)])
LSTM 입력을 위해 3차원 형태로 변경
ex) (4,) -> (1, 4, 1)
X = X.reshape(1, n_timesteps, 1)
y = y.reshape(1, n_timesteps, 1)
return X, y
X, y = get_sequence(4)
print(X.shape)
X
print(y.shape)
bi-LSTM 모델
tf.keras.layers.TimeDistributed
- 각 time 에서 출력된 output 을 내부에 선언해준 레이어와 연결시켜주는 역할
- TimeDistributed 또한 Wrapper 다 (Wrapper 상속객체)
- https://www.tensorflow.org/api_docs/python/tf/keras/layers/TimeDistributed
tf.keras.layers.TimeDistributed(
layer, **kwargs
)tf.keras.layers.Bidirectional
- RNN 에 적용하는 양방향 (bidirectional) wrapper
- https://www.tensorflow.org/api_docs/python/tf/keras/layers/Bidirectional
tf.keras.layers.Bidirectional(
layer,
merge_mode='concat',
weights=None,
backward_layer=None,
**kwargs
)하이퍼 파라미터
n_units = 20
n_timesteps = 4
Bidirectional 래퍼(wrapper) 를 사용하여 LSTM을 양방향으로 설정
model = Sequential()
model.add(Input(shape=(n_timesteps, 1)))
model.add(Bidirectional(LSTM(n_units, return_sequences=True)))
model.add(TimeDistributed(Dense(1, activation='sigmoid')))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
양방향 LSTM 모델을 정의할때 주의점!
- 정방향, 역방향 LSTM 계측 모두 출력값을 연결해야 하기 때문에, return_sequences 인자를 반드시 True 로 해야 함.
- 또한 Dense 계층을 TimeDistributed 래퍼를 사용해 3차원 텐서를 입력받을수 있게 확장해야 한다
for epoch in range(1000) :
X, y = get_sequence(n_timesteps)
model.fit(X, y, epochs=1, batch_size=1)
평가
X, y = get_sequence(n_timesteps)
predict = model.predict(X)
result = predict.argmax(axis=-1)
for i in range(n_timesteps) :
print('실제값 : ', y[0, i], '예측값 : ', result[0,i])
