Recommendation system
1.1. Collaborative Filtering

'유저들로부터 얻은 정보'를 사용하여 유저의 관심사를 예측하는 방법Collaborative -> 다수의 의견을 반영한다.즉, 유저들의 데이터가 축적될수록 추천은 정확해진다.ex) 유저 A와 비슷한 성향을 갖는 유저들이 선호하는 아이템을 추천\-유저 u의 아이템 i의 평
2.2.Model-based CF with SVD
\-유저와 아이템을 잠재적 요인을 사용하여 표현할 수 있다고 보는 모델\-유저와 아이템을 같은 차원의 벡터로 표현하여 나타낸다.\-같은 차원의 벡터 공간에서 유저와 아이템 벡터가 놓일 경우 유저와 아이템의 유사한 정도를 확인할 수 있다.\-차원 축소 기법 중 하나로 E
3.3.Matrix Factorization with SGD
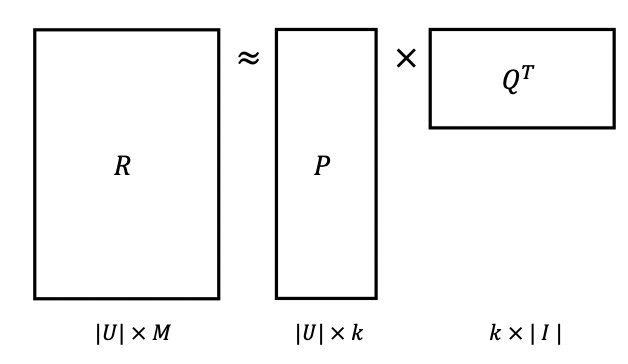
\-rating matrix를 P와 Q로 분해𝑅 ≈ 𝑃 × 𝑄^T = 𝑅 𝑃→ |𝑈| × 𝑘 𝑄→ |𝐼| × 𝑘 \-평점 예측: 𝑟̂ =p^Tqr과 𝑟̂이 최대한 유사하도록 P,Q 학습목적 함수를 정의하고 이를 minimize하는 o
4.4.Matrix Factorization with ALS
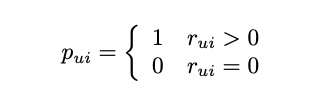
Alternative Least Square -user와 item matrix를 번갈아가면서 업데이트 -두 matrix 중 하나를 상수로 놓고 나머지 matrix를 update하는 최적화 방법 즉, p,q 중 하나를 고정하고 least-square 문제를 푸는것 -Im
5.Self-Attentive Sequential Recommendation
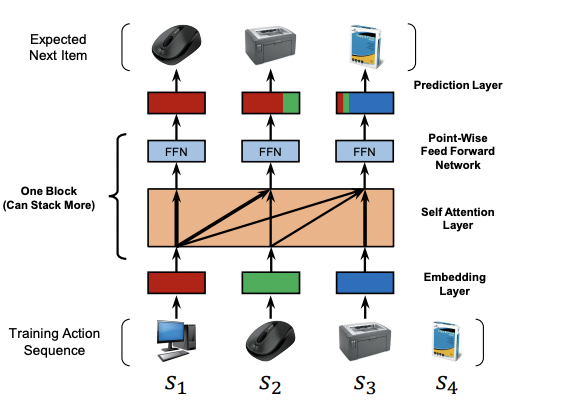
\-기존 MF기반 추천 시스템은 유저/아이템 matrix를 통해 유저별 아이템 벡터를 표현할 수 있지만 실제로 아이템이 많기 때문에 0으로 채워지는 sparsity 문제가 있었고 이를 dense한 벡터로 만들기 위해 차원을 축소하여 유저 Latent matix, 아이템
6.BERT4Rec: Sequential Recommendation
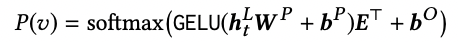
Why BERT? -단방향 모델인 SASRec과 다르게 양방향 모델을 사용하여 sequence한 정보를 더 받을 수 있다. -복잡한 관계 학습이 가능하다. Masked Model -next item의 정보가 context vector에 들어가면 학습 효과가 저하되어
7.LightGCN: Graph Convolution Network for Recommendation
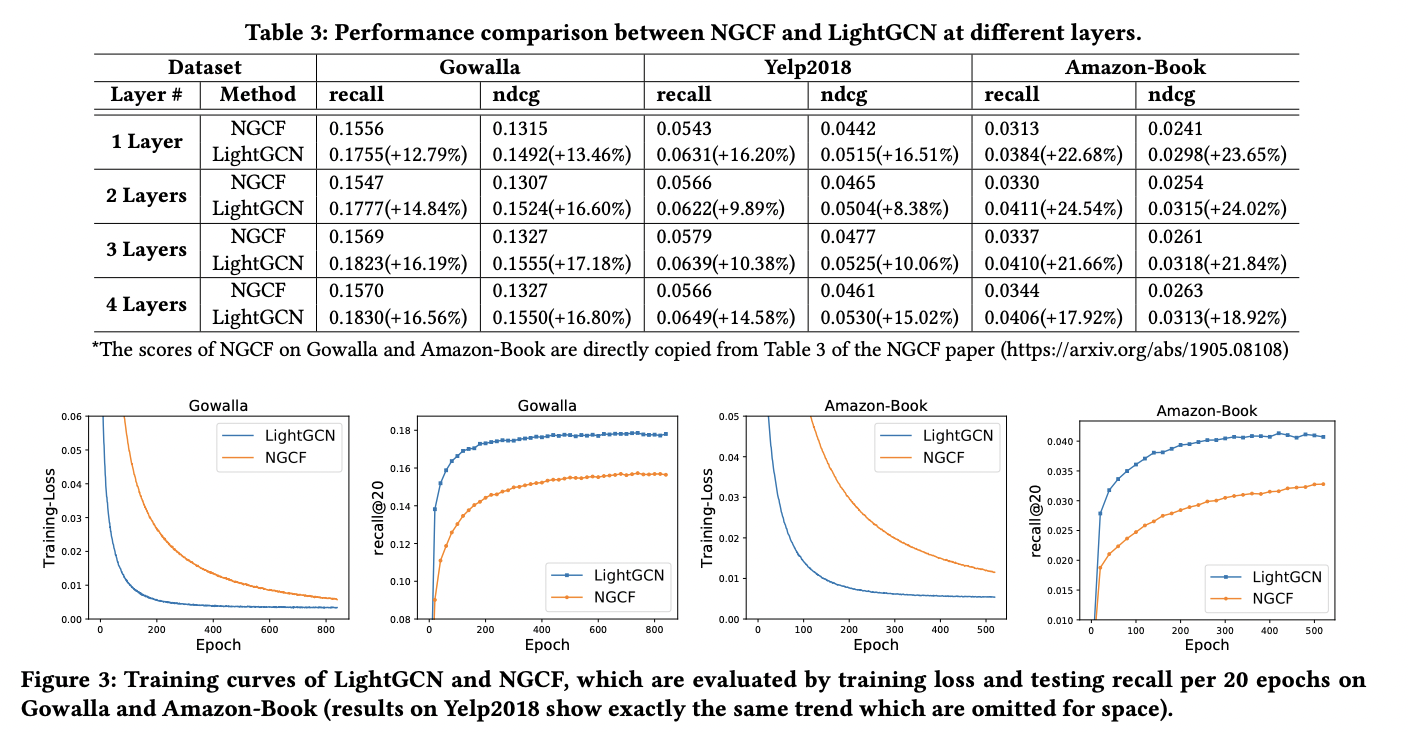
Classification Task, Recommendation Task의 GCN 차이 -Classification Task는 노드 자체에 rich semantic feature를 가지며 Recommendation 경우 User or Item idex를 Random