참고
지난 번에 배운 Transformer 내용도 참고하자.
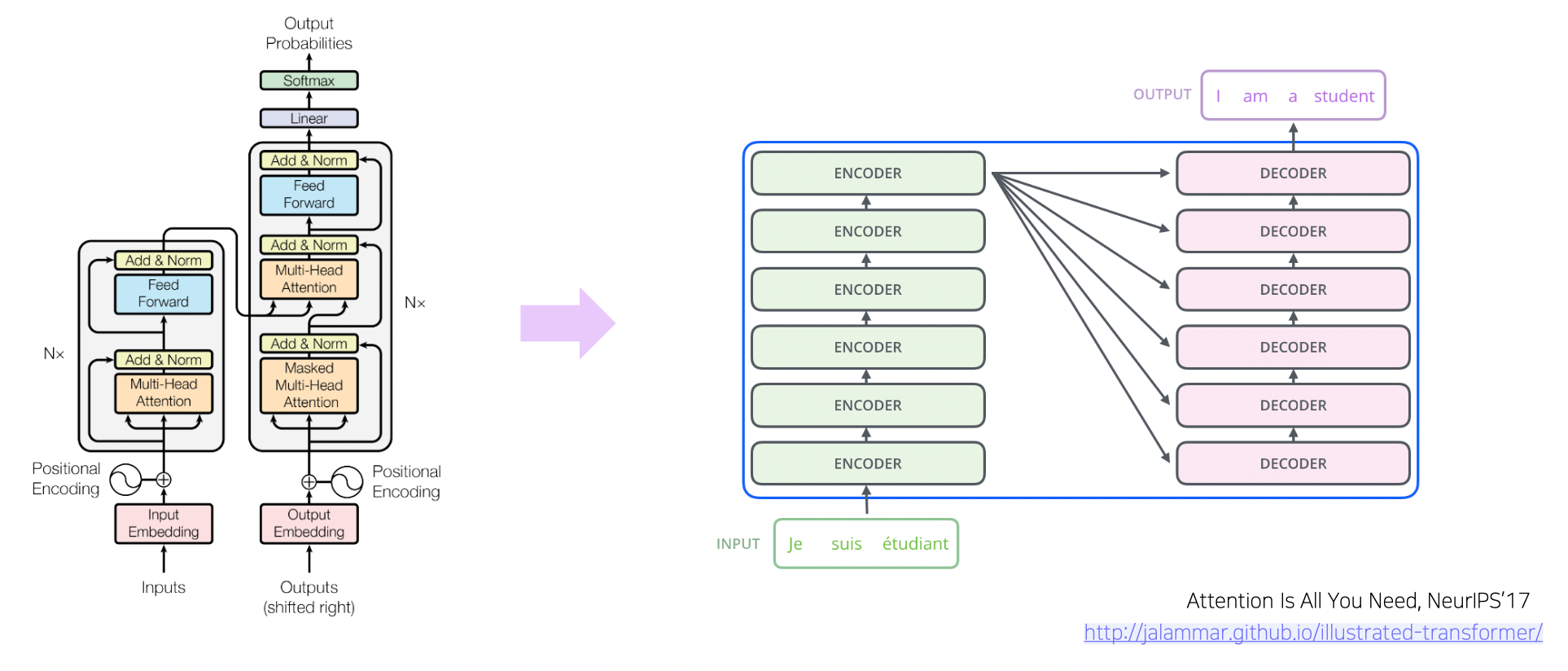
특징
- RNN 구조 대신 Attention 으로만 번역 모델 구성
- Long-Term Dependency 해결
- 인코더와 디코더에서 어텐션 사용
- 기존 어텐션과 다르게 자기 문장 내에서 어텐션을 수행하므로 셀프 어텐션
- 쿼리 : 해당 단어와 관련된 벡터
- 키 : 문장 내 각 단어와 관련된 벡터
- 밸류 : 쿼리와 키로 구한 확률분포와 결합되는 벡터
- 한 단어의 쿼리와 모든 단어의 키를 내적하여 벡터를 만듦 → 이를 소프트맥스하여 가중치를 만들고 모든 단어에 대한 밸류 벡터의 가중 평균을 얻어냄
- 멀리 있는 단어끼리도 정보를 알 수 있음
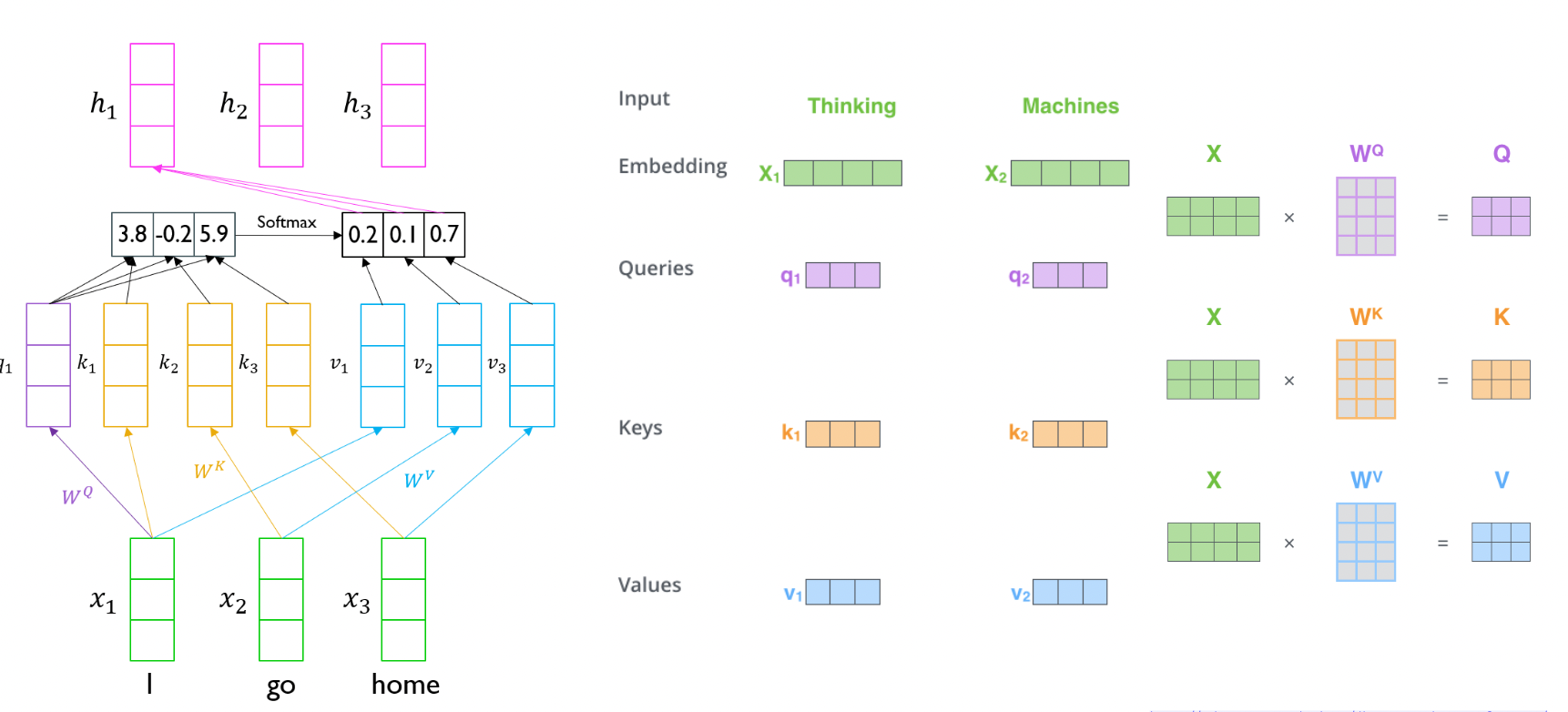
Scaled Dot-Product Attention
- 입력 : 한 단어의 Q 와 모든 단어의 K, V (Q, K, V, Output 은 모두 벡터임)
- 출력 : 밸류 벡터의 가중합
- Q, K 는 내적을 하기 때문에 차원이 같아야 함. V 는 상관없음 (실제 구현에서는 Q, K, V 차원 같게 함)
- 수식
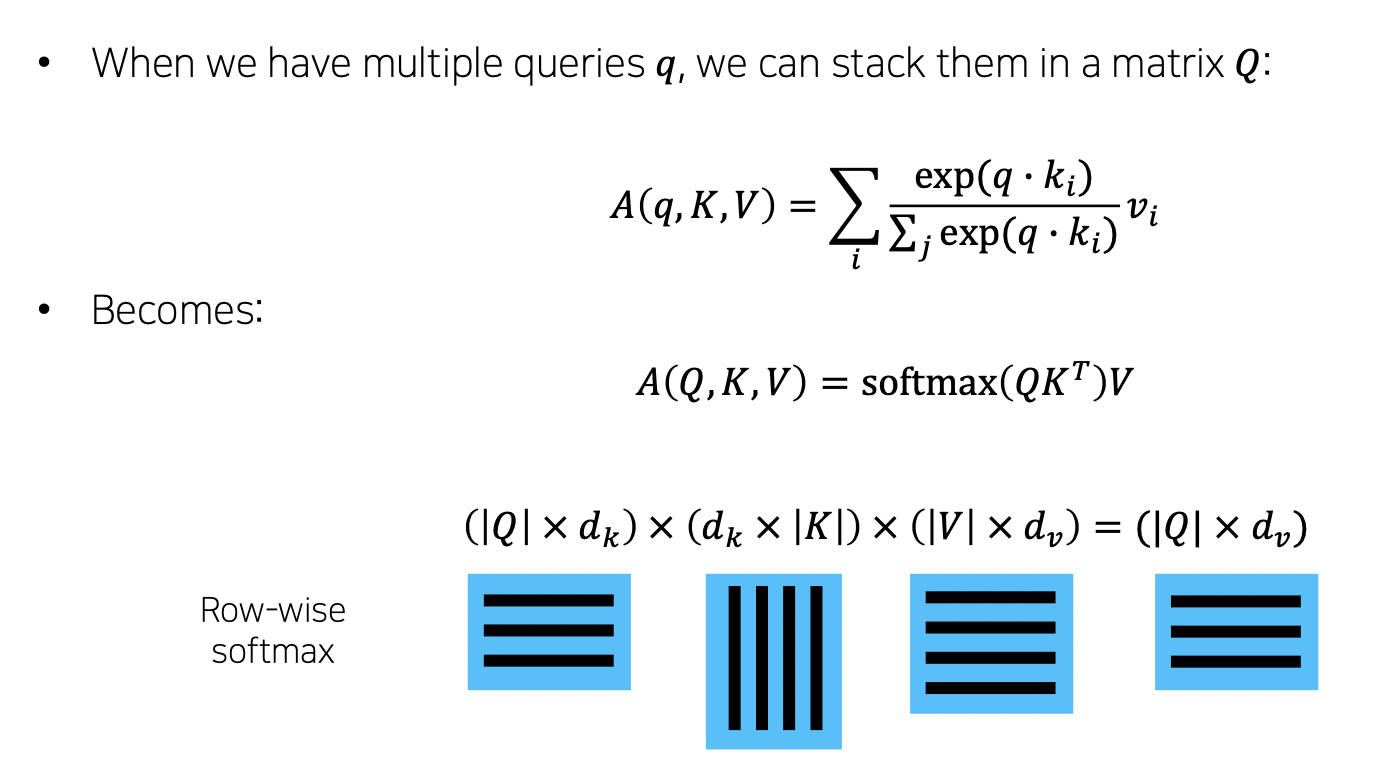
- scaled (루트 k차원으로 나누기)
- Q 와 K 의 차원이 커질 수록 QK(T) 값이 커짐, 따라서 softmax 시 큰 값은 매우 커지고 작은 값은 매우 작아지는 문제 발생
- 이를 해결하기 위해 정규화 필요. 정규화로 표준편차를 나눠주고자 함. 이 때 분산은 차원개수와 동일하므로 루트(차원개수) 를 나눔. 분산 1 로 유지. (Q 와 K 의 곱해지는 값들이 모두 독립이라 하면 각각 분산은 1 임 (이상적으로). QK(T) 하면 11 dk 가 됨)
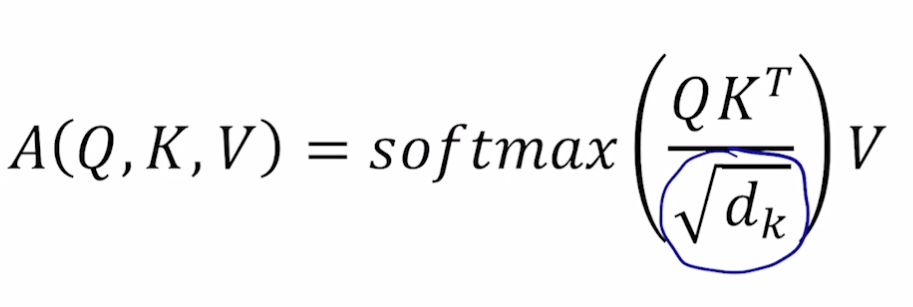
Multi-head Attention
- 단일 어텐션은 단어들끼리 연관성을 짓는 방법이 하나이므로 만약 잘못된 연관이 지어질 경우 성능이 낮아짐

- 멀티 헤드 어텐션 수행 후 concat 하고 다시 원래 차원으로 돌려냄
- 각 단어의 임베딩을 헤드 개수만큼 쪼개서 수행
- Cost

- Complexity per Layer : RNN 에 비해 Self-Attention 은 각 어텐션에 대한 정보를 지녀야하므로 더 많은 메모리 소요
- Sequential Operations : 하지만 GPU 개수만 된다면 병렬 연산이 가능하므로 RNN 에 비해 좋음 (RNN 은 순차진행이니까 병렬해도 오래걸림)
- 따라서 트랜스포머는 RNN 에 비해 메모리는 많이 먹지만 학습 시간은 적게 듦
- Sequential Operations : 멀리 있더라도 뒤에 있는 단어가 앞 단어를 참조할 수 있음
Block 단위로 보기
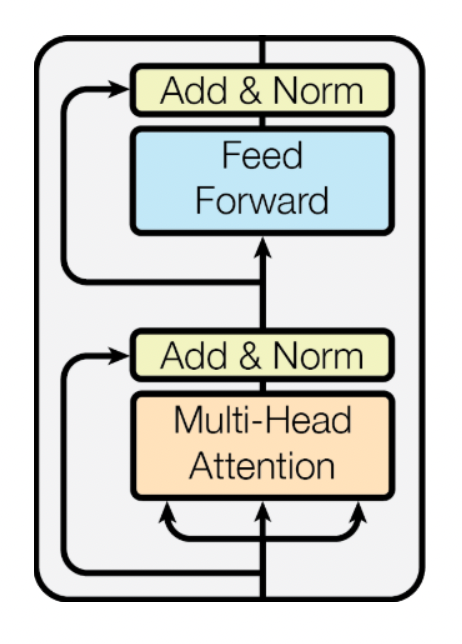
- Multi-Head Attention 부분과 Feed Forward 부분으로 나뉨
- 각 부분은 만들어진 벡터에 Residual connection (이를 위해서는 입력과 출력 벡터 차원이 같아야 함) 을 진행하고 Norm 을 수행
Layer Normalization
- Normalization
- 딥러닝에 다양한 Normalization 존재 → 주어진 다수의 sample 에 대해 평균을 0, 분산을 1 로 만든 뒤 원하는 평균과 분산으로 구성할 수 있도록 함
- Normalization 을 거친 후 y = 2x + 3 의 x 에 넣어주면 (affine transformation) , 평균은 3, 분산은 2 의 제곱이 됨
- 이들은 경사하강법의 파라미터가 됨
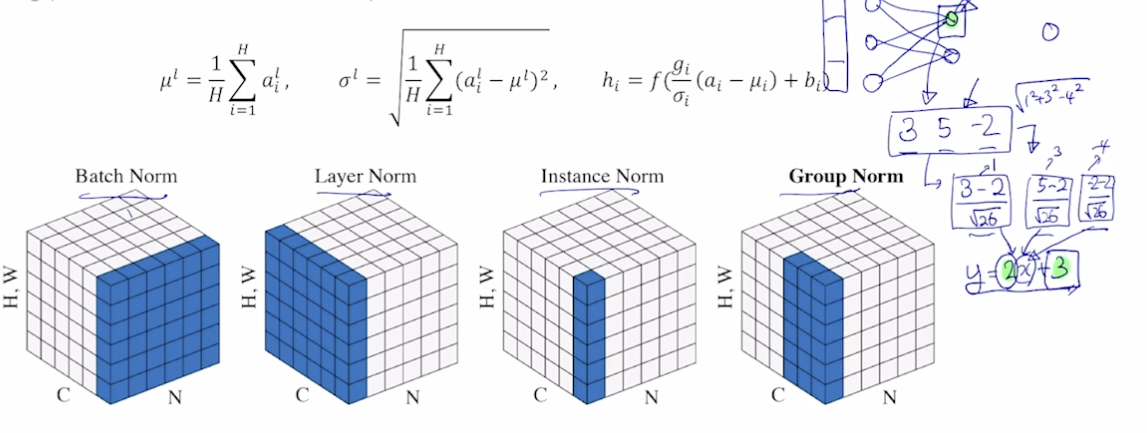
- Layer Normalization
- 각 레이어에 대해 평균과 표준편차를 구해서 normalization 수행, 이후 affine transformation 수행
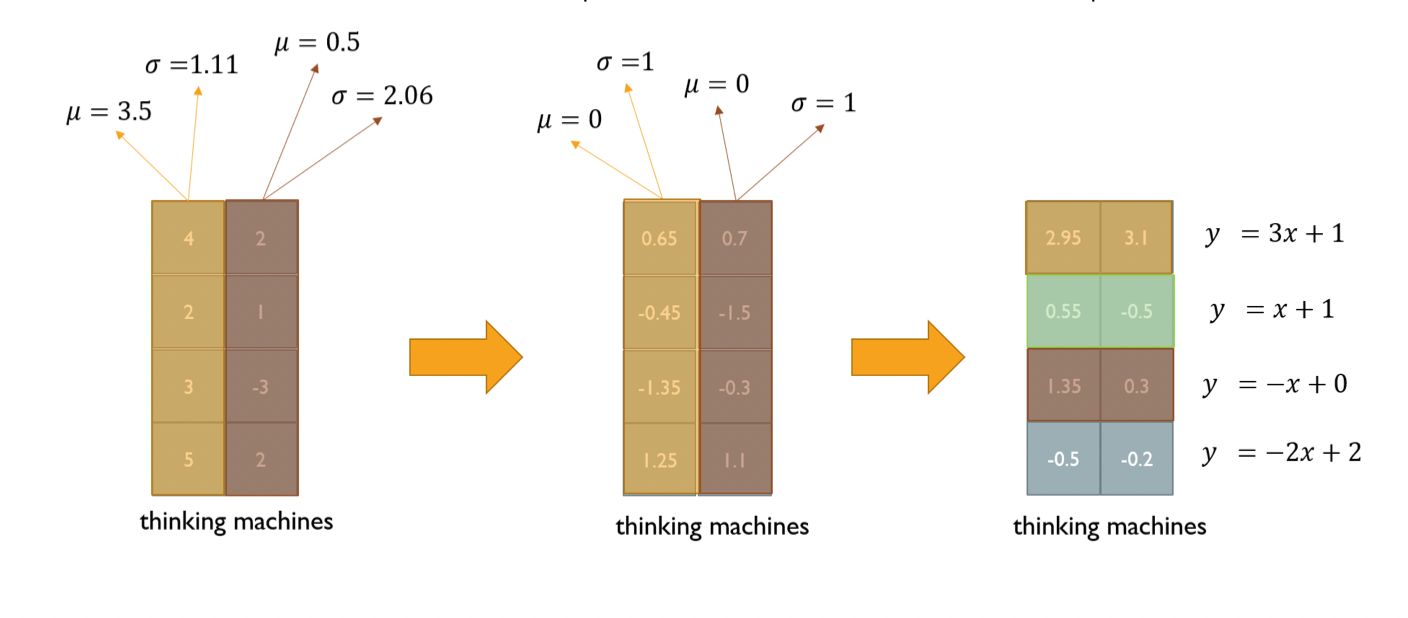
- 학습 안정화 + 성능 조금 더 끌어올림
Positional Encoding
- RNN 과 다르게 Self-attention 기반 모듈은 가중치를 구하면 순서에 상관없어짐. 마치 순서를 고려하지 않는 집합으로 인코딩하는 것과 같아짐
- 따라서 위치 정보를 주는 Positional Encoding 필요
- I go home 에서 I 가 처음이라는 것을 벡터에 기록해줌
- 간단한 방법으로는 I = [3, -2, 4] 에서 첫 번째에 1000 을 더해줌 [1003, -2, 4]
- 이런 식으로 유니크하게 순서를 알 수 있게 특정 상수를 벡터에 더해줌. sin, cos 주기 함수 사용
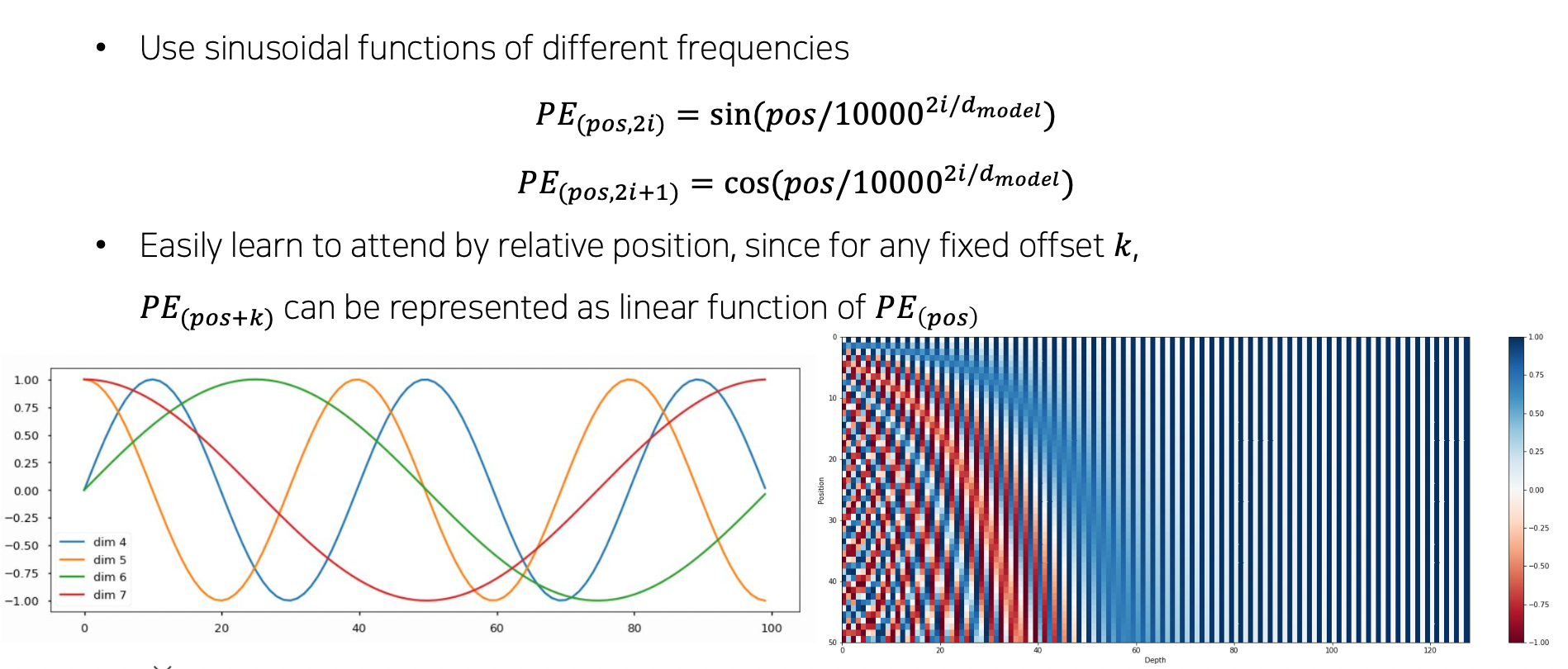
- dim 개수만큼 특정한 sin, cos 그래프가 생김
- 어떤 단어가 어떤 위치에 있었는지 알 수 있게 됨
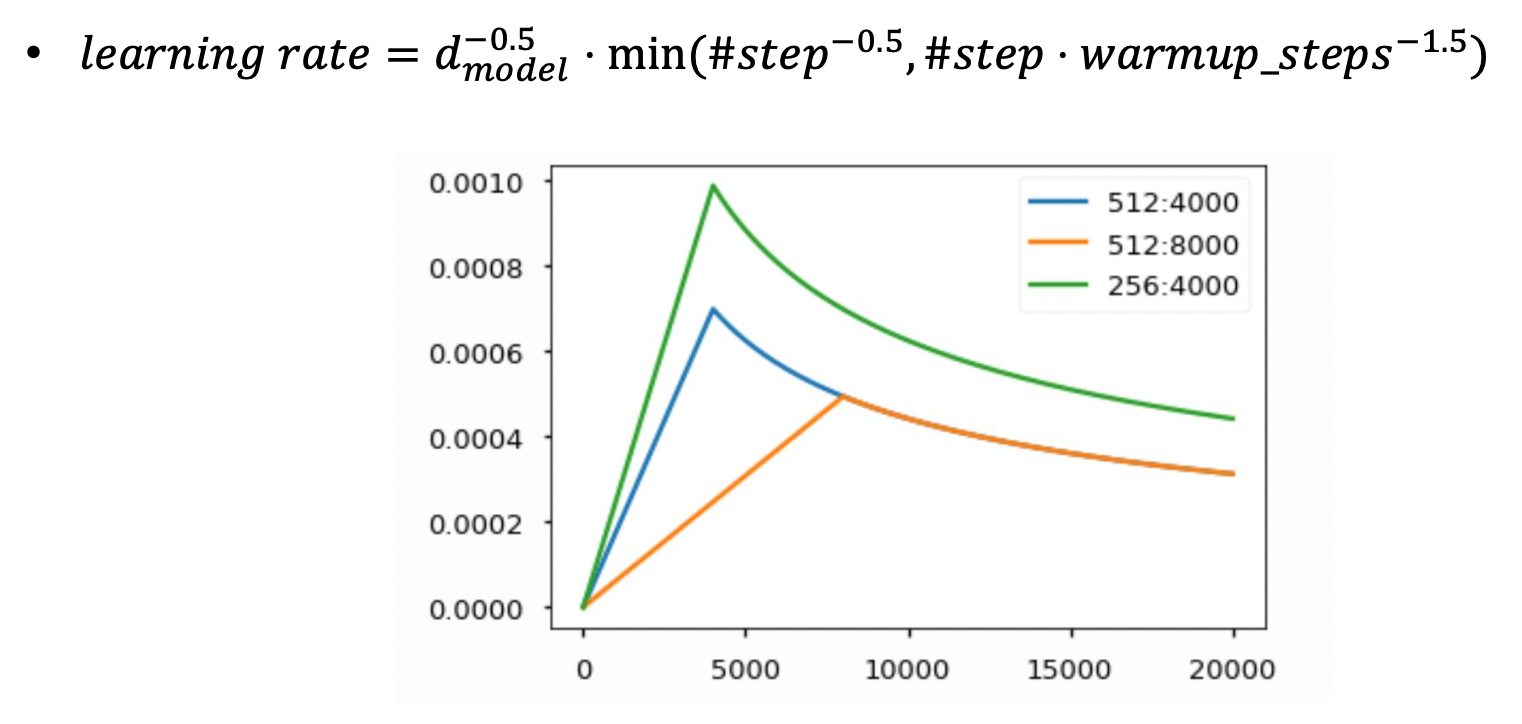
Warm-up Learning Rate Scheduler
- 학습 중에 러닝 레이트를 적절히 변경시킴
인코딩 과정
- 단어 임베딩
- 포지셔널 인코딩 더하기
- 멀티헤드 어텐션 수행
- Residual (원래값 더하기) 후 Layer Normalization
- Feed Forward 수행
- Residual (원래값 더하기) 후 Layer Normalization
- 위 과정을 N 번 (6, 12, 24 등, 독립적인 파라미터 가짐) 만큼 진행. stack (시퀀셜하게 진행)
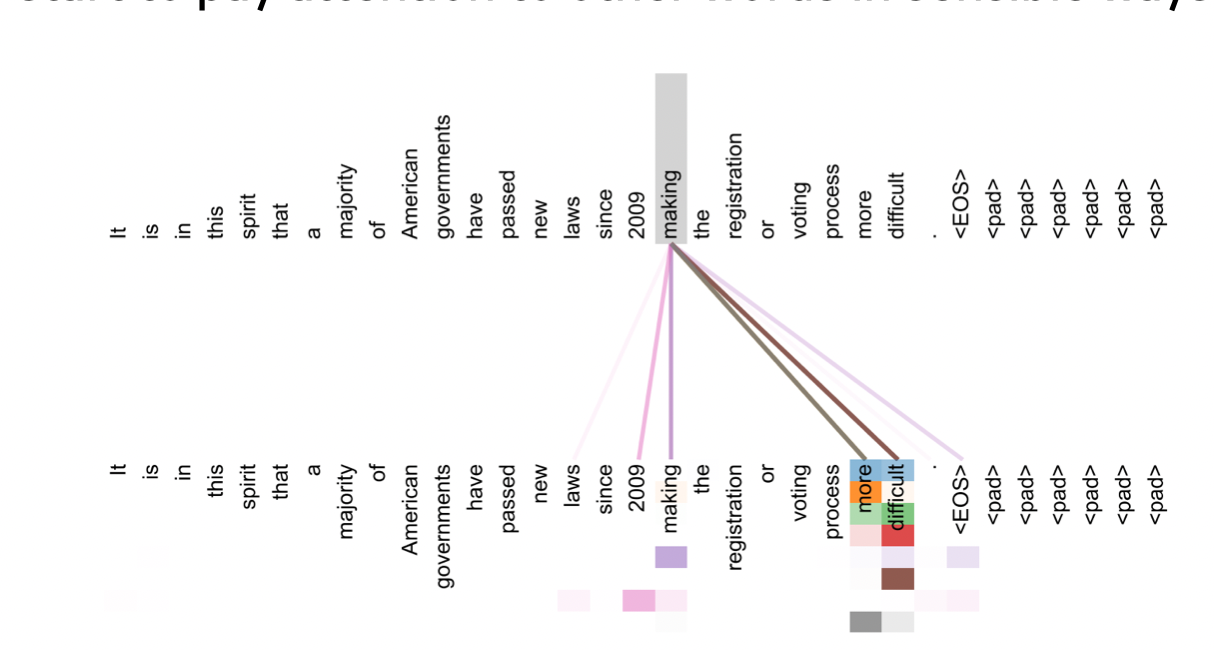
- 사진과 같이 멀티헤드 어텐션으로 인해 한 단어가 문장 내 다른 단어와 어떻게 연관짓는지 알 수 있음
Decoder
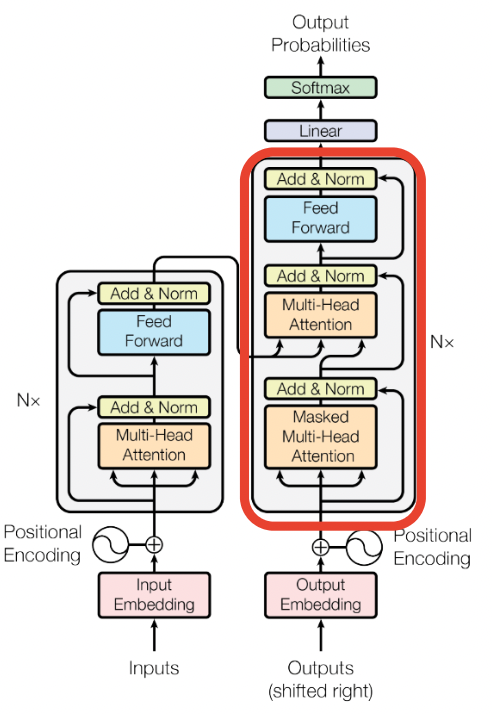
-
출력 문장에 대해 임베딩하고 포지셔널 인코딩한 후 Masked Multi-Head Attention 수행하여 Query 만들어냄. 추가적으로 Residual + Norm 수행
-
인코더에서 나온 최종 벡터가 K, V 로 사용되어 Multi-Head Attention (Encoder-Decoder Attention) 수행. 추가적으로 Residual + Norm 수행. 여기서 Residual 덕에 디코더의 문장 정보를 지니게 됨.
→ 인코더의 정보와 디코더의 문장 정보를 잘 결합
-
마지막으로 Feed Forward 수행
Masked Self-Attention
- 출력 문장에서 이전 단어들에 대해서만 어텐션을 수행. 뒤에 단어들은 masked 가려버림.
- QK 하고 softmax 한 후 뒤에 해당되는 부분을 0 으로 만듦. 이후 row 별로 합이 1 이 되도록 다시 softmax
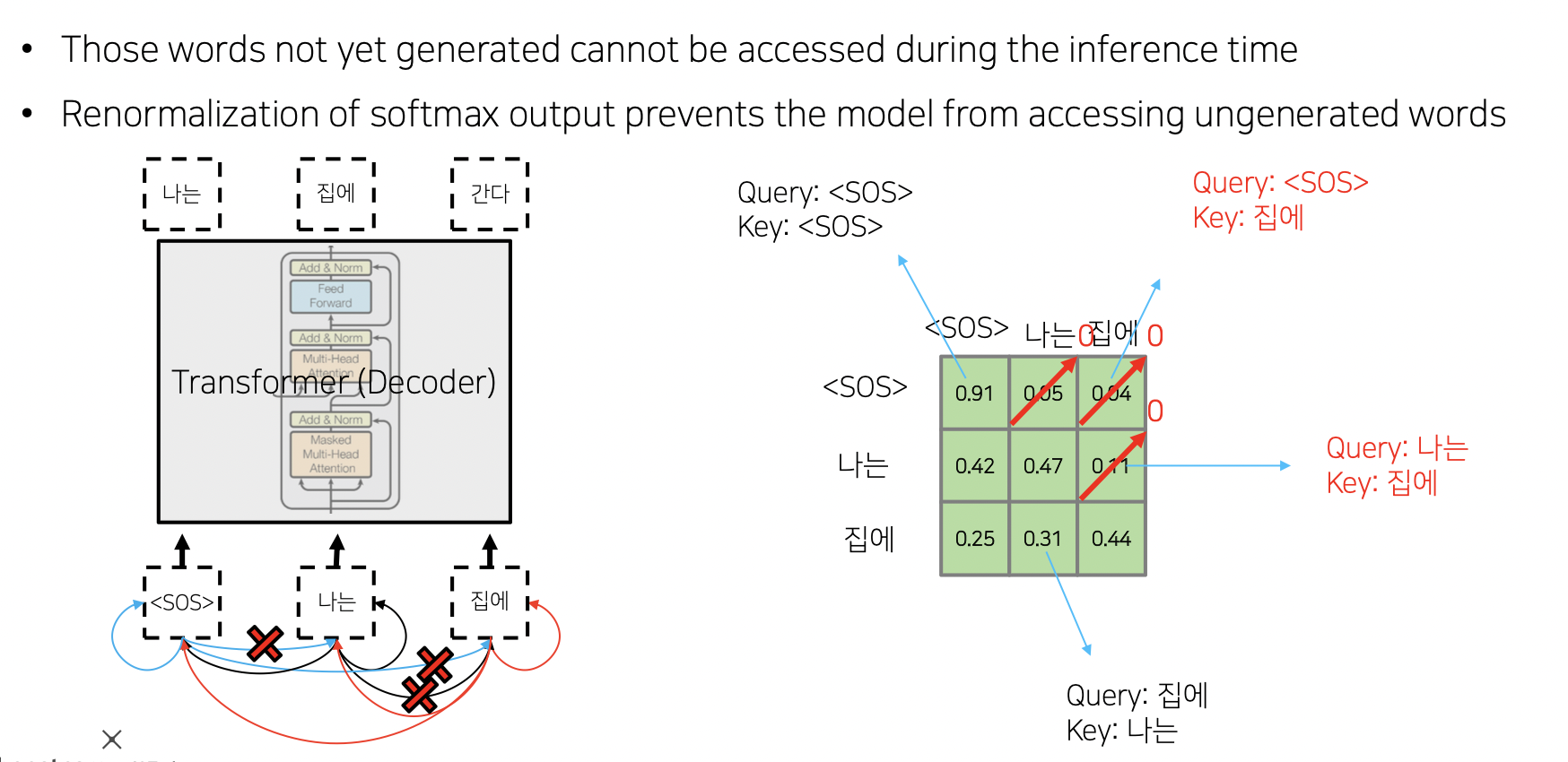
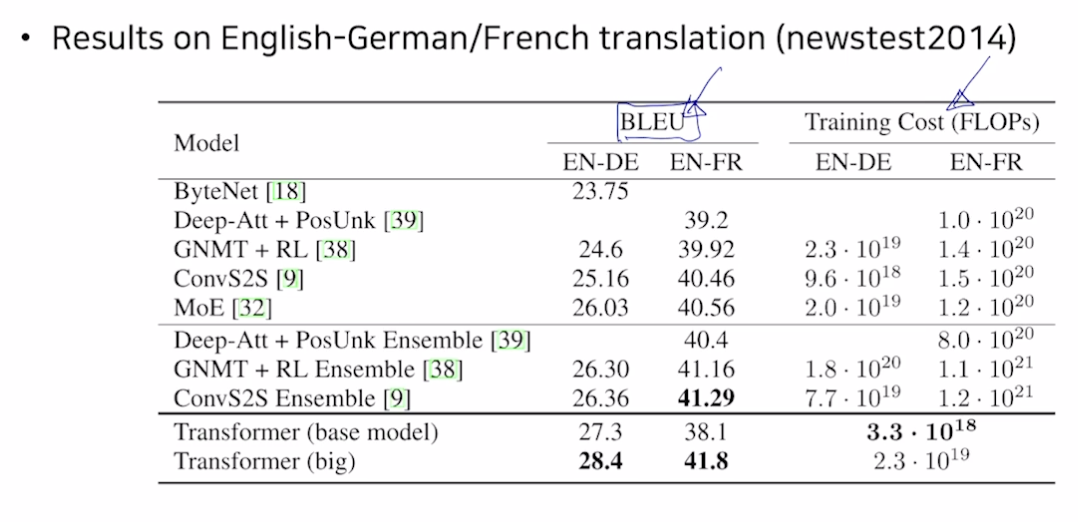
결과
Further Reading
- Attention is all you need, NeurIPS'17
- Illustrated Transformer
- Annotated Transformer
- Group Normalization
참조
BoostCamp AI Tech

데이터로 문제를 해결하는 엔지니어를 꿈꿉니다.