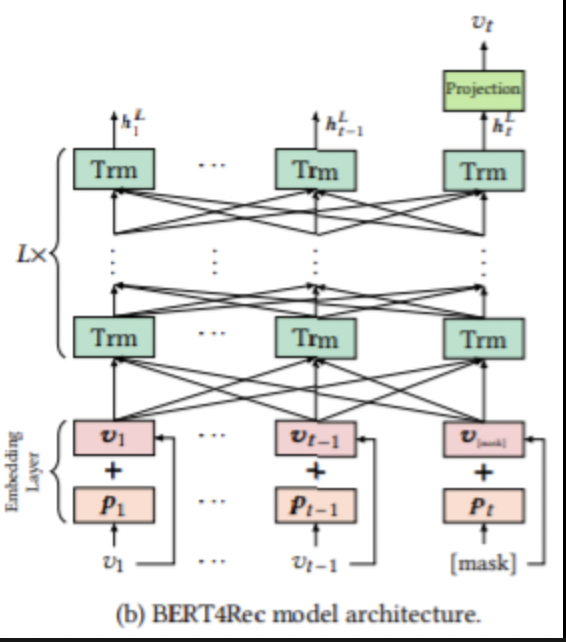
Why BERT?
-단방향 모델인 SASRec과 다르게 양방향 모델을 사용하여 sequence한 정보를 더 받을 수 있다.
-복잡한 관계 학습이 가능하다.
Masked Model
-next item의 정보가 context vector에 들어가면 학습 효과가 저하되어 SASRec에서는 다음 시점 item에 대한 정보를 masking 했지만 BERT4Rec은 BERT의 Pre-training Masked Language Model을 활용하여 Training에는 next item prediction이 아닌 item을 random masked 처리하여 양방향 학습을 하고 Testing에 next item prediction을 수행하여 SASRec과 달리 context vector에서 non-masking 수행
BERT4Rec Structure
Multi-Head Attention
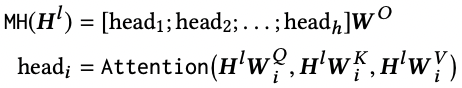
-head num의 수만큼 dimension을 나눠 dimension 마다 다른 정보를 학습
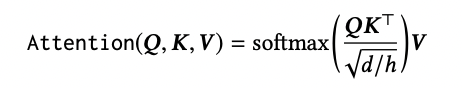
-앞서 말한 것처럼 masking 처리하지 않음
-최종적으로 head num만큼 나눠진 context vector를 concat하여 원래 size로 복구
Position-wise & Feed-Forward Network
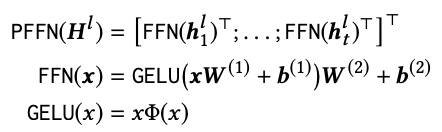
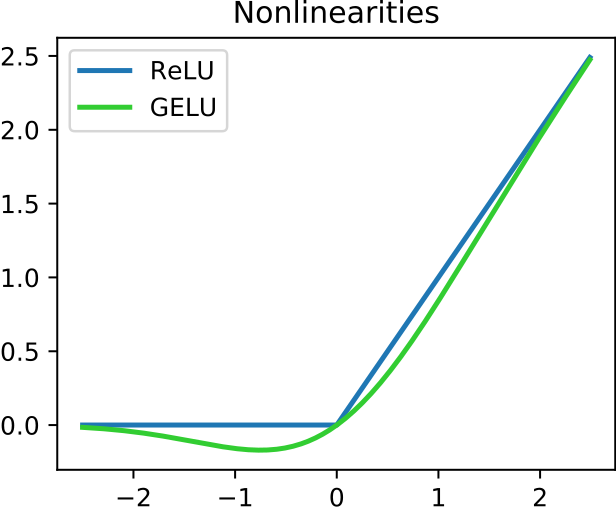
-SASRec에서 사용된 ReLU와 달리 GeLU 사용
RuLU vs GeLU
Output layer
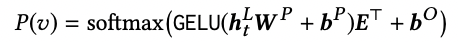
-여기서 W는 학습 가능한 투영 행렬이고, b^p와 b^o는 bias이고 E ∈ R은 항목 세트 V에 대한 임베딩 행렬
-과적합 완화 및 모델 축소를 위해 입력 및 출력 레이어에서 공유 임베딩 매트릭스를 사용
Loss Function
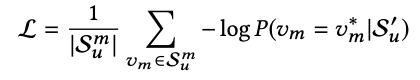
-GT의 positive score는 높게 negative sampling의 negative score은 낮게 학습
Test for Recommendation
-test에는 next item prediction task이기 때문에 Fine-tuning 처럼 Train 과정에서 last item masked하고 last item prediction iteration을 수행
