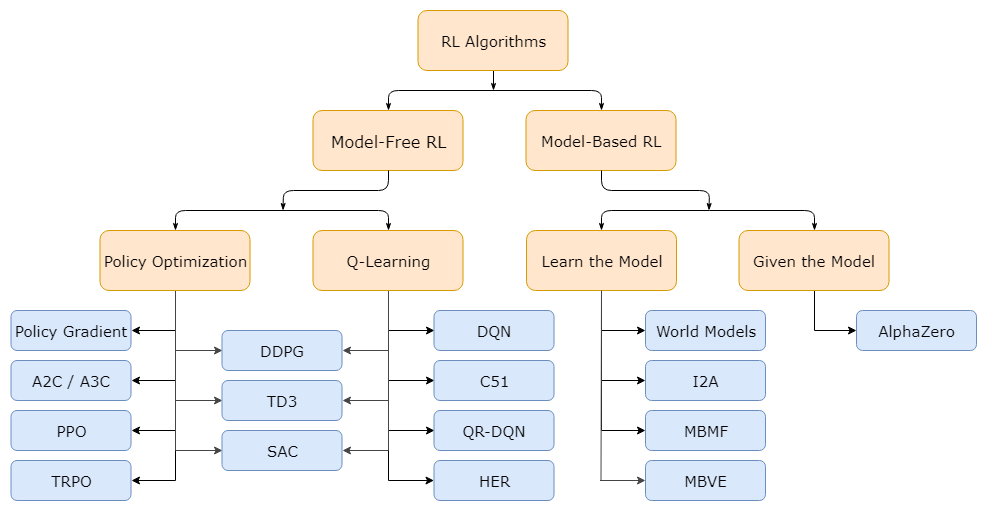
Taxonomy of RL algorithm
여기서
- Policy Optimization : on-policy RL
- Q-Learning : off-policy RL
Off-policy vs. On-policy
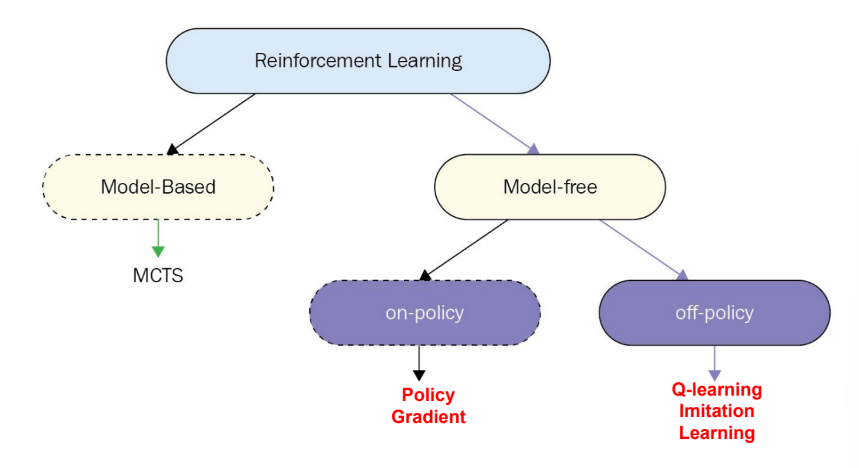
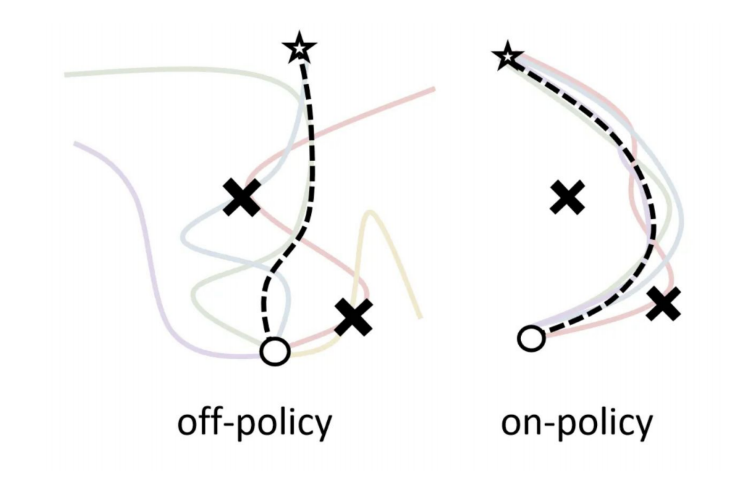
Policy Gradient is On-policy
algorithm
- sample {γi} from π(at∣st) (run it on the robot)
skip 불가능!
- ▽θJ(θ)≈∑i(∑t▽θlogπθ(ati∣sti))(∑tr(sti,ati))
- θ←θ+α▽θJ(θ)
pros
cons
- Neural networks는 각 gradient step마다 조금씩만 변화
∵ NN은 non-linear해서 크게 변화하면 optimize가 불가능해짐
- On-policy learning은 extremely inefficient해질 수 있음
위의 이유로 인해서
Off-policy learning & importance sampling
sampling from the different distribution을 하고자 함
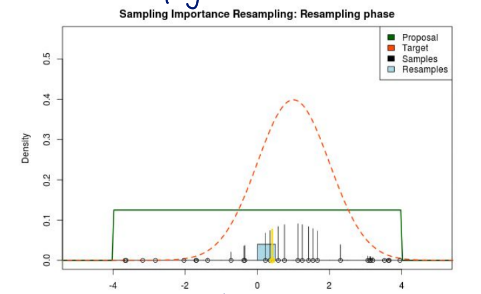
이렇게 density가 높은 부분을 더 많이 샘플링 하려고 함
importance sampling
Ex∼p(x)[f(x)]=∫p(x)f(x)dx =∫q(x)q(x)p(x)f(x)dx =∫q(x)q(x)p(x)f(x)dx =Ex∼q(x)[q(x)p(x)f(x)]
이 importance sampling을 통해
different distribution을 sample함
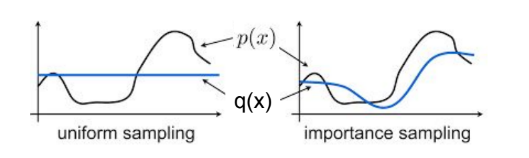
이렇게 uniform sampling과 달리 importance sampling은 p(x)의 모양을 따라서 sampling함
p(x)가 높은 부분이 더 sampling되도록
이때, p(x)는 original distribution that we want to learn
Policy gradient에 적용
objective function of policy gradient
θ∗=θargmaxJ(θ)
J(θ)=Eτ∼pθ(τ)[r(τ)]
우리가 만약 pθ(τ)에 대한 샘플을 가지고 있지 않으면 어떡할까?
And we have samples from some pˉ(τ) instead
pˉ(τ):q(x) - importance sampling distribution
importance sampling 식 사용해서 objective function 변경
J(θ)=Eτ∼pˉ(τ)[pˉ(τ)pθ(τ)r(τ)]
pθ(τ)=p(s1)t=1ΠTπθ(at∣st)p(st+1∣st,at)
pˉ(τ)pθ(τ)=p(s1)t=1ΠTπˉ(at∣st)p(st+1∣st,at)p(s1)t=1ΠTπθ(at∣st)p(st+1∣st,at)=t=1ΠTπˉ(at∣st)t=1ΠTπθ(at∣st)
πˉ : policy that we are sampling on
약분된 부분들은 같은 environmnet에서 왔으니 같은 값들이라서 cancle될 수 있었던 것임 수 있었던 것임
다시 최종 식을 보자면,
- 분모 : importance sampling에 따른 poicy
- 분자 : 우리가 끌어내고 싶은 policy
Deriving policy gradient with importance sampling
J(θ)=Eτ∼pˉ(τ)[pˉ(τ)pθ(τ)r(τ)]
위의 식에서 새로운 파라미터 θ′를 estimate하는 방법
J(θ′)=Eτ∼pθ(τ)[pθ(τ)pθ′(τ)r(τ)]
pθ′(τ) : the only bit that depends on θ′ that is the off-policy policy gradient parameter
▽θ′J(θ′)=Eτ∼pθ(τ)[pθ(τ)▽θ′pθ′(τ)r(τ)]=Eτ∼pθ(τ)[pθ(τ)pθ′(τ)▽θ′logpθ(τ)r(τ)]
θ=θ′이 되는 경우 약분 가능
The off-policy policy gradient
▽θ′J(θ′)=Eτ∼pθ(τ)[pθ(τ)pθ′(τ)▽θ′logpθ(τ)r(τ)]when θ=θ′=Eτ∼pθ(τ)[(t=1ΠTπθ(at∣st)πθ′(at∣st))(t=1∑T▽θ′logπθ′(at∣st))(t=1∑Tr(st,at))]
causality 적용하면
▽θ′J(θ′)=Eτ∼pθ(τ)[t−1∑T▽θ′logπθ′(at∣st)(t′=1Πtπθ(at′∣st′)πθ′(at′∣st′))(t′=t∑Tr(st′,at′)(t′′=tΠt′πθ(at′′∣st′′)πθ′(at′′∣st′′)))]
- t′=1Πtπθ(at′∣st′)πθ′(at′∣st′) : future actions don't affect current weight 반영
- t′′=tΠt′πθ(at′′∣st′′)πθ′(at′′∣st′′) : 이 항을 무시하면, policy iteration algorithm을 얻게 됨
그런데 밑의 식에서,
▽θ′J(θ′)=Eτ∼pθ(τ)[t=1∑T▽θ′logπθ′(at∣st)(t=1ΠTπθ(at∣st)πθ′(at∣st))(t=1∑Tr(st,at))]
πθ(at∣st)πθ′(at∣st)<1이기 때문에, 계속 곱하다보면 값이 엄청 작아지게 됨
θ에서 sampling하기 때문에 πθ가 πθ′보다 클 수밖에 없음
→ trajectory가 길다면, 뒤의 action은 gradient가 잘 흘러가지 못하게 됨
let's write the objective a bit differently
- on-policy policy gradient
▽θJ(θ)≈N1i=1∑Nt=1∑T▽θlogπθ(ai,t∣si,t)Q^i,t
- off-policy policy gradient
▽θ′J(θ′)≈N1i=1∑Nt=1∑Tπθ(si,t,ai,t)πθ′(si,t,ai,t)▽θ′logπθ′(ai,t∣si,t)Q^i,t ≈N1i=1∑Nt=1∑Tπθ(si,t)πθ′(si,t)πθ(ai,t∣si,t)πθ′(ai,t∣si,t)▽θ′logπθ′(ai,t∣si,t)Q^i,t
- 이때, suppose πθ′(st)=πθ(st) and ignore πθ(si,t)πθ′(si,t)
sometimes work in practice, when important sampling has same state distribution with the policy
