Instance Segmentation
개념
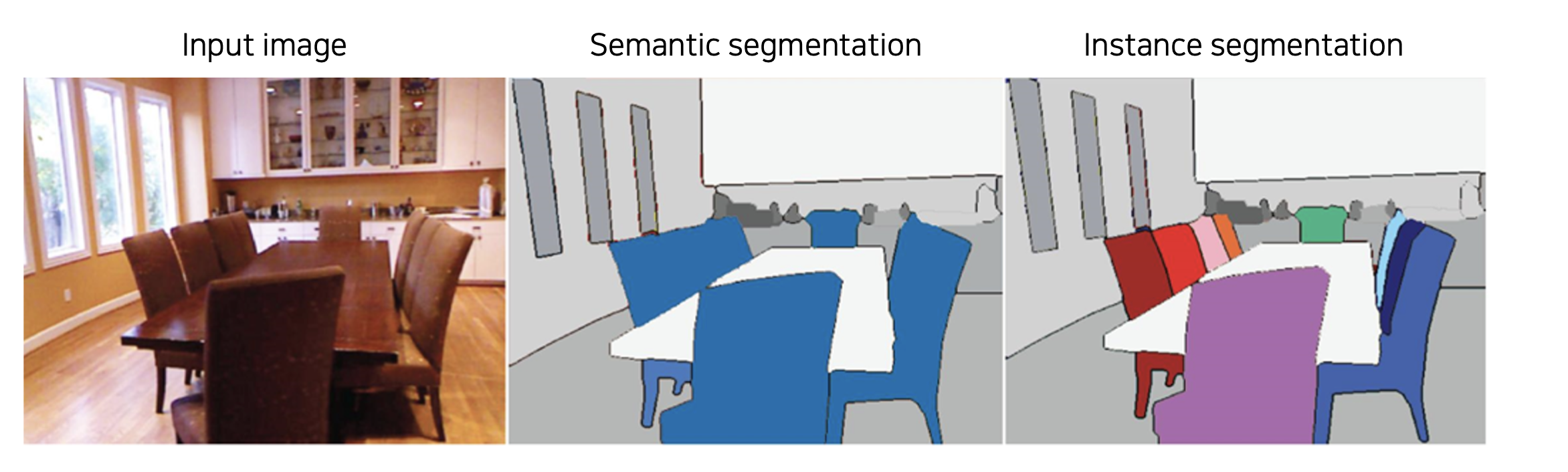
Semantic Segmentation 과 달리 같은 물체라도 다른 객체라면 다르게 구분해준다.
Semantic segmentation + Distinguishing instances
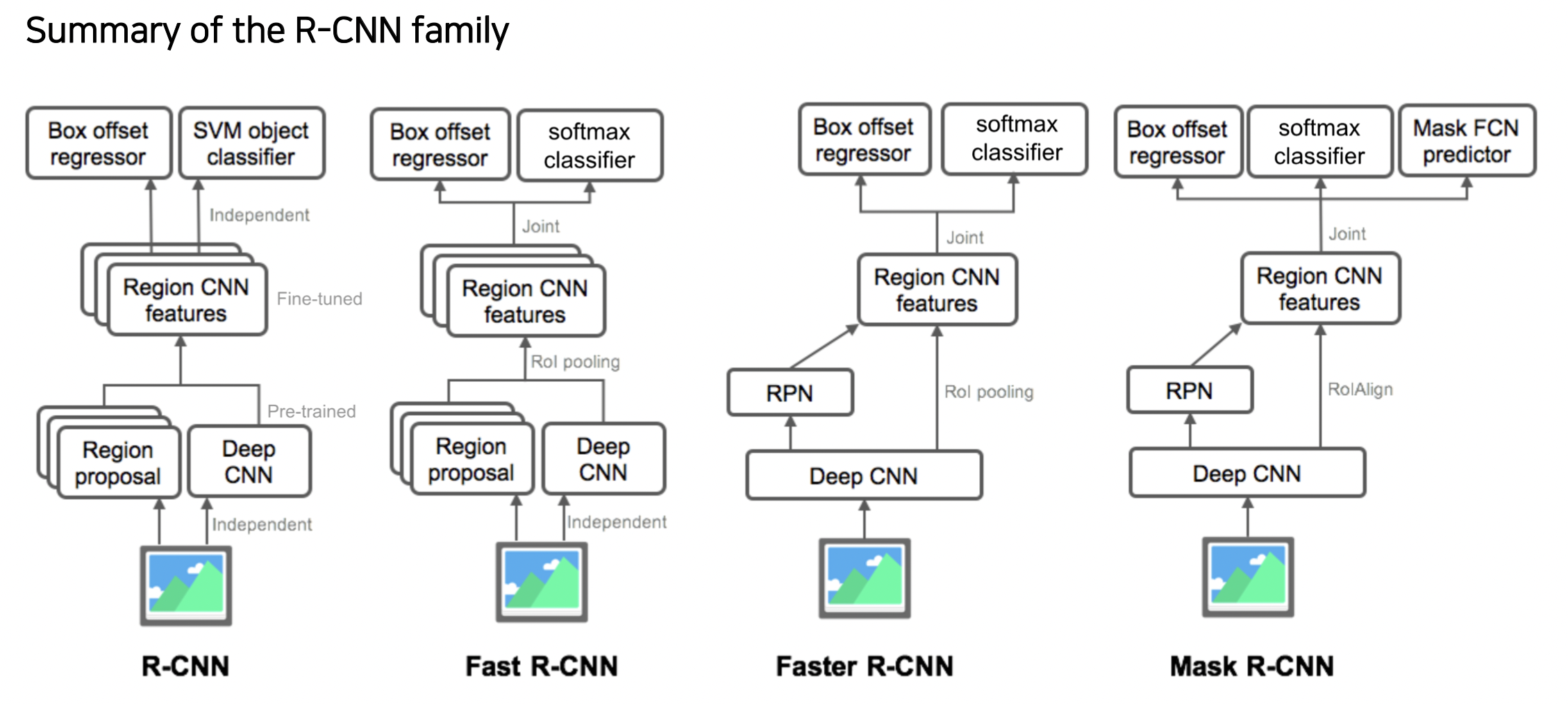
Mask R-CNN 방법
Mask-RCNN = Faster R-CNN + Mask branch
(Two-stage 구조)
Faster R-CNN 에서는 RoI Pooling 을 사용했다면
Mask R-CNN 는 RoI Align 을 사용해서 소수점을 처리할 수 있다.
Semantic segmentation 에서는 물체의 위치 주변에 박스만 치면 됐지만 이제는 물체에 대한 정확한 위치를 추려내야 하기 때문에 사용한다.
마스크 브랜치는 각 클래스 별로 바이너리 마스크를 prediction 하는 구조를 갖고 있다.
네트워크를 거쳐 나온 class 를 통해 전체 마스크 중 어떤 마스크를 선택할지 고른다.
아래 그림은 80 개의 클래스가 있다.

YOLACT (You Only Look At CoefficienTs)
실시간으로 semantic segmentation 이 가능한 Single-stage 네트워크이다.
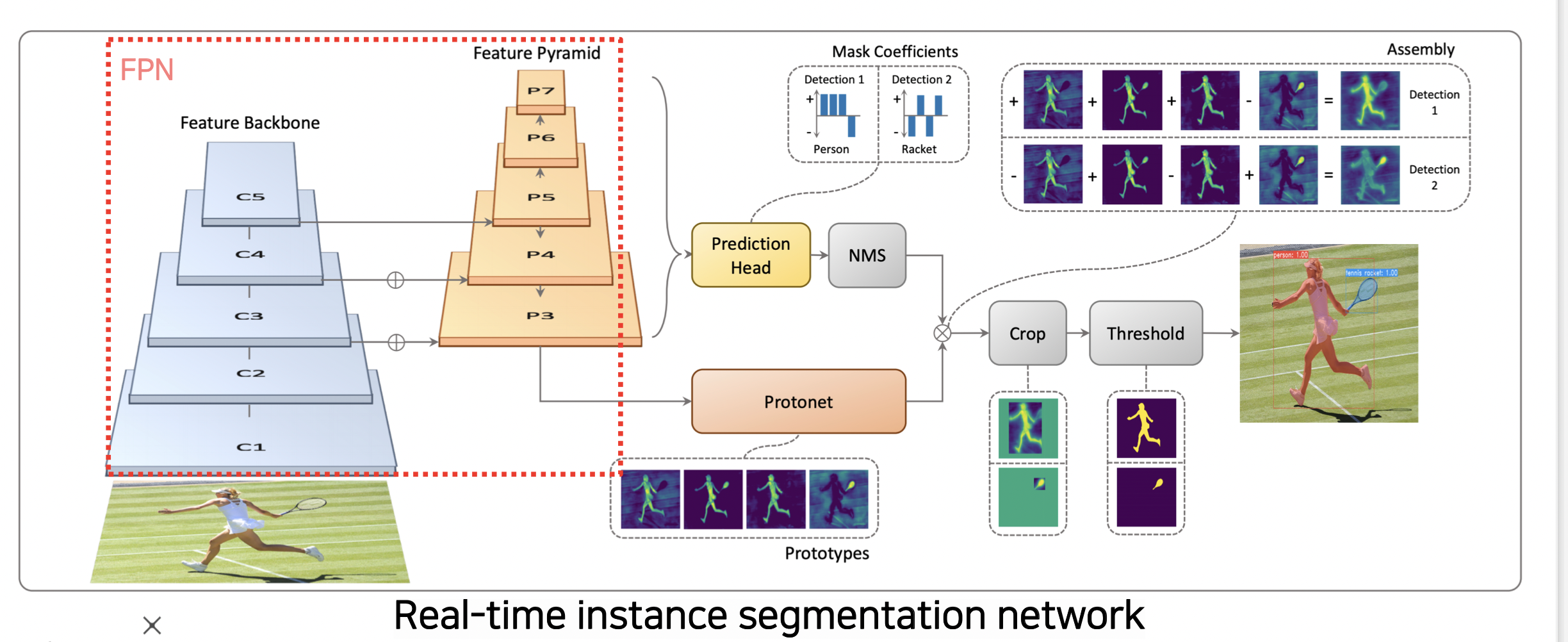
Feature Pyramid
Feature Pyramid 구조를 통해 고해상도의 feature map 을 사용할 수 있다. (Skip connection)
프로토타입
마스크의 프로토타입을 사용한다.
Mask R-CNN 에서는 각각 독립적인 마스크를 한 번에 생성했다면
프로토타입은 마스크는 아니지만 마스크를 합성해낼 수 있는 기본적인 component 를 통해 추후에 마스크를 만들어낸다.
각 마스크를 바로 만드는 방법보다 효율적이다.
Prediction Head
prediction head 는 프로토타입을 잘 합성하기 위한 계수 (coefficients) 를 출력한다.
계수와 프로토넷은 선형결합되어 각 detection 에 적합한 마스크를 생성한다.
YolactEdge 방법
엣지 디바이스에 올릴 수 있을 정도로 가볍게 만들기 위해 제안되었다.
이전 프레임 중 키프레임에 해당하는 프레임 피쳐를 다음 프레임에 전달해서 피쳐맵의 계산량을 줄였다.
하지만 마스크가 깜빡 거리거나 떨리는 성능 문제가 있어 더 연구돼야 한다.

Panoptic Segmentation
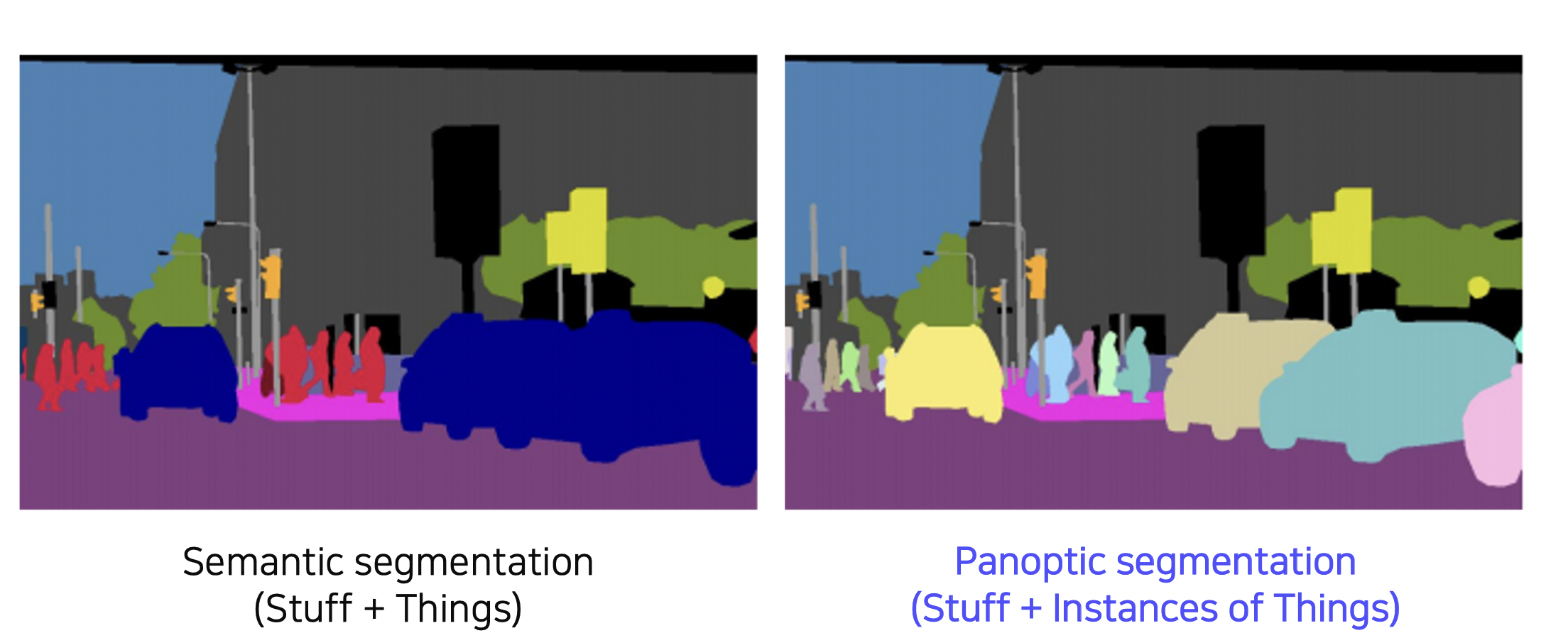
Instance Segmentation 은 배경에는 관심이 없고 움직이는 물체 (사람, 차 등) 만 감지했다면, Panoptic Segmentation 은 물체와 더불어 배경까지 감지한다. (Stuff + Instance of Things)
UPS 모델
FPN 구조를 사용하여 고해상도의 피쳐맵을 뽑아내고
헤드 브랜치를 여러 개로 나눈다.
Semantic Head 는 Fully Convolution 구조로 Semantic map 을 prediction 한다. (배경과 물체인지 구분)
Instance Head 는 물체의 detection, box regression, 마스크를 추출한다. (물체에 대해 박싱)
Panoptic Head 는 위 두 결과를 하나의 Segmentation map 으로 합쳐준다.

Semantic Head 는 물체를 구분하는 thing 과 배경을 구분하는 stuff 마스크들이 있다.
stuff 마스크는 바로 최종 출력 (panotic) 으로 가고 thing 마스크는 instance 마스크와 더해져서 (해당 박스가 물체인지 알 수 있게 함) 최종 출력으로 간다.
thing 마스크 전체 (전체 물체 맵) 에서 가장 뚜렷한 물체 부분을 뺀 일종의 배경에 대한 정보를 한 층으로 최종 출력에 붙인다.

VPSNet 방법
panoptic segmentation 구조를 video 로 확장하였다.
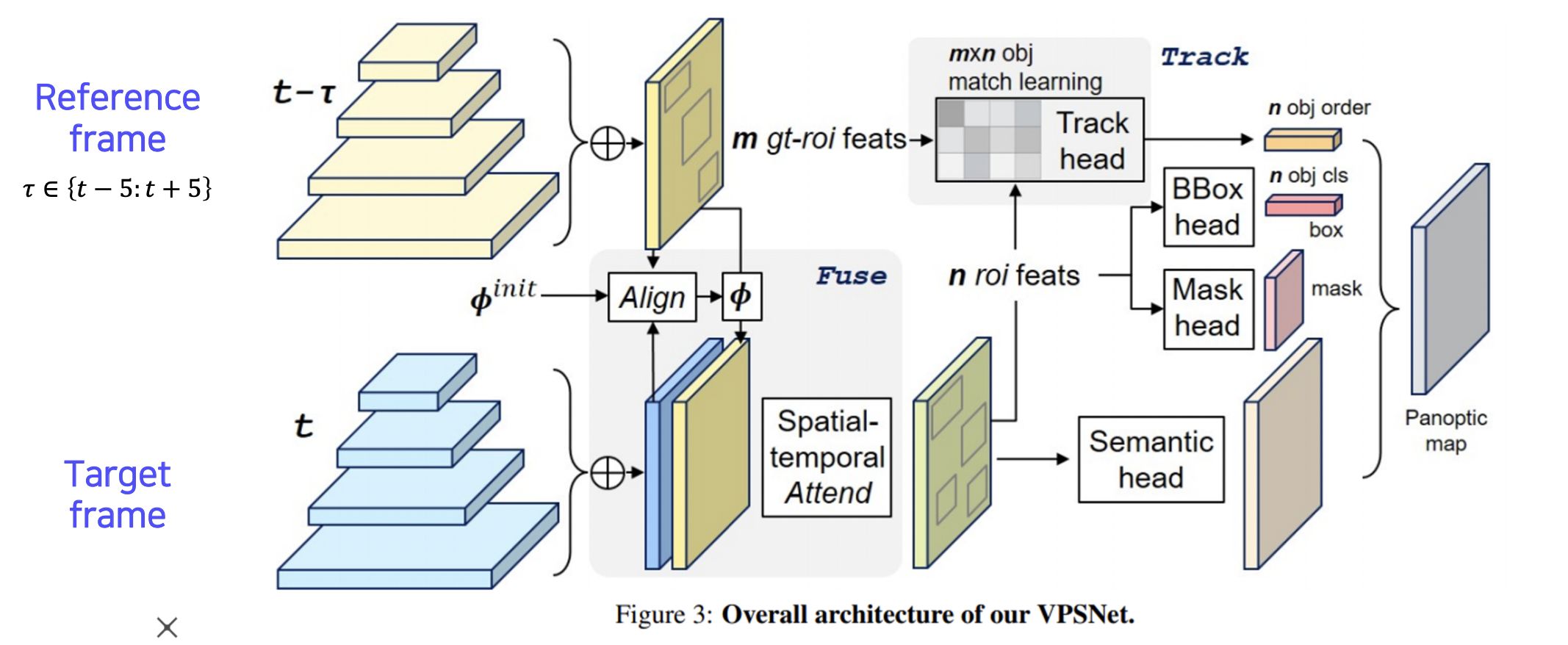
- Align reference features onto the target feature map (Fusion at pixel level)
- 시간 차를 갖는 두 영상 사이에 파이라는 모션맵을 사용해서 각 프레임에 나온 피쳐맵을 모션에 따라 매핑한다.
(모션맵은 시간 차가 있는 두 영상에서 움직임이 어떻게 변화는지 파악한다.) - t- 에서 뽑힌 피쳐이지만 t 에서 뽑은 것처럼 옮겨준다. 이 것과 원래 t 에서 뽑은 피쳐를 합쳐준다.
- 여러 피쳐의 특징을 합쳐 씀으로써 시간 연속적으로 더 스무스하게 segmentation 이 가능하다.
- Track module associates different object instances (Track at instance level)
- track head 를 통해 기존의 roi 와 현재 roi 의 연관성을 파악한다.
- 같은 물체는 같은 id 를 갖도록 트래킹해준다.
- Fused-and-tracked modules are trained to synergize each other
- 바운딩박스 헤드, 마스크 헤드, 시맨틱 헤드에서 나온 결과를 panoptic 맵으로 합친다.
Landmark Localization
Landmark Localization 이란?
얼굴이나 사람의 포즈를 추적하는데 많이 사용되는 방법으로
특정 물체에서 중요하다고 생각되는 특정 부분 (landmark) 들을 정의하고 추적한다.

Coordinate regression vs. Heatmap classification
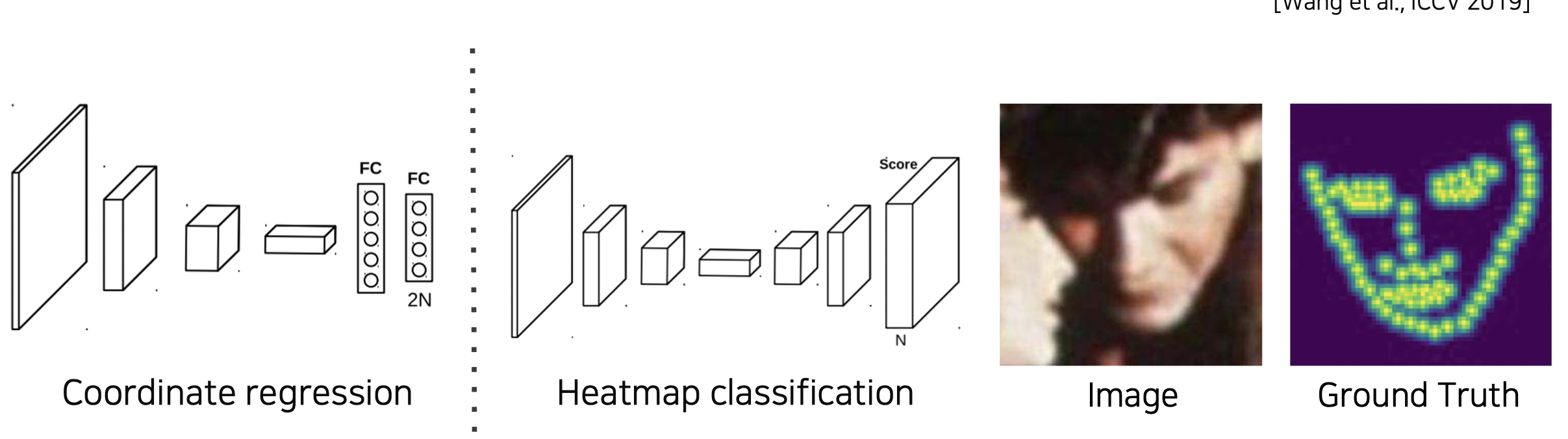
Coordinate regression
정확성이 낮고 일반화에 문제가 있다.
Heatmap classification
각 키포인트가 발생할 확률을 히트맵으로 나타내는 방법으로 성능은 좋지만 모든 픽셀에 대해 판별하다 보니 계산량이 많다.
히트맵 생성
히트맵은 각 위치마다 confidence 가 나오는 형태의 표현이다.
x, y 위치가 레이블로 주어졌을 때 (x, y) 히트맵을 가우시안 방법을 통해 구한다.
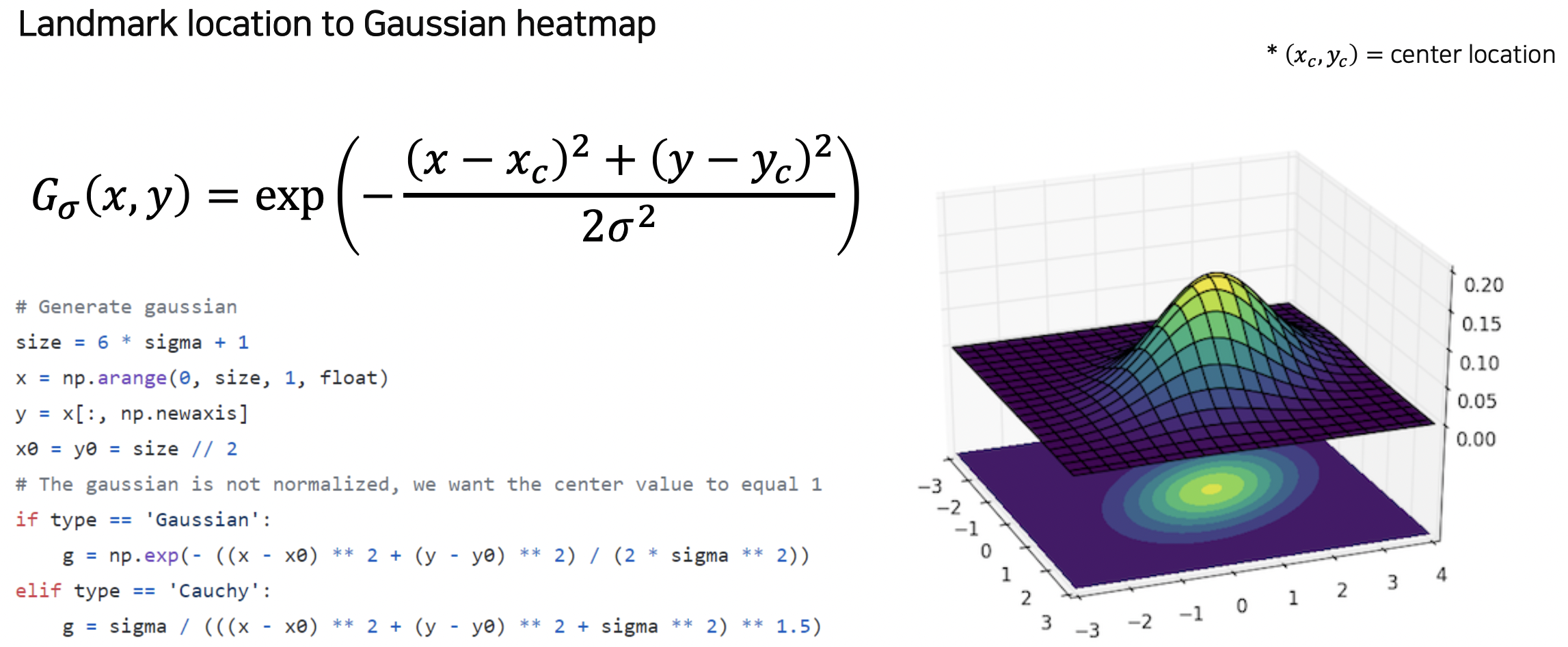
히트맵이 만들어졌다면 히트맵을 사용 가능한 좌표 x, y 로 바꿔야 한다.
히트맵에서 가장 값이 큰 max 부분의 위치 x, y 를 이미지에 나타내면 된다.
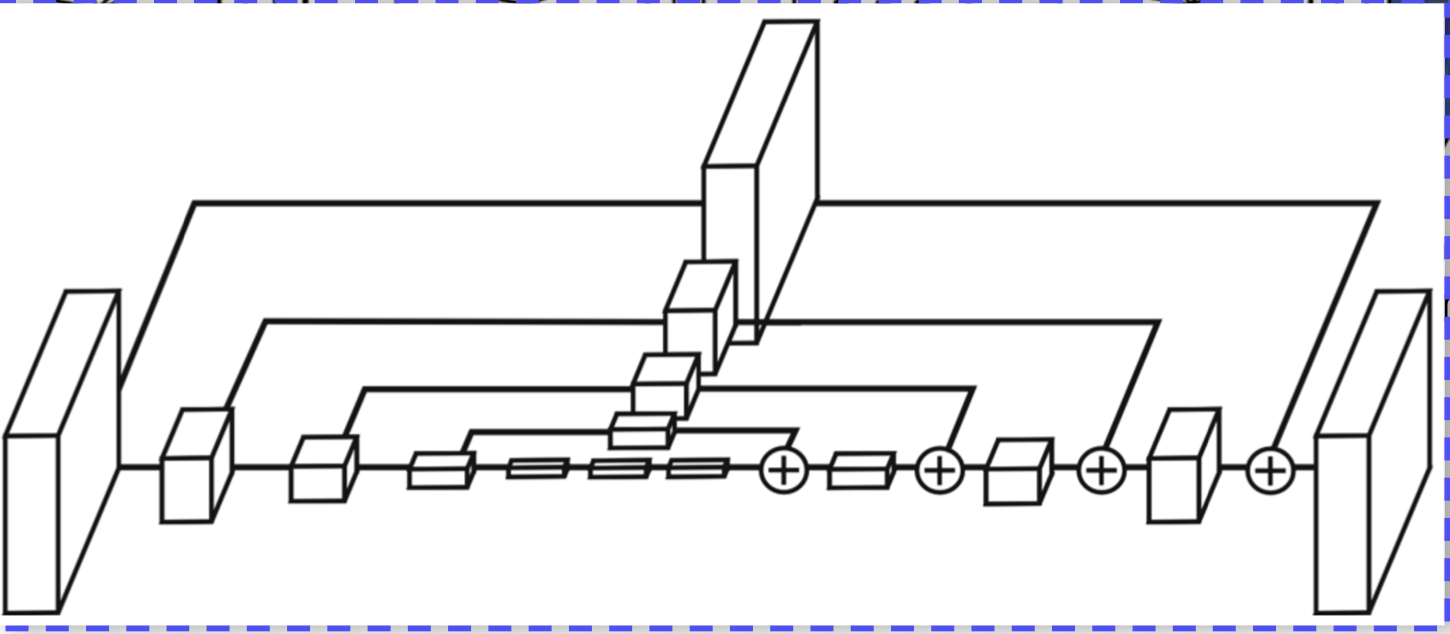
Hourglass network 방법
U-Net 구조가 여러 개 쌓인 구조로 모양이 모래시계 같아서 이름이 hourglass 가 되었다.
receptive field 를 크게 가져가서 정보를 많이 볼 수 있고 skip connection 을 사용하여 기존 정보를 보존할 수 있다.
현재 주어진 rough 한 정보를 계속 개선해나간다.

U-Net 의 Skip connection 과 다른점
- concat 이 아닌 + 를 사용하여 차원이 늘지 않는다.
- skip 할 때 그냥 더해지는게 아니라 convolution 을 통과시키고 더한다.
DensePose 방법
지금까지는 sparse 하게 몇 몇 landmark 만 찾아냈는데 DensePose 방법은 모든 신체 부위의 landmark 를 dense 하게 찾아낼 수 있다.

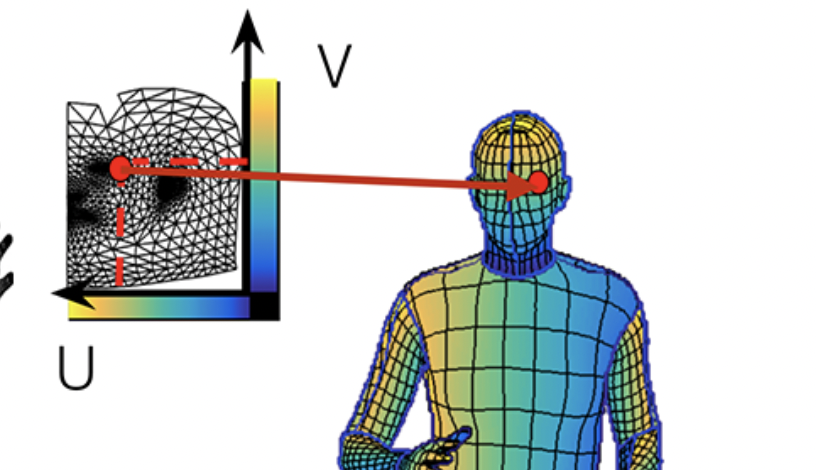
UV map
UVmap 표현법을 사용해서 3D 처럼 표현 가능하다.
UVmap 에서의 한 점은 3D mesh 의 한 점으로 연결된다.
UVmap 과 3D mesh 의 관계는 변하지 않는다. 즉, 점의 위치를 알면 3D 맵의 좌표가 변해도 따라갈 수 있다. 연결되어 있기 때문!
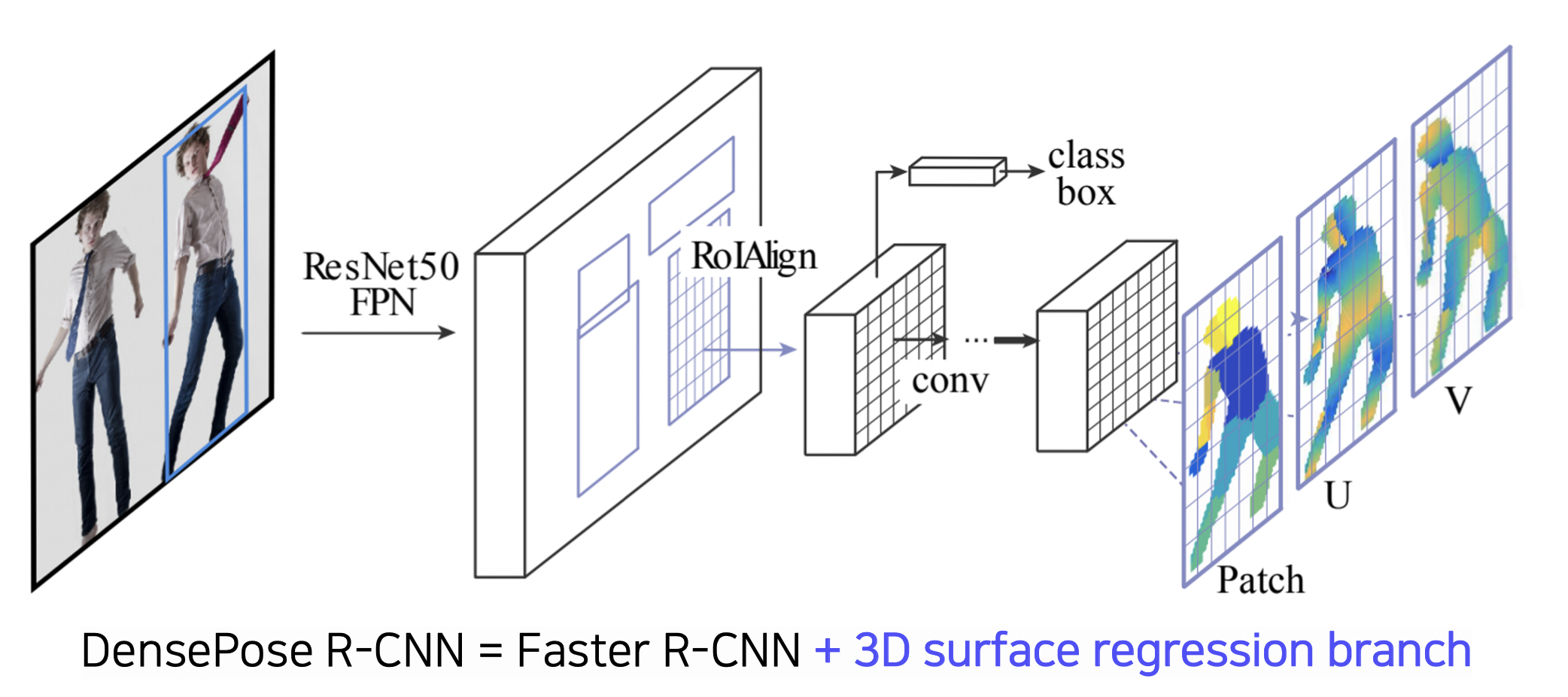
DensePose 의 구조
mask R-CNN 과 비슷한데 mask branch 파트를 3D surface regression branch 로 대체하였다.
RetinaFace
FPN 에 다양한 태스크를 한 번에 풀도록 multi-task branches 를 사용하였다.
다른 태스크를 수행하면서 백본 네트워크 (멀티 스케일 피쳐맵) 가 더 학습이 잘 된다.
적은 데이터로도 강한 학습 효과를 나타낸다.

이렇듯 backbone 네트워크 위에 다양한 방법을 얹는 것이 대세가 되었다.
Detecting Objects as Keypoints
바운딩 박스가 아닌 키포인트 위주로 탐지하는 방법들이다.
CornerNet & CenterNet
CornerNet
왼쪽 위 점, 오른쪽 아래 점만 있으면 바운딩 박스 하나가 결정된다는 특징을 활용한 구조이다.
두 좌표를 찾고 같이 임베딩시켜 이미지에서 찾을 수 있도록 한다.
싱글 스테이지 구조에 가깝고 성능보다는 속도에 중점을 뒀다.

CenterNet(1)
왼쪽 위 점, 오른쪽 아래 점, 가운데 점까지 추가하였다.

CenterNet(2)
폭, 높이, 가운데 점을 사용하였다.
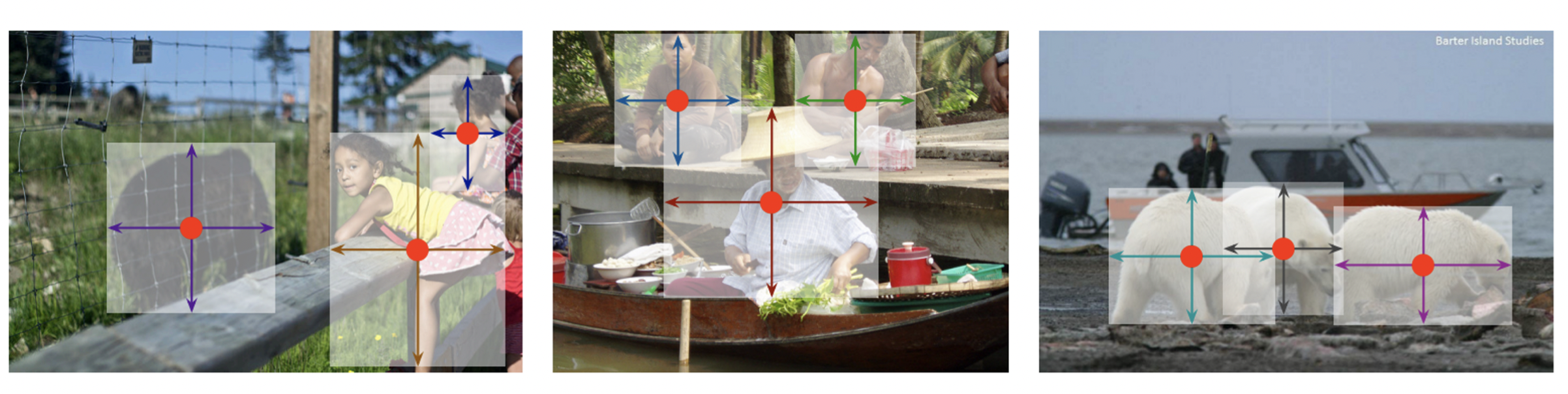
참조
BoostCamp AI Tech
