Semantic Segentation 이란?
Classification 처럼 영상 단위로 클래스를 분류하는 것이 아닌
영상의 픽셀 단위로 물체를 구분하는 태스크를 말한다.
단, 객체 단위가 아닌 픽셀 단위이므로 사람이라는 클래스가 있을 때 사람 객체가 여려명 있다해도 모두 같은 색으로 구분된다.
*같은 클래스라도 다른 객체를 따로 구분하는 태스크는 instance segmentation 라고 한다.
응용 분야
- 의료용 사진
- 자율 주행
- 포토샵 등
Fully Convolutional Networks (FCN)
Semantic Segentation 문제를 해결하기 위해 나온 첫 모델 구조로 기존 CNN 구조와 다르게 뒷 부분에 FC 레이어를 사용하지 않고 전체 구조를 Convolution 레이어로 구성한다.
구체적으로는 FC 부분을 1x1 Conv 레이어로 구성한다.
FCN 구조는 이미지에서 각 픽셀의 위치를 알 수 있어서 물체 분별이 가능하다.
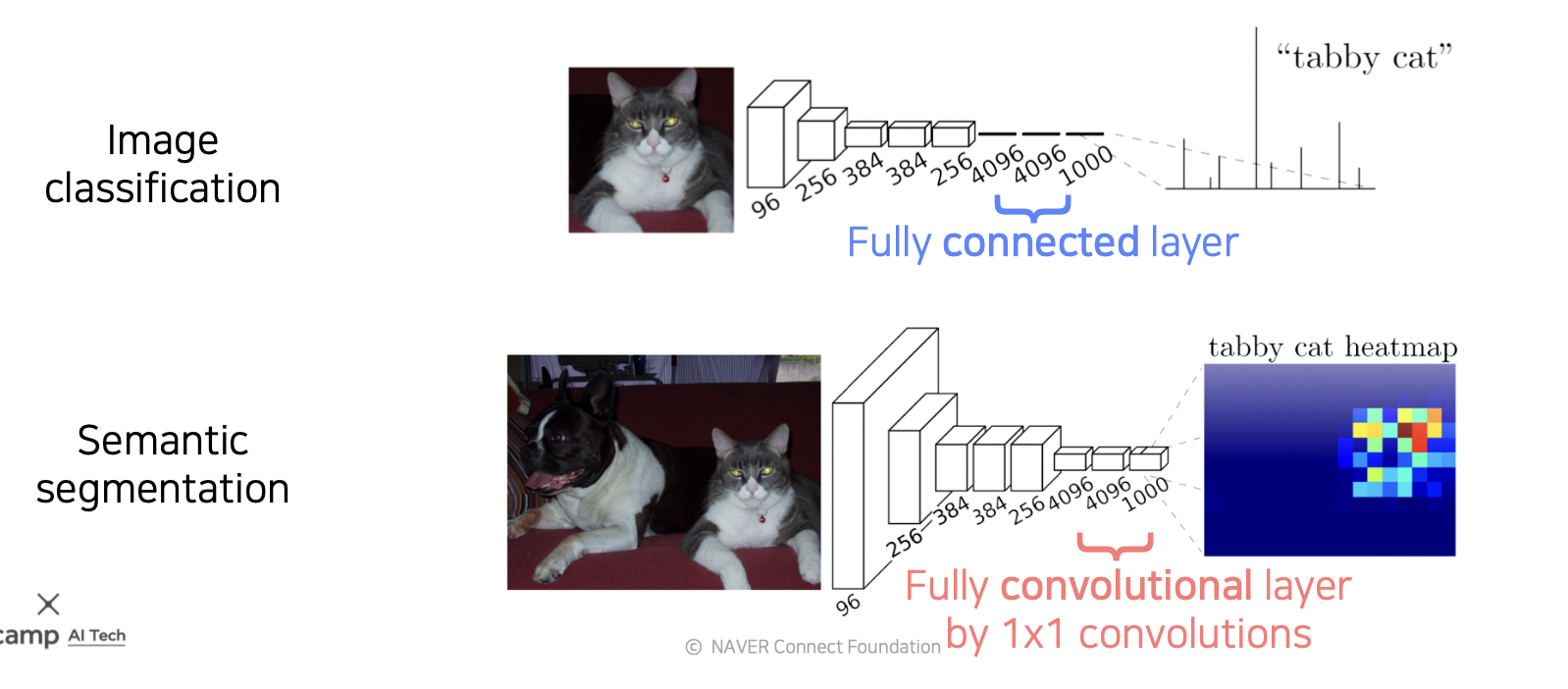

아래 모형과 같이 h x w 구조를 띄어 위치를 파악할 수 있다.
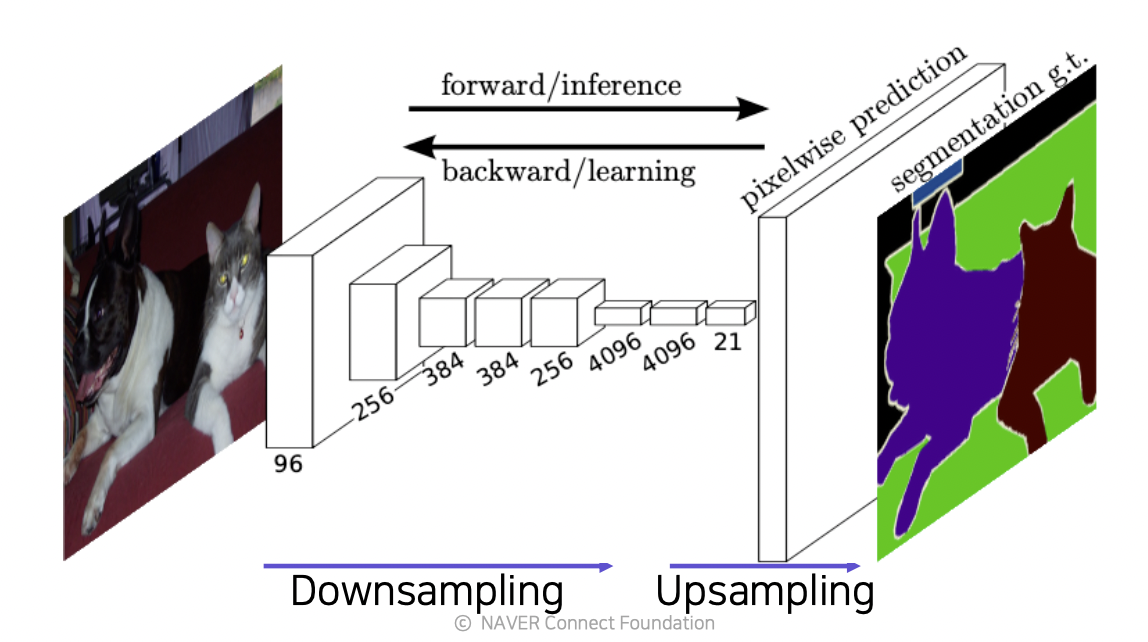
문제점
최종 결과의 해상도가 좋지 않기 않다는 문제점이 있다.
이 문제를 해결하기 위해 Upsamplig 을 사용한다.
Upsampling 레이어
최종 단에서 입력 이미지의 크기로 다시 확장시키는 방법 (deconvolution) 이다.
Transposed convolution
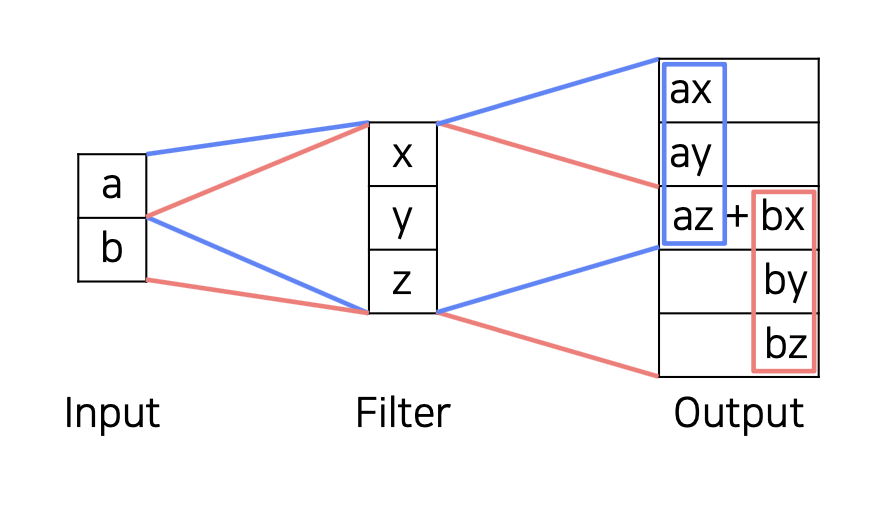
위 방법은 중첩되는 구간이 드문 드문 나타난다는 문제점 (overlap issue) 이 있다.
해결책
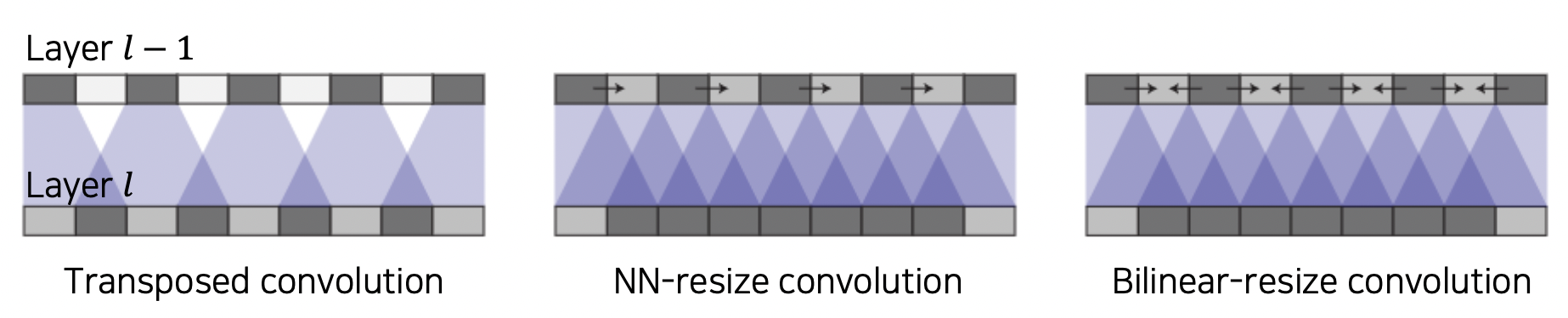
Bilinear-resize convolution (Nearest Neighbor + Bilinear) 을 적용한다.
Nearest Neighbor
overlap issue 를 해소하기 위해 같은 값을 여러 번 적용한다.
Bilinear
Nearest Neighbor 에서는 출력 값 사이의 값을 옆의 값 그대로 사용했는데, Bilinear 는 평균을 사용하여 더 부드럽게 값이 나오도록 한다.
FCN 의 특징
CNN 의 초기 레이어에서는 지역적이고 detail 한 정보를 알 수 있고
나중 레이어에서는 전체적이고 의미에 관한 정보를 알 수 있다.
FCN 은 디테일한 정보와 전체적인 정보를 모두 사용한다는 특징이 있다.
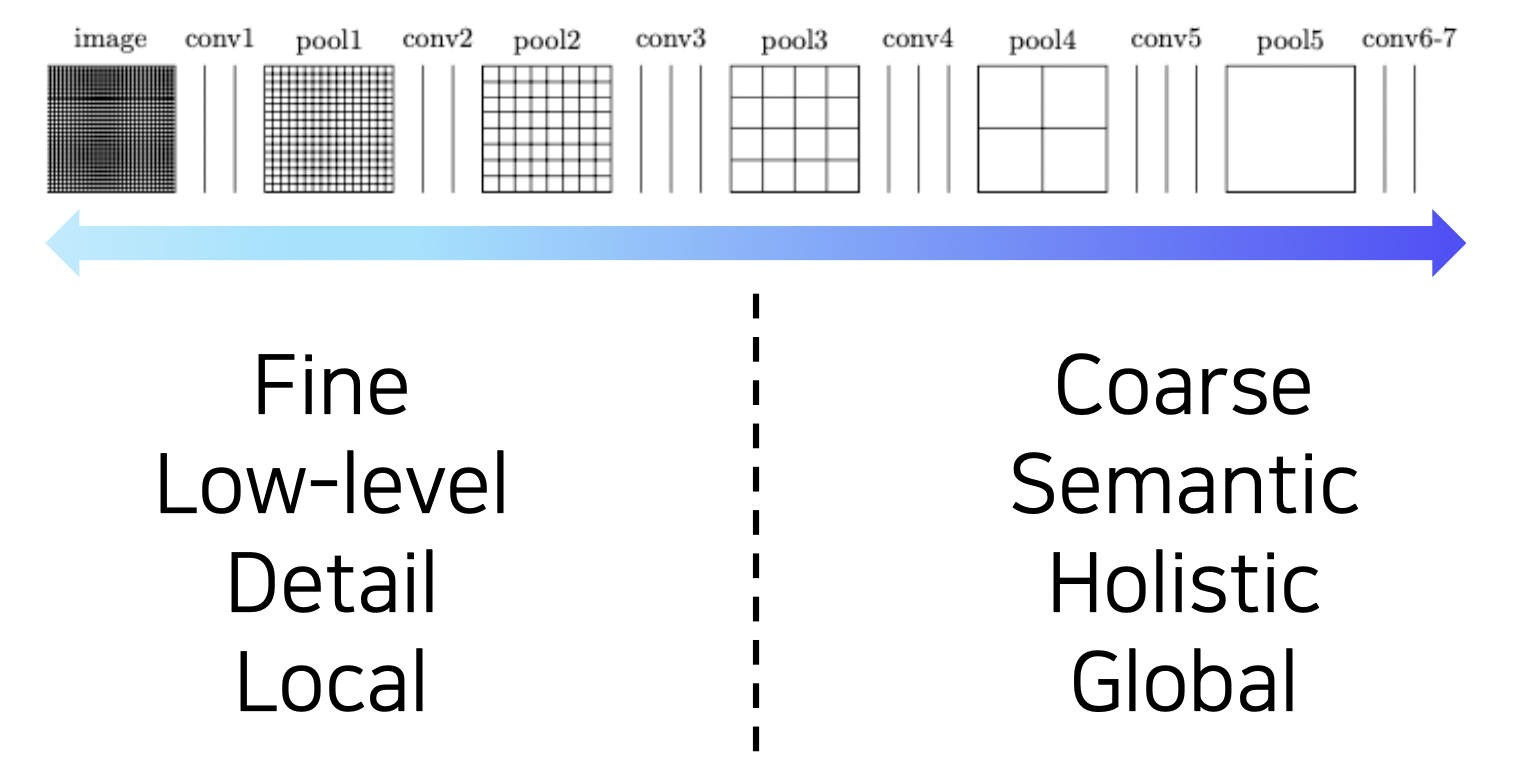
두 특징을 모두 확보하기 위해 다음과 같이 각 단계의 upsample 을 만들어서 각 단계마다 점수를 파악하고 최종적으로는 각 단계 결과를 모두 고려해서 사용한다.

결과

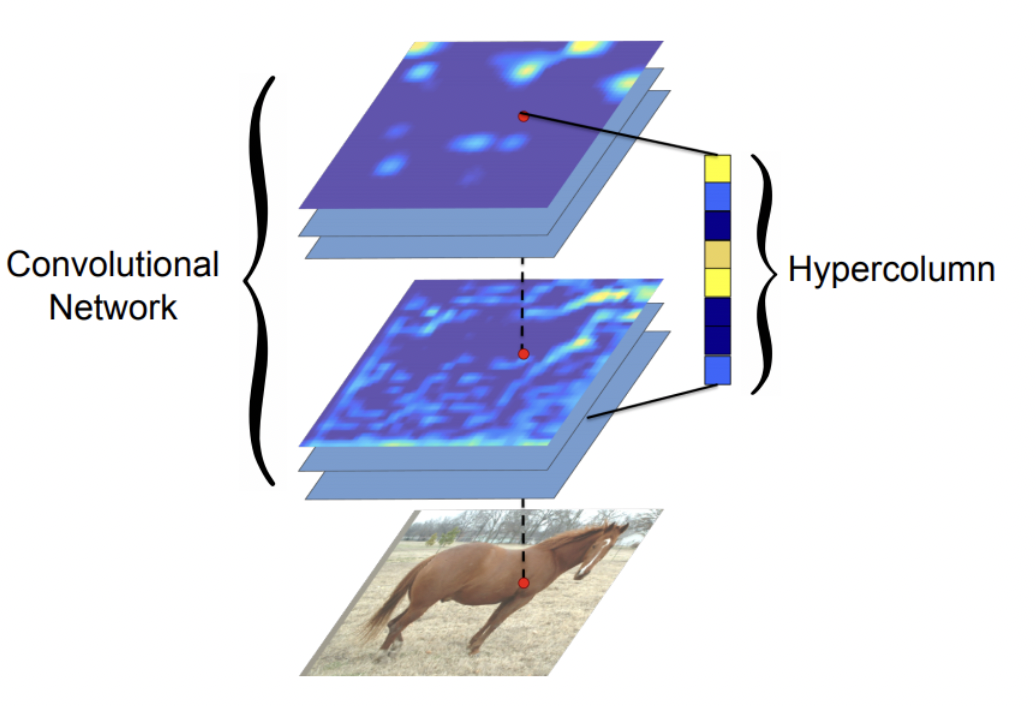
Hypercolumns
FCN 과 같은 해, 같은 학교에서 비슷한 논문이 나왔다. 하지만 FCN 보다 좋지 않다.
U-Net
영상 전체가 아닌 일부분을 봐야하는 경우에 유용한 모델이다.
FCN 에 Skip connection 을 적용했다고 보면 된다.
Contracting path 는 FCN 과 동일하다.
다만, Expanding path 에서 각 단계에 맞는 downsample (압축 단계의 값들) 들의 값을 concat 한다는 특징이 있다.

Skip connection 을 통해 초반 레이어의 정보 (공간적으로 높은 해상도) 를 뒤쪽 레이어에 전달할 수 있다.
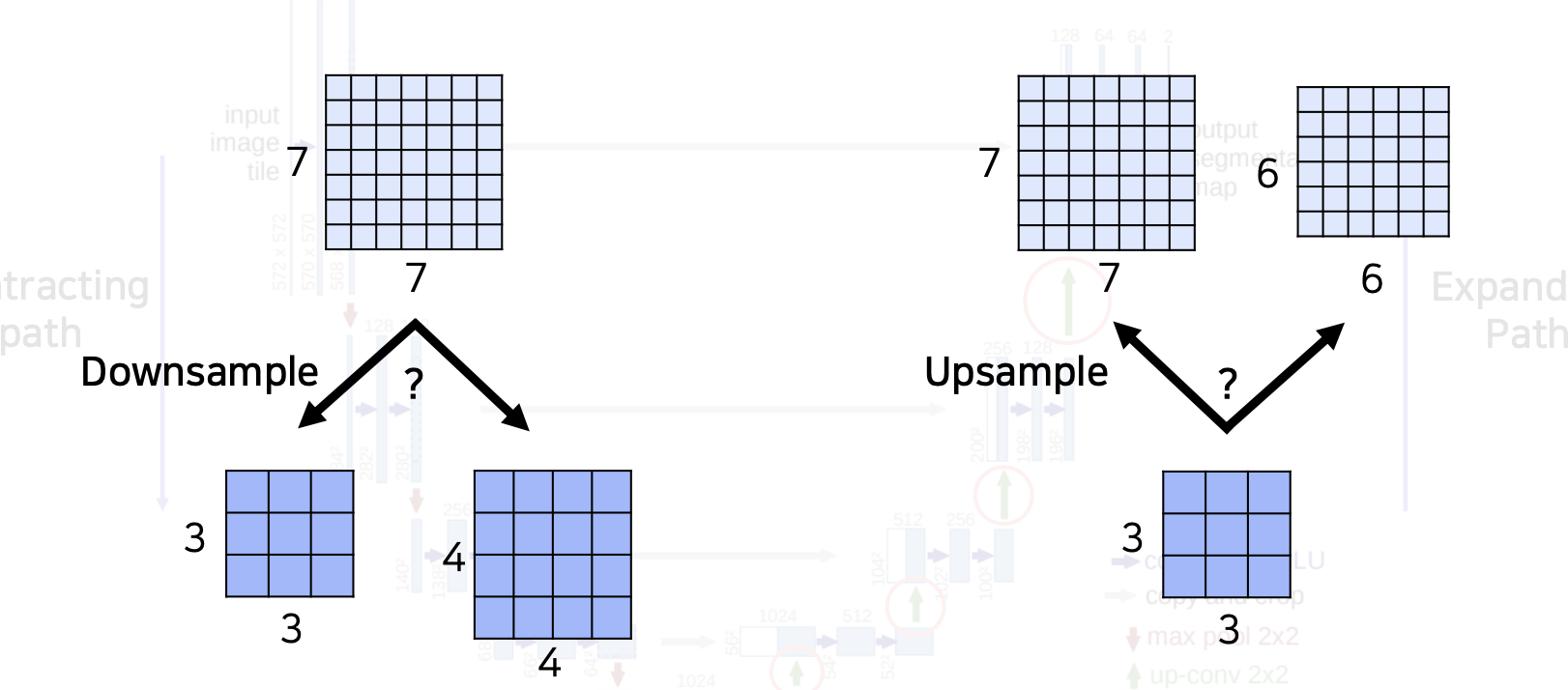
feature map 의 공간 크기가 홀수라면?
concat 을 위해서는 크기가 맞아야 하는데 feature map 의 공간 크기가 홀수면 문제가 생긴다.
downsample 을 할 때 7x7 을 쪼개면 3x3 또는 4x4 가 될 수 있는데 이를 다시 upsample 하여도 7x7 이 되지 않는다.
따라서 홀수 크기를 사용하지 않도록 주의해야 한다.
DeepLab
CRFs 와 Atrous Convolution 을 사용한 모델이다.
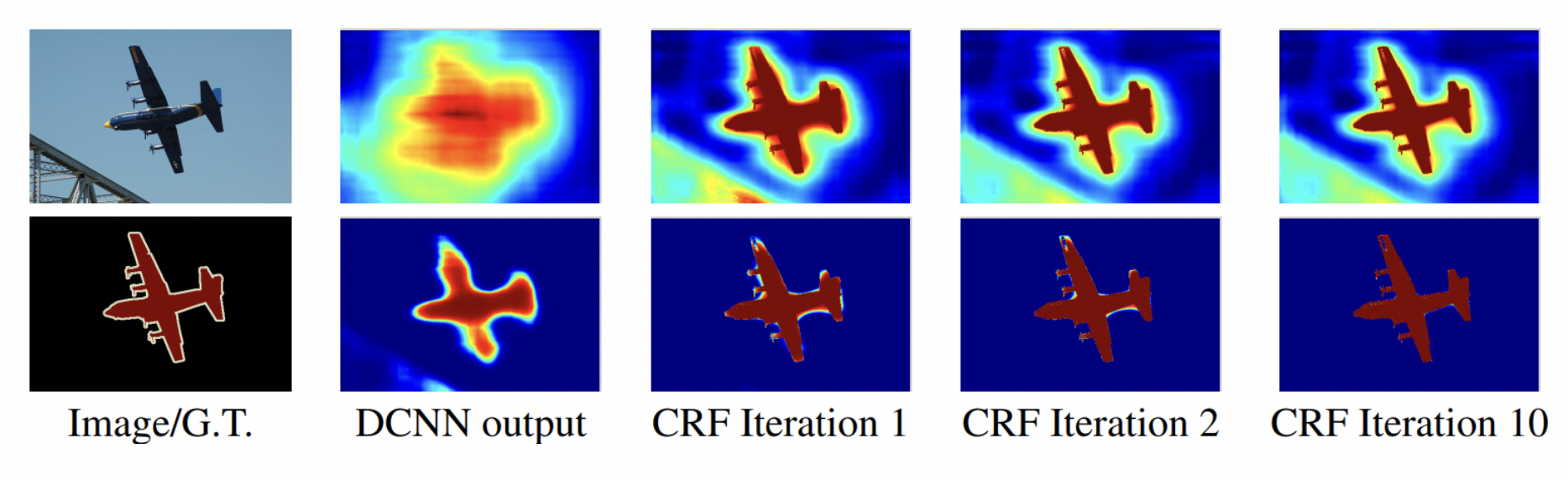
CRFs (Conditional Random Fields)
물체 경계를 잘 찾아내는 방법이다.
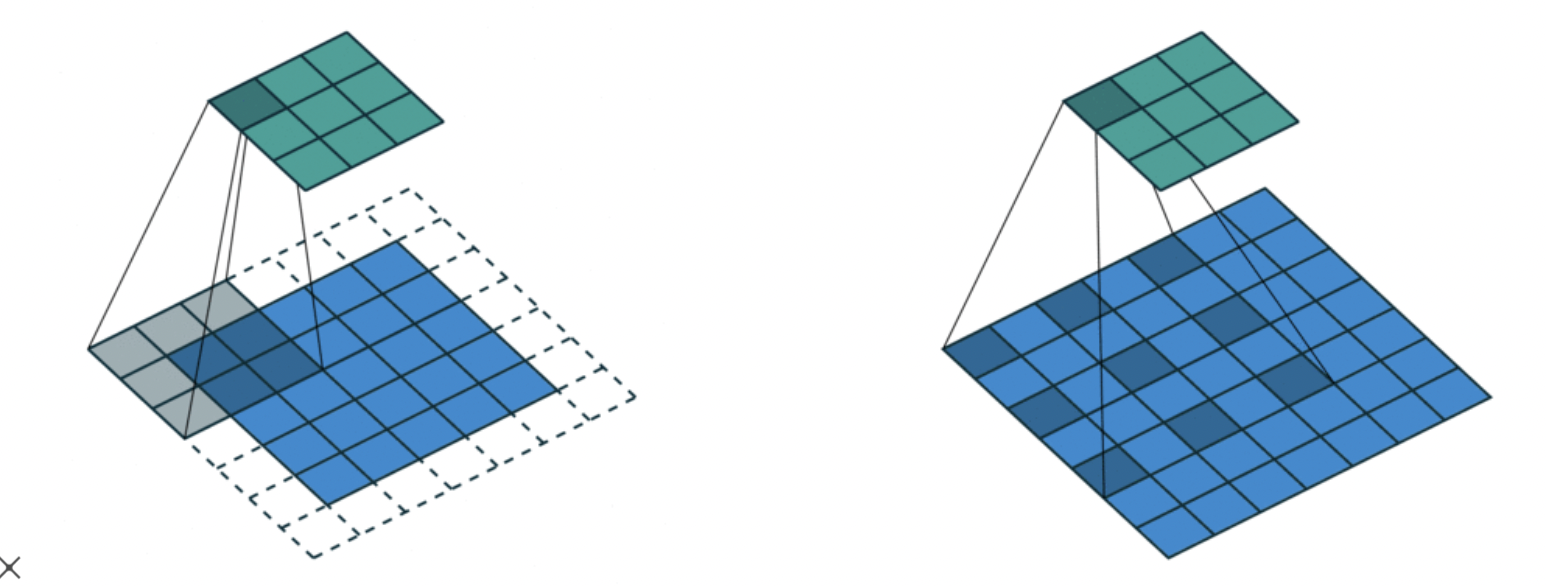
Atrous convolution (Dilated convolution)
convolution 커널 사이에 일정 공간을 넣어줘서 실제 convolution 영역보다 더 넓게 볼 수 있도록 하였다. 더 넓은 영역을 보지만 파라미터는 줄어드는 효과가 생긴다.
아래 사진의 오른쪽 부분과 같이 수행된다.
원래는 3x3 만 보고 convolution 을 하지만, atrous = 1 을 하여 중간 중간 0 을 채워 넣은 5x5 크기를 receptive field 로 사용하여 하나의 점으로 나타내준다.
Depthwise separable convolution
기존과 다르게 depthwise + pointwise 를 수행하여 파라미터를 매우 줄였다.
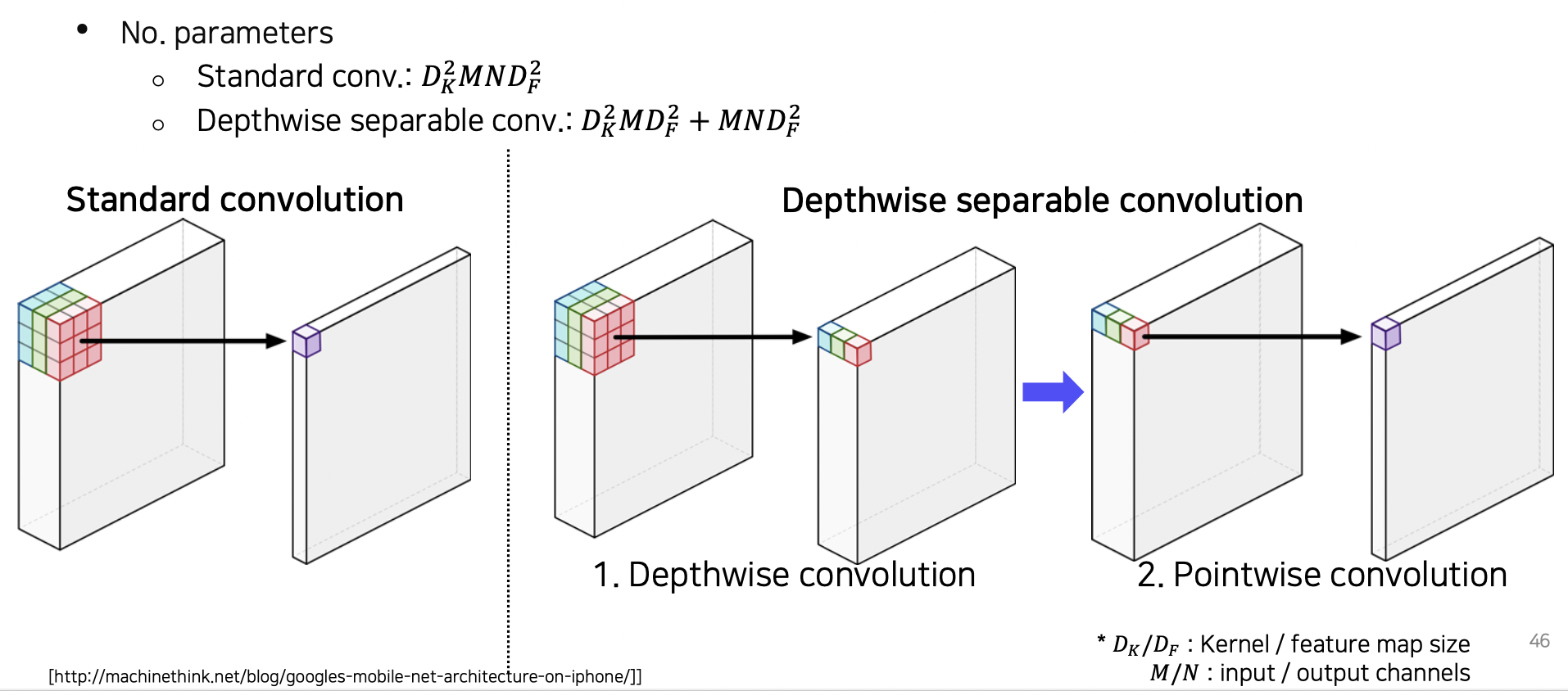
참조
BoostCamp AI Tech
