LSTM (Long Short-Term Memory)
- 단기 기억을 길게 보관할 수 있도록 만든 소자
- 셀 스테이트
- 조금 더 완성된 (여러가지 필요한 정보를 담고 있는) 벡터
- 히든 스테이트
- 셀 스테이트 벡터를 한 번 더 가공해서 노출시켜주는 벡터
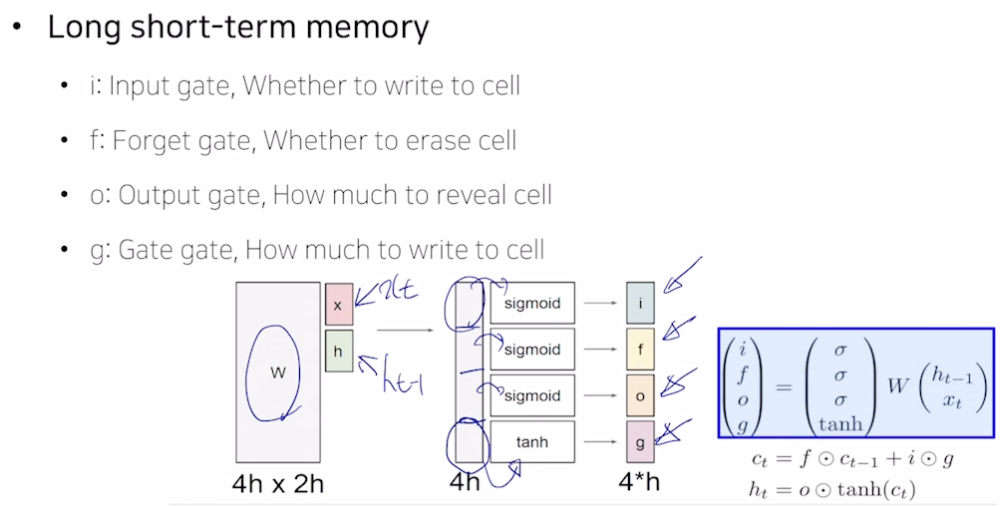
- x 와 h 는 h 차원 가져서 concat 하면 2h. 선형결합하면 2h → 4h 가 됨.
- 시그모이드를 거치면 값을 줄여줌 (e.g., 원래 값의 30% 만 보존)
- tanh를 거치면 -1~1 사이 값 가지므로 벡터를 저 사이로 변환시켜 유의미한 정보로 만듦
- Forget gate
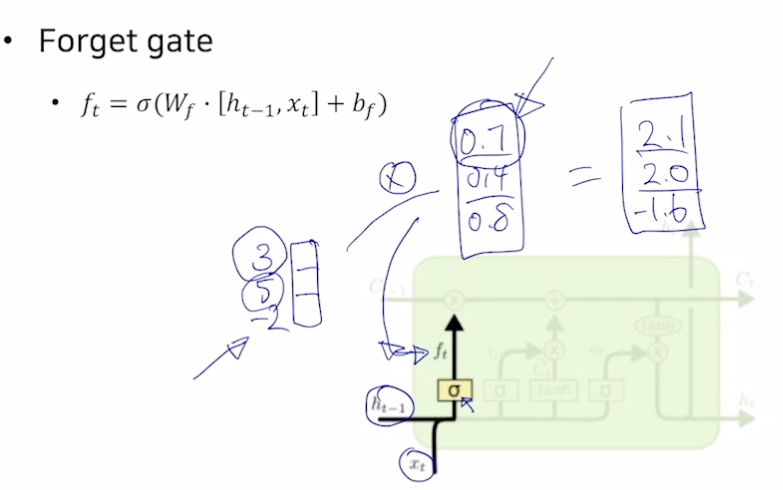
- 시그모이드를 통해 값을 버림
- Gate gate
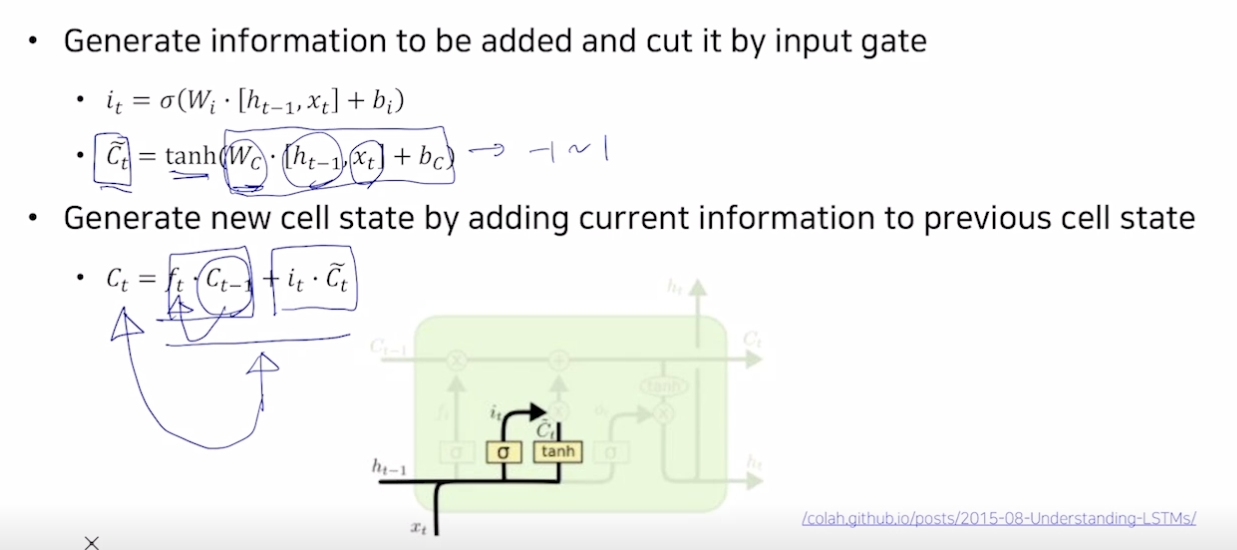
- C틸다는 tanh 를 거쳐 -1~1 로 바뀜.
- 셀 스테이트 갱신 : 덜어낸 정보 (c forget ) 와 새로운 정보 ( C틸다 (한 번의 선형변환만으로 더해줄 값을 만들기 어렵기 때문에 C틸다로 값을 만들고 i 를 곱하여 값을 덜어냄)) 를 더한다.
- Output gate
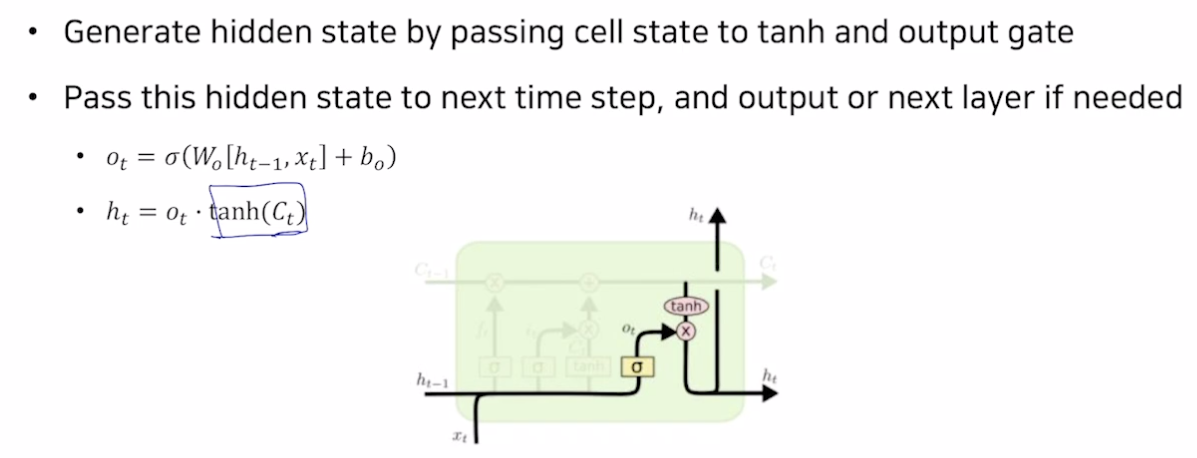
- 히든 스테이트 : 만들어진 셀 스테이트에 tanh 를 통해 정보를 만들고 o 만큼 덜어냄.
- 히든 스테이트는 많은 정보를 지닌 셀 스테이트를 조정해준 것
- 출력의 소스가 됨
GRU (Gated Recurrent Unit)
- 경량화되어 적은 메모리 소요 + 속도 빠름
- 히든 스테이트 벡터만 존재
- 전체 동작 원리는 LSTM 과 거의 비슷함
- LSTM 에서 완전한 정보 셀 스테이트처럼 여기서는 히든 스테이트가 완전한 정보를 지녀야 함

- z 는 인풋 게이트
- 구조를 보면 이전 정보 h 에는 1-z, 현재 인풋 게이트 h틸다에는 z 를 곱하여 덜어낼 것과 새로 채울 것의 비율을 맞춰줌
- 경량화됐지만 LSTM 과 비슷하거나 좋은 성능 보여줌
Backpropagation in LSTM?GRU
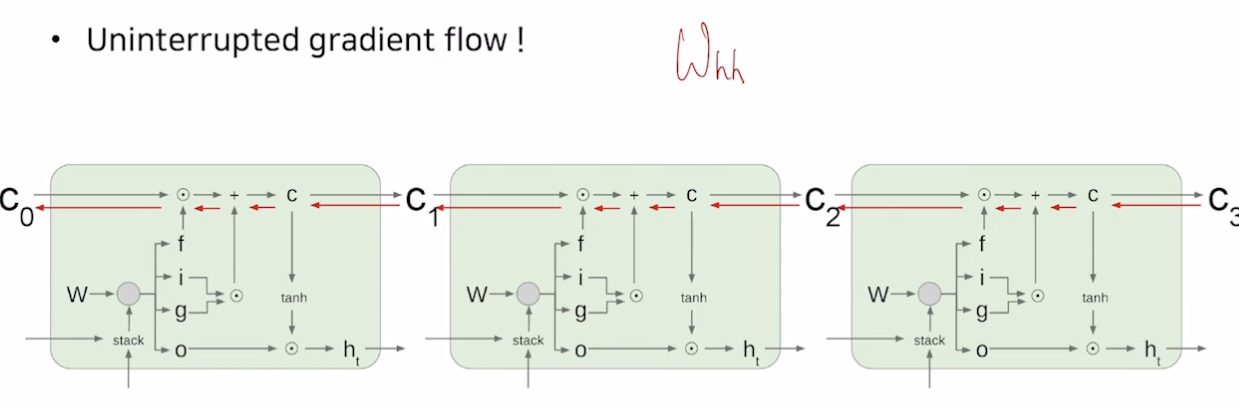
- 더 길게 grad 를 전달해줄 수 있음
요약
-
RNN 은 아키텍쳐 디자인에 유연성을 더해줌
-
기본 RNN 은 간단하지만 잘 동작하지 않음
→ timestep 마다 업데이트하는 과정이 곱셈에 기반했기 때문에 gradient vanishing 문제 생김
-
LSTM 과 GRU 는 덧셈 기반으로 grad 잘 전달함
Further Reading
Further Question
- BPTT 이외에 RNN/LSTM/GRU의 구조를 유지하면서 gradient vanishing/exploding 문제를 완화할 수 있는 방법이 있을까요?
-> RTRL, EKF (확실하지 않음) - RNN/LSTM/GRU 기반의 Language Model에서 초반 time step의 정보를 전달하기 어려운 점을 완화할 수 있는 방법이 있을까요?
-> teacher forcing (초반에는 출력 단어를 입력으로 넣지 않고 답을 입력으로 넣음)
참조
BoostCamp AI Tech

데이터로 문제를 해결하는 엔지니어를 꿈꿉니다.