Advanced Policy Gradient
Progress beyond Vanilla Policy Gradient
- Natural Policy Gradient: REINFORCE
- PPO (Proximal Policy Optimization)
- TRPO (Trust Region Policy Optimization)
Basic idea in on-policy optimization
training performace를 무너뜨리는 taking bad actions의 경우를 피하자
- PPO
- line search : first pick direction, then step size
- TRPO
- trust region : first pick step size, then direction
둘이 opposite한 방식 사용
PPO가 stable
Improving the policy gradient: Lowering Variance
trajectory가 적을수록 variance는 높아짐
▽θJ(θ)≈N1i=1∑Nt=1T▽θlogπθ(ai,t∣si,t)(t′=1∑Tr(si.t′.ai.t′))
뒤에 −avg(r)을 더하기도 함
N=number of trajectory
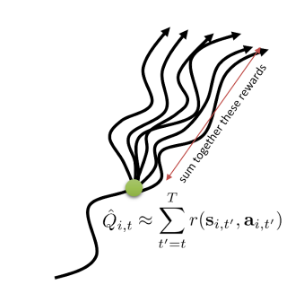
- (t′=1∑Tr(si.t′.ai.t′))=Q^i,t : reward to go
- state si,t에서 action ai.t를 취할 경우의 expected reward 추정값
st에서 할 수 있는 action이 다양하기 때문에 여러 시나리오(trajectory)가 존재함
can we get a better estimate?
- Q(st.at)=∑t′=tTEπθ[r(st′.at′)∣st.at] : true expected reward-to-go
Q^를 Q로 바꾸어 모든 trajectory를 고려하도록 함
→▽θJ(θ)≈N1i=1∑Nt=1T▽θlogπθ(ai,t∣si,t)Q(si,t,ai,t)
Baseline Trick: Lowering Variance
위의 식에서 reward가 언제나 양수면 학습을 잘 못하기 때문에, Q−V로 변경
→▽θJ(θ)≈N1i=1∑Nt=1T▽θlogπθ(ai,t∣si,t)(Q(si,t,ai,t)−V(si,t))
- Q(si,t,ai,t)−V(si,t) : Advantage function
- Q(si,t,ai,t) : 모든 시나리오의 reward 평균
- V(si,t) : b(=baseline)
lower the variance를 통해 학습이 더 stable할 수 있도록 함
bt=N1i∑Q(si,t,ai,t)
V(st)=Eat∼πθ(at∣st)[Q(st,at)]
=Vπ(st)=t′=t∑TEπθ[r(st′,at′)∣st′]
이때, baseline은 trajectory에 따라 다름(depend on state)
state가 action보다 reward에 영향 大
→ 다양한 action에 대해 평균 내서 구함
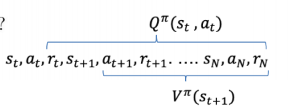
State & State-action Value Function
- Qπ(st,at)=t′=t∑TEπθ[r(st′,at′)∣st,at] : total reward from taking at in st
- Vπ(st)=t′=t∑TEπθ[r(st′,at′)∣st′] : total reward from st
- Aπ(st,at)=Qπ(st,at)−Vπ(st) : how much better at is
- ▽θJ(θ)≈N1i=1∑Nt=1∑T▽θ(ai,t∣si,t)Aπ(si,t,ai,t)
다양한 trajectory를 사용하기 때문에,
the better this estimate, the lower the variance
그러나 sample에 따라 미분값이 달라지는 biased 발생
policy gradient와의 비교
▽θJ(θ)≈N1i=1∑Nt=1∑T▽θ(ai,t∣si,t)(t′=1∑Tr(si,t′,ai,t′−b))
b에 따라 미분값에 변화가 없기 때문에 unbiased
but high variance single-sample estimate
Value Function Fitting
무엇을 fit해야 되냐면...
이에 따라서
Qπ(st,at)=r(st,at)+Vπ(st+1)
→Aπ(st,at)=Qπ(st,at)−Vπ(st) =r(st,at)+Vπ(st+1)−Vπ(st)
⇒ Vπ(s)만 fit하면 됨
Policy Evaluation
Vπ(st)=t′=t∑TEπθ[r(st′,at′∣st)]
J(θ)=Es1≈p(s1)[Vπ(s1)]
여기서 policy evaluation은 Monte Carlo policy evaluation을 통해 함
what policy gradient does
- Vπ(st)≈t′=t∑Tr(st′,at′)
- Vπ(st)≈N1i=1∑Nt′=t∑Tr(st′,at′)
다양한 초기 조건을 통해 더 일반적인 추정치를 얻기 위해 시뮬레이터를 여러 번 초기화
추정의 신뢰성을 높이기 위해 많은 trajectory를 생성해야 하므로, 시뮬레이터를 reset해서 여러 에피소드를 독립적으로 진행
Monte Carlo evaluation with function approximation
Vπ(st)≈t′=t∑Tr(st′,at′) 은 Vπ(st)≈N1i=1∑Nt′=t∑T 만큼 좋지는 않음
but still pretty good!
-
training data: (si,t,∑t′=tTr(si,t′,ai,t′)) ∑t′=tTr(si,t′,ai,t′):yi,t
-
supervised regression: L(ϕ)=21i∑∥V^ϕπ(si)−yi∥2
Can we do better?
-
ideal target
yi,t=t′=t∑TEπθr(st′,at′∣si,t)≈r(si,t,ai,t)+Vπ(si,t+1)≈r(si,t,ai,t)+V^ϕπ(si,t+1)
-
Monte carlo target
yi,t=t′=t∑Tr(ai,t′,ai,t′)
-
training data
(si,t,r(si,t,ai,t)+V^ϕπ(si,t+1))
- V^ϕπ(si,t+1) might incorrect
- r(si,t,ai,t)+V^ϕπ(si,t+1)=yi,t
-
supervised regression
L(ϕ)=21i∑∥V^ϕπ(si)−yi∥2
sometimes referred to as a "bootstrapped" estimate
low variance, high bias
이해가 안 돼서 gpt한테 물어봤는데
- Low Variance:
bootstrapped target r(si,t,ai,t)+V^ϕπ(si,t+1)는 다음 상태의 가치 함수 추정치를 사용해 평균적인 변동성을 줄이므로 Monte Carlo 방식보다 variance가 낮아 학습이 안정적
- High Bias:
target이 미래 상태에 대한 추정치에 기반하므로, 초기에는 부정확한 추정치가 누적될 가능성이 있음. 이는 이상적인 target보다 낮은 수준의 정확도를 제공하게 되어 편향이 발생 가능
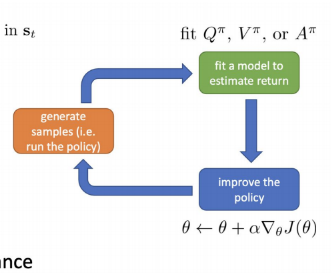
From Evaluation to Actor Critic
An actor-critic algorithm
batch actor-critic algorithm
- sample si,ai from πθ(a∣s) (run it on the robot)
- fit V^ϕπ(s) to sampled reward sums
- evaluate A^π(si,ai)=r(si,ai)+V^ϕπ(si′)−V^ϕπ(si)
si′=si+1
- ▽θJ(θ)≈i∑▽θlogπθ(ai∣si)A^π(si,ai)
- θ←θ+α▽θJ(θ)
이때,
- yi,t=r(si,t,ai,t)+V^ϕπ(si,t+1)
- L(ϕ)=21i∑∥V^ϕπ(si)−yi∥2
알고리즘에 optimize는 policy를 하는 거고, V는 이 loss function을 이용해 optimize함
on-policy에서 기원한 알고리즘이라 trajectory를 모두 꺼내고 다음을 진행해야 함 → 시간이 오래 걸리고 비효율적
Putting Discount Factors
T(episode length)가 ∞인 경우,
V^ϕπ can get infinitely large in many cases
simple trick: better to get reward sooner than later
yi,t≈r(si,t,ai,t)+γV^ϕπ(si,t+1)
여기서 γ∈[0,1] : discount factor 0.99 works well
Aπ(st,at)=Qπ(st,at)−Vπ(st)=r(st,at)+Vπ(st+1)−Vπ(st)≈r(st,at)+γVπ(st+1)−Vπ(st)
Actor-critic algorithm (with discount)
batch actor-critic algorithm
- sample si,ai from πθ(a∣s) (run it on the robot)
- fit V^ϕπ(s) to sampled reward sums
- evaluate A^π(si,ai)=r(si,ai)+γV^ϕπ(si′)−V^ϕπ(si)
si′=si+1
- ▽θJ(θ)≈i∑▽θlogπθ(ai∣si)A^π(si,ai)
- θ←θ+α▽θJ(θ)
online actor-critic algorithm
bootstrapping한 알고리즘
- take action a∼πθ(a∣s), get (s,a,s′,r)
- update V^ϕπ using target r+γV^ϕπ(s′)
- evaluate A^π(si,ai)=r(si,ai)+γV^ϕπ(si′)−V^ϕπ(si)
si′=si+1
- ▽θJ(θ)≈i∑▽θlogπθ(ai∣si)A^π(si,ai)
- θ←θ+α▽θJ(θ)
한 timestep에서만 trajectory를 뽑을 수 있게 되어 sampling efficent해짐
one transition(st,at,rt)만 가지고 와서 학습이 가능해짐
