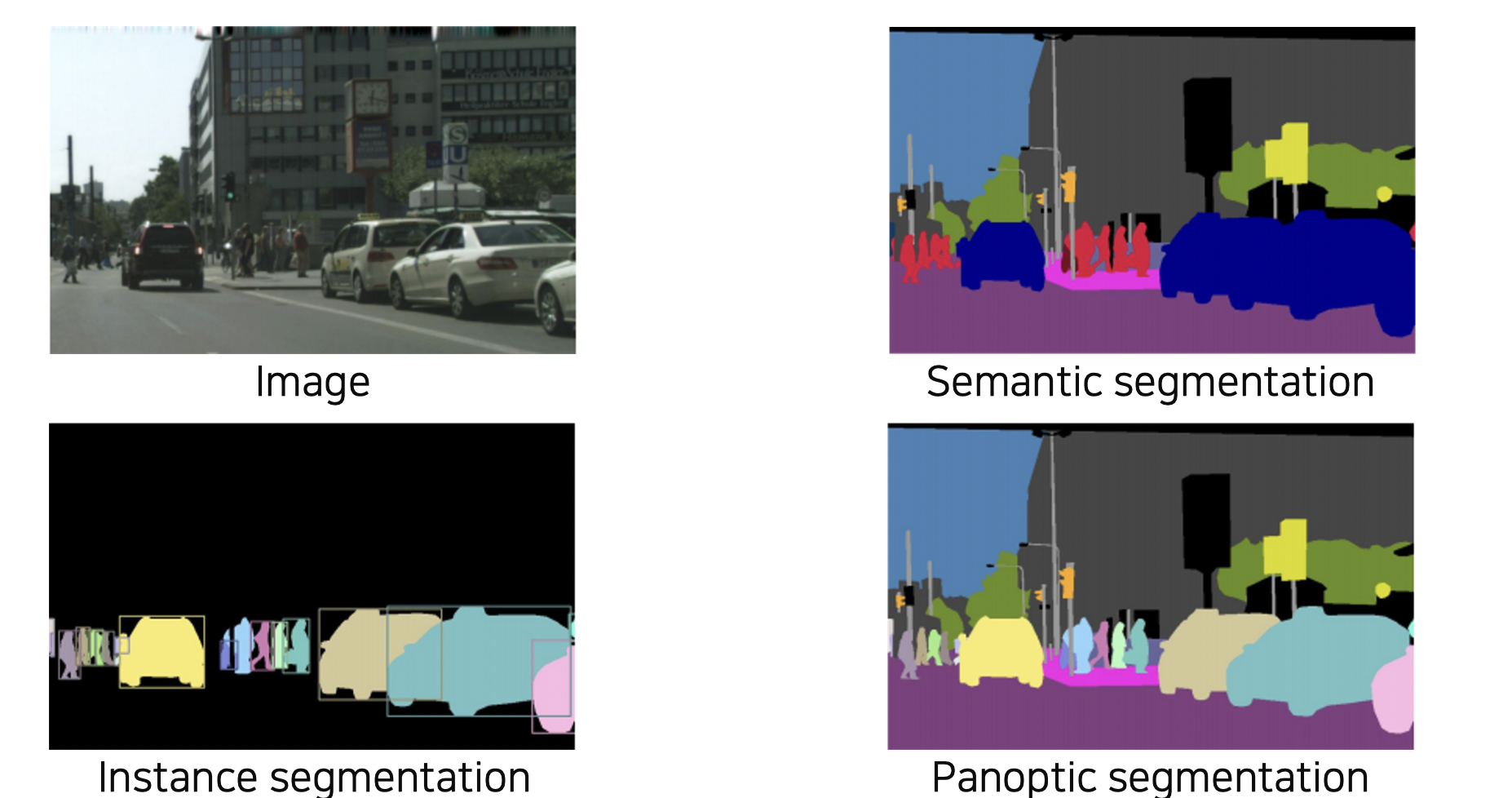
Object Detection 이란?
Sementic segmentation 에서 Instance segmentation 과 Panoptic segmentation 으로 가려면 각 Object Detection 이 가능해야 한다.
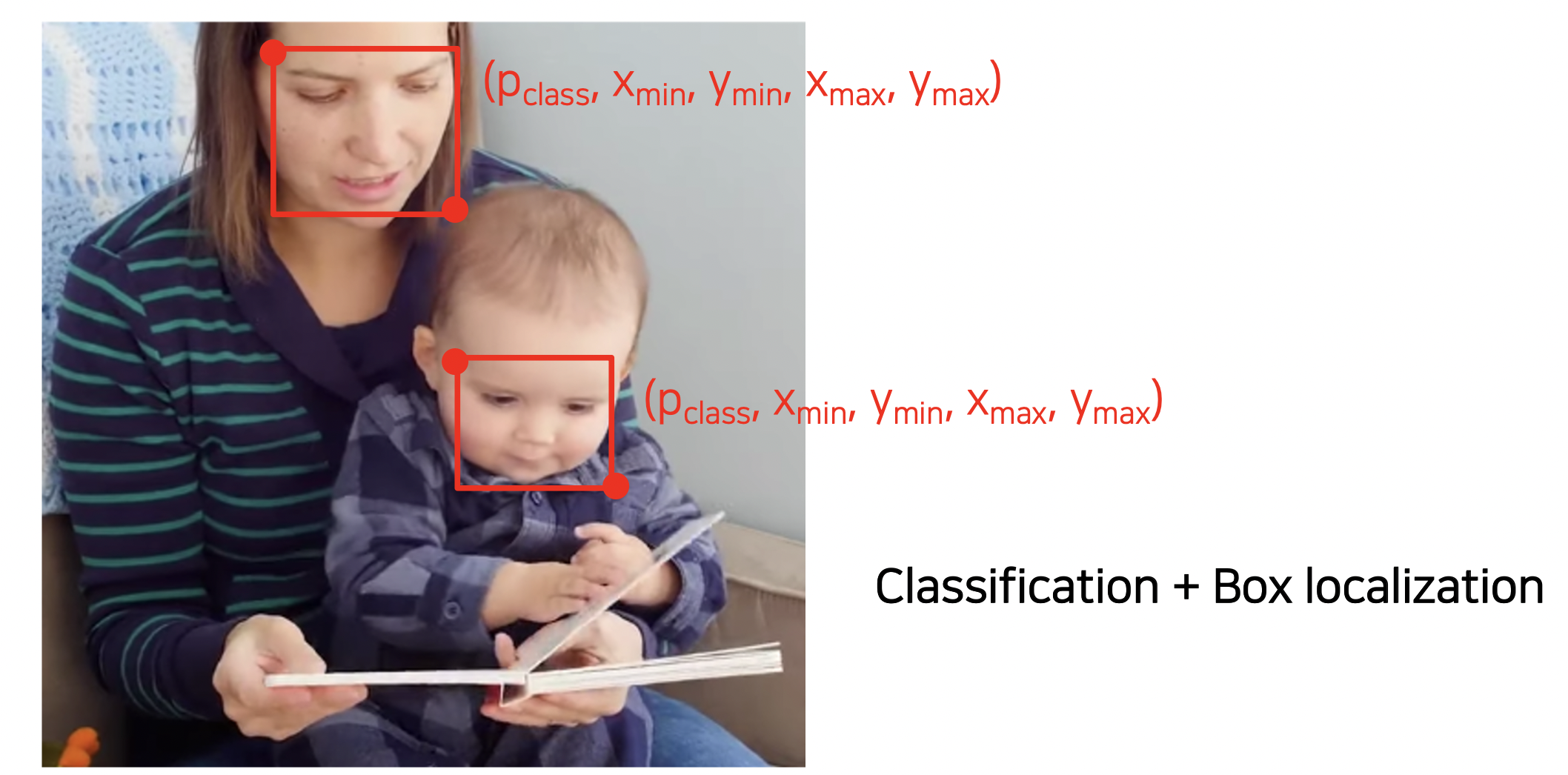
Object Detection 은 Classification + Box localization 을 필요로 한다.
물체라 판단되는 부분에 박스를 치고 그 부분이 물체인지 아닌지 판별한다.
응용
- 자율주행
- OCR
Two-stage detector (R-CNN family)
박스를 만드는 일과 박스가 물체인지 판별하는 일을 따로 수행하기 때문에 two-stage 이다.
Traditional methods - hand-crafted techniques
딥러닝으로 학습하지 않는 일반적인 방법들을 말한다.
주로 영상의 경계 (gradient) 를 기반으로 detection 을 수행한다.
Histogram of Oriented Gradients 와 Support Vector Machine 등을 사용한다.

Selective search 방법
- 먼저 영상을 비슷한 색끼리 잘게 분할한다. (Over-segmentation)
- 분할된 것들을 비슷한 특징 (색, 기울기 분포 등) 으로 반복해서 합쳐나간다. (Iteratively merging similar regions)
- 만들어진 박스 후보들을 추출해낸다.

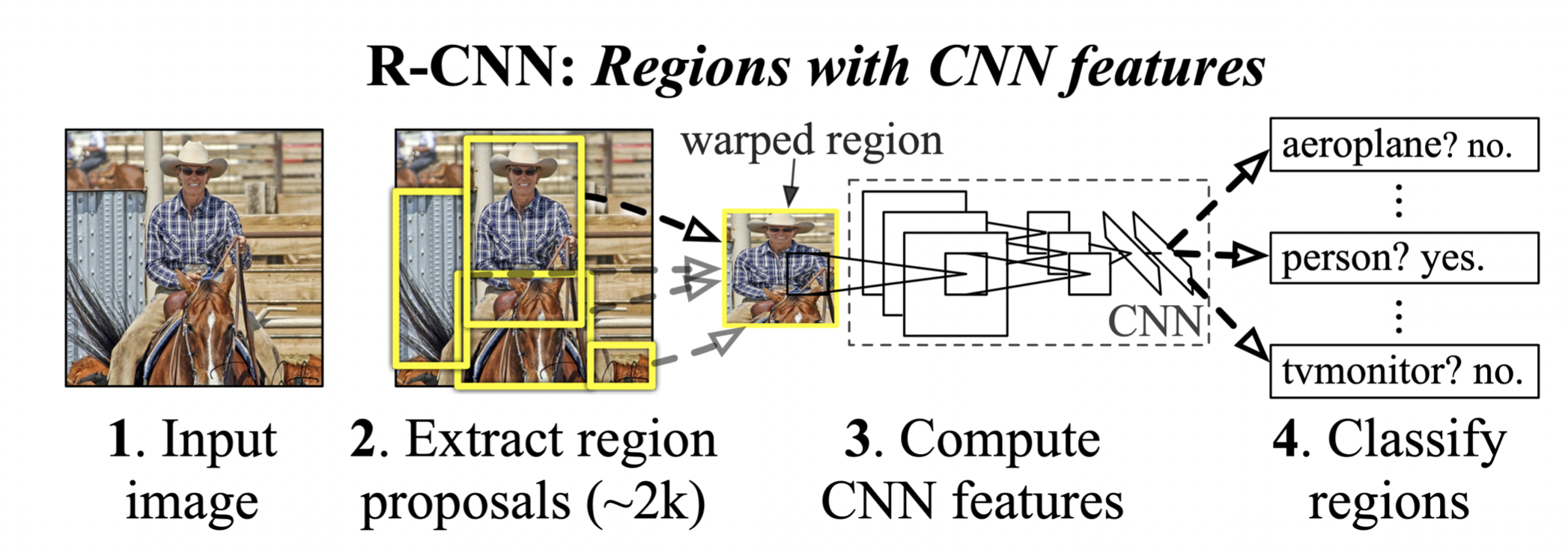
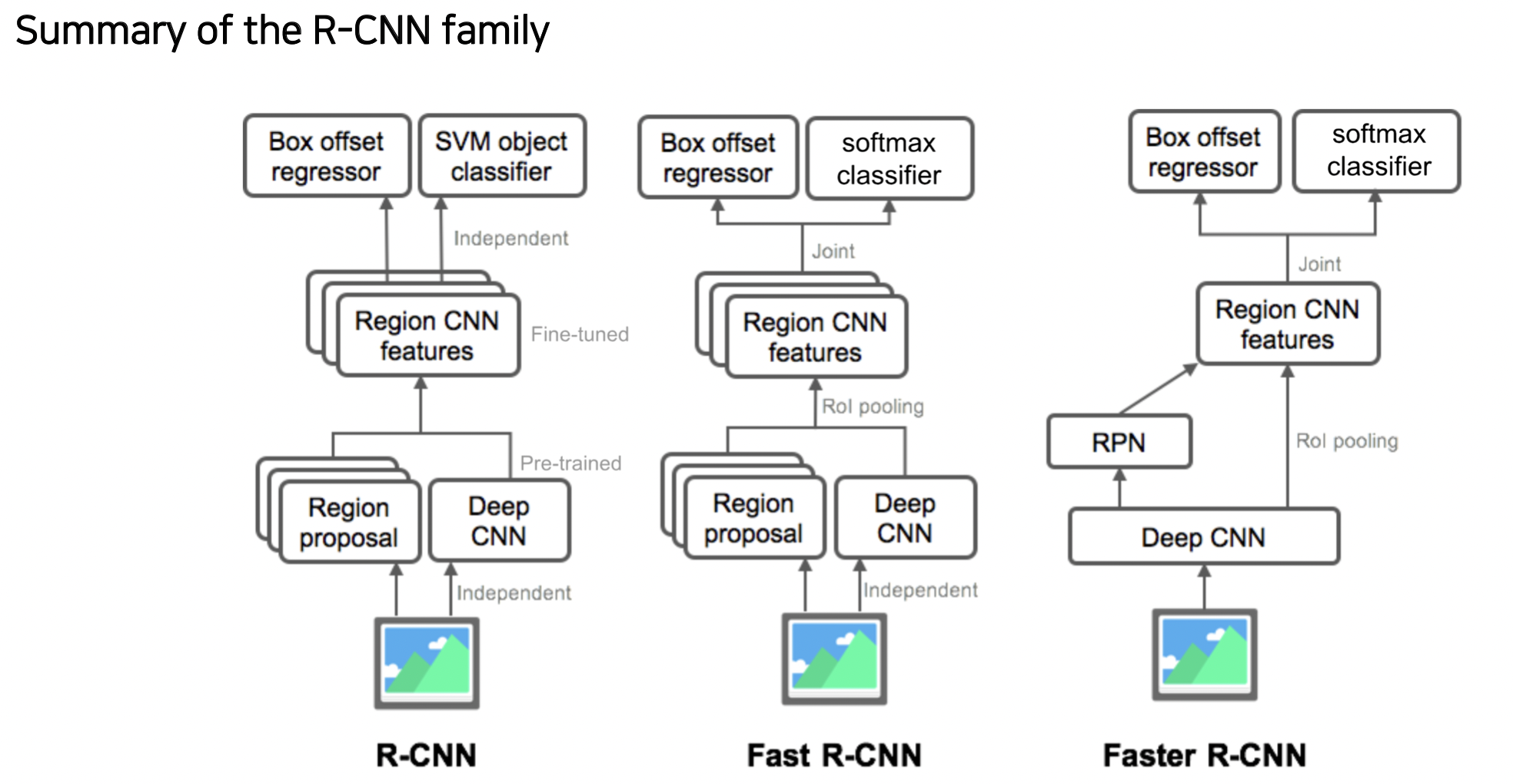
R-CNN 계열
R-CNN (Regions with CNN features)
- 입력된 이미지에서 객체에 대한 지역을 검출한다. (Selective search 같은 알고리즘 사용)
- 각 객체를 CNN 을 통해 클래스 분류를 한다.
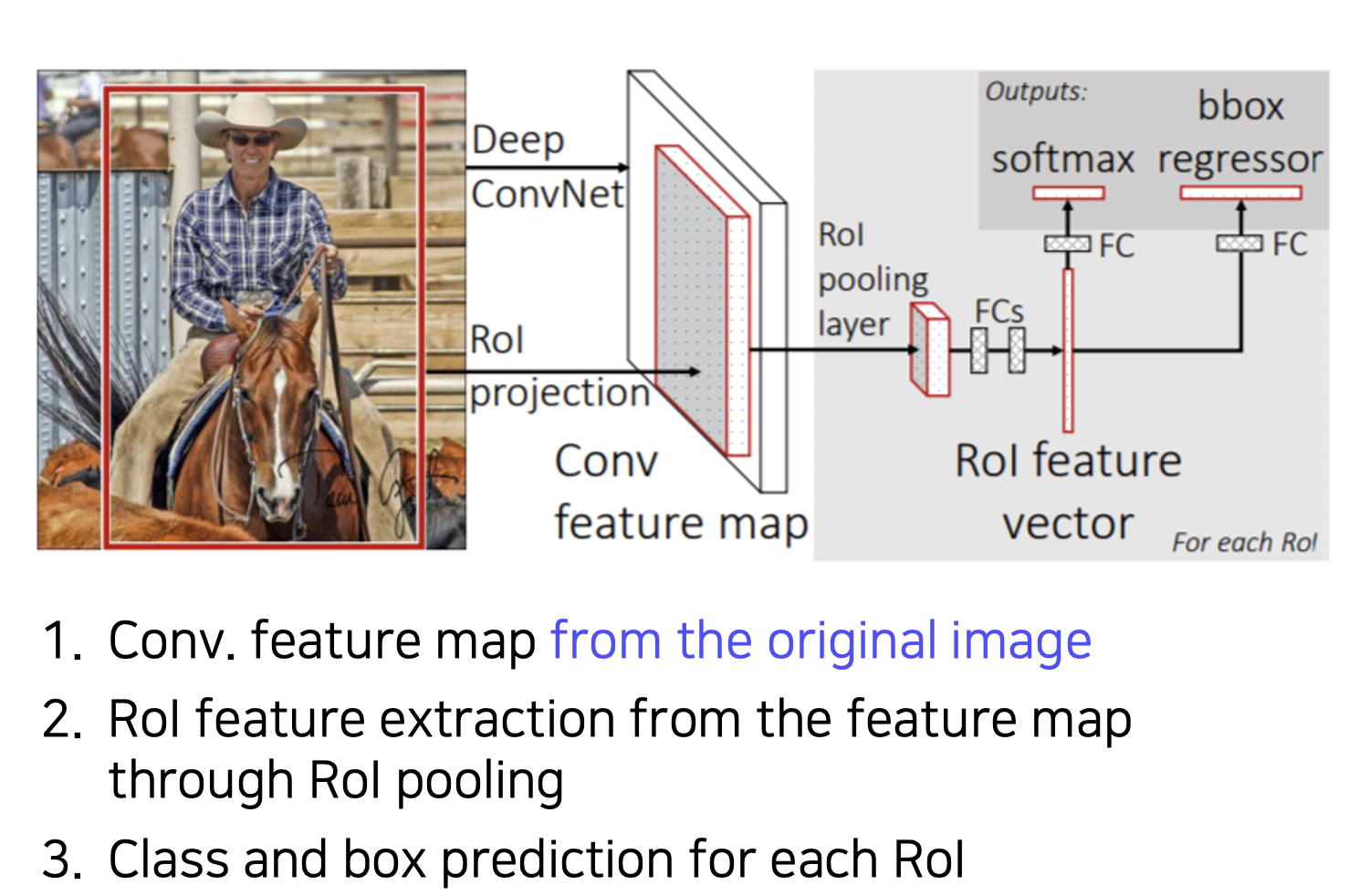
Fast R-CNN
영상 전체에 대한 feature 를 한 번에 추출하고 (한 번의 CNN) 이를 재활용하여 시간을 줄인다.
RoI (Region of Interest) 를 사용한다.
- FCN 을 통해 이미지의 feature 를 얻는다.
- 얻은 feature 를 재활용하기 위해 RoI pooling 을 사용한다. RoI projection 을 거치면 물체의 후보 위치 (RoI pooling layer) 들을 얻는다.
- FC 레이어를 통해 각 RoI 를 분류하고 물체가 맞는지 체크한다.
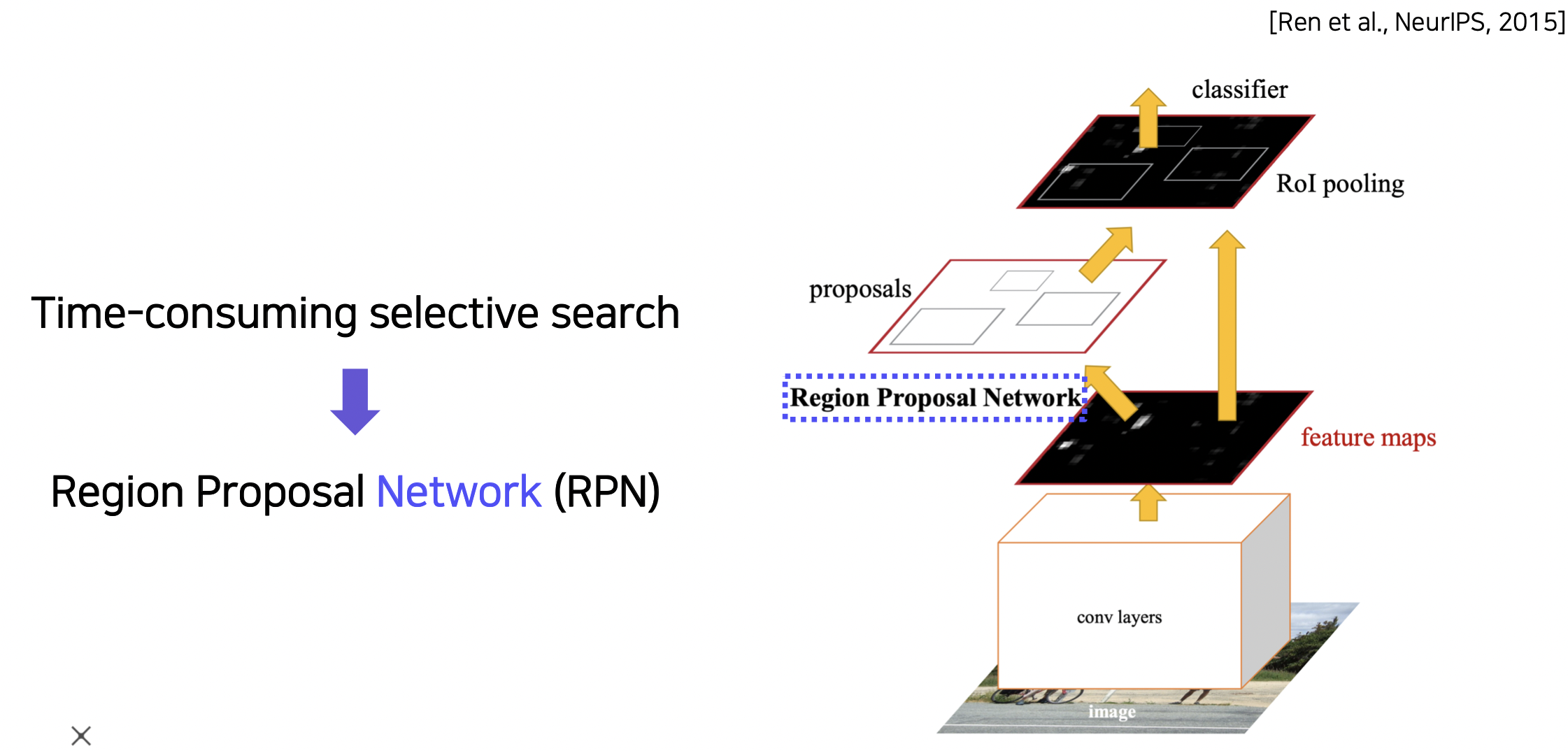
Faster R-CNN
Region proposal (박스 생성) 부분도 neural network 로 만든 End-to-End 모델이다.
Selective search 같은 방법 대신 학습 가능한 RPN (Region Proposal Network) 을 통해 지역을 검출한다.
IoU (Intersection over Union)
두 영역의 겹치는 부분을 측정하는 방법이다.

이 수치가 높을 수록 객체 탐지를 잘하고 있음을 알 수 있다.
Region proposal
이미지의 각 위치에 대해 Anchor box 를 통해 해당 위치가 박싱돼야하는지 알 수 있다.
Faster R-CNN 에서는 9 개의 박스를 사용했다.

각 박스에 대해 탐지를 하며, 해당 박스와 물체 간의 IoU 가 0.7 을 넘으면 positive samples, 0.3 이하면 negative samples 로 두어 loss 를 구하고 업데이트한다.
슬라이딩 윈도우 형식으로 한 점에 대해 각 박스를 대입하며 탐색한다.

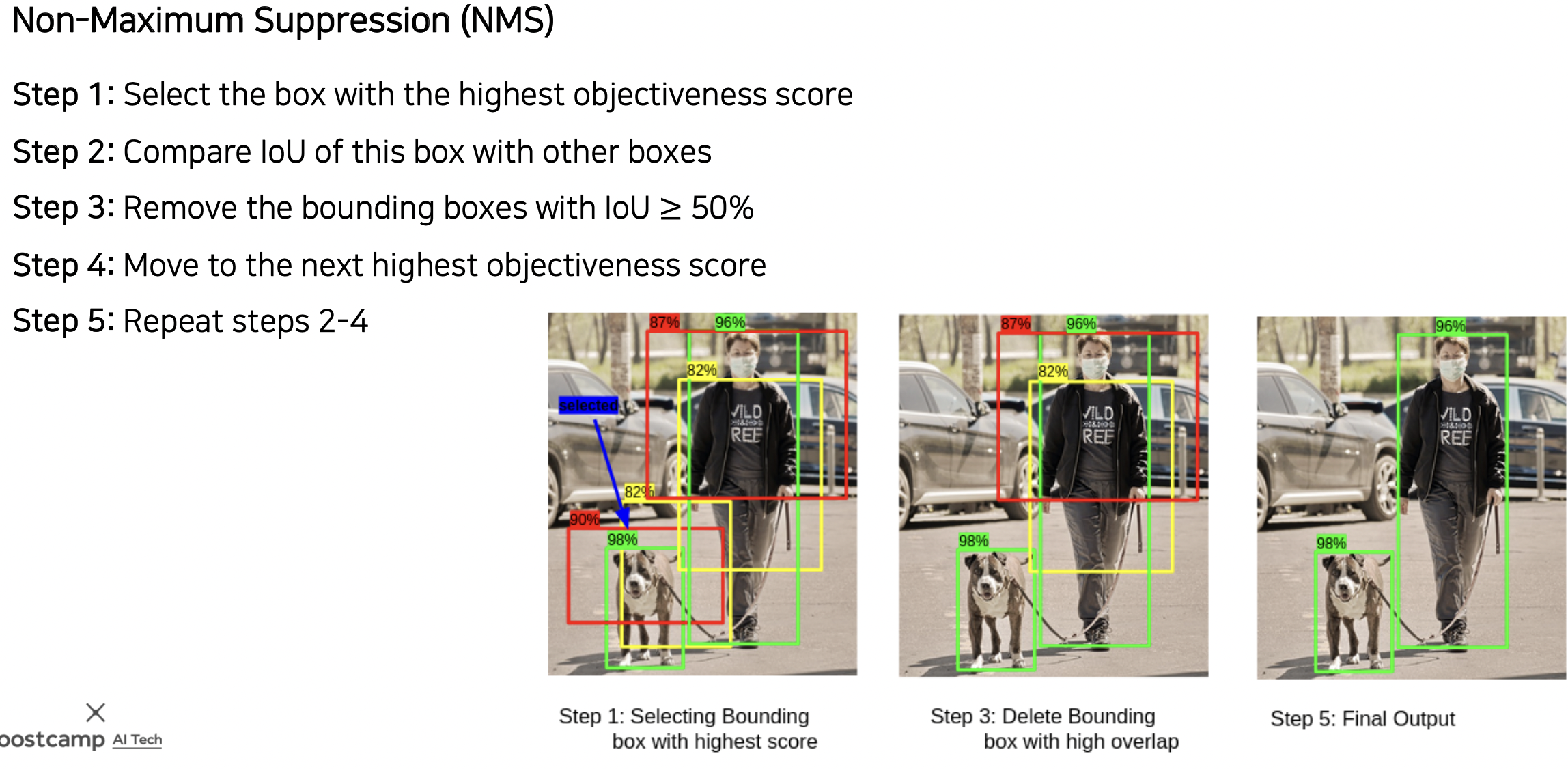
많은 박스들이 생기는데 Non-Maximum Suppression (NMS) 를 통해 가장 최적의 박스만 남긴다.
정리
Single-stage detector
Two-stage 와 다르게 RoI pooling 과 관련된 부분이 없고 박싱과 객체 분류를 동시에 수행한다.
정확도를 포기하더라도 속도를 올려서 실시간 detection 이 가능하도록 만드는게 주 목적이다.
YOLO (You Only Look Once)
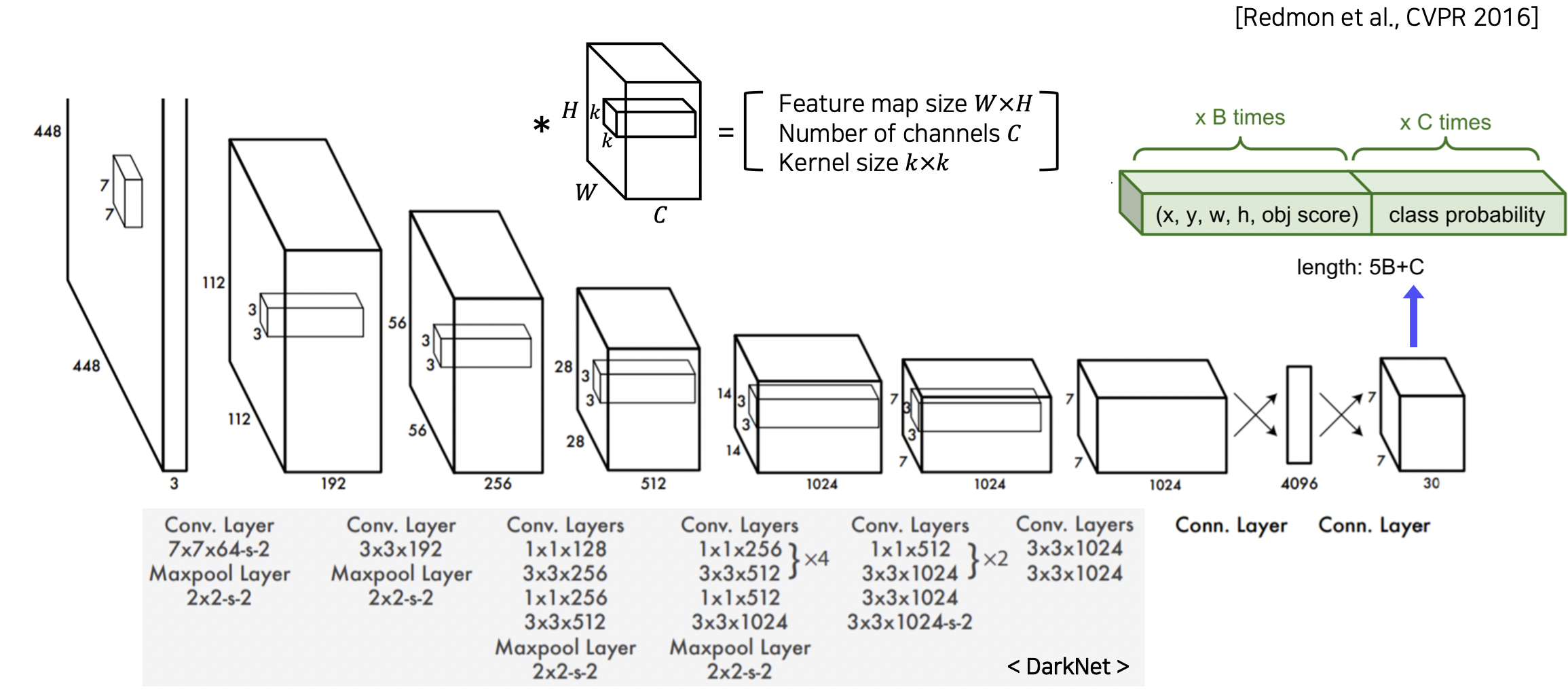
SxS 그리드로 이미지를 나누고 바운딩 박스를 잡아내는 알고리즘과 각 부분의 분류를 맡는 알고리즘을 동시에 진행한다.

구조가 일반 CNN 과 매우 유사하다.
마지막에 B 는 2, C 는 20 이라 총 30 채널 사이즈가 된다.
S 는 마지막 레이어의 해상도로 결정된다.
실시간 탐지에 있어 좋은 성능을 보인다.
SSD (Single Shot multibox Detector)
적절한 바운딩 박스를 출력할 수 있도록 멀티스케일 구조로 만들었다.
각 피쳐맵마다 적절한 바운딩 박스 크기를 예측 가능하다.
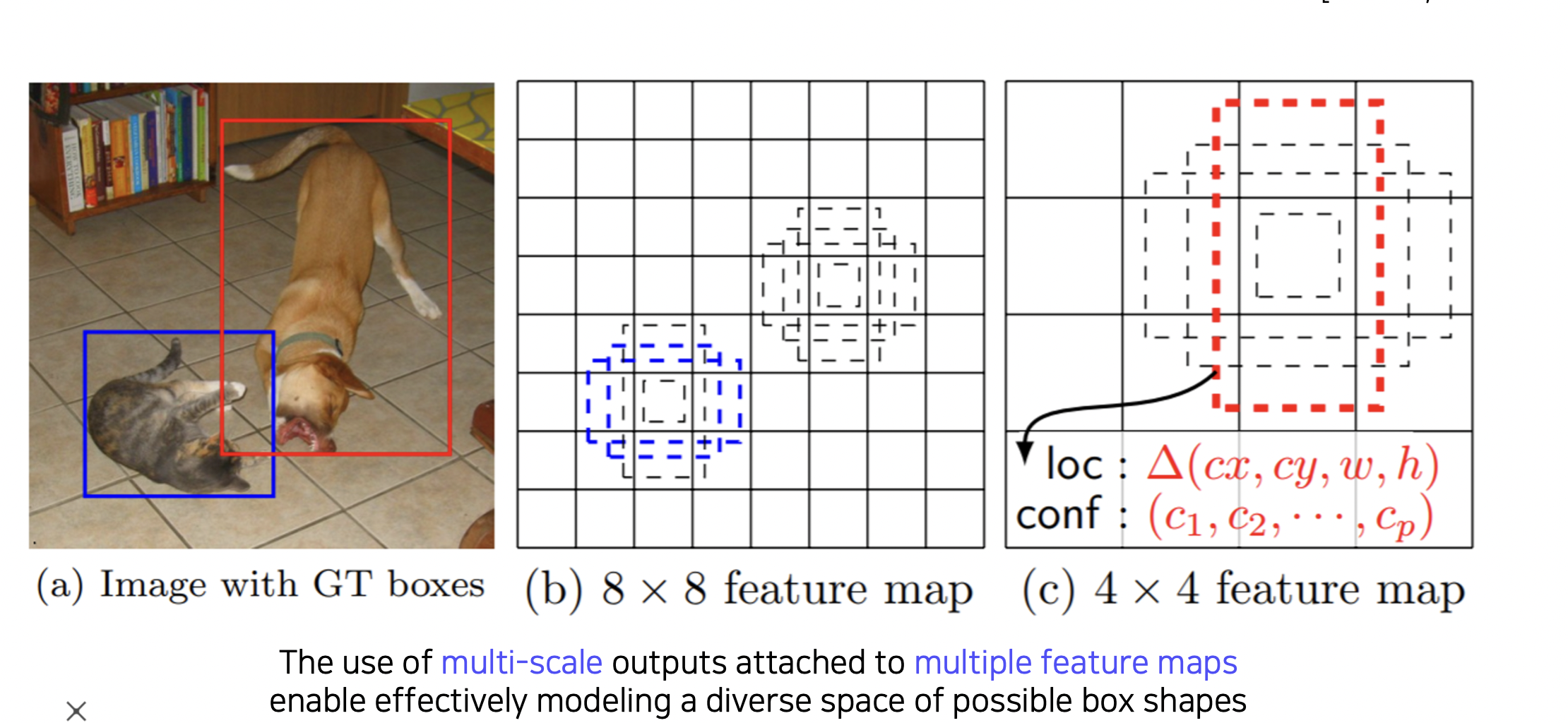
아래와 같이 멀티 스케일로 다양한 스케일 오브젝트를 통해 더 잘 예측한다.
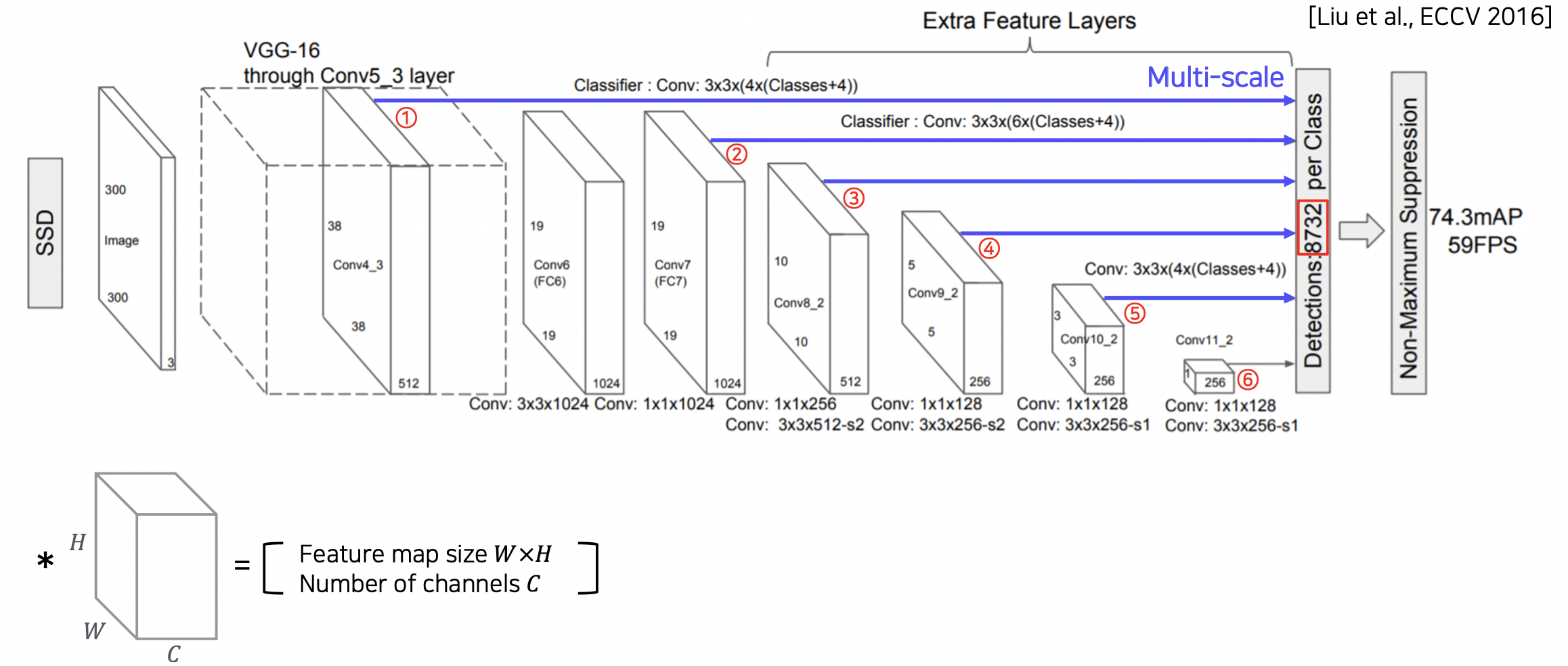
YOLO 보다 성능이 좋다.
Single-stage detector vs. Two-stage detector
Focal loss
싱글 스테이지 디텍터는 RoI 풀링이 없어서 모든 영역에서 loss 가 계산되고, gradient 가 일정해지는 문제가 있다.
Class imbalance 문제
일반적인 영상은 배경이 더 넓고 실제 물체는 일부분인데 배경 부분에서 많은 박스를 잡아먹는 (계산량 증가) 문제를 말한다.
Focal loss 로 위 문제를 해결할 수 있다.
물체 부분은 로스를 더 낮게 만들고 배경 부분은 로스가 잘 안바뀌어 많은 배경에 대해 로스가 잘 수정되지 않는다.
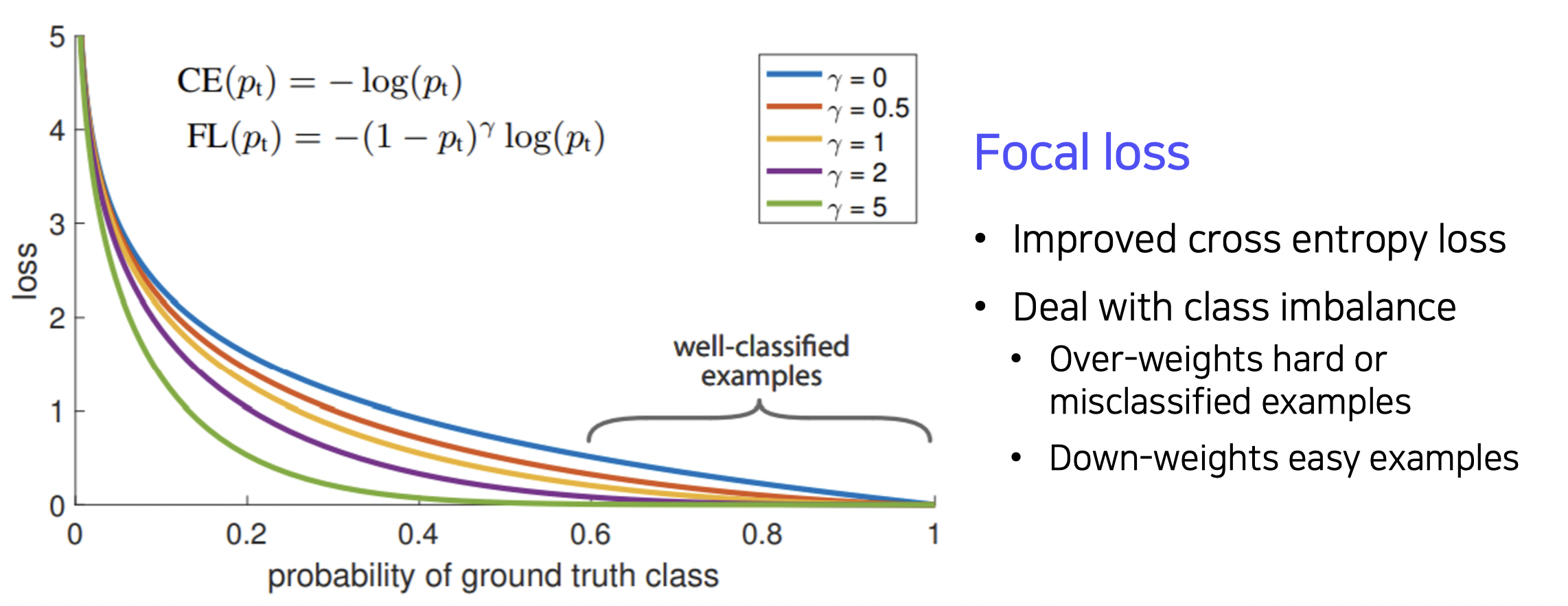
RetinaNet
U-net 과 비슷한 모델 구조를 지녔다.
low-level 과 high-level 특성을 잘 지닌다.
단, concat 이 아닌 + 를 수행한다.
one-stage network 의 일종이다.

Detection with Transformer
NLP 영역에서 성공을 거둔 트랜스포머를 CV 영역에 적용하였다.
DETR
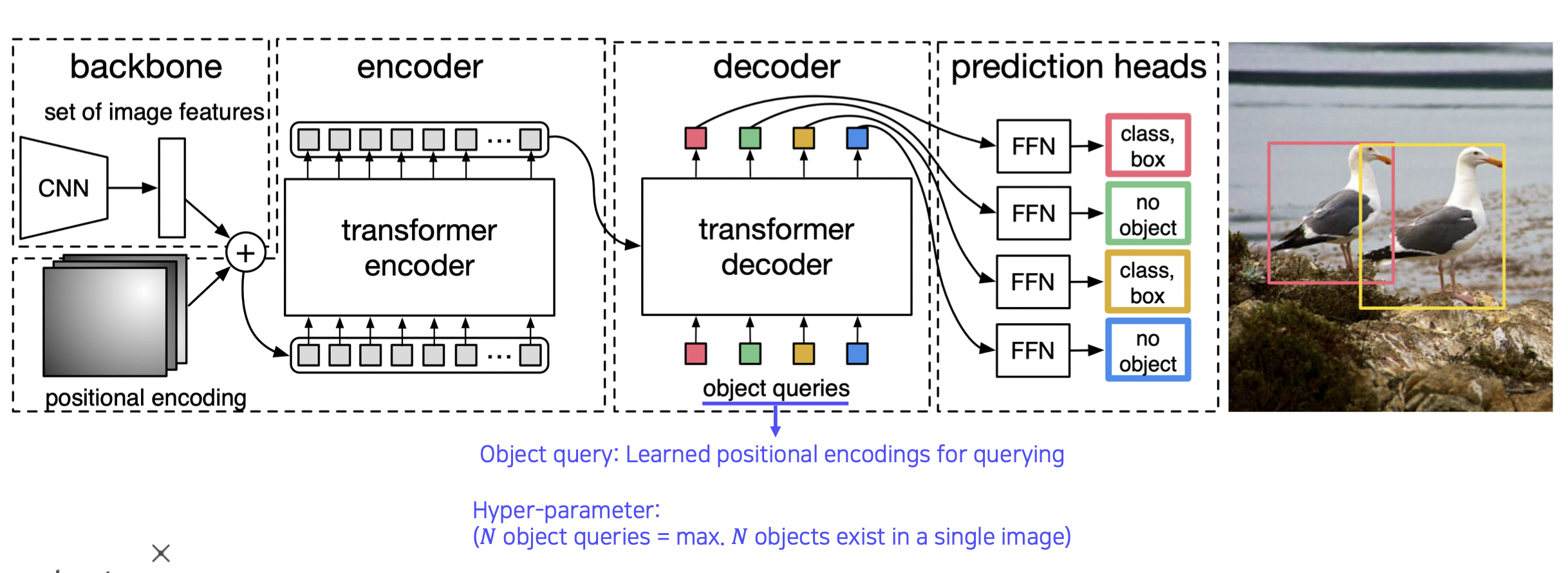
CNN 을 통해 나온 feature map 과 위치에 대한 정보를 더하여 인코딩한다.
그리고 이를 트랜스포머 인코더에 넣어 서로 관계를 파악한다.
이후 object query (학습된 포지셔널 인코딩) 를 디코더에 넣어서 해당 위치에 해당되는 물체가 무엇인지 알아낸다.
또 다른 트렌드
박스로 표현하지 말고 물체의 중심점을 파악하자.

참조
BoostCamp AI Tech
