CNN 은 black box
CNN 에 입력 데이터를 넣으면 어떻게 수행되는지 파악하기 힘들다.
시각화를 통해 black box 를 들여다 봐서 어느 부분이 잘 안되는지 등을 파악하도록 하자.
Neural Network 시각화 유형들
학습된 모델의 특성 자체를 파악하려는 방법과 데이터를 통해 모델의 특성을 파악하려는 방법이 있다.

Analysis of model behaviors
학습된 모델의 특성 (레이어 등) 을 파악하는 방법들
Nearest neighbors in a feature space 방법
DB (일종의 공간) 에 이미지들이 저장되어 있고 query image 를 주면 특성이 비슷한 k 개의 이미지를 가져온다.

사진들의 특성을 고차원 공간에 넣어둔다.

비슷한 사진끼리 근처에 있게 된다.
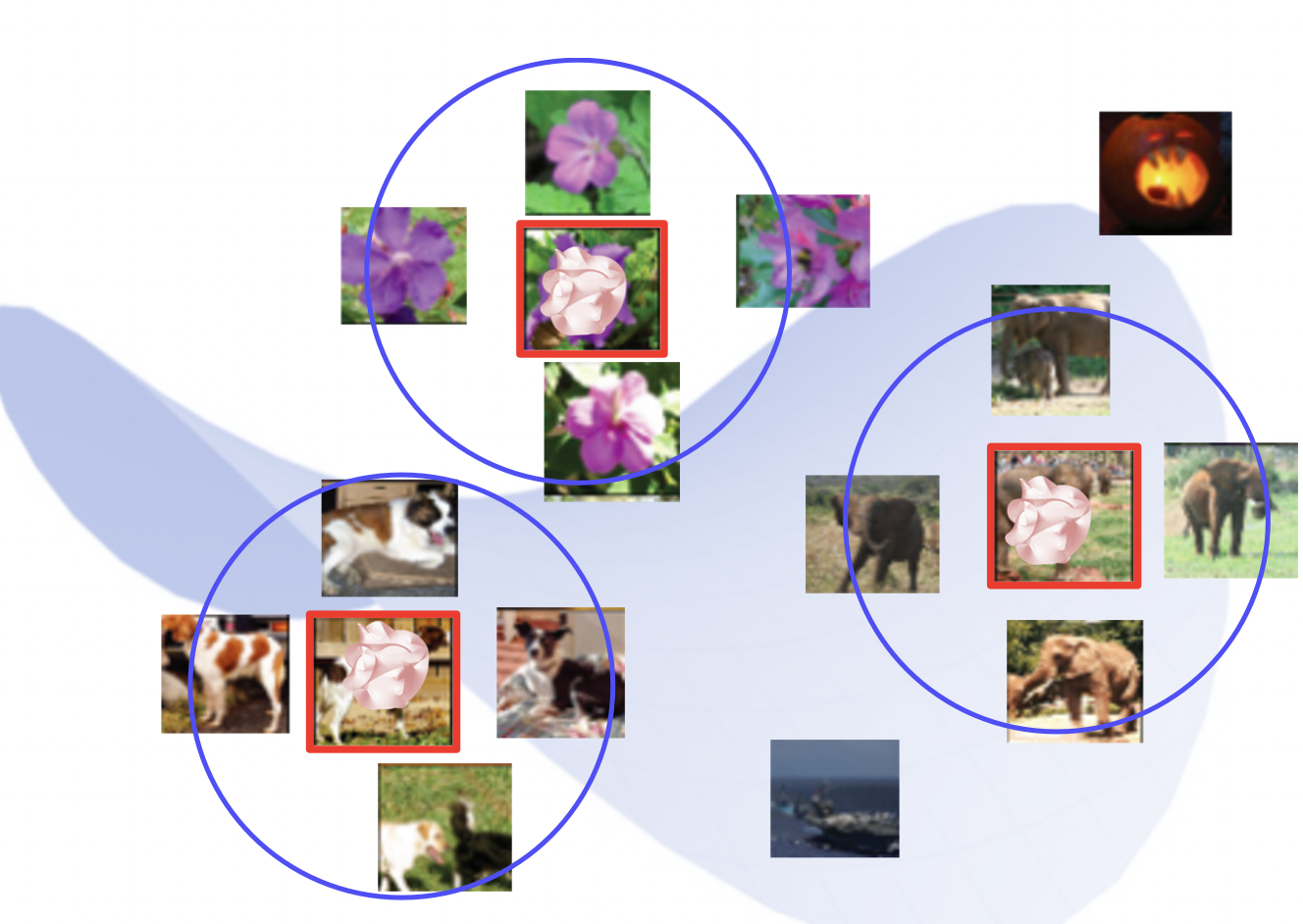
내가 원하는 사진을 넣었을 때 비슷한 사진이 나오는 일종의 검색과도 같다고 생각하면 된다.
전체적으로 잘 진행되고 있는지 등을 파악하기는 어렵다.
Dimensionality reduction 방법
backbone network 로 추출해낸 특징 벡터는 너무 고차원이라 큰 특징을 알기 힘들다.
따라서 저차원으로 내려서 (차원 축소) 특징들을 보기 좋게 시각화하자.
t-SNE 축소 방법
t-SNE 방법을 통해 아래와 같이 특징별로 데이터가 뭉쳐진 것을 확인할 수 있다.

Layer activation 방법
Mid to high level feature 분석 방법으로
어느 레벨의 특정 레이어가 어떤 역할을 하는지 알 수 있다.
High activation mask visuallization 을 사용한다.

Maximally activation patches 방법
패치를 뜯어내어 해당 히든 노드는 어떤 역할을 하는지 찾아낸다.
- 분석하고자 하는 특정 레이어를 정한다.
- 예제 데이터를 백본 네트워크에 넣어서 각 레이어의 액티베이션을 뽑아내고 보고 싶은 채널을 저장한다.
- 저장된 채널의 가장 큰 값을 갖는 위치를 파악하고 리셉티브 필드를 뜯어와서 그 히든 레이어가 어떤 것을 보는지 살펴본다.

Class Visuallization 방법
예제 데이터를 사용하지 않고 Gradient ascent 를 통해 해당 클래스에 어떤 이미지가 내재되는지 알 수 있다.

Gradient ascent 수행
해당 클래스에 내재되는 이미지를 알기 위해 아무 입력을 넣는다.
출력과 클래스를 loss 로 만들어 최적화를 수행하여 내재되는 이미지를 얻어낸다.
CNN 모델 f 를 거친 어떤 클래스에 관한 스코어를 최대화 (ascent) 하는 I (입력) 를 찾는 알고리즘이다.
찾은 I 가 영상이 아닐 수 있기 때문에 (너무 큰 값을 가져서 해석이 안되는데 강아지로 판단할 수 도 있음) 정규화식 (L-2 norm) 을 추가하였다.
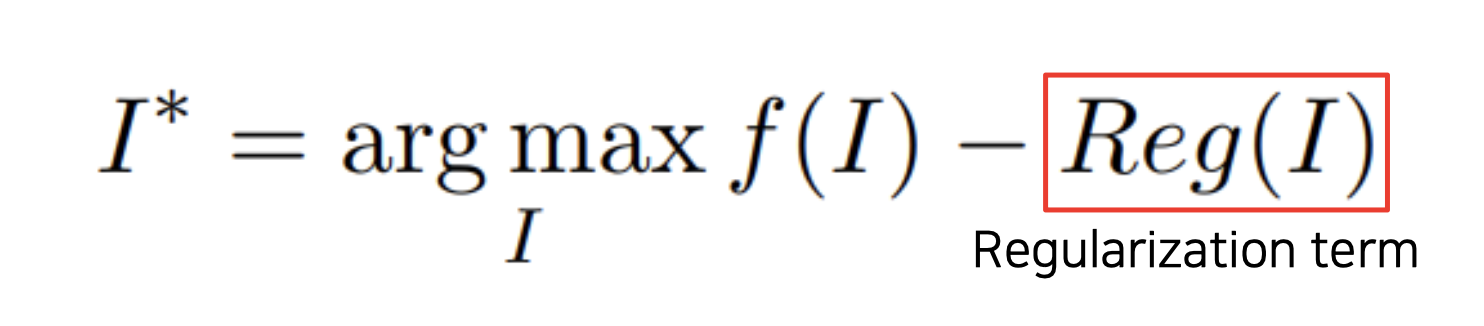
Model Decision Explanation
모델에 데이터를 넣어서 어떤 결과가 나오는지를 파악하는 방법들
Saliency test
Occlusion map 방법
사진에 occlusion (방해하는 이미지) 을 넣고 올바르게 분류할 확률을 구한다.
어떤 위치를 가리냐에 따라 점수가 크게 달라지는데 어떤 부분이 해당 클래스를 찾는데 중요한지 파악할 수 있게 된다.
점수가 낮은 부분이 중요한 부분이다.
각 부분을 모두 가렸을 때 점수를 기록한 것이 Occlusion map 이다.

Backpropagation 방법
Gradient ascent 처럼 최적화를 이용한 방법이다.
입력 이미지를 넣고 원하는 클래스와 관련된 부분에 대한 클래스 스코어를 구한다.
이를 통해 입력 이미지와 해당 클래스의 관계되는 부분을 파악할 수 있다.
점수가 클 수록 하얀 점이 나타난다.

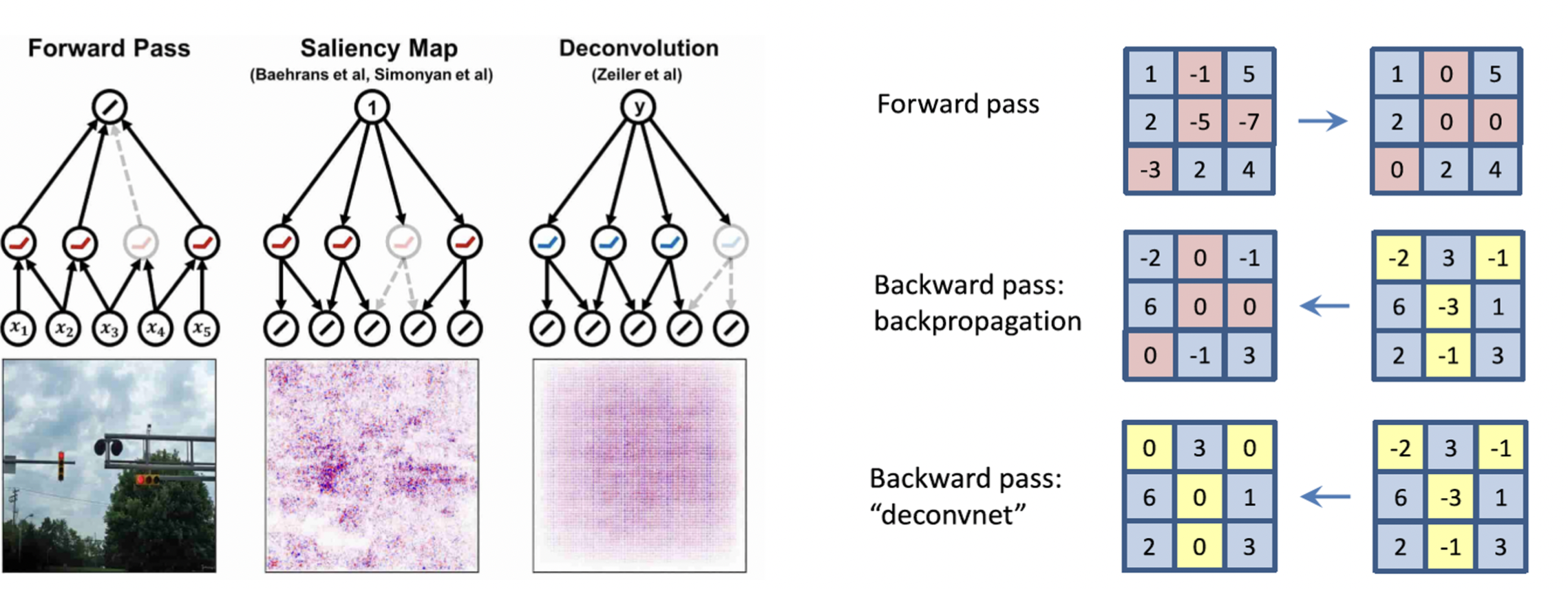
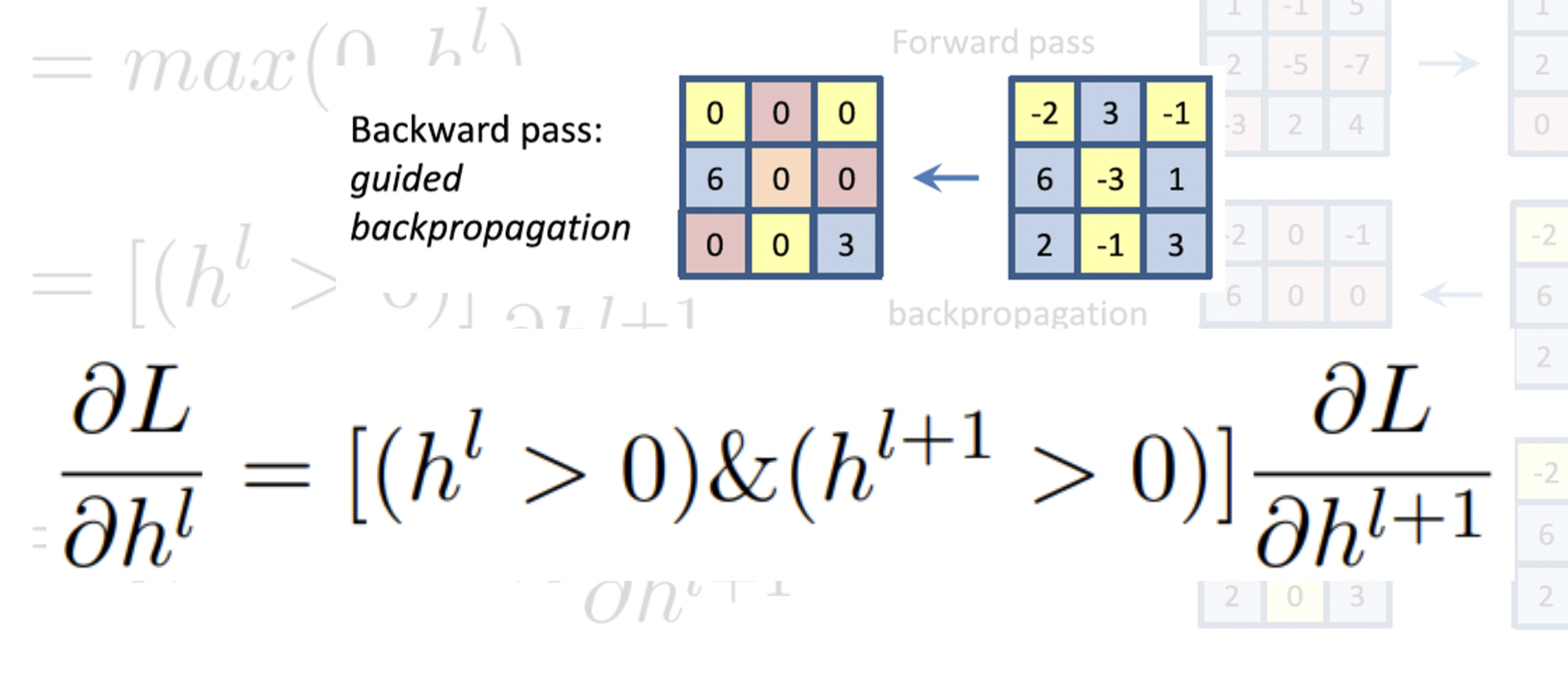
Rectified unit (backward pass) 수행
Backpropagation 의 구체적인 과정이다.
ReLU 를 사용하여 순전파에서 -인 부분을 날리고, 역전파에서도 -인 부분을 날려서
서로 겹치는 부분에 대해 활성화를 한다.
결과
고양이 이미지를 줬을 때 눈, 귀와 얼굴 쪽을 주로 봤다는 것을 알 수 있다.

Class Activation Map (CAM) 방법
이미지의 어떤 부분이 해당 이미지를 판단하는 근거가 되는지 보여준다.
위치에 대한 정보를 주지 않았는데 위치 태스크도 수행하는 기특한 방법이다.

FC layer 대신 GAP (Global Average Pooling) 을 사용한다.
GAP 을 원하는 클래스에 대한 FC 로 학습시키면서 해당되는 부분을 활성화시킨다.
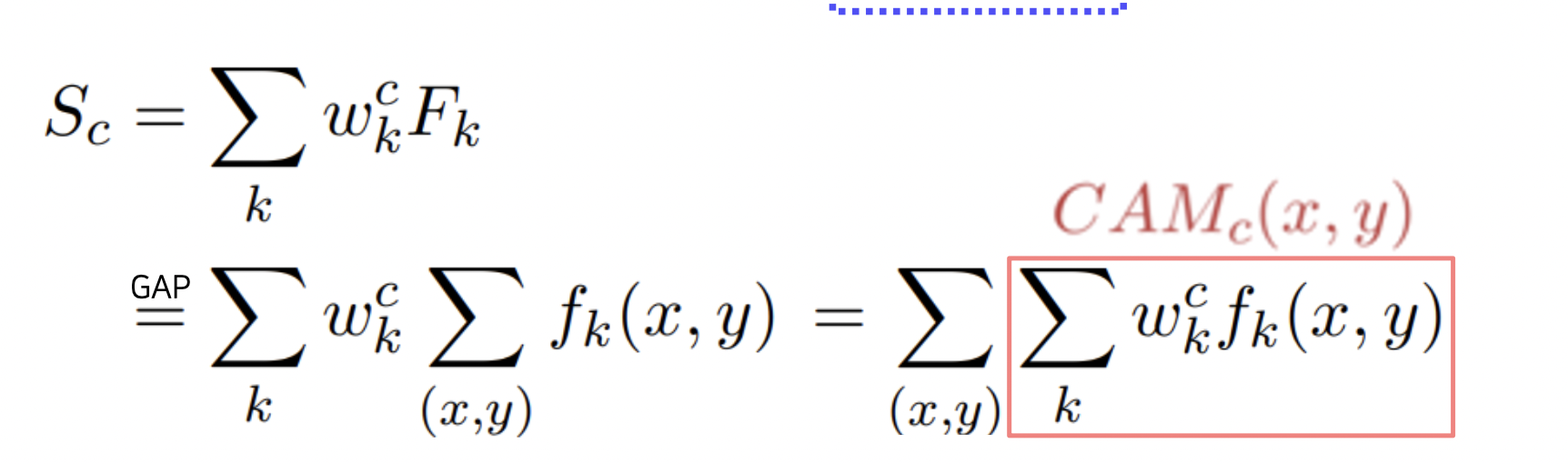

마지막 부분이 GAP 과 FC 레이어로 이루어져야 하므로 바꾼 상태에서 재학습을 해야한다.
ResNet 과 GoogLeNet 은 이미 GAP 이 존재해서 마지막 FC 를 떼고 원하는 클래스에 맞게 FC 를 넣어 학습하면 된다.
반면, AlexNet 은 GAP 이 없는데 GAP 을 넣고 학습하면 오히려 성능이 안 좋아질 수 있어서 사용하지 않는다.
Grad-CAM 방법

수식 개선을 통해 CAM 을 직접 만들지 않고도 CAM 역할을 할 수 있게 만들었다.
AlexNet 등에서도 구조 변경을 하지 않아도 된다.
GAP 을 붙이고 학습하여 얻은 웨이트 대신 기학습된 모델의 weight 를 가져와서 CAM 을 만든다.

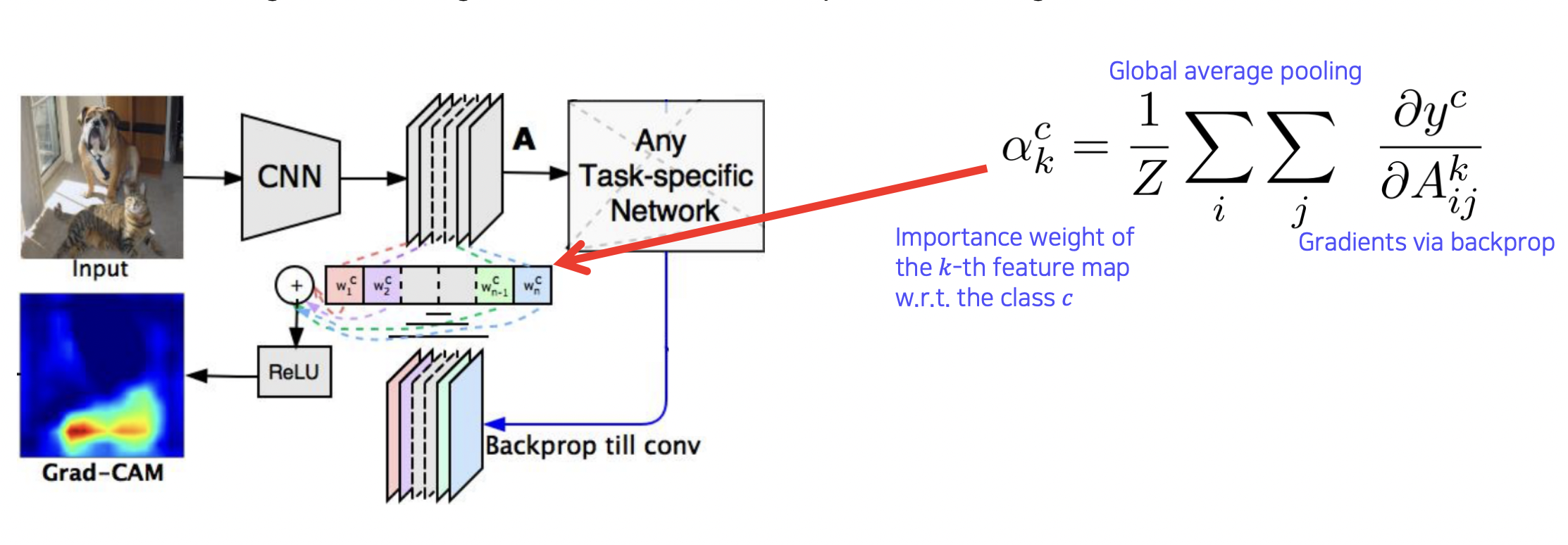
ReLu 를 통해 positive effect 에만 집중시킨다.
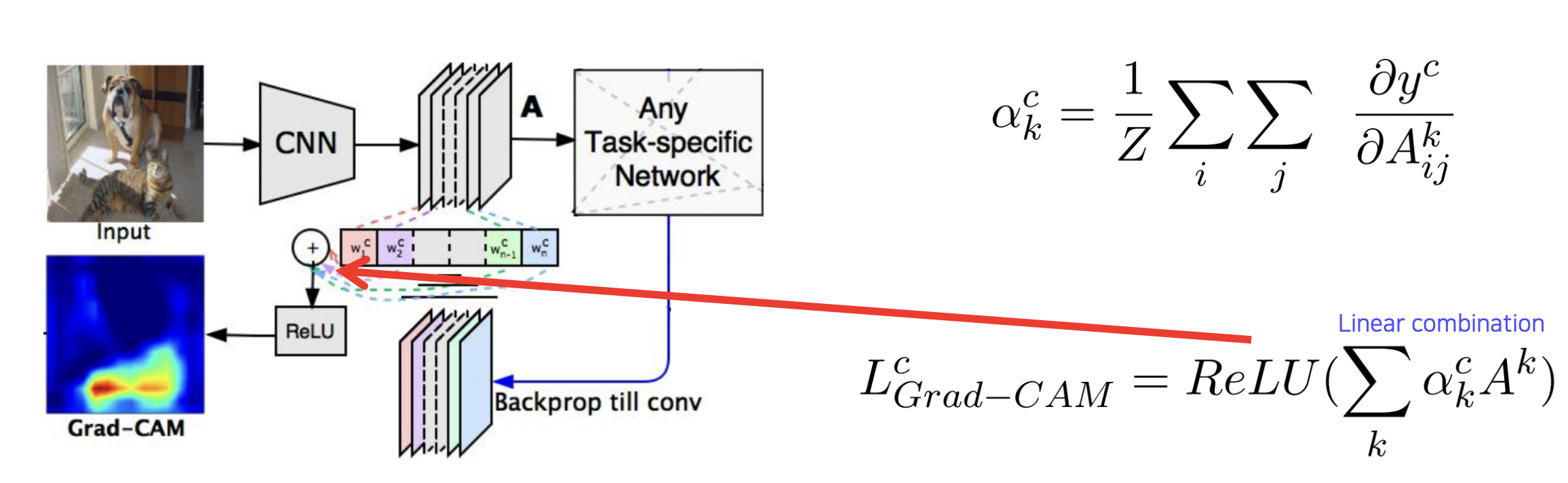
Guided Backprop 과 함께 사용하기도 한다.
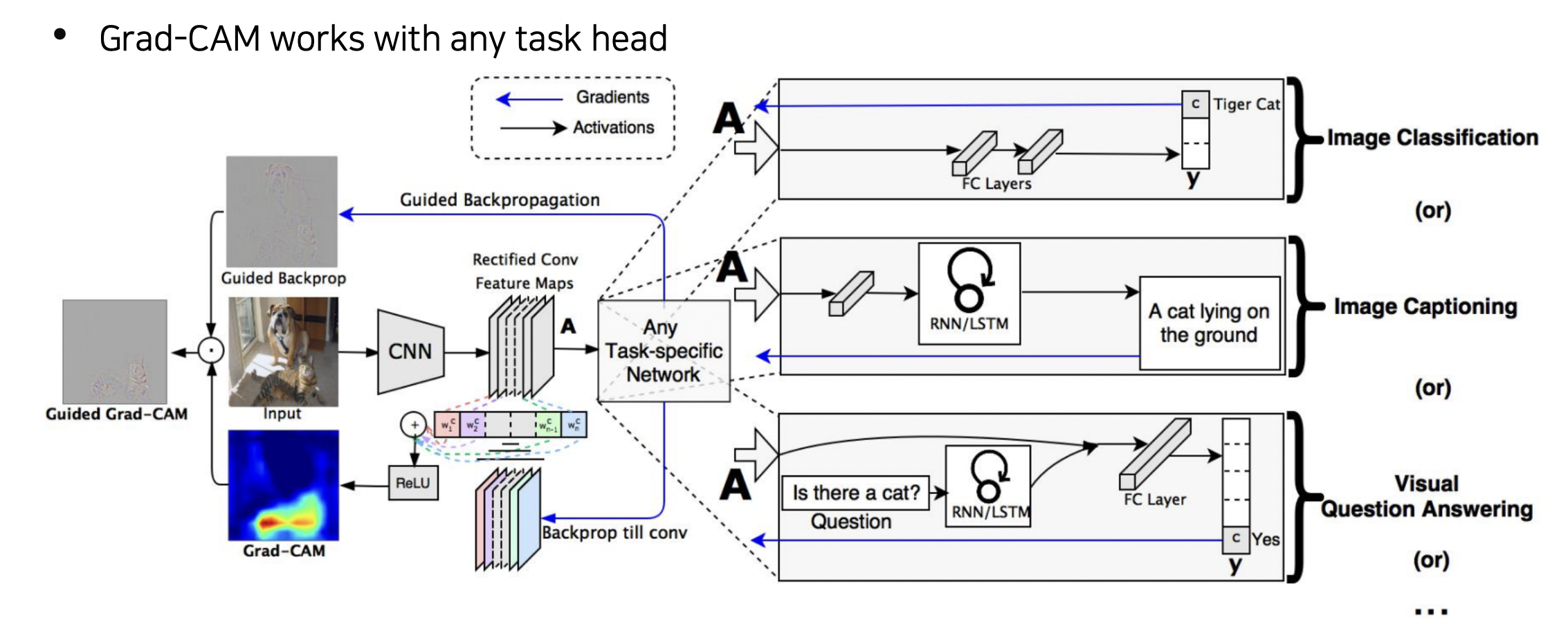
결과

SCOUTER
왜 해당 클래스라고 판단했는지, 왜 아니라고 판단했는지를 알 수 있다.

참조
BoostCamp AI Tech
