Seq2Seq Model
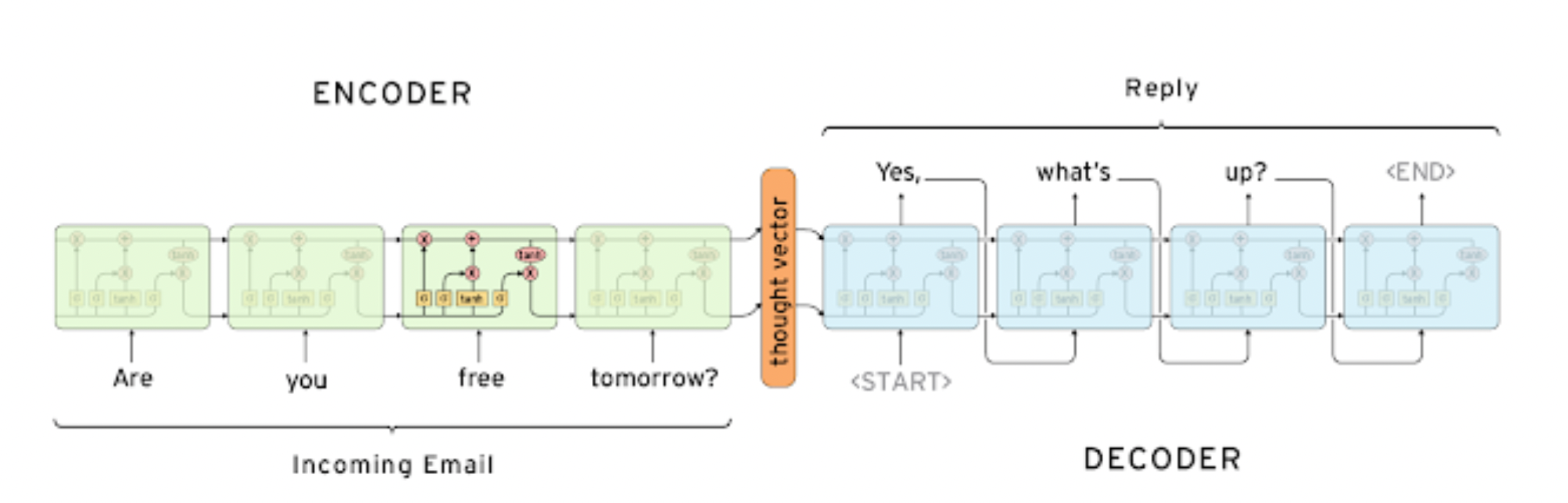
- many to many, 번역 모델에 사용
- 단어 시퀀스를 입력으로 받고 단어 시퀀스를 출력으로 줌
- 인코더 - 디코더 구조
- 인코더 : 입력 문장을 모두 받음
- 디코더 : 인코더의 마지막 히든 스테이트 벡터와 sos 를 입력으로 하여 단어 시퀀스 출력, 마지막에 eos 가 들어오면 종료
- LSTM 사용
- 문제점
- 벡터는 크기가 고정, 입력 문장이 짧든 길든 마지막 히든 스테이트 벡터에 정보가 다 담겨야 하므로 표현에 부족함이 있음
- LSTM 으로 롱텀 디펜던시를 해결했더라도 문장이 길면 부족한 성능
- 인코더의 첫 단어와 디코더의 첫 단어를 내야 하는데 멀어서 잘 못함
Attention
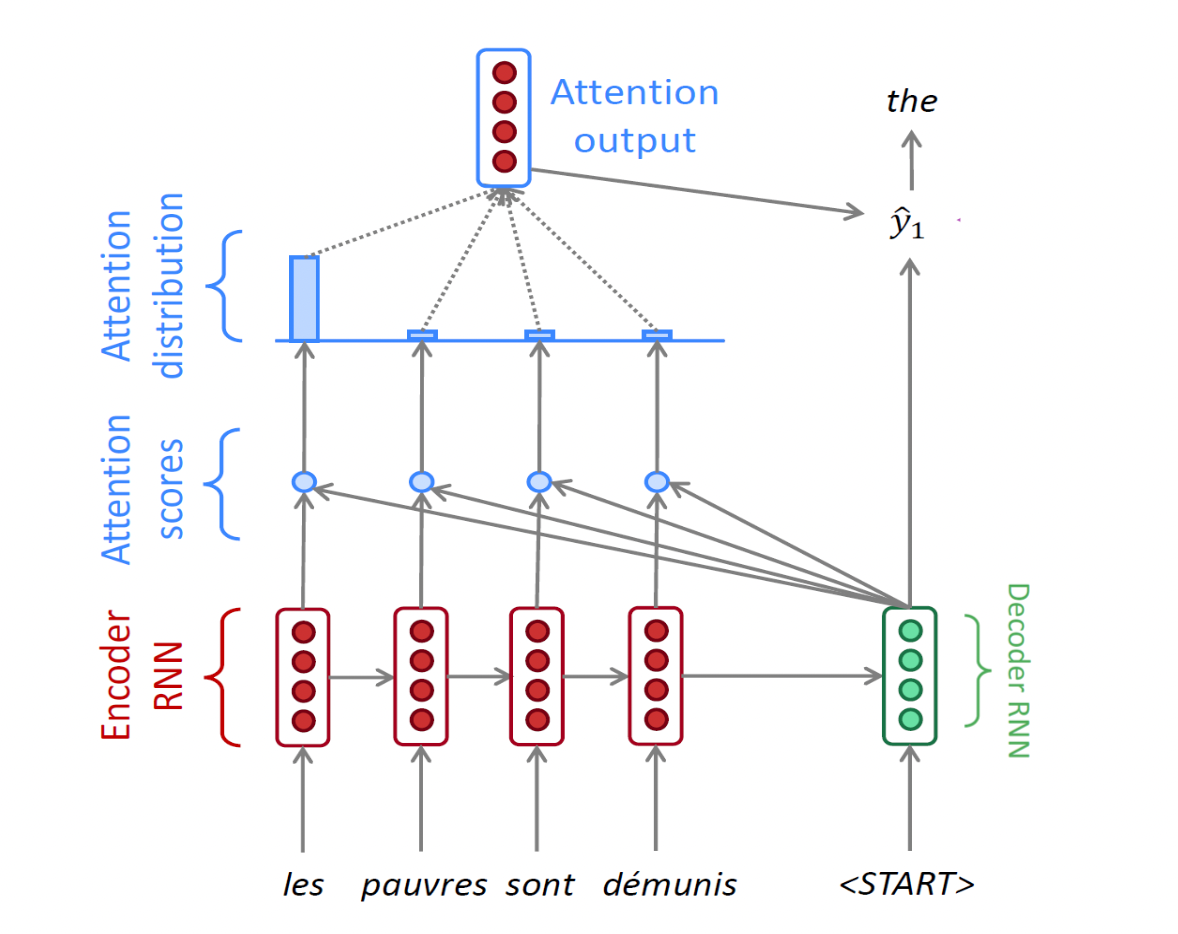
- 인코더에서 나온 마지막 h 와 디코더의 입력으로 디코더의 h 를 만들고 이를 인코더 입력 단어 각각의 히든 스테이트 벡터와 어텐션 스코어를 계산 (내적) 한 후 어텐션 분포 (소프트맥스) 를 만듦. 이 분포를 어텐션 벡터 (합이 1 인 확률분포)라고 함.
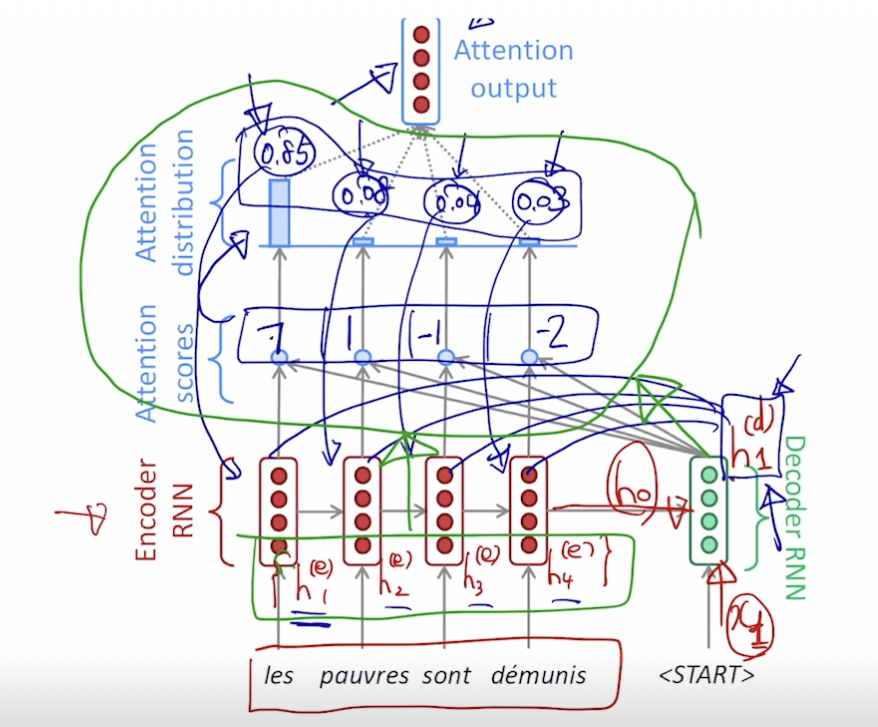
- 만들어진 어텐션 분포를 인코더의 각 히든 스테이트 벡터에 적용해서 가중 평균을 구함. 이 가중 평균은 어텐션 아웃풋, 또는 컨텍스트 벡터가 됨
- 즉, 위에서 파란 부분은 어텐션 모듈이고 그 입력으로 디코더의 h 벡터와 인코더 단어들의 각 h 벡터 세트가 들어가서 하나의 컨텍스트 벡터를 출력함
- 디코더의 h 벡터는 컨텍스트 벡터와 concat 되어 단어 예측에 사용
- 디코더의 히든 스테이트 벡터는 어텐션을 만드는 역할과 출력 단어를 만드는 역할을 수행함. 역전파 과정에서는 예측 단어가 실제 단어와 다르면 어텐션의 웨이트들과 디코더의 웨이트는 같이 수정됨.
- 학습에는 Teacher forcing 함, ground truth 를 디코더의 입력으로 넣음. 하지만 Teacher forcing 을 안했을 때 regularlization 이 잘되므로 초반에 Teacher forcing 사용
Q. 컨텍스트 벡터는 같은게 계속 갱신되는거겠지? 그 전에 어텐션 벡터 (분포) 는 계속 갱신되는거겠지?
→ 갱신이 아니라 어텐션은 그냥 계산해서 디코더 스텝 단계에서 빼주는 역할
Different Attention Mechanism
- 디코더의 h 벡터와 인코더의 각 h 벡터로 어텐션 구하는 법
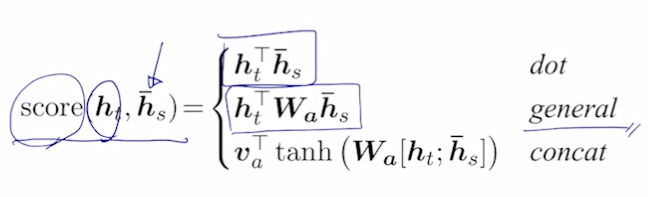
- general
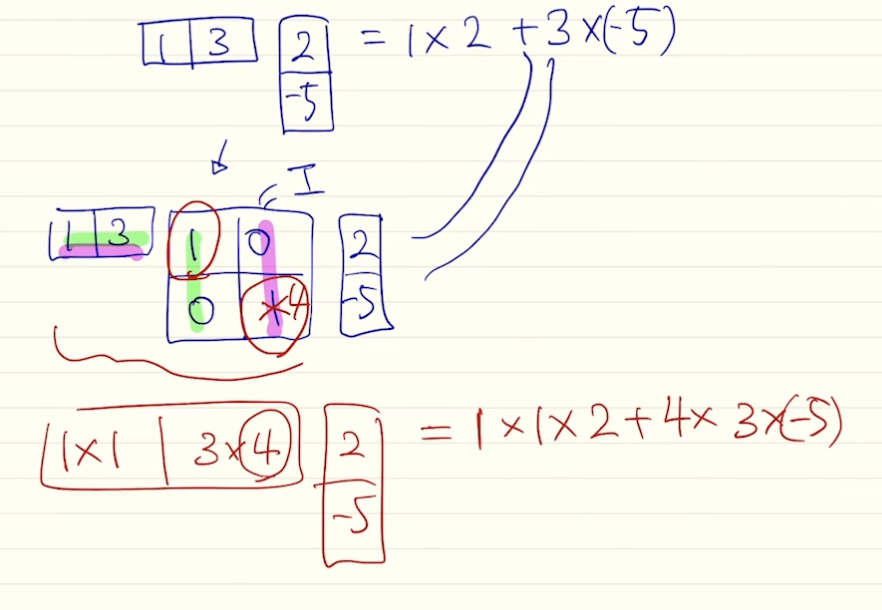
- 벡터끼리 곱을 하는 내적에서 항등행렬을 가운데 곱해도 결과는 그대로임. 여기서 항등행렬의 값을 변형시키는 방식 사용 가능 → 가중치가 됨
- 항등행렬말고 이 행렬의 값을 a, b, c, d 로 변형시키면 내적이라는 단순한 계산을 더 확장시켜 어텐션을 구할 수 있게 해줌
- concat
- 디코더의 h 와 인코더의 h 를 통해 스칼라를 구해야 함. 이 때, 내적 말고 MLP 로 해결하려 함. 두 벡터를 concat 하고 MLP 수행해서 스칼라 구함.
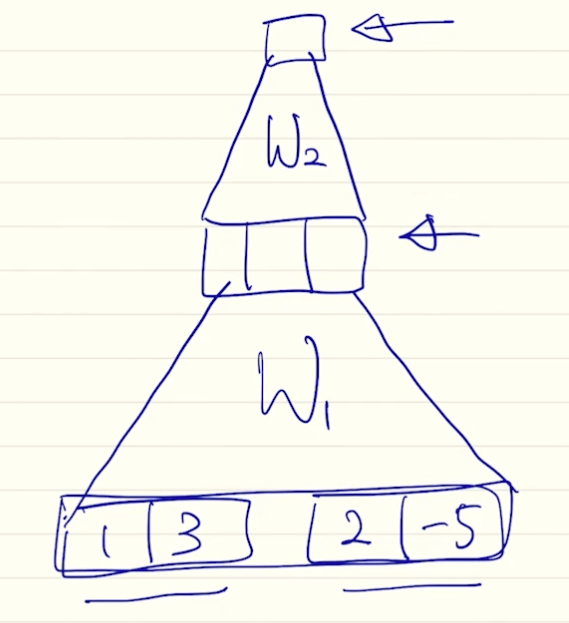
- 는 첫 번째 웨이트, 는 두 번째 웨이트
- 이 파라미터들은 전체 역전파 과정에서 학습됨
어텐션 장점
- NMT 기계번역 분야에서 성능 많이 높임
- 디코더가 입력의 어느 부분에 초점을 맞출지 알게됨
- 문장이 길수록 초반 단어의 의미가 퇴색되는 bottleneck 현상 해결
- 디코더가 직접 입력 단어의 h 를 보므로
- vanishing gradient 문제 해결
- 멀리 있는 뒤에 단어부터 역전파 해오면 처음 단어 쪽 웨이트는 학습이 잘 안 되는데, 어텐션으로 지름길이 생겨서 학습 영향 끼침
- 새로운 해석을 할 수 있게 해줌
- 어텐션 분포 (어텐션 벡터) 를 조사해서 디코더가 어떤 것에 집중하는지 알 수 있음
- 언제 어떤 단어를 봐야할 지 스스로 학습함
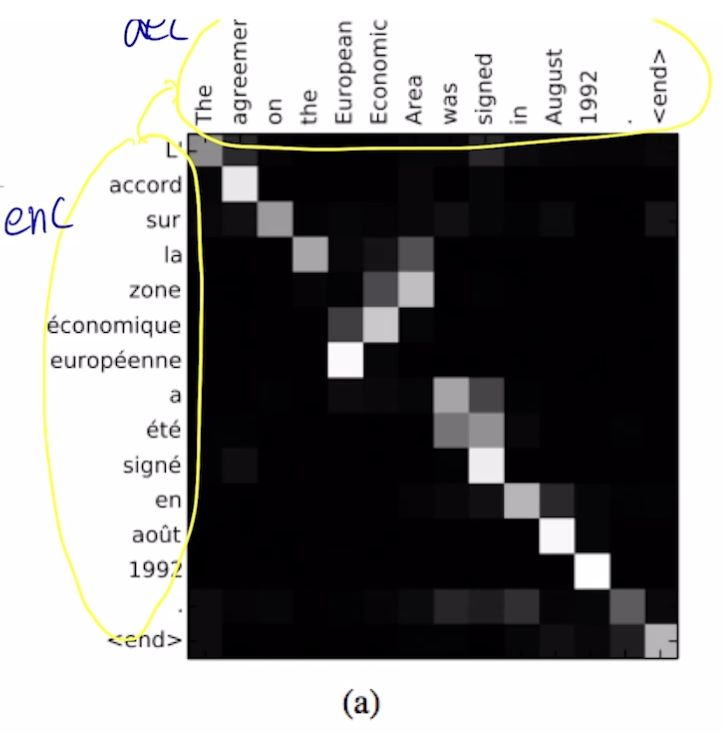
- 왼쪽이 입력, 오른쪽이 출력
- 디코더에서 어떤 입력에 집중하는지 알 수 있음
- 입력 문장과 출력 문장의 어순 차이 등도 극복 가능
Further Reading
- Sequence to sequence learning with neural networks, ICML’14
- Effective Approaches to Attention-based Neural Machine Translation, EMNLP 2015
- CS224n(2019)_Lecture8_NMT
참조
BoostCamp AI Tech

데이터로 문제를 해결하는 엔지니어를 꿈꿉니다.