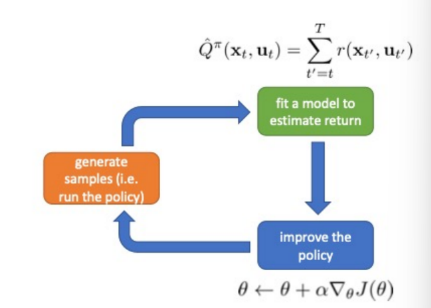
Recap: Basic of Reinforcement Learning
input
agent, environment
agent take the state(st)
→ agent take action
→ action에 따라 환경(state st+1) 변화
objective function
Expected cumulative reward
R(τ)=t=0∑∞γtrt where0<γ<1
RL Problem
expected cumulative reward를 최대화 시키는 policy 채택
π를 policy라고 할 때,
π∗=πargmaxE[R(τ)]
- expected 함수는
- s0이 주어진 경우, Value function
- s0,a0이 주어진 경우, Q function
Taxonomy of RL algorithm
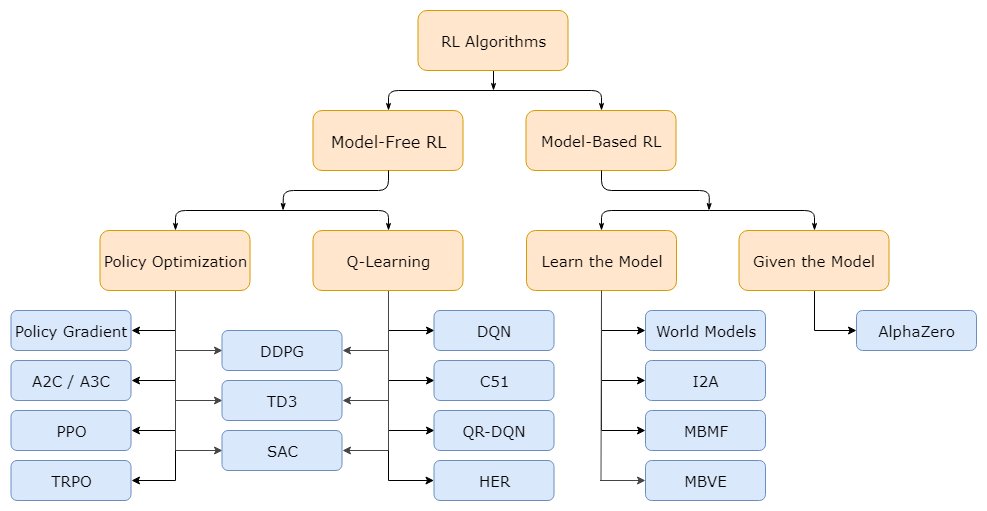
- Model-Free RL : agent는 environment에 대해 아무 정보도 가지고 있지 않음
대부분의 RL모델들의 기반
- Policy Optimization : objective function으로 최적화
RL에서 제일 간단한 편
- Policy Gradient : objective function을 gradient descent로 optimize하는 모델
- Q-Learning : Value/Q function으로 학습
- Model-Based RL : agent는 environment의 작동 방식에 대해 알고 있음
일단 이 정도만 알아놓고 가겠음
The goal of Reinforcement Leraning
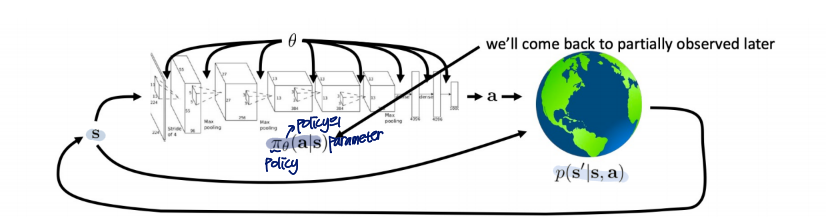
여기서 policy πθ에 따른 probability distribution over a sequence of trajectory 식을 표현하면
pθ(τ)=pθ(s1,a1,...,sT,aT)=p(s1)t=1ΠTπθ(at∣st)p(st+1∣st,at)
식을 풀어보면 이해가 좀 더 잘 되는데...

이런 이유로 저렇게 도출됨
Goal of RL
일단 그래서 위의 식을 통한 RL의 goal은
θ∗=θargmaxEτ∼pθ(τ)[t∑r(st,at)]
미분이 어려워서 원래 objective function에서의 discounted factor는 작성 생략됨
정리를 하자면
policy를 따라서 trajectory가 생성되는데, 가장 적절한 trajectory가 포함되어 있는 probability distribution을 만들어내는 policy의 parameter를 찾아내는 것이 목표!
infinite한 경우
θ∗=θargmaxE(s,a)∼pθ(s,a)[r(s,a)]
finite한 경우(certain timestep에서 끝날 것이라고 가정한 경우)
θ∗=θargmaxt=1∑TE(st,at)∼pθ(st,at)[r(st,at)]
그냥 아까 식에서 ∑이 밖으로 빠지고, T에서 끝난다는 게 생긴 거 말고 다른 거 없음
Evaluating Objective
θ∗=θargmaxEτ∼pθ(τ)[t∑r(st,at)]
J(θ)=Eτ∼pθ(τ)[t∑r(st,at)]≈N1i∑Nt∑r(si,t,ai,t)
real world의 policy를 N time 학습했다는 가정
(i,t): i-th sample에서 t번째 timestep
여기서 i∑N은 sum over samples from πθ
그런데
- initial probability: p(s1)
- transition probability: p(st+1∣st)
이 두 값을 모르는데 J(θ)를 어떻게 구하는 걸까?
roleplay를 통해 N번의 sampling을 하고, 이걸 다 더해서 1/N을 취하면 real world의 어느정도는 따라갈 것이라고 가정을 함으로써 해결
그래서 N의 값이 커질수록 estimate가 더 정확해짐
근데 솔직히 내가 잘 이해한 건지 모르겠음..
Direct policy differentiation
J(θ)=Eτ∼pθ(τ)[t∑r(st,at)]=Eτ∼pθ(τ)[r(τ)]
E(x)=∫p(x)dx
위의 식을 사용해서 식을 바꾸면,
J(θ)=∫pθ(τ)r(τ)dτ
여기서 r(τ)는 상수
미분하면,
▽θJ(θ)=∫▽θpθ(τ)r(τ)dτ
a convenitent identity
pθ(τ)▽θlogpθ(τ)=pθ(τ)pθ(τ)▽θpθ(τ)=▽θpθ(τ)
위의 식을 사용하면,
▽θJ(θ)=∫pθ(τ)▽θlogpθ(τ)r(τ)dτ=Eτ∼pθ(τ)[▽θlogpθ(τ)r(τ)]
이렇게 표현이 됨
pθ(τ)=pθ(a1,a1,...,sT,aT)=p(s1)t=1ΠTπθ(at∣st)p(st+1∣st,at)
log of both sides
logpθ(τ)=logp(s1)+t=1∑Tlogπθ(at∣st)+logp(st+1∣st,at)
위를 따르면
▽θlogpθ(τ)r(τ)=▽θ[logp(s1)+t=1∑Tlogπθ(at∣st)+logp(st+1∣st,at)]
logp(s1)과 logp(st+1∣st,at)는 상수(θ에 depend하지 않음)이기 때문에 미분 과정 중 0이 됨
따라서,
▽θJ(θ)=Eτ∼pθ(τ)[(t=1∑T▽θlogπθ(at∣st))(t=1∑Tr(st,at))]=N1i=1∑N(t=1∑Tlogπθ(ai,t∣si,t))(t=1∑Tr(si,t,ai,t))
이제 다 알려진 value들이라서 계산이 가능해짐!
θ←θ+α▽θJ(θ)
Policy gradient algorithm
- sample {τi} from πθ(at∣st) (run the policy)
sample 생성
- ▽θJ(θ)≈i∑(t∑Tlogπθ(ai,t∣si,t))(t∑Tr(si,t,ai,t))
fit a model to estimate return
- θ←θ+α▽θJ(θ)
improve the policy
Comparison to maximum likelihood
policy gradient는 maximum likelihood의 weighted version이라고 볼 수 있음!
- policy gradient
▽θJ(θ)≈N1i=1∑N(t=1∑Tlogπθ(ai,t∣si,t))(t=1∑Tr(si,t,ai,t))
- maximum likelihood
▽θJML(θ)≈N1i=1∑N(t=1∑Tlogπθ(ai,t∣si,t))
Example: Gaussian policies

action이 continuous함
- example: πθ(at∣st)=N(fneural network(st);Σ)
action이 continuous하기 때문에 μ,Σ 설정함
- logπθ(at∣st)=−21∥f(st)−at∥Σ2+const
- ▽θlogπθ(at∣st)=−21Σ−1(f(st)−at)dθdf
필요한 값들 구했으니 이제 알고리즘 식에 넣어서 사용하면 됨
What did we just do?
▽θJ(θ)≈N1i=1∑N(t=1∑Tlogπθ(ai,t∣si,t))(t=1∑Tr(si,t,ai,t))
가중치를 통해 good stuff(trajectory)는 more likey, bad stuff는 less likely하게 만들어짐
trial and error를 통해 더 많은 가중치를 주는 trajectory를 더 자주 선택할 수 있도록 만듦
Partial observability
에이전트가 환경의 전체 상태 st를 직접 관찰할 수 없고, 대신 그 상태에 대한 부분적인 정보인 관찰치(observation) ot만을 받게 되는 경우,
objective function의 형태는 같음
그냥 πθ의 변수에서 state를 observation으로만 바꾸면 됨
▽θJ(θ)≈N1i=1∑N(t=1∑Tlogπθ(ai,t∣oi,t))(t=1∑Tr(si,t,ai,t))
Markov property is not actually used!
can use policy gradient in partially observed MDP(Markov Decision Property)'s without modification
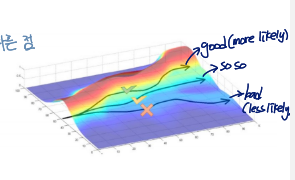
Problem of Policy Gradient
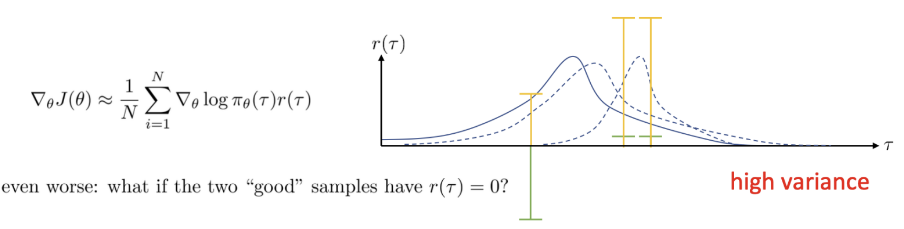
현재 위의 그래프에는 three samples가 있음
- 연두색 : 1차 reward
- 노란색 : 2차 reward
1차 때,
맨 왼쪽의 sample은 large negative reward로 인해 distribution이 오른쪽으로 shift될 것임
negative sample을 less likely하게 만들기 위해
그런데 positive reward를 받는 경우에는 negative reward를 받았을 때보다 조금만 shift되게 됨
high variance의 문제
샘플링의 패턴에 따라 distribution of the policy는 다른 결과를 보임
→ there is a very high variance of the distribution of the policy when we use the policy gradient
Reducing variance
Causality
policy at time t′는 본인보다 이전 time의 reward에 영향을 주지 못함
이건 Morkov property와 별개의 개념으로 항상 맞음 (Markov는 맞을 때도, 틀릴 때도 있음)
Causality를 고려해서 식을 변경하면
▽θJ(θ)≈i=1∑N(t=1∑Tlogπθ(ai,t∣si,t))(t′=t∑Tr(si,t′,ai,t′))
t′=1∑Tr(si,t′,ai,t′)을 t′=t∑Tr(si,t′,ai,t′)로 바꿈으로써 variance가 줄어듦
∵ whole value가 작아지면 variance 또한 작아짐
그리고 이때, t′=t∑Tr(si,t′,ai,t′)는 reward to go로 Q function과 같음
Baselines
reward가 항상 positive면 bad sample의 개선이 잘 안 되기 때문에 rewrad는 0에 centered되어 있어야 함
▽θJ(θ)≈N1i=1∑N▽θlogpθ(τ)[r(τ)−b]
b=N1i=1∑Nr(τ)
expected value를 미분하면
E[▽θlogpθ(τ)b]=∫pθ(τ)▽θlogpθ(τ)b dτ=∫▽θpθ(τ)b dτ=b▽θ∫pθ(τ)dτ=b▽θ1=0
따라서 expected value에 변화 없음
- subtracting a baseline은 unbiased in expectation
therefore main operation of policy gradient에는 영향을 주지 않음
- average reward is not the best baseline, but it's pretty good!
∵ variance가 줄어듦
Analyzing variance
variance를 minimize하는 걸 goal로 잡고
variance를 write down하자면
Var[x]=E[x2]−E[x]2
▽θJ(θ)=Eτ∼pθ(τ)[▽θlogpθ(τ)(r(τ)−b)]
Var=Eτ∼pθ(τ)[(▽θlogpθ(τ)(r(τ)−b))2]−Eτ∼pθ(τ)[▽θlogpθ(τ)(r(τ)−b)]2
두 번째 항은 미분값이 0이라는 걸 알아냈으므로 첫 번째 항만 남게 됨
dbdVar=dbdE[g(τ)2(r(τ)−b)2] =dbd(E[g(τ)2r(τ)2]−2E[g(τ)2r(τ)b]+b2E[g(τ)2]) =−2E[g(τ)2r(τ)]+2bE[g(τ)2]=0
g(τ) : derivative of log likelihood
b=E[g(τ)2]E[g(τ)2]r(τ)
this is just expected reward, but weighted by gradient magnitudes
Review
- the high variance problem of policy gradient
- exploting causality
- future doesn't affect the past
- baselines
- analyzing variance
- can derive optimal baselines