--10.데이터분석으로 심부전증을 예방할 수 있을까?.ipynb--
의료 데이터 셋에 대하여
의료 데이터의 수집
- 의료데이터는 어떻게 '수집' 이 되느냐 부터가 굉장히 중요
- 우리나라는 2020.1월에 새로운 법이 통과! => 데이터 3법
- 그중에 가장 핵심은 개인정보에 대한 것
- 의료정보는 굉장히 민감한 개인정보들이 많기 때문에, 수집이 되더라도, 사람들에게 전파되기 어려운 법적인 특성을 있었습니다. - '가명정보' 를 사용할수 있게 허용됨.
- '실명정보' 에서 개인식별 정보를 비식별화 (de-identification) 과정을 거쳐서 만들어진 데이터, 쉽게 말해서 가명정보화 하여 일반적으로 사용할수 있는 데이터화 하여, 이후에 관련분야 민간 연구자들에게도 전달될수 있도록 하여 제공하도록 함 --> 데이터3법을 통해 의료데이터에 생긴 핵심적인 변화.
- 2020년동안 많은 분들이 '바이오 데이터 분석가' 라든지 '4차 산업 혁명' 에 이어 '바이오 데이터' 관련 된 것들이 뜨기 시작함. (법적인 배경이 있었던 것이다)
- 교육현장, 민간 사업체 등에서 공공데이터로 제공이 됨.
- 데이터를 생산해서 제공하는 의료기관이라든지, 연구기관들에서 더 인센티브를 주는 방식으로 하여 데이터 생산을 더더욱 독력하는 중.
- 그리하여 의료데이터 수집이 가속회 되고 있고, 그에 따라 의료데이터를 다룰 인력들에 대한 수요가 점점 늘어나고 있다.
- 기본적으로 가공해서 업로딩 하는 데이터 엔지니어
- 데이터분석, 모델링 활용하는 사람들
의료 데이터 분석의 현재
- 우리나라는 이제 걸음마 단계. (그동안 법적 제약)
- 그 이전에는 주로 연구 되었던 것들이 의료 영상 같은 것들. MRI, CT (3D 스캔)
- 병 판명, 등에 사용
- 아직 분석의 결과는 이렇다 할만한게 없다.
- 의료 데이터를 적극 사용해왔던 국가들
- 핀란드 : 환자들에게 전자포털 제공, 자신의 데이터를 제공할지 안할지 관리 가능케 함. 인프라 잘 구성됨.
- 덴마크 : 국가에서 포털 구축, 진료기록 99% 에게 환자 주치의에게 전달됨. 과거 기록들을 통해 더 좋은 진료서비스, 개인 병력, 과거 어떤 치료 진료 내역등이 공유됨.
- 영국 : 전자 의무 기록 활용
- 중국 : 의료 융합 추진, 병원 공실률 down 시켜 의료 인프라 효율적 활용. 특정 병원에 사람이 쏠리지 않도록 함. 국가적으로 컨트롤 함.
- 미국 : 주로 연구및 연구 발표 활발. 민간단체에서 임상데이터 수집 가능. 연구가능한데이터 많이 취득함. 의료 빅데이터 관련해서만 논문이 100건 이상 나오는 중.
- 대한민국 : 우리는 이제 걸음마 시작단계, 할일이 많다. 다른 관점에서 보면, 의료 데이터 다루는 것이 국내에선 수요가 계속 늘어날 것이다! 그래서 이 분야 진입은 전망이 좋다.
주제 : 데이터 분석으로 심부전증을 예방할 수 있을까?
실습 가이드
- 데이터를 다운로드 불러옵니다.
- 코드는 위에서부터 아래로 순서대로 실행합니다.
데이터 소개
- 이번 주제는 Heart Failure Prediction 데이터셋을 사용합니다.
- 다음 1개의 csv 파일을 사용합니다.
heart_failure_clinical_records_dataset.csv - 각 파일의 컬럼은 아래와 같습니다.
- age: 환자의 나이
- anaemia: 환자의 빈혈증 여부 (0: 정상, 1: 빈혈)
- creatinine_phosphokinase: 크레아틴키나제 검사 결과
- diabetes: 당뇨병 여부 (0: 정상, 1: 당뇨)
- ejection_fraction: 박출계수 (%)
- high_blood_pressure: 고혈압 여부 (0: 정상, 1: 고혈압)
- platelets: 혈소판 수 (kiloplatelets/mL)
- serum_creatinine: 혈중 크레아틴 레벨 (mg/dL)
- serum_sodium: 혈중 나트륨 레벨 (mEq/L)
- sex: 성별 (0: 여성, 1: 남성)
- smoking: 흡연 여부 (0: 비흡연, 1: 흡연)
- time: 관찰 기간 (일)
- DEATH_EVENT: 사망 여부 (0: 생존, 1: 사망)
- 데이터 URL: https://www.kaggle.com/andrewmvd/heart-failure-clinical-data
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import os
base_path = r'/content/drive/MyDrive/dataset'
file_path = os.path.join(base_path, 'heart_failure_clinical_records_dataset.csv')
df = pd.read_csv(file_path)
df
EDA 및 데이터 기초 통계 분석
Dataframe 의 각 컬럼 분석하기
shape, head(), info(), describe() <- 왜 하느냐 이걸로 뭘 얻고자 하느냐가 중요!!!
df.head()
df.info() # 결측치가 있는지 없는지, 데이터 타입은 어떻게 이루어져있는 것인가.
"""
현재 EDA 를 수행하고 있습니다.
데이터들의 숫자드을 쓱 눈으로 보는것 먼저 해봅시다.
age : 환자의 나이 (숫자형) <- 정수값일줄 알았는데 float 타입으로 읽혀짐. 확인해볼 필요 있음.
anaemia : 빈혈증 여부 0, 1 값만 가지고 있슴 확인 (분류형) (0: 정상, 1: 빈혈)
creatinine_phosphokinase : 크레아틴키나제 검사 결과 (숫자형, 수치형)
diabetes : 당뇨병 여부 0, 1 값만 가지고 있슴 확인 (분류형) (0: 정상, 1: 당뇨병)
ejection_fraction : 박출계수 (%) 심박이 이루어질때 나오는 피의 비율 0 ~ 100 (숫자형, 수치형)
high_blood_pressure : 고혈압 여부. 0, 1 값만 가지고 있슴 확인 (분류형) (0: 정상, 1: 고혈압)
platelets : 혈소판 수치 (kiloplatelets/mL) 단위. 혈액 ml 당 (숫자형, 수치형)
serum_creatinine: 혈중 크레아틴 레벨 (mg/dL) (숫자형, 수치형)
serum_sodium: 혈중 나트륨 레벨 (mEq/L) (수치형)
sex: 성별 0, 1 값만 가지고 있슴 확인 (분류형) (0: 여성, 1: 남성)
smoking: 흡연 여부 (분류형) (0: 비흡연, 1: 흡연)
time: 관찰기간 (일) (숫자형, 수치형)
DEATH_EVENT: 사망 여부 (분류형) (0: 생존, 1: 사망) <- 타겟값.
각 컬럼들이
"""
None
"""
info() 중요하다
특히 Non-Null 개수와 Dtype !!
지금은 총 299개의 ROW가 있고 인덱스 0 ~ 298
Non-null 이 '전부' 299 : 결측치(missing value) 확인
총 3개의 float 와 10개의 int로 되어 있슴.
간혹 데이터 타입이 잘 정의 되어 있지 않은 경우 object (파이썬 객체)로 되어 있는 경우가 있다.
그런 경우에는 데이터 타입을 변환해주어야 하는 전처리를 해주어야 할때도 있습니다.
지금은 그렇게 하지 않아도 될만큼 깔끔하게 정리되어 있다.
매우 깔끔(클린)한 데이터 셋이다!
비록 dtype 은 int 타입이나 '분류형'으로 보아야 하는 데이터들이 있다.
ex) DEATH_EVENT, smoking, sex, anaemia, diabetes, high_blood_pressure
"""
None
df.describe()
balanced vs imbalanced 여부 확인
outlier(이상치) 여부
이상치 (outlier)
이상치 (Outlier)란 관측된 데이터의 범위에서 많이 벗어나 아주 작은 값이나 아주 큰 값

이상치와 박스플롯 (box plot)

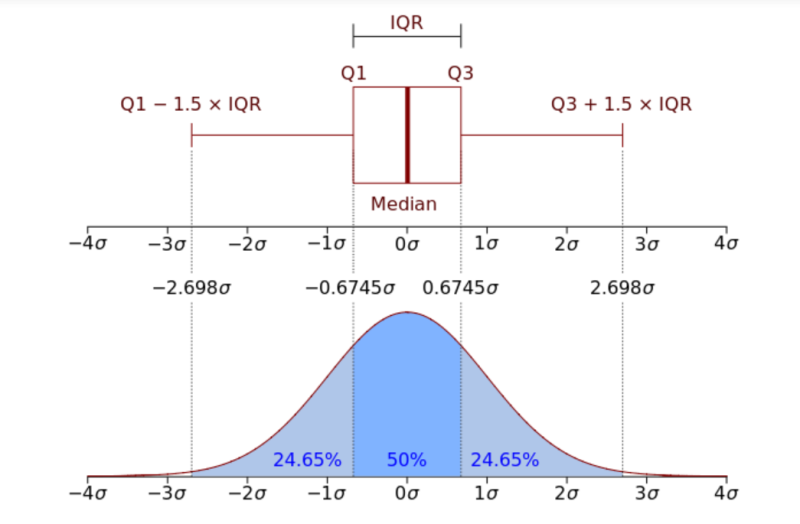
이상치 탐색을 위해 박스플롯으로 시각화하곤 합니다. 박스플롯은 다음과 같은 원리로 그려집니다.
박스플롯은 분위수를 기준으로 그려집니다.
상자 안에 그려져 있는 직선은 중위수(Median)을 나타냅니다.
상자의 밑변은 1분위수를 나타내며, 윗변은 3분위수를 나타냅니다.
상자를 중심으로 위 아래에, 직선이 있는 것을 볼 수 있습니다.
이 직선은 울타리라고 부릅니다.
상자로부터 아래 직선의 계산식 : Q1 - 1.5 (Q3 - Q1)
상자로부터 위 직선의 계산식 : Q3 + 1.5 (Q3 - Q1)
이 울타리를 벗어난 값들을 Outlier라고 부릅니다.
Outlier는 기본적으로 통계추정에 있어서 방해가 되고는 합니다.
통계분석은 전부 귀납법인데, 이상치같은 특수 케이스가 규칙을 만드는데 방해가 되기 때문입니다.
Outlier의 처리방법
-
제거를 하는 방법 (단점: 데이터가 버려진다)
-
데이터 변형을 통해 Outlier문제를 줄여줍니다.
- 통계추정에세는 정규분포를 맞추어 주는 것이 매우 중요합니다. 보통 Outlier로 인해 한 쪽으로 치우친 분포는 log 변환을 통해 정규성을 맞추어주고는 합니다.
df.describe()
"""
숫자로만 보면 알기 어려운 것들이 있다.
그래도 확인해볼수 있는 것들은
max, min 값이 과도하게 크거나 작은 것들
예를 들어 creatinine_phosphokinase 의 경우
min 값이 23 d이고 중앙값이 250 인데... max 값이 7861 이다!?!?
앞의 것들 min ~ 75% 의 증가세에 비하면 max 값이 상당히 큰 값이다. 상당한 outlier 에 해당한다 볼수 있다.
상위 몇개 데이터는 배제해볼 필요성도 있겠구나.. 라고 생각해볼수 잇습니다.
ejection_fraction : 크게 문제 없어 보인다
platelets(혈소판 수치) : 크게 문제 없어 보인다 . 증가세가 일정한 느낌
serum_sodium : 크게 문제 없어 보인다. 그러나 값의 범위가 좁은 느김
113 ~ 148 범위. 평균이 136 인데... std 가 4.4. 정도밖에 안된다.
time : 최소 4일 최대 285일 관찰 .. 285일이면 약 9개월 정도 관찰.
나중에 time 과 DEATH_EVENT 의 관계를 보면 될거 같다.
사망을 하게 되면 관찰이 멈출테니까.. 상당히 correlate 된 데이터라 볼수 있을듯.
잠시후에 다시 이야기 하도록 하죠.
"""
None
수치형 데이터의 시각화
나이(age)와 DEATH_EVENT 의 관계에 대한 분석
sns.histplot(x = 'age', data = df)
hue를 사용하기
sns.histplot(x = 'age', data = df, hue='DEATH_EVENT')
DEATH EVENT 가 0 / 1 두개의 값을 가지기에 두개의 색으로 쪼개어져 나온다
두개의 히스토그램이 '겹쳐' 있는 겁니다. (겹친부분이 회색) 쌓인(stack) 형태가 아닙니다
"""
DEATH_EVENT=1 : 사망하신 분들이 나이대별로 고루 분포되어 있다.
DEATH_EVENT=0 : 사망하지 않은분들은 나이가 젊은 쪽에 몰려 있슴을 확인할수 있다
"""
여기에 좀더 통계적으로 보려면 kde=True 를 주면 됩니다
None
kde : kernel dentisy estimate : 좀더 부드러운 곡선으로 (kde 플롯까지 같이 보여줌)
sns.histplot(x = 'age', data = df, hue='DEATH_EVENT', kde=True)
"""
상당히 범위가 많이 겹쳐 있기 때문에
age 가 DEATH_EVENT 를 가르는데에는 크게 유용하진 않을거 같습니다.
"""
None
creatinine_phosphokinase와 DEATH_EVENT의 관계 분석
df.columns
df.describe()
sns.histplot(x='creatinine_phosphokinase', data=df)
"""
일전의 '기술통계량'에서 보았듯이 outlier가 많다!
지금의 histogram 으로 유용한 데이터 얻기가 쉽지 않을 수 있다.
그래서 outlier를 배제하고 들여다보자. 3000이상은 떼어내고 보자.
"""
None
sns.histplot(x='creatinine_phosphokinase', data=df.loc[df['creatinine_phosphokinase'] < 3000])
'통계적인 특징'이 잘 드러나지 않는다
유용한 정보를 얻어내기 쉽지 않아보인다
ejection_fraction 와 DEATH_EVENT 와의 관계 분석
sns.histplot(x='ejection_fraction', data=df)
sns.histplot(x='ejection_fraction', data=df, bins=13, hue='DEATH_EVENT', kde=True)
platelets 와 DEATH_EVENT 의 관계에 대한 분석
sns.histplot(x='platelets', data=df, hue='DEATH_EVENT', kde=True)
'platelets' 와 'creatinine_phosphokinase' 와 'DEATH_EVENT와의 관계성 시각화.
jointplo
df.columns
sns.jointplot(x='platelets', y='creatinine_phosphokinase', hue='DEATH_EVENT', data=df, alpha=0.3)
"""
scatter 플롯으로 보이는 분포가 밑에 많이 뭉쳐있어서
DEATH_EVENT를 가르는데 도움이 되지는 않을 것 같다.
"""
None
범주형 데이터 통계 확인하기
seaborn의 Boxplot 계열(boxplot(), violinplot(), swarmplot())을 사용
Hint) hue 키워드를 사용하여 범주 세분화 가능
범주형 데이터의 경우
위 히스토그램 데이터를 볼수 있는 것과 달리
boxplot 을 통해 범주별로 따로 통계를 내야 어느정도 확인을 할수 있다.
흡연여부(smoking) 와 DEATH_EVENT 와의 관계 분석
smoking과 ejection_fraction부터 확인.
sns.boxplot(x='smoking', y='ejection_fraction', data=df, hue='smoking')
sns.violinplot(x='DEATH_EVENT', y='ejection_fraction', data=df, hue='DEATH_EVENT')
smoking, ejection_fraction,DEATH_EVENT 관계
sns.violinplot(x='DEATH_EVENT', y='ejection_fraction', data=df, hue='smoking')
sns.swarmplot(x='DEATH_EVENT', y='platelets', data=df, hue='DEATH_EVENT')
sns.swarmplot(x='DEATH_EVENT', y='platelets', data=df, hue='smoking',)
범주형 통계 확인
countplot() 사용
sns.countplot(x='DEATH_EVENT', data=df, hue='DEATH_EVENT')
df.describe()
성별(sex)와 DEATH_EVENT 통계 확인
sns.countplot(x='sex', data=df, hue='DEATH_EVENT')
파생변수 생성하여 분석하기
df['age']
나이대(age_span)컬럼을 추가
기존의 컬럼대신 새로운 컬럼데이터를 만든뒤 이를 분석에 활용
df['age_span'] = (df['age']/10).astype(int) * 10
df
df.groupby('age_span').size()
df.groupby('age_span').mean()
나이대별 사망자 수 계산하기
ab = df.groupby('age_span').sum()['DEATH_EVENT']
ab
plt.bar(ab.index, ab)
df2 = pd.DataFrame(ab)
df2
df2.sort_values(by='DEATH_EVENT')
df2.sort_values(by='DEATH_EVENT', ascending=False).plot(kind='bar')
pairplot은 모든 수치형 데이터에 대한 조합을 jointplot 으로 한번에 보여줌.
df.columns
sns.pairplot(df[['age', 'creatinine_phosphokinase', 'ejection_fraction', 'DEATH_EVENT']], hue='DEATH_EVENT')
데이터 전처리
from sklearn.preprocessing import StandardScaler
수치형 데이터만 스케일링 하면 된다. (이미 범주형 데이터는 0,1 <- one-hot encoding이 되어있다.)
df.columns
X_num = df[['age', 'creatinine_phosphokinase', 'ejection_fraction', 'platelets',
'serum_creatinine', 'serum_sodium']]
X_cat = df[[ 'anaemia', 'diabetes', 'high_blood_pressure', 'sex', 'smoking']]
y = df['DEATH_EVENT']
X_num # 수치형 데이터
X_cat # 범주형 데이터
y
수치형 입력 데이터를 전처리 하고 입력데이터 통합하기
scaler = StandardScaler()
scaler.fit(X_num)
X_scaled = scaler.transform(X_num) # 결과는 numpy array 였다.
X_scaled = pd.DataFrame(data=X_scaled, index = X_num.index, columns=X_num.columns)
X_scaled
X_scaled.describe()
scale이 된 숫자형화 범주형을 다시 합친다.
X = pd.concat([X_scaled, X_cat], axis=1)
X
train / test 데이터 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
X_train.shape, X_test.shape
y_train.shape, y_test.shape
모델 학습하기
from sklearn.linear_model import LogisticRegression
model_lr = LogisticRegression()
model_lr.fit(X_train, y_train)
model_lr.get_params()
종종 iteration이 부족해서 학습이 덜 되었다고 뜰 때가 있다.
그럴땐 mat_iter값을 더 많이 설정 해준다.
model_lr = LogisticRegression(max_iter=1000)
model_lr.fit(X_train, y_train)
모델 학습 결과 평가
from sklearn.metrics import classification_report
pred = model_lr.predict(X_test)
print(classification_report(y_test, pred))
XGBoost 모델 생성/학습
분류형에서 쓰임.
from xgboost import XGBClassifier
model_xgb = XGBClassifier()
model_xgb.fit(X_train, y_train)
pred = model_xgb.predict(X_test)
print(classification_report(y_test, pred))
특징의 중요도 확인 가능!
머신러닝 학습 이후에 가능한것.
modelxgb.feature_importances # 이번 모델에서의 각 feature의 중요도
modelxgb.feature_importances.sum()
plt.bar(X.columns, modelxgb.feature_importances)
plt.xticks(rotation=90)
df.columns
sns.jointplot(x='ejection_fraction', y='serum_creatinine', data=df, hue='DEATH_EVENT', alpha=0.3)
모델 학습 결과 심화 분석하기
Precision-Recall 커브 확인하기
from sklearn.metrics import PrecisionRecallDisplay, precision_recall_curve
Precision-Recall 커브는 Precision 과 Recall 의 관계를 보는 겁니다.
ex) Recall 을 유지하면서 Precision 을 얼마나 끌어올릴수 있는지..
fig = plt.figure()
ax = fig.gca() # get current axes
PrecisionRecallDisplay.from_estimator(model_lr, X_test, y_test, ax=ax)
PrecisionRecallDisplay.from_estimator(model_xgb, X_test, y_test, ax=ax)
ROC 커브 확인하기
from sklearn.metrics import RocCurveDisplay, roc_curve
model_lr.predict_proba(X_test)[:10]
pred_prob = model_lr.predict_proba(X_test)[:, 1]
fprs, tprs, thresholds = roc_curve(y_test, pred_prob)
plt.plot(fprs,tprs,label='ROC')
fig = plt.figure()
ax = fig.gca()
proba_lr = model_lr.predict_proba(X_test)[:, 1]
proba_xgb = model_xgb.predict_proba(X_test)[:, 1]
fprs, tprs, thresholds = roc_curve(y_test, proba_lr)
ax.plot(fprs, tprs, label='Logistic Regression')
fprs, tprs, thresholds = roc_curve(y_test, proba_xgb)
ax.plot(fprs, tprs, label='XGBBoost')
ax.set_xlabel('FPR: Flase Positive Rate')
ax.set_xlabel('TPR: True Positive Rate')
fig.legend()
