Beam Search
- 디코더에서 단어 예측할 때, 확률 기반이므로 어떤 단어를 선택할지 돕는 알고리즘
- Greedy decoding
- 현재 타임 스텝에서 확률이 가장 큰 단어 (가장 좋아보이는 단어) 를 선택
- 만약 잘못 예측했다면? 돌아가야하는데 갈 수 없음 → 다음 후보군 필요
- Exhaustive search
- 이상적으로는 전체 경우의 수를 다 따지는게 맞음
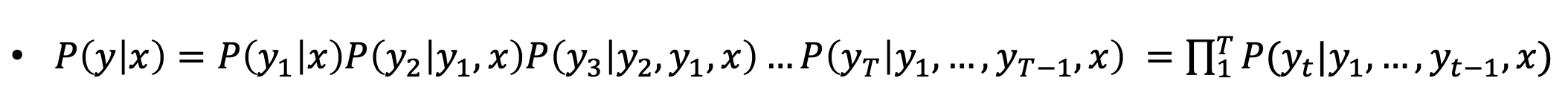
- 매 타임 스텝마다 V (보캡 사이즈) 의 t 승의 경우의 수를 구해야함 → 시간 소요 너무 큼
- 적당한 크기 후보군 선정, Beam Search
- 아이디어 : 디코더의 매 타임 스텝마다, k 개의 후보군을 정하고 가장 높은 확률 단어 선택, 후보 상황을 hypothesis 라고 부름
- k : beam size (보통 5~10 사용)
- 로그로 확률값들을 더함

- 모든 경우를 따지는 것보다는 정확하지 않지만 훨씬 효율적임
- 예시
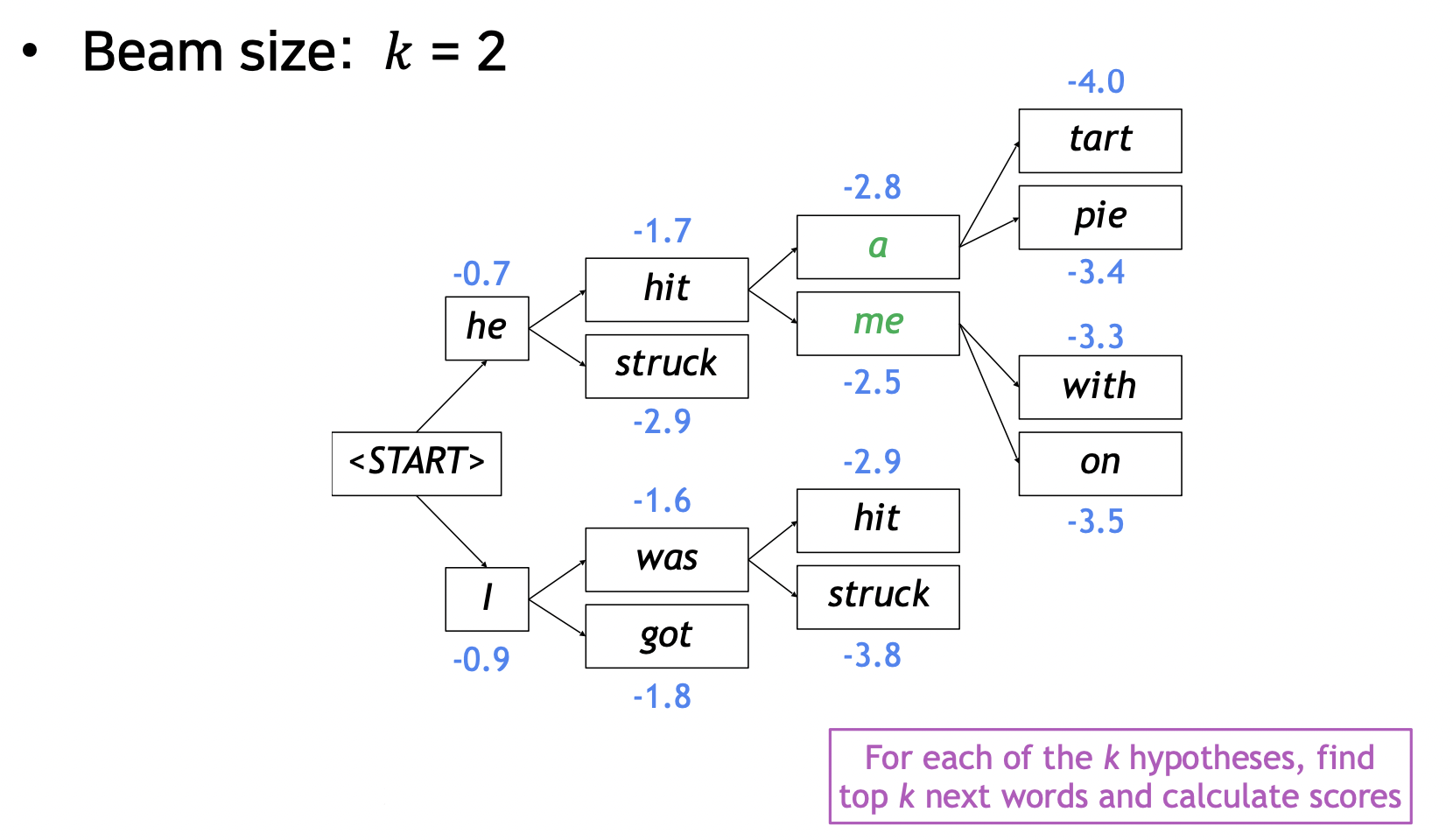

-
매 타임 스텝마다 k 개 단어를 뽑고 각 경우의 확률을 구함
-
언제 빔서치가 멈추는가?
- 각 가정은 END 토큰을 만나면 멈춤
- 멈춘 가정들의 결과를 따로 저장해 둠
- 빔서치가 멈추는 경우는 정해둔 타임스텝 T 까지만 디코딩해서 멈추거나 n 개의 가설이 완료되면 멈춤
-
완성된 가설들 중 가장 높은 점수를 지닌 가설을 선택, log 결합확률분포로 구함
-
가설의 길이가 짧을수록 점수가 높다는 문제가 있음 (항상 - 값을 더해주므로 긴 가설은 점수가 낮음)
-
공평하게 비교하기 위해 각 가설의 길이로 Normalize 진행

-
BLEU score
- 문장 예측 결과의 성능을 측정하는 지표
- 기존 방법들의 문제점
- 단어가 맞는지 칸칸이 비교하는 방법의 경우, 잘 번역했어도 한 두 단어가 추가, 누락된 경우 낮은 정확도가 나옴
- 정답 : I love you, 예측 : My I love you ⇒ 칸칸이 비교하므로 0% 정확도
- 다른 방법, F-measure
- 단어가 맞는지 칸칸이 비교하는 방법의 경우, 잘 번역했어도 한 두 단어가 추가, 누락된 경우 낮은 정확도가 나옴
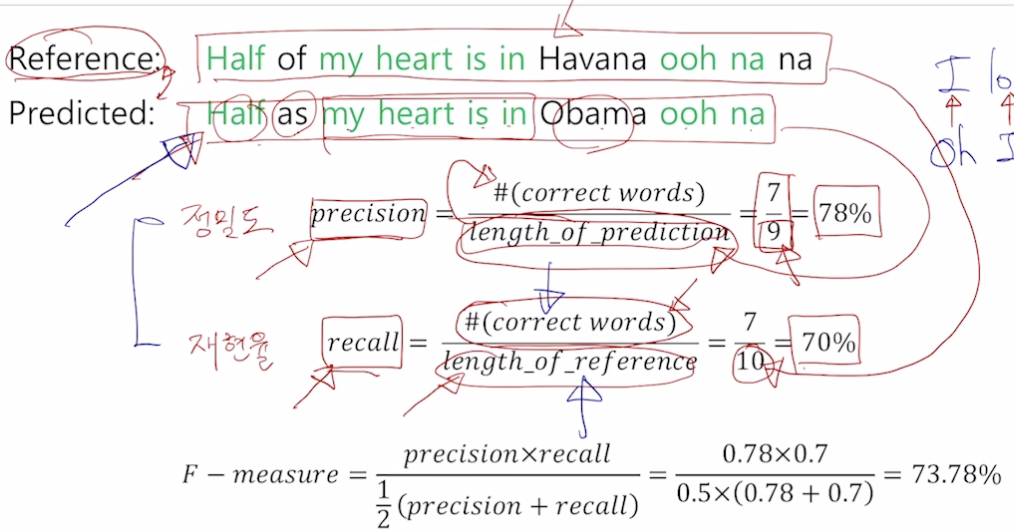
- 정밀도 : 예측된 결과가 나왔을 때 실질적으로 느끼는 정확도
- 재현율 : 전체 결과 중 예측 결과로 나오지 않은 누락 정보를 알 수 있음 (아비터의 리콜처럼 소환 기능, 누락되지 않게 소환해야 리콜 잘한 것)
- 위 두 값을 평가하기 위해 F-measure (조화평균, 여기서는 역수로 안더하는듯) 사용
- 산술평균 (더하고 나누기 개수) ≥ 기하평균 (곱하고 루트 개수) ≥ 조화평균 (역수 더하고 개수로 나누고 다시 전체 역수)
- 문제점

- 말이 되지 않는 문장인데 점수가 높음
- BiLingual Evaluation Understudy (BLEU)
- 개별 단어 레벨에서 얼마나 겹치냐 + N-gram (얼마나 연속으로 맞는지) 반영 (N 은 1~4 모두 사용)
- 정밀도만 고려하고 재현율은 사용하지 않음 (정밀도의 특성 때문, 번역 결과만 보고 고려하기 때문)

- brevity penalty 는 실제 문장보다 짧게 문장을 뽑아내면 점수를 낮춰주고, 너무 많아지면 1 로만 계산하기 위해 사용
- 산술 평균보다는 작게 만들고 싶고, 조화 평균은 너무 작은 값에 치중하므로 기하 평균 사용
- 예시

Further Reading
참조
BoostCamp AI Tech

데이터로 문제를 해결하는 엔지니어를 꿈꿉니다.