Sequential Model
-
시퀀셜 모델링은 다음과 같은 이유로 힘듦
-
단어 중간 생략
-
단어 뒤에 생략
-
단어 앞에 생략
⇒ 이런 문제를 해결하기 위해 트랜스포머의 셀프-어텐션 등장
-
Transformer
- 트랜스포머는 어텐션으로만 설계된 최초의 시퀀스 문제 다루는 모델
- 기존 RNN (재귀적 수행) 이랑 달라짐
- 트랜스포머는 이미지 분류, detection 등에도 사용됨
- GPT-3, 달리 등은 셀프 어텐션 사용
- 시퀀스-시퀀스 모델, 주어진 문장을 다른 문장으로 만드는 것, 번역이라면 NMT 모델
- RNN 은 단어 개수대로 모델이 돌아갔다면, 트랜스포머는 인코더, 셀프어텐션 부분은 단어를 한 번에 처리함
- 이해해야 할 것
- N 개의 단어가 어떻게 한 번에 인코더에 처리되는지
- 인코더와 디코더는 어떤 정보를 주고 받는지
- 디코더가 어떻게 문장을 생성해내는지 (이번에는 별로 안 다룸)
Encoder
- 문장 벡터가 한 번에 들어감
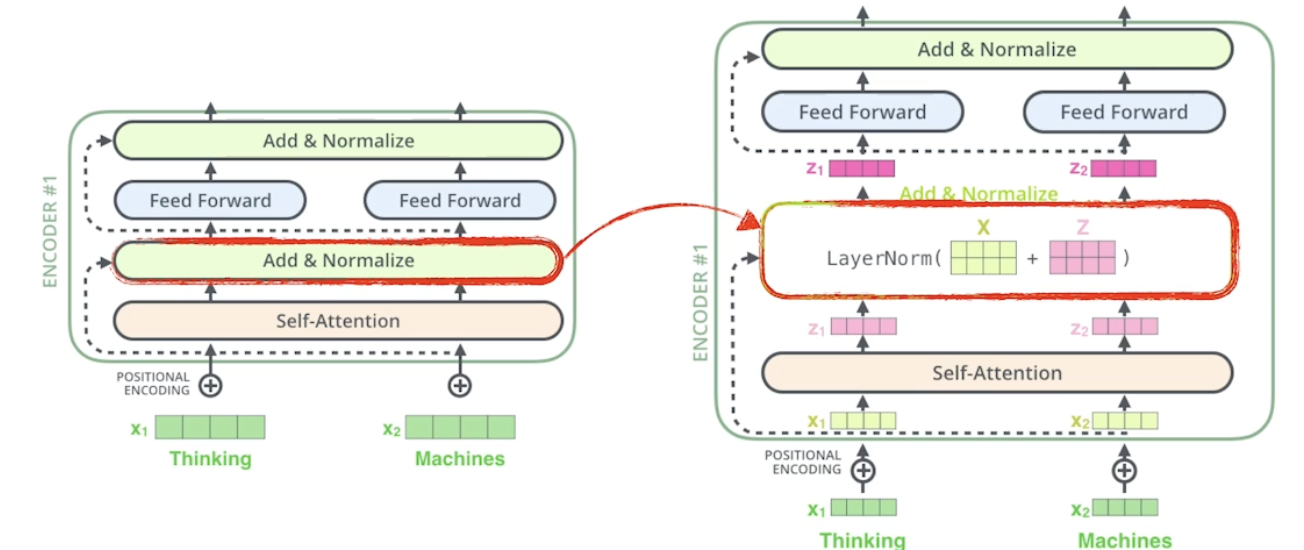
- 인코더는 Self-Attention → Feed Forward Neural Network 로 구성
- 인코더와 디코더에 사용되는 Self-Attention 이 트랜스포머의 핵심

- 세 개의 단어 (각각 벡터) 가 주어지면 셀프어텐션은 벡터가 벡터로 바꿀 때 각각의 단어 x 들을 모두 사용함 → 디펜던시가 있음 (다른 단어들 보는 것)
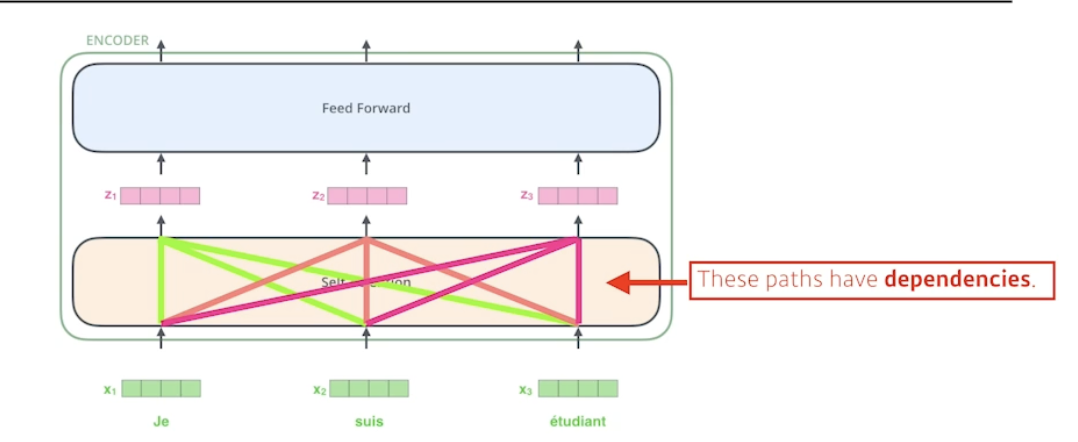
- 피드 포워드는 그냥 원래 MLP 처럼 진행
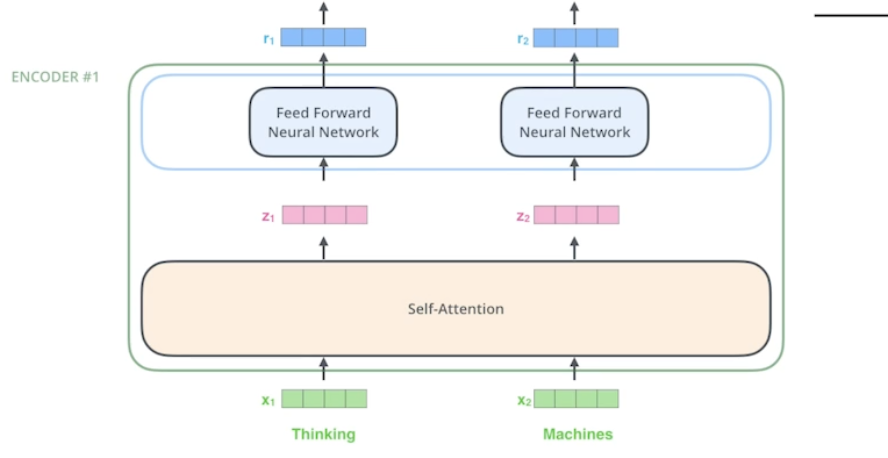
Self-Attention (이 과정 반드시 이해)
- The animal didn't cross the street because it was too tired. 라는 문장에서 it 이 뭘가리키는지 다른 모든 단어들과의 관계성을 따져야함 → The animal 선택
- Thinking 이라는 단어가 주어졌을 때 인코딩하기 위해 세 개의 벡터 Queries, Key, Values 벡터가 사용됨
- 한 단어마다 Q, K, V 가 생성됨

- Thinking 과 Machines 라는 단어들을 인코딩하면 각 단어마다 만들어진 Q, K, V 를 통해 Score 를 생성 → i 번째 단어가 j 번째 단어와 얼마나 유사도가 있는지 qi, kj 를 내적

- i 번째 단어와 나머지 단어들과의 관계를 계산 → Attention
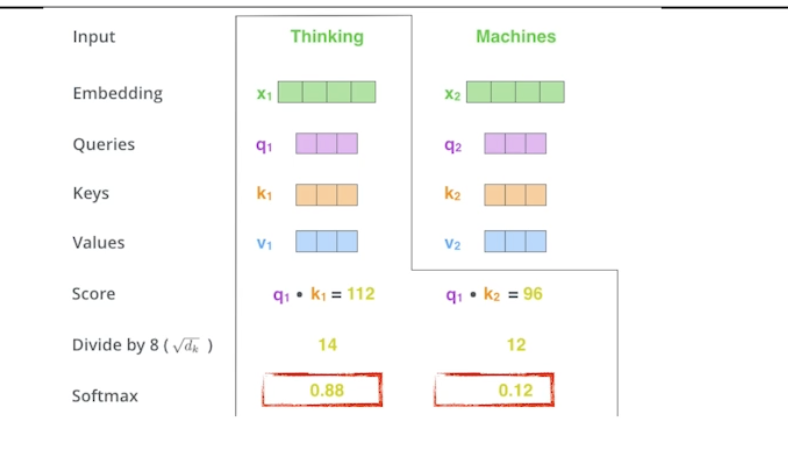
- 스코어가 나오면 스코어에 대해노말라이제이션 (루트dk (키벡터차원) = 8로 나눠줌, 값이 너무 커지지 않게 하기 위해).
- 이후 소프트맥스함 → i, j 단어와의 관계를 확률로 표현
- 이 값을 value 와 곱함, 이후 다 더함 Sum
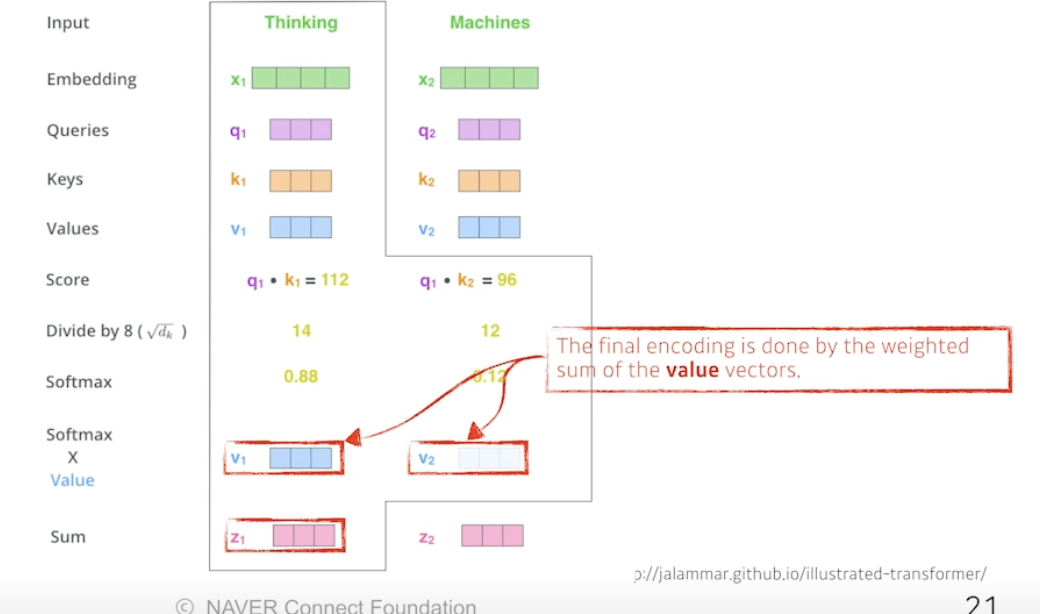
⇒ Value 벡터의 웨이트를 구하는 과정. 각 단어 쿼리와 다른 단어 키 곱하고, 노말라이즈하고, 소프트맥스하고, 밸류곱함
- Q, K 는 차원이 같아야함 (내적), V 는 차원 달라도됨
- 행렬로 보자

- 수식
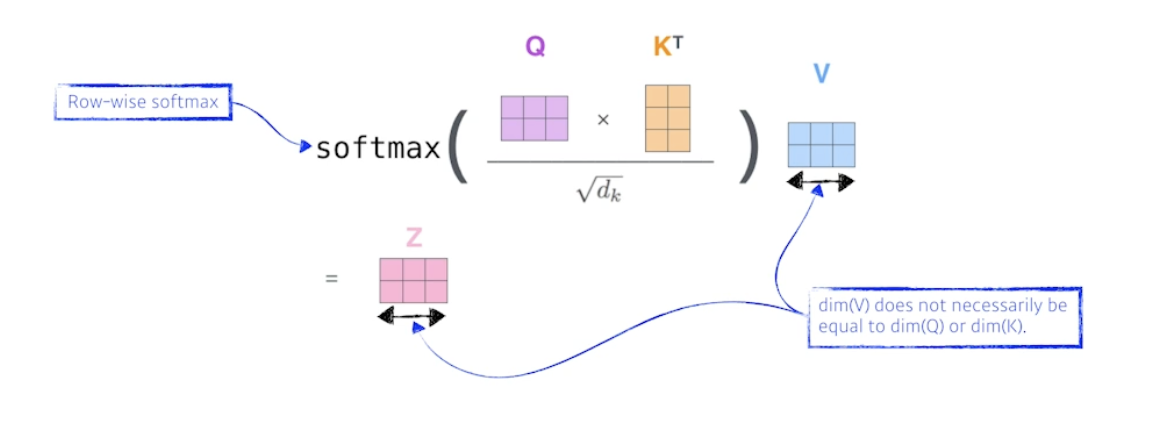
⇒ Single-head Attention
왜 잘될까?
-
어떤 이미지를 CNN 이나 MLP 로 차원을 바꿀 때 인풋 크기가 픽스되면 출력크기도 픽스됨, 필터나 웨이트가 고정되기 때문
-
트랜스포머는 인풋이나 네트워크가 고정되어있더라도, 인코딩하려는 단어와 옆에 주어진 다른 단어들에 따라 출력이 달라질 수 있음 → 훨씬 많은걸 표현할 수 있음
⇒ 많이 표현하기 때문에 더 많은 컴퓨테이션 요구함
- 단어가 1000 개면 1000x1000 (한 번에 처리해야하고, 비용이 N^2 소모됨) 만들어야함. RNN 은 1000 만 필요함
- 즉, 시간이나 메모리는 더 먹지만 더 표현을 잘하고 플렉서블한 모델임
Multi-head Attention
- 싱글 헤드 어텐션을 여러번 함
- 하나의 임베딩된 벡터에 대해 Q, K, V 를 여러개 만듦
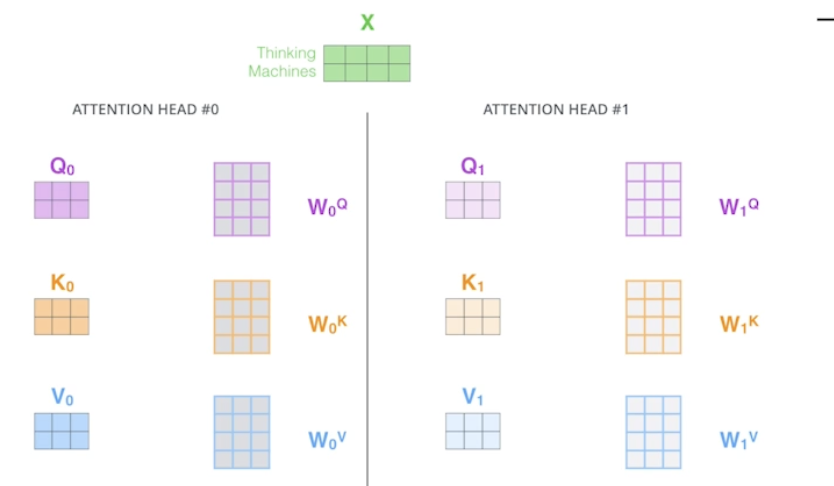
- 한 단어에 대해 만약 8번 셀프 어텐션하면 8개의 인코딩된 결과가 나옴

- 임베딩된 차원과 인코딩된 차원은 항상 같아야 함
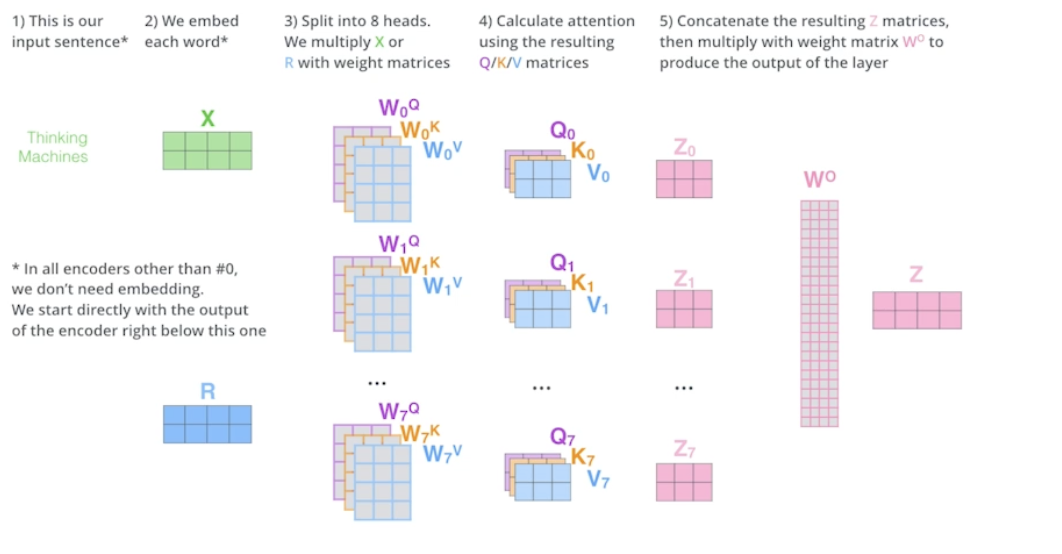
- 실제로는 한 단어의 임베딩 벡터 차원이 100 이라면 10 짜리 10 개로 나눠서 어텐션 진행 → 10 헤드 어텐션
positional encoding
- 모든 단어를 한 번에 인코더에 넣으면 단어들의 순서가 사라짐 → 순서를 기억하게 해줌
- 주어진 입력 값에 어떤 값을 더해줌
- 최근에 사용되는 포지셔널 인코딩 결과
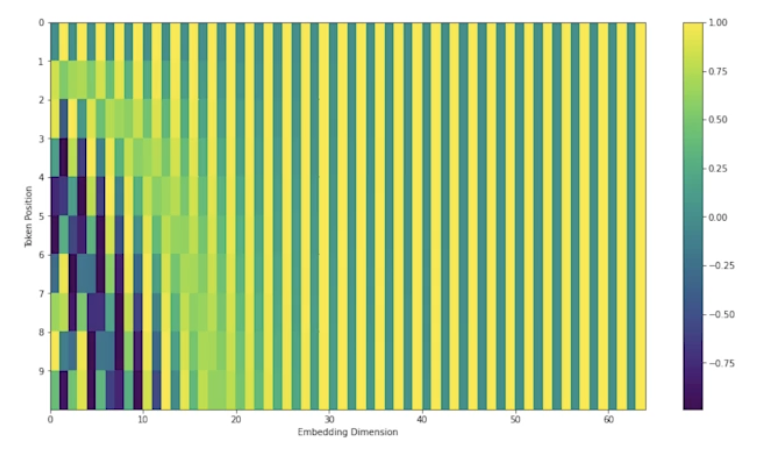
- 왜 트랜스포머는 입력 임베딩에 독릭적으로 진행되는지 생각해볼 것
Decoder

- Encoder 는 주어진 단어를 표현하는 것
- Decoder 는 단어를 생성해내야함
- Encoder 에서 Decoder 로 어떤 정보가 갈까?
- Key, Value 를 보냄
- i 번째 단어 어텐션 만들 때 Qi 와 Kj 곱하고 차원루트 나누고 Vi 더했음
- 인풋에 있는 단어들에 대해 출력하고자 하는 어텐션을 만들려면 인풋 단어들의 K 와 V 벡터가 필요함, 가장 상위 레이어 만듦
- 디코더에서 셀프어텐션 레이어는 마스킹을 함, 이전 단어들만 관여하고 뒤에 단어들에 대해서는 어텐션 하지 않음
- 추정할 때도 마찬가지
Encoder-Decoder Attention
- 디코더에 들어있는 레이어
- 인코더의 K, V 와 출력 단어의 Q 로 어텐션 진행
활용
Vision Transformer
- 원래는 NMT (번역) 문제에만 사용됐는데 이제는 이미지에도 많이 사용
- VIT 라는 논문에서 사용
- 인코더만 활용
- 원래 NMT 는 단어들의 시퀀스가 있었다면, 이미지를 가공해서 맞춰줌 (포지셔널 인코딩도 필요)
DALL-E
- 문장만 보고 사진을 생성해냄
- GPT-3 활용
참조
BoostCamp AI Tech

데이터로 문제를 해결하는 엔지니어를 꿈꿉니다.