📝 Dropout: A Simple Way to Prevent Neural Networks from Overfitting
Abstract
-
딥러닝에서 과적합이 문제되는 대형 신경망을 효율적으로 학습시키기 위해 드롭아웃(Dropout) 기법을 제안
-
훈련 중에 뉴런과 연결을 랜덤하게 제거하여 과적합을 방지하고, 다양한 "얇아진" 네트워크를 학습하는 효과를 줌
-
테스트 시에는 가중치를 조정한 단일 네트워크로 여러 모델의 평균 예측 효과를 근사할 수 있음
-
드롭아웃을 적용하면 컴퓨터 비전, 음성 인식, 문서 분류 등 다양한 분야에서 최신 성능을 달성함
1 Introduction
-
딥러닝 모델은 복잡한 관계를 학습하지만, 데이터가 부족하면 과적합 문제가 발생함.
-
드롭아웃은 뉴런을 랜덤하게 제거해 과적합을 방지하고, 다양한 네트워크를 결합하는 효과를 줌.
-
훈련 시에는 랜덤하게 뉴런을 끄고, 테스트 시에는 조정된 가중치를 사용해 단일 네트워크로 근사함.
-
이 방식은 다양한 머신러닝 문제에서 기존 정규화 방법보다 일반화 성능이 뛰어남.
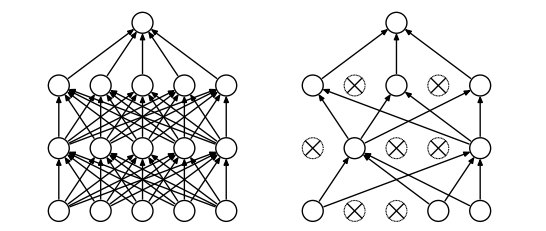
왼쪽 그림은 일반적인 신경망(Neural Network) 구조를 나타내며, 각 층의 뉴런들이 서로 촘촘하게 연결되어 있다. 오른쪽 그림은 Dropout이 적용된 신경망으로, 일부 뉴런이 랜덤하게 비활성화(엑스(X) 표시)되어 네트워크가 단순화된 모습을 보인다. Dropout을 적용하면 각 뉴런이 특정한 다른 뉴런에 의존하는 현상이 줄어들어, 모델이 더욱 일반화된 학습을 하게 된다.
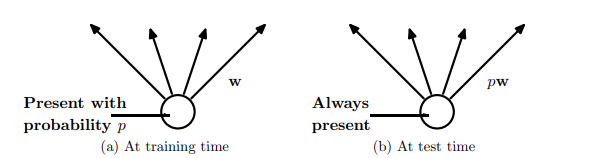
(a) 훈련 시에는 각 뉴런이 확률 로 활성화되며, 비활성화된 뉴런은 완전히 제거된다. (b) 테스트 시에는 모든 뉴런이 활성화되지만, 학습 시의 확률 를 반영하여 가중치 가 로 조정된다. 이를 통해, 학습 시 다수의 작은 네트워크를 학습한 효과를 유지하면서도 하나의 신경망으로 예측을 수행할 수 있다.
2 Motivation
-
Dropout은 성적 진화의 원리에서 영감을 얻은 개념
-
신경망의 은닉 유닛이 특정 유닛에 의존하지 않고 독립적으로 유용한 특징을 학습하도록 만듦
3 Related Work
-
Dropout은 신경망의 은닉 유닛에 노이즈를 추가하는 정규화 방법으로 해석될 수 있음
-
Denoising Autoencoder(DAE)에서 입력에 노이즈를 추가하는 방식에서 확장된 개념이며, 모델 평균화 효과도 가짐
-
확률적 정규화 기법인 Dropout을 결정론적으로 근사하는 연구도 진행되었으며, 기존 연구와 비교해 숨겨진 층을 포함한 모델에서도 효과를 검증함
4 Model Description
-
신경망의 피드포워드 연산을 일반적인 네트워크와 드롭아웃 네트워크로 비교
-
일반적인 네트워크에서는 각 층의 입력과 가중치를 이용해 출력을 계산함 (𝑓(𝑥)는 활성화 함수)
- 드롭아웃 네트워크에서는 각 층에서 확률 을 따르는 베르누이 분포로 마스크 벡터 생성하고, 요소별 곱을 수행하여 출력 유닛을 랜덤하게 삭제함 (∗는 요소별 곱을 의미)
-
학습 시에는 랜덤하게 뉴런을 비활성화하여 서브 네트워크를 샘플링하고, 역전파를 적용함
-
테스트 시에는 드롭아웃을 사용하지 않으며, 가중치를 로 조정하여 일관성을 유지함
5 Learning Dropout Nets
5.1 Backpropagation
-
가중치 벡터를 일정 반경 내로 제한하면 너무 큰 학습률(learning rate)을 사용해도 가중치가 폭발하지 않음
-
드롭아웃이 주는 노이즈가 최적화 과정에서 더 넓은 가중치 공간을 탐색할 수 있도록 도와줌
-
학습률이 감소함에 따라 탐색 과정이 점점 짧아지고, 결국 더 좋은 최소값(minimum)에 수렴할 가능성이 높아짐
5.2 Unsupervised Pretraining
-
신경망은 RBM, 오토인코더, 딥 볼츠만 머신 등을 사용해 사전 학습(pretraining)할 수 있음.
-
사전 학습된 신경망에 드롭아웃을 적용할 경우, 가중치를 배로 조정해야 함.
-
초기에는 드롭아웃이 사전 학습된 가중치 정보를 손실시킬 것으로 우려했으나, 학습률을 낮추면 정보가 유지되고 일반화 성능이 개선됨.
6 Experimental Results
- 다양한 데이터셋에서 드롭아웃이 일반화 성능 향상에 효과적임.
6.1 Results on Image Data Sets
-
MNIST, SVHN, CIFAR-10/100, ImageNet 등에서 드롭아웃 적용 시 성능 개선됨.
-
ImageNet에서 드롭아웃을 적용한 컨볼루션 네트워크가 다른 방법들보다 월등한 성능을 보임.
6.2 Results on TIMIT
- TIMIT 데이터셋에서는 드롭아웃이 전화 인식 성능을 개선함.
6.3 Results on a Text Data Set
- 드롭아웃이 텍스트 분류 작업에서는 개선 효과가 상대적으로 적음.
6.4 Comparison with Bayesian Neural Networks
- 베이지안 신경망에 비해 드롭아웃은 훈련 속도가 빠르고 테스트 시간도 적게 소모됨.
