📝 Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
Abstract
- 이 논문에서 순환 신경망(RNN)에서 다양한 유형의 순환 유닛을 비교하려 함
1 Introduction
-
최근 RNN은 기계 번역 등에서 뛰어난 성능을 보이지만, 대부분의 성공 사례는 기본 RNN이 아닌 LSTM 같은 정교한 유닛을 포함한 RNN을 사용함
-
이 논문에서는 LSTM과 GRU를 비교하며, 전통적인 tanh 유닛도 함께 평가함
-
실험 결과, 특정 데이터셋에서 GRU가 LSTM보다 더 빠르게 수렴하며 일반화 성능이 뛰어남
2 Background: Recurrent Neural Network
-
RNN은 가변 길이 시퀀스를 처리할 수 있는 순환 구조의 신경망임
-
기울기 소실/폭발 문제로 인해 장기 의존성 학습이 어려움
-
이를 해결하기 위해 개선된 학습 알고리즘과 정교한 활성화 함수(LSTM, GRU)가 연구됨
-
LSTM과 GRU를 활용한 RNN이 음성 인식, 기계 번역 등에서 우수한 성능을 보임
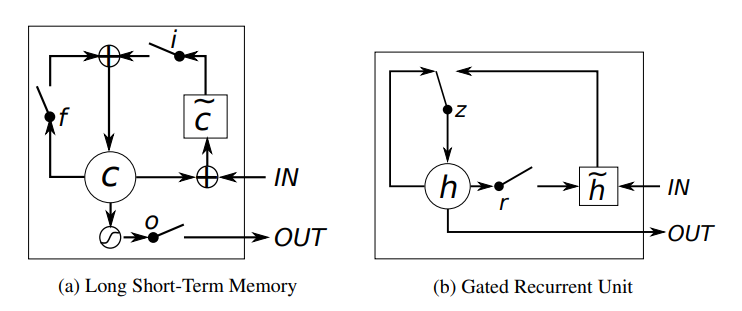
이 이미지는 LSTM(Long Short-Term Memory)과 GRU(Gated Recurrent Unit)의 구조를 비교한 것이다. 두 모델 모두 순환신경망(RNN)의 단점을 보완하기 위해 고안되었으며, 장기 의존성 문제를 해결하는 데 사용된다.
LSTM은 입력 게이트(i), 망각 게이트(f), 출력 게이트(o), 셀 상태(C)를 이용해 정보를 조절하며, 보다 정교한 장기 기억 조절이 가능하지만 구조가 복잡하고 연산량이 많다. 반면, GRU는 업데이트 게이트(z)와 리셋 게이트(r)만을 사용하여 더 간결하고 계산량이 적으며 빠르게 학습할 수 있다.
일반적으로 LSTM은 복잡한 장기 의존성 문제에서 유리하고, GRU는 상대적으로 간단한 문제에서 빠르고 효율적한 선택이 될 수 있다. 어느 구조를 사용할지는 문제 특성과 성능 요구사항에 따라 달라진다.
3 Gated Recurrent Neural Networks
3.1 Long Short-Term Memory Unit
-
LSTM은 기존 RNN과 다르게 메모리 셀을 유지하며, 게이트를 통해 정보 저장 여부를 결정함.
-
출력은 로, 출력 게이트가 메모리 노출을 조절함.
-
망각 게이트 와 입력 게이트 가 기존 메모리와 새로운 정보를 조절함.
-
중요한 특징을 초기에 감지하면 이를 장거리까지 유지할 수 있어 장기 의존성 문제를 해결함.
3.2 Gated Recurrent Unit
-
GRU는 LSTM과 유사하게 게이트를 사용하지만, 별도의 메모리 셀 없이 정보 흐름을 조절함.
-
활성화 상태는 로 업데이트되며, 업데이트 게이트 가 갱신 정도를 조절함.
-
리셋 게이트 는 이전 상태를 잊을지를 결정하며, 0에 가까울수록 초기 입력을 읽는 것처럼 동작함.
-
GRU는 상태를 조절하는 별도의 출력 게이트 없이, 매 시점마다 전체 상태를 노출함.
3.3 Discussion
-
LSTM과 GRU는 기존 RNN과 달리 기존 정보를 유지하면서 새로운 정보를 추가하는 방식으로 동작함.
-
덧셈 연산 덕분에 중요한 정보를 오래 기억할 수 있고, 역전파 시 기울기 소실 문제를 완화함.
-
LSTM은 출력 게이트를 통해 메모리 노출을 조절할 수 있지만, GRU는 모든 정보를 직접 노출함.
4 Experiments Setting
4.1 Tasks and Datasets
우리는 LSTM 유닛, GRU, 그리고 tanh 유닛을 비교하여 순차 모델링(sequence modeling) 작업을 수행한다. 순차 모델링의 목표는 주어진 학습 데이터에 대해 로그 가능도(log-likelihood)를 최대화 하여 시퀀스 확률 분포를 학습하는 것이다.
여기서 𝜃는 모델의 매개변수(parameter) 집합을 의미한다.
다성 음악(polyphonic music) 모델링과 음성 신호(speech signal) 모델링 두 가지 작업에서 이러한 유닛들을 평가한다.
4.2 Models
-
LSTM, GRU, tanH 세 모델 간 공정한 비교를 위해 모델 크기를 조정하여 각 모델이 대략 동일한 수의 매개변수를 갖도록 함
-
과적합을 방지하고 비교의 신뢰도를 높이기 위해 모델을 작게 설계함
-
음악 및 음성 데이터셋에서 LSTM이 가장 성능이 좋았고, tanh는 상대적으로 성능이 낮음
-
RMSProp을 사용하여 훈련했고, 기울기 폭발 방지를 위해 기울기 크기를 1로 조정함
5 Results and Analysis
-
GRU-RNN은 대부분의 다성 음악 데이터셋에서 LSTM-RNN과 tanh-RNN보다 우수했으나, 성능 차이는 크지 않았음
-
Ubisoft 데이터셋에서는 GRU-RNN과 LSTM-RNN이 tanh-RNN보다 훨씬 뛰어났으며, Ubisoft A에서는 LSTM-RNN이, Ubisoft B에서는 GRU-RNN이 최고 성능을 기록함
-
GRU-RNN은 학습 속도가 더 빠르고, tanh-RNN은 업데이트가 가벼우나 성능이 낮아 학습이 제대로 이루어지지 않음
-
게이트 유닛이 전통적인 순환 유닛보다 전반적으로 우수하지만, LSTM과 GRU 중 어느 것이 더 나은지는 데이터셋과 과업에 따라 달라질 수 있음
6 Conclusion
-
LSTM과 GRU는 전통적인 tanh 유닛보다 우수했고, 특히 원시 음성 신호 모델링에서 차이가 뚜렷했음
-
두 게이팅 유닛(LSTM, GRU) 중 어느 것이 더 나은지 확실한 결론을 내리진 못함
-
향후 각 유닛의 기여도를 더 잘 이해하기 위해 추가 실험이 필요함
