Conditional Generative Model
개념
그림으로 그린 가방을 실제 가방으로 생성해준다면?
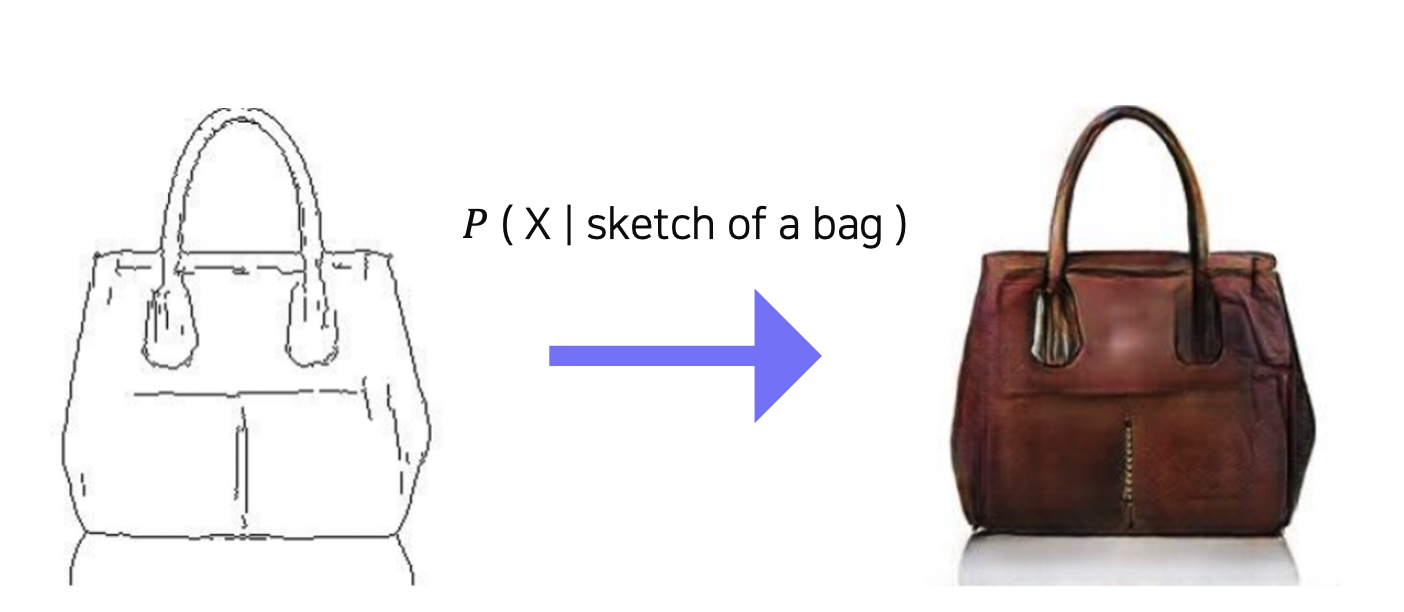
입력에 대해 X 인 이미지가 나올 확률을 구하고, 샘플링을 통해 이미지를 생성한다.
Generative Model 과 Conditional Generative Model
Generative Model 은 가방에 대해 생성하면 랜덤한 가방 이미지만 생성할 수 있다.
반면, Conditional Generative Model 은 주어진 스케치에 대해 랜덤한 가방 이미지를 생성할 수 있다.
즉, 사용자가 원하는 형태로 이미지를 생성할 수 있다.
Conditional GM 의 응용 사례
- 저퀄리티의 음성 파일을 고퀄리티로 변환
- 중국어 문장을 영어로 번역
- 제목과 부제목만 가지고 글쓰기 등
Recap (복기) : GAN
생성 모델 (Generator) 과 판별 모델 (Discriminator) 의 상호 작용으로 모델의 성능이 향상되는 방법이다.
GAN vs. Conditional GAN
Generator 에 사용자의 입력 c 를 추가하였다.
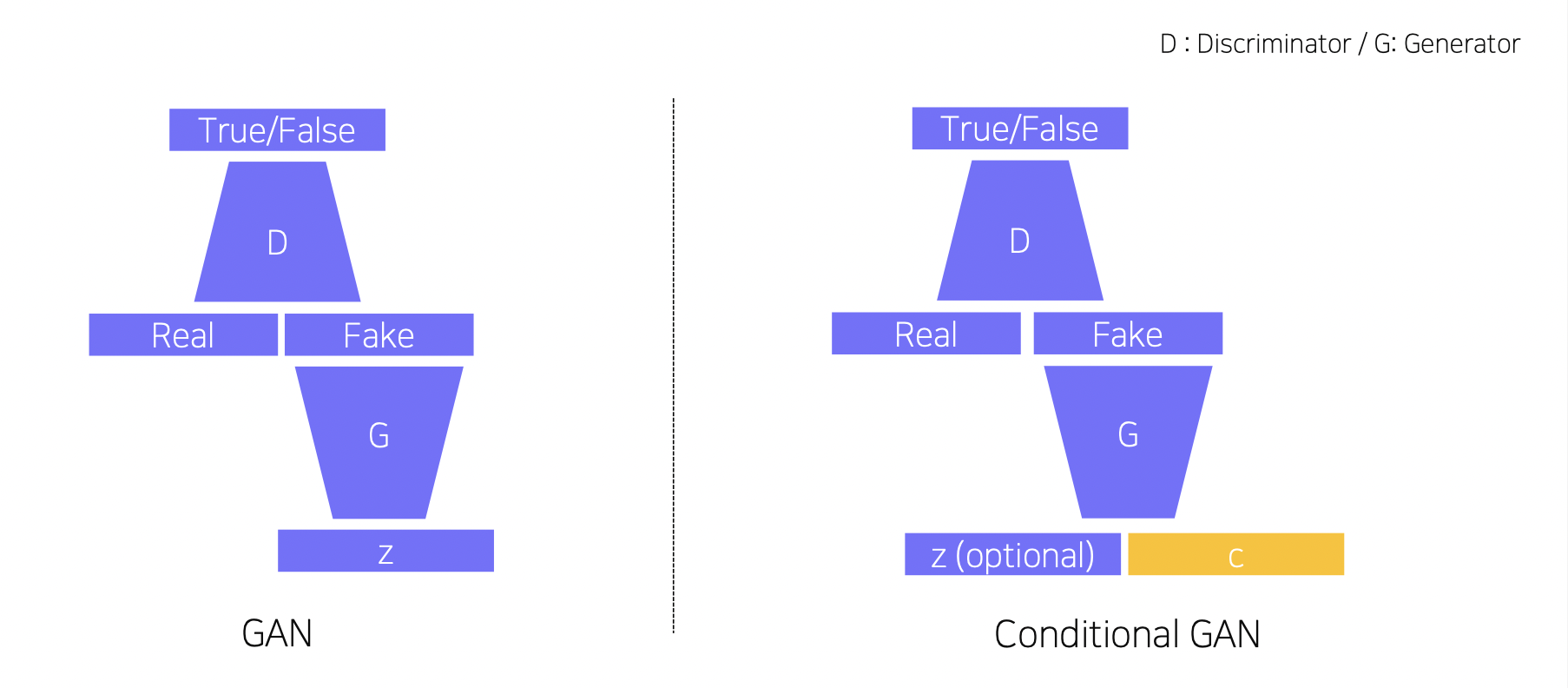
Conditional GAN and Image Translation
원하는 이미지를 다른 스타일로 바꿀 수 있다. (Image Translation)

Example : Super Resolution
저해상도 이미지를 고해상도로 바꾸는 문제에 사용될 수 있다.
기본 회귀 모델과 Super Resolution GAN 의 차이
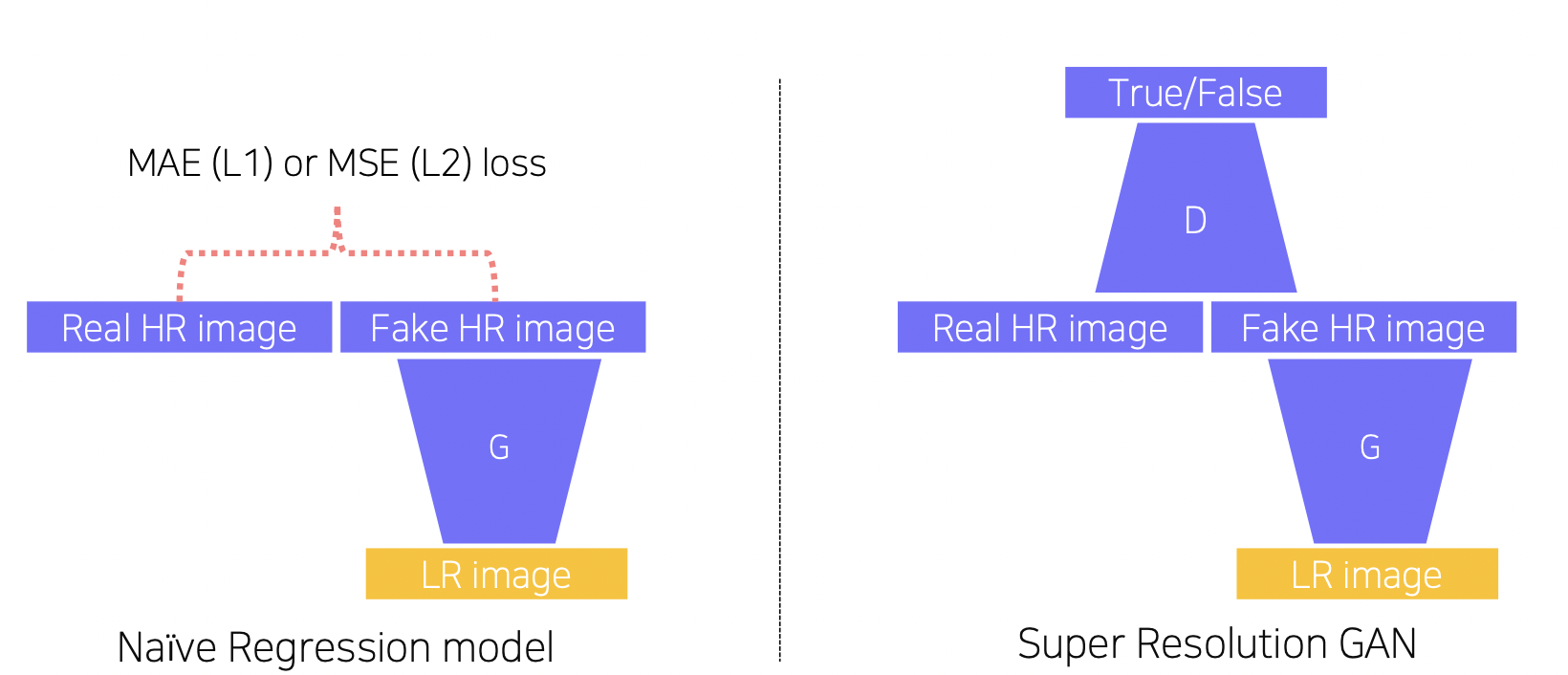
기본 회귀 모델은 평균을 사용하기 때문에 실제 이미지들과 평균적으로 적당히 떨어진 이미지 (어정쩡한 이미지) 를 생성하게 된다. 실제와 가장 근접한 이미지를 생성하지 못한다.
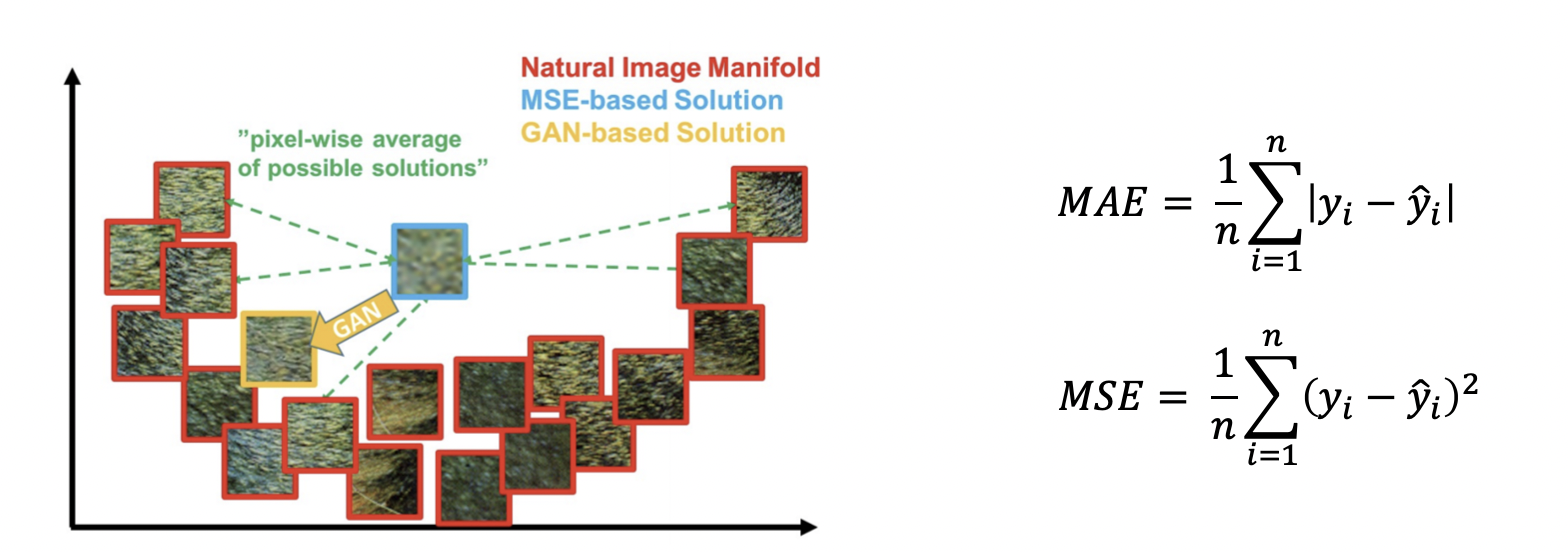
반면, GAN 은 Discriminator 의 판별을 피하기 위해 실제 데이터와 가장 가깝게 생성한다.
아래 사진과 같이 평균을 사용하면 흰색과 검정색의 평균인 회색을 생성하고, GAN 은 실제와 가깝기 위해 흰색 또는 검정색을 생성하는 것을 볼 수 있다.
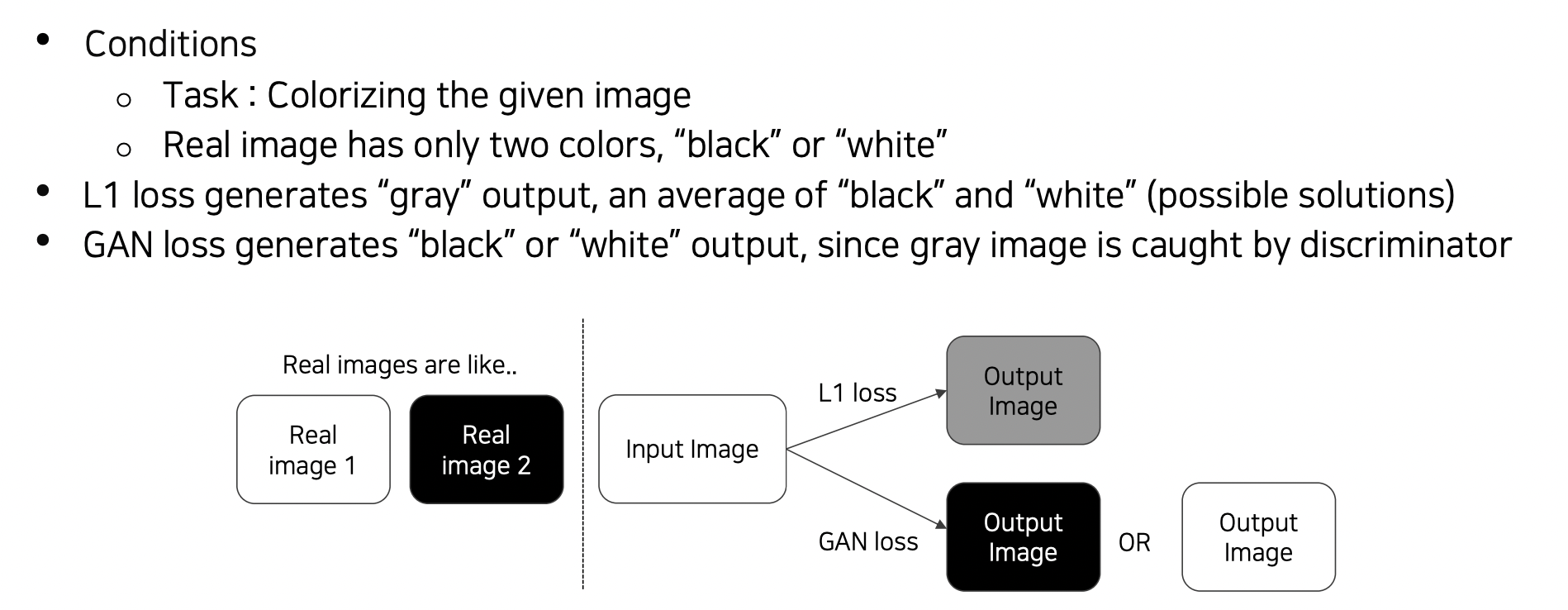
결과

Image Translation GANs
GAN 을 이용한 Image Translation 의 더 구체적인 방법들을 알아보자.
Pix2Pix 방법
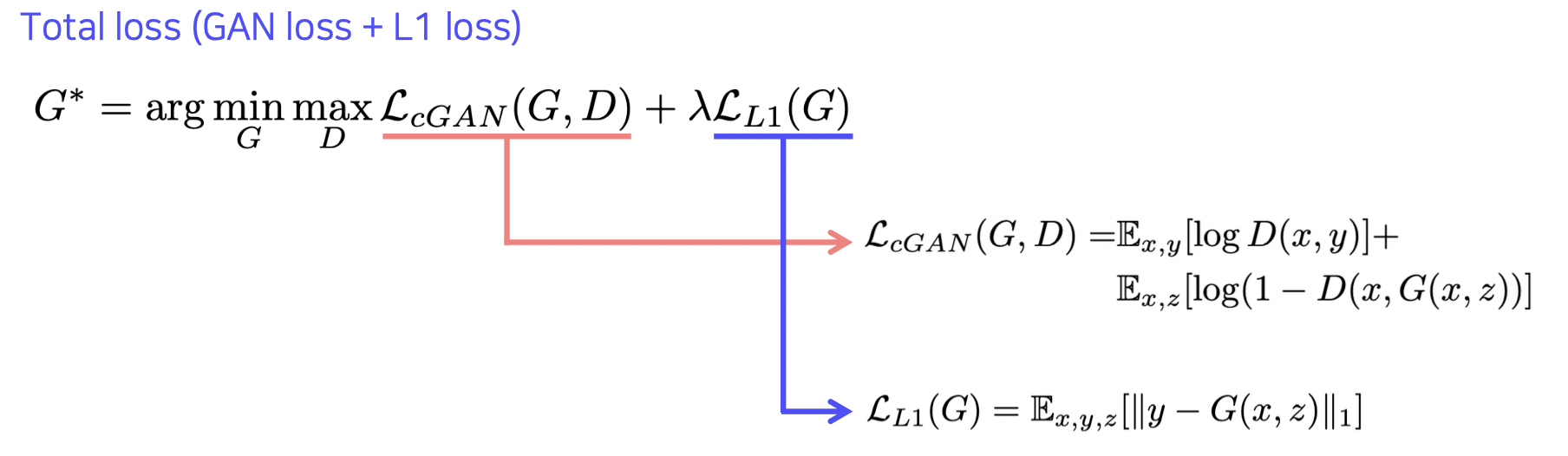
위 태스크를 수행함에 있어 L1 Loss 와 GAN Loss (Adversarial Loss) 를 모두 사용하는 방법이다.
실제 데이터와 직접 비교하기 위해 L1 loss 를 사용하는데
이 경우 생성된 이미지가 흐린 문제가 있다.
GAN loss 까지 사용하여 더 리얼한 사진을 만들 수 있다.
GAN loss 만 사용하면 실제 사진과 직접 비교는 힘들다.
그리고 이 당시에는 GAN 학습이 불안정한 문제가 있었기 때문에
L1 loss 도 같이 사용하였다.
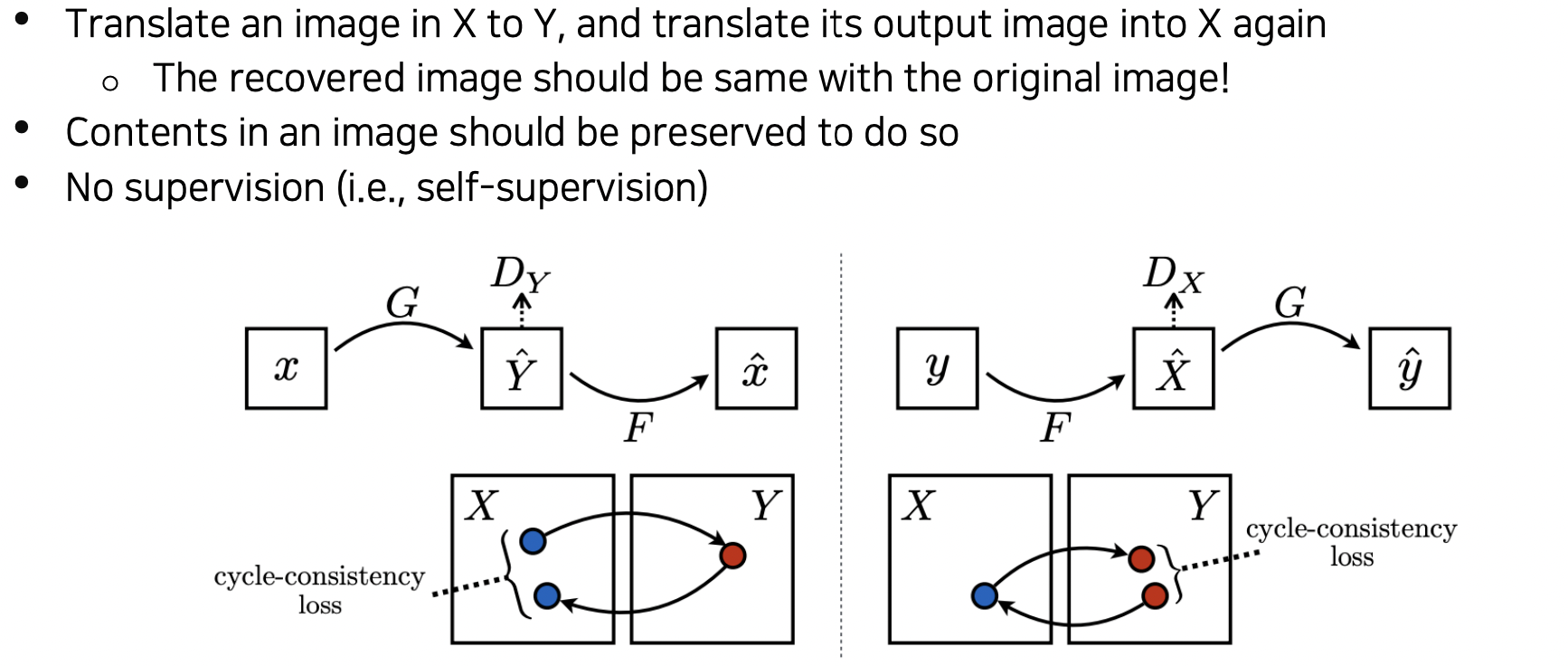
CycleGAN
Pix2Pix 는 지도학습이라 paired data (스케치로 그린 가방과 목표하는 가방), 입력 데이터와 정답이 필요했다.
데이터의 label 작업은 쉽지 않으므로 CycleGAN 은 paired data 를 사용하지 않고도 사진의 스타일을 변환화도록 하였다.

Loss
CycleGAN loss = GAN loss + Cycle-consistency loss
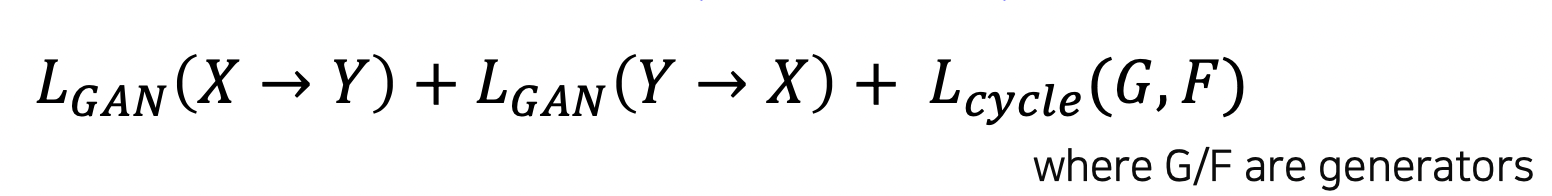
GAN loss
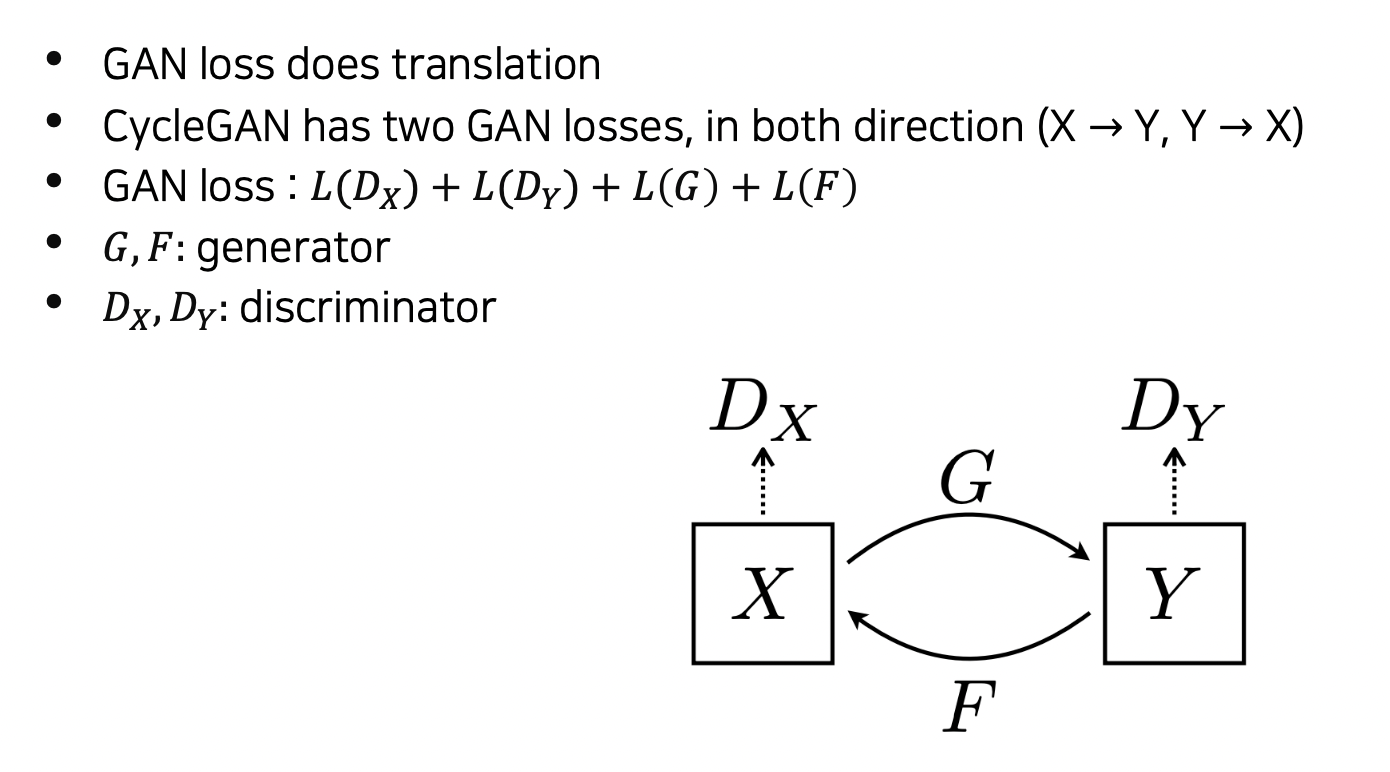
이미지를 X 도메인에서 Y 도메인으로 생성한 Dx 가 실제 Y 와 같은지 (반대도 수행) 체크한다.
즉, X 가 Y 로 갈 때 정말 그 스타일 같은지 본다.
만약 GAN loss 만 사용하게 된다면 입력에 상관없이 generator가 하나의 최적화된 이미지만 생성하는 Mode Collapse 문제가 발생한다.
Cycle-consistency loss
Mode Collapse 문제를 해결하기 위해
X->Y 로 갔다가 Y->X 로 돌아오게 만들고 원본이 유지되도록 함으로써
내용을 지킬 수 있다.
self-supervised 방법으로 볼 수 있다.
Perceptual Loss
supervise 가 가능 할 때는 성능을 위해 CycleGAN 보다 GAN 을 사용한다.
그런데 GAN 을 학습시키는 것은 제너레이터, 디스크리미네이터를 번갈아 학습하기 때문에 어렵다.
더 쉬운 방법을 통해 좋은 성능의 이미지를 생성해보자.
GAN loss 와 Perceptual loss 의 차이
GAN loss
학습이 어렵지만 어떤 프리트레인된 네트워크가 필요하지 않다.
기학습된 모델이 필요하지 않기 때문에 여러 응용이 가능하다.
Perceptual loss
간단한 forward, backward 로 구성되어 학습이 쉽다.
loss 를 학습하기 위해 기학습된 네트워크가 필요하다.
Perceptual Loss 개념
기학습된 모델은 인식을 한다는 점에서 인간의 시각 인식 체계와 비슷하다.
기학습된 모델 (더 이상 업데이트 되지 않음) 의 초반 레이어는 이미지를 인식 공간으로 볼 수 있다.
민감하게 다뤄야하는 것과 신경쓰지 않아도 되는 부분을 구분할 수 있다.
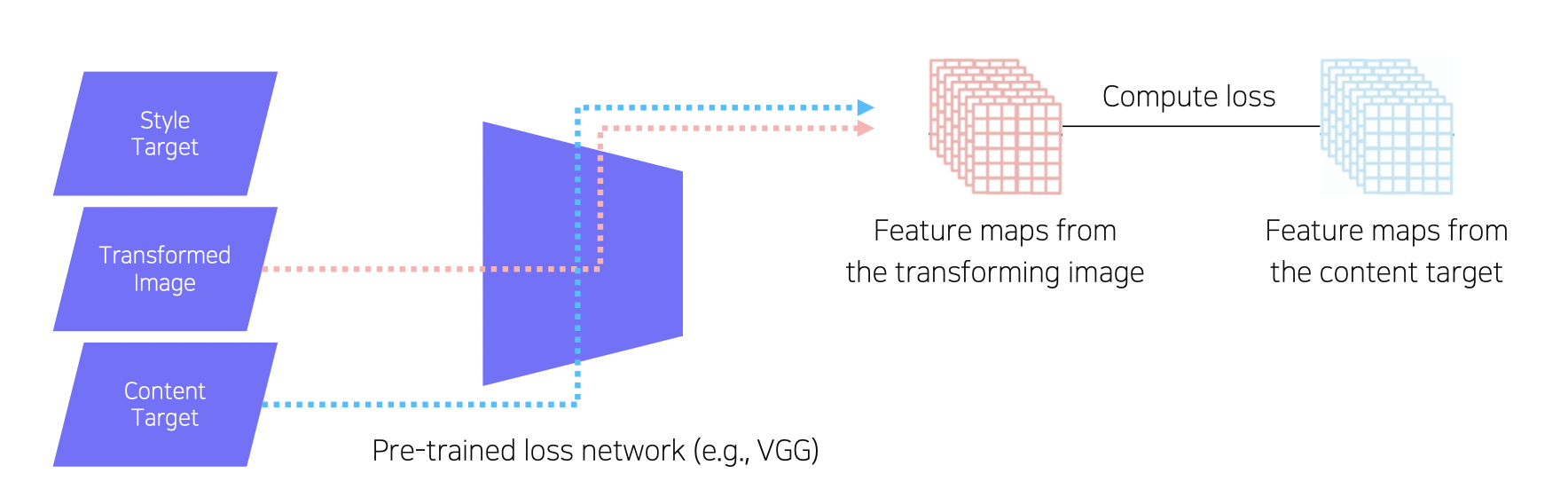
Image Transform Net 을 통해 스타일이 바뀐 이미지 y_hat 과
y_style, y_content 를 기학습된 VGG 넷에 넣고
Feature Reconstruction Loss 와 Style Reconstruction Loss 를 구한다.
Feature Reconstruction Loss
VGG 넷을 통과한 y_hat 와 y_content 의 결과를 L2 loss 로 만든 것이 Feature Reconstruction Loss 이다.
이 로스는 바뀐 이미지가 원래 이미지 모양을 유지하도록 만든다.
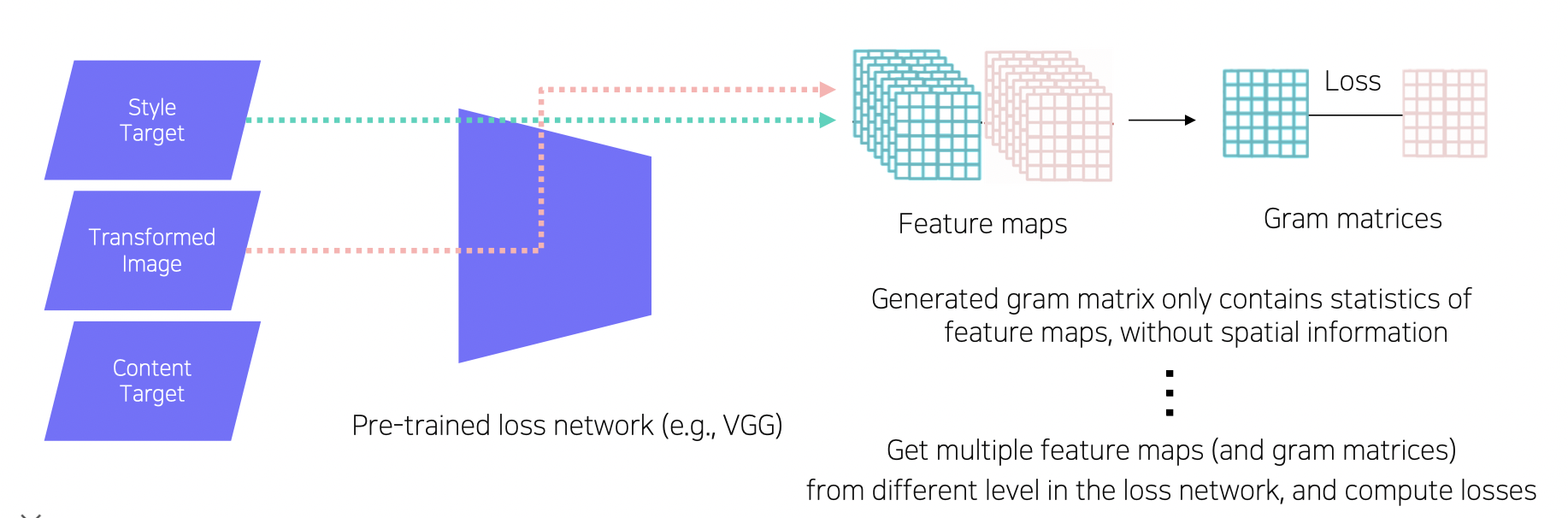
Style Reconstruction Loss
VGG(y_hat) 과 VGG(y_style) 으로 바로 loss 를 만들지 않고 각각 Gram matrices (이미지 전반에 걸친 통계적 특성 파악) 을 적용한 후 Style Reconstruction Loss 를 만든다.
Generator 의 결과가 원하는 스타일과 부합하도록 만든다.
Various GAN Applications
Deepfake
사람의 목소리나 얼굴을 다르게 바꿀 수 있다.
없는 사람의 얼굴을 만들거나 유명인사의 가짜 목소리를 만들 수 있다.
Deepfake 와 윤리
딥페이크의 위험을 막기 위해 딥페이크를 감지하는 대회를 열기도 하였다.
Face de-identification
GAN 의 선한 사용법!
privacy 를 보호하기 위해 진짜 사람과 약간만 달라도 잡아내는 기술에 적용될 수 있다.
Video Translation (manipulation)
한 사람의 외모에 다른 사람의 동작을 입힌 동영상을 만들 수 있다.
비디오를 게임화시키는 데에도 사용될 수 있다.
참조
BoostCamp AI Tech

와우..! 대단한 기술입니다