📝 BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding
Abstract
-
기존의 언어 표현 모델과 달리, BERT는 비지도 학습된 텍스트에서 양방향 표현을 사전 학습하도록 설계됨
-
모든 레이어에서 좌우 문맥을 동시에 고려하여 학습하므로, 사전 학습된 BERT 모델은 단 하나의 출력 레이어만 추가하여 다양한 자연어 처리(NLP) 작업에 쉽게 미세 조정할 수 있음
-
질문 답변 및 언어 추론과 같은 작업에서 별도의 모델 구조 변경 없이 최첨단 성능을 달성할 수 있음
-
총 11개의 자연어 처리(NLP) 작업에서 새로운 최고 성능을 달성함
1 Introduction
-
사전 학습된 언어 표현을 다운스트림 작업에 적용하는 두 가지 방법은 크게 특징 기반 접근법과 미세 조정 접근법이 있음
-
기존의 미세 조정 접근법은 단방향 언어 모델을 사용하기 때문에 제한이 존재함
-
이를 해결하기 위해 "마스크드 언어 모델" 목표를 사용하여 양방향 문맥을 학습하는 BERT를 제안함
2 Related Work
2.1 Unsupervised Feature-based Approaches
-
단어 임베딩 벡터를 사전 훈련하기 위해 좌에서 우로 진행하는 언어 모델링과 좌우 문맥을 활용하여 올바른 단어를 판별하는 방식이 사용됨
-
ELMo는 좌우 문맥을 모두 활용하여 문맥 감지 특징을 학습하며, 다양한 NLP 태스크에서 성능 향상을 보임
-
단어 예측을 기반으로 한 여러 연구들이 NLP 모델의 강건성을 향상하는 데 기여함
2.2 Unsupervised Fine-tuning Approaches
-
특징 기반 접근법과 마찬가지로, 초기 연구들은 레이블이 없는 텍스트로부터 단어 임베딩 파라미터 만을 사전 학습함
-
최근에는 문장 또는 문서 인코더를 사용하여 맥락 기반 토큰 표현을 학습한 후, 지도 학습 다운스트림 태스크를 위해 미세 조정하는 연구가 활발히 진행됨
-
새로 학습해야 할 파라미터가 적다는 점에서 OpenAI GPT는 이러한 방식으로 GLUE 벤치마크에서 성능을 크게 향상시킴
-
BERT는 양방향 사전 학습을 통해 더 강력한 성능을 보이며 NLP 전반을 혁신함
2.3 Transfer Learning from Supervised Data
-
대규모 데이터셋을 활용한 지도 학습 태스크에서도 효과적인 전이 학습이 가능하다는 연구들이 진행됨
-
자연어 추론(NLI) 및 기계 번역에서 전이 학습을 통한 성능 향상이 입증됨
-
컴퓨터 비전에서도 ImageNet을 활용한 전이 학습이 효과적인 것으로 나타남
3 BERT
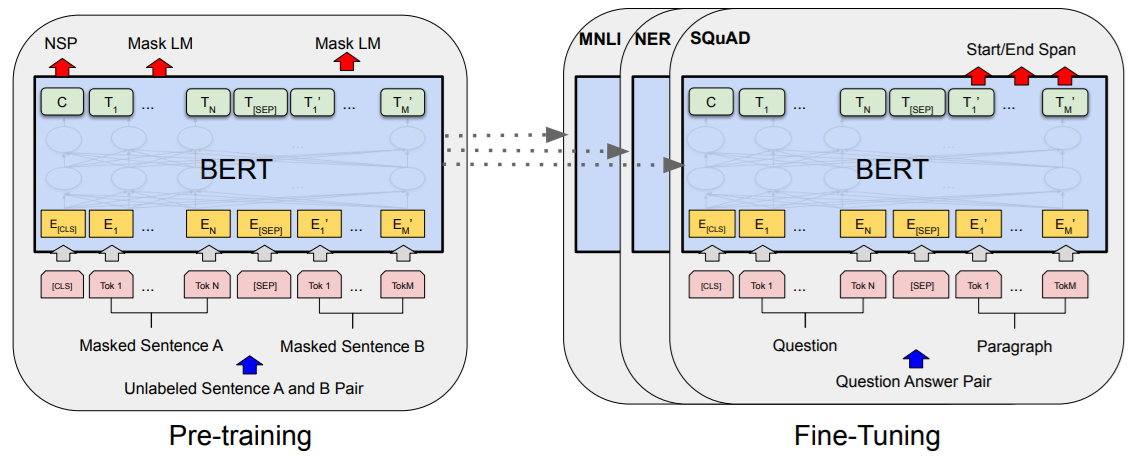
3.1 Pre-training BERT
-
목적: 일반적인 언어 이해 능력을 학습하는 단계로, 대규모 텍스트 데이터에서 BERT의 초기 언어 모델을 훈련함
-
구성:
-
토큰 임베딩 (Token Embedding)
-
세그먼트 임베딩 (Segment Embedding): 문장 A와 문장 B를 구분하는 역할
-
포지션 임베딩 (Position Embedding): 문장 내 토큰의 위치 정보를 포함함
-
-
훈련 목표:
-
Masked Language Model (MLM): 입력 문장에서 일부 단어를 [MASK]로 가리고, BERT가 해당 단어를 예측하도록 학습함
-
Next Sentence Prediction (NSP): 두 문장이 연속된 문장인지 예측하는 작업임. BERT는 문장 쌍을 입력으로 받고, "연속된 문장"인지 아닌지를 맞히도록 훈련됨.
-
3.2 Fine-tuning BERT
-
목적: 사전 훈련된 BERT 모델을 특정 작업(질문 답변, 문장 분류, 개체명 인식 등)에 적응시키기 위해 추가 훈련함
-
구성:
-
입력: 사전 훈련과 유사하지만, 주어진 작업에 맞게 데이터가 구성됨
-
출력: 작업에 따라 다르게 조정됨
-
문장 분류 (NSP, MNLI): 최종 출력 [CLS] 토큰의 벡터를 사용해 문장 관계를 분류함
-
개체명 인식 (NER): 각 토큰의 출력을 사용해 해당 토큰의 라벨을 예측함
-
질문 답변 (SQuAD): 시작 토큰과 끝 토큰을 예측해 답변의 범위를 찾음
-
-
-
미세 조정 과정: 전체 BERT 모델을 다시 훈련하지만, 사전 훈련된 가중치를 초기화 값으로 사용하고, 새 작업에 적합한 방식으로 손실 함수를 정의해 추가 학습을 진행함
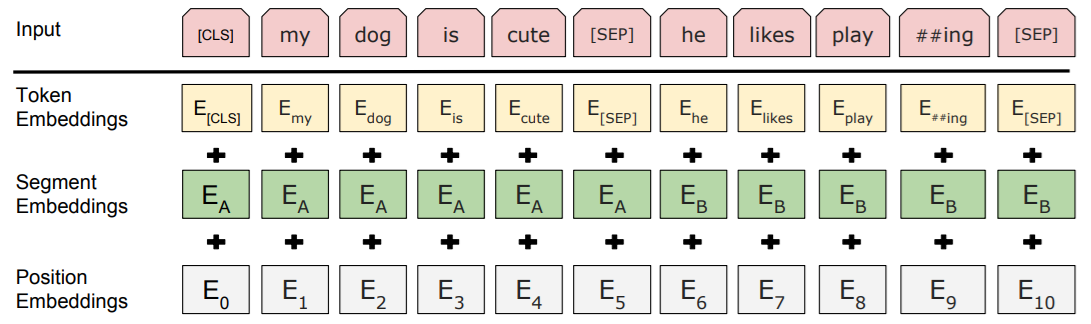
(이미지에 대한 설명)
1. Input (입력)
-
입력 문장은 토큰화된 형태로 표현됨
-
BERT는 두 문장을 입력받을 수 있으며, 각 문장은 [SEP] 토큰으로 구분됨
-
[CLS] 토큰은 문장의 시작에 붙는 특별한 토큰으로, 전체 문장의 표현을 생성하는 데 사용됨
[CLS] my dog is cute [SEP] he likes play ##ing [SEP]
(여기서 "##ing"은 WordPiece 토크나이저에 의해 "play"와 "ing"가 분리된 형태)
2. Token Embeddings (토큰 임베딩)
-
각 토큰은 고정된 차원의 벡터로 변환됨
-
예를 들어, "my"는 , "dog"는 로 임베딩됨
-
[CLS]와 [SEP] 같은 특별한 토큰에도 고유한 임베딩이 있음
3. Segment Embeddings (세그먼트 임베딩)
-
BERT는 두 개의 문장을 구분하기 위해 Segment Embedding을 사용함
-
문장 A에는 , 문장 B에는 가 추가됨
-
이 예시에서 "my dog is cute"가 문장 A, "he likes playing"이 문장 B에 해당함
4. Position Embeddings (위치 임베딩)
-
트랜스포머는 순서를 모르는 구조라, BERT는 단어의 위치 정보를 추가로 제공함
-
각 토큰 위치에 따라 고유한 위치 임베딩 이 더해짐
-
이 임베딩은 문장 내에서 각 단어의 위치를 인식할 수 있도록 도와줌
5. 최종 입력 표현
- 최종 입력 표현은 아래 세 가지 임베딩의 합으로 구성됨
입력 임베딩 = Token Embedding + Segment Embedding + Position Embedding
4 Experiments
-
GLUE: BERT가 GLUE 벤치마크에서 기존 SOTA 대비 큰 폭의 점수 향상
-
SQuAD: BERT는 단일 모델로도 기존 앙상블보다 높은 점수 달성, v2.0에서도 +5.1 F1 향상
-
SWAG: 상식 추론 과제에서 기존 대비 +8.3% 개선
-
결론: BERT는 다양한 NLP 태스크에서 강력한 성능을 보이며, 간단한 미세 조정만으로도 최고 성능을 달성함
5 Ablation Studies
5.1 Effect of Pre-training Tasks
-
NSP를 제거하면 QNLI, MNLI, SQuAD에서 성능이 크게 저하됨
-
LTR 모델은 모든 태스크에서 MLM보다 성능이 낮음
5.2 Effect of Model Size
-
모델 크기가 클수록 성능 향상됨
-
대형 모델이 기계 번역 및 언어 모델링에서 성능을 향상시키는 것은 알려졌지만, BERT는 작은 데이터셋에서도 큰 모델이 효과적임을 처음으로 실증함
5.3 Feature-based Approach with BERT
-
BERT는 미세 조정과 특징 기반 접근법 모두 강력함
-
특징 기반 접근법은 사전 계산 후 다양한 모델에 적용할 수 있는 장점이 있음
-
가장 성능이 좋은 방법은 상위 4개 히든 레이어를 연결한 후 활용하는 것
6 Conclusion
-
비지도 사전 훈련이 NLP에서 필수적인 요소로 자리 잡음
-
저자원 태스크도 단방향 신경망을 통해 성능 향상 가능함
-
이 연구는 이를 양방향 신경망으로 확장하여 다양한 태스크를 해결하는 것이 핵심
