General Recommendation
-기존 MF기반 추천 시스템은 유저/아이템 matrix를 통해 유저별 아이템 벡터를 표현할 수 있지만 실제로 아이템이 많기 때문에 0으로 채워지는 sparsity 문제가 있었고 이를 dense한 벡터로 만들기 위해 차원을 축소하여 유저 Latent matix, 아이템 Latent matrix로 Matrix Factiorization을 수행
Sequential Recommendation
- 유저의 sequential한 정보를 파악 후 아이템을 추천하는 방법이며 e-commerce에 적합하고 기존 추천 시스템 방식은 구매의 순서,시기와 같은 sequential한 정보를 무시
-Seqential 정보를 이용하기 위해서 NLP에서 좋은 성능을 보이는 방법론을 추천 시스템에 맞도록 변형하여 사용
연구 방향
GRU4Rec -> CASER(CNN) -> SASRec -> BERT4REC
SASRec structure
기존 Sequential Recommendation 모델인 GRU는 순차적인 계산 떄문에 Long term 정보를 반영 하기 힘들다는 문제가 있었다. 이후 SASRec에서는 Transformer block의 장점인 병렬처리 방법으로 접근한 모델이다.
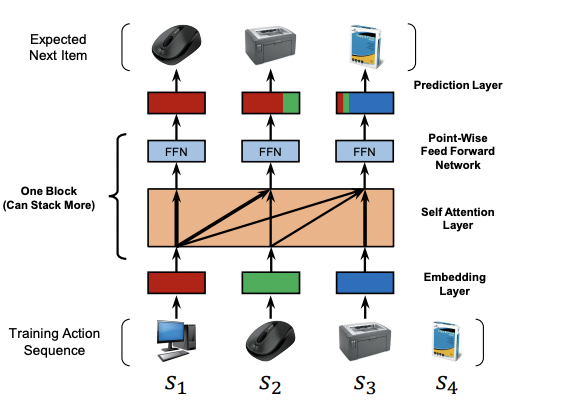
위 이미지를 보면 컴퓨터가 들어오면 컴퓨터만 attention이 걸리고 마우스가 들어오면 컴퓨터와 마우스가 attention이 걸리는 것을 볼 수 있다.
Embedding Layer
embedding layer에서는 training sequence를 고정된 길이 sequence로 변환
-길이가 너무 길 경우 최근 n개 선택
-짧을경우 n개 전 zero padding
-하나의 유저의 history를 time stamp에 따라 순차 정렬
-Explict 정부가 있는 경우 binary로 변경
Positional Embedding
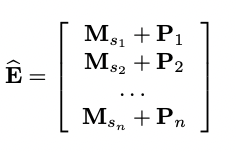
learnable position을 위해 positional Embedding 수행
-논문에서는 fixed된 position을 사용해 봤지만 성능이 저하되었다고 설명함
Self-Attention Block
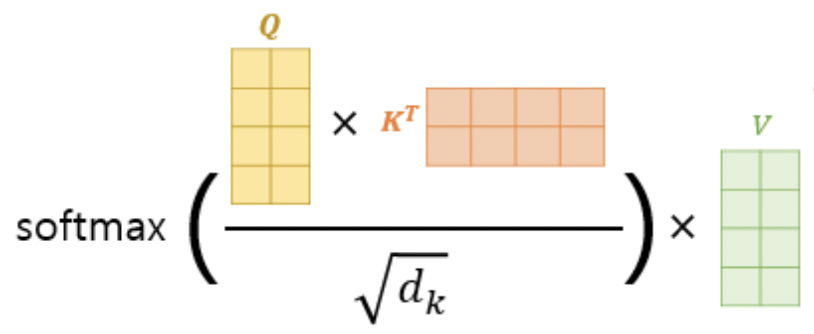
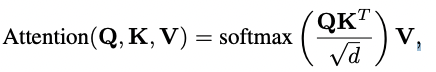
Key와 Query의 관계 matrix는 아이템 간 상관관계를 의미하고 inner product시 너무 큰 값이 나오는 것을 방지하기 위해 scale parameter d사용
Q와 K의 inner product 후 나온 matrix에서는 예측 할 다음 아이템을 해당 시점에서는 모르도록 masking 처리하는데 이는 masking 처리를 안하면 정답을 알려주고 학습하는 것과 똑같기 때문이다. 이러한 masking 처리 때문에 SASRec은 단방향성 모델이다.
이후 masking된 matrix를 가지고 Value와 계산을 하여 Context vector를 구함
Point-Wise Feed-Forward Network
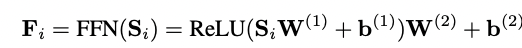
-Context vector는 linear model이기 때문에 Layer에 쌓는 의미를 부여하기 위해서 non-linear activation ReLU 사용
-서로 다른 Latent 차원의 iteraction을 위해 two-layer feed-forword network 사용
-각 아이템 끼리는 정보 교환이 없기 때문에 point-wise로 진행
-feed-forword network에서 1층과 2층 layer의 weight를 공유
Residual Connection & Dropout
-block을 쌓을 떄 Residual Connection을 통해 Loss 전파한다.
-일반적으로 Dropout은 network를 끊는 방식으로 사용하지만 SASRec 논문에서는 Sequence item index를 통해 item matrix에서 Look up 해올 때 random한 비율로 아이템을 가지고 오지 않음
Prediction Layer
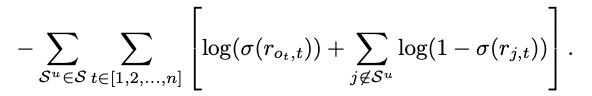
-Negative sample은 해당 유저가 산 적이 없는 아이템들 중 랜덤하게 100개 선택 또는 user의 id가 없는 경우 session에서 나오지 않은 아이템 선택
- 그 후 positive item은 score가 높게 negative item은 score가 낮게 학습
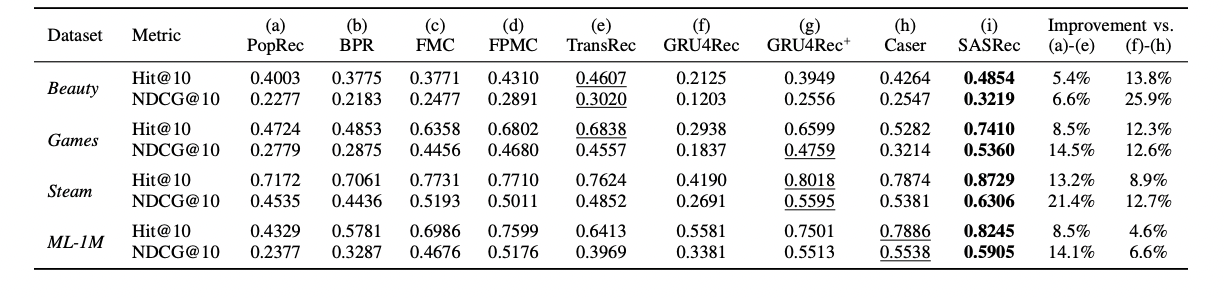
Recommendation performance & attention map
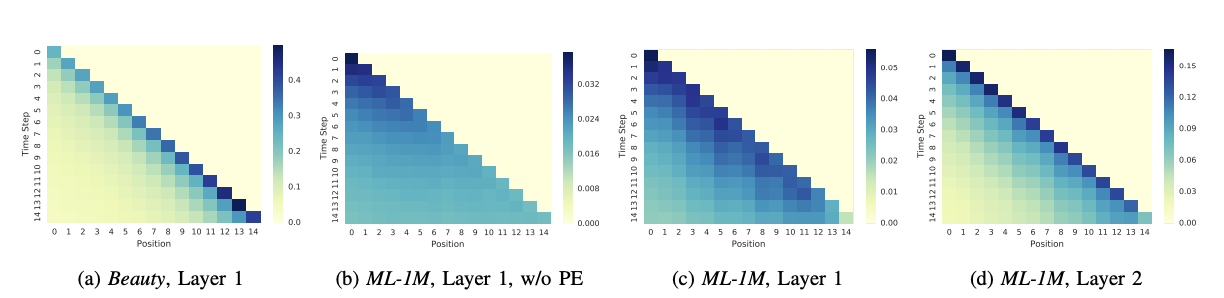
-데이터셋에 따라 adaptive하게 달라지는 attention map
-Beauty -> sparse, ML -> Dense
-attention ma을 보면 sparse set은 최근 2~3개 아이템 정보 기반으로 예측, dense set은 Sequence한 최근 정보를 더 많이 관측
