[AI : Data representation and problem solving] Autoencoder and VAE

이번 챕터에는 Generative Model의 시초격인 Autoencoder(AE)와 Variational Autoencoder(VAE)에 대해 살펴보고자 한다.
사실 엄밀히 따지자면 Autoencoder는 생성형 모델은 아니지만, VAE를 이해하기 위해선 Autoencoder를 떼놓을 수 없으니 묶어서 이해해보도록 하자.
Autoencoder
어떤 입력 데이터 가 주어졌을 때, 입력 에 대해 동일한 출력 가 나오도록 하는 것이 오토인코더의 기본 개념이다.
입력 데이터는 인코딩 과정을 통해 병목(Bottleneck)이라 불리우는 매우 작은 차원의 네트워크를 통과하게 되고, 인코딩된 데이터는 복원(디코딩)되며 원본에 이미지의 형태가 출력된다.
데이터를 인코딩한다는 것은 데이터를 잠재 공간(Latent space)으로 투영한다는 것과 동일한 의미이다.
위와 같은 과정(입력 데이터 압축 및 복원)을 거치며 모델은 데이터의 특징 표현을 학습하게 되며, 이는 앞서 우리가 살펴보았던 Representation Learning와 동일한 과정으로 이해할 수 있다.
이 과정에서 어떠한 사람의 노력은 필요하지 않다. 따라서 레이블이 없는 데이터를 입력하더라도 모델은 충분히 데이터의 특징 표현을 학습할 수 있다.
즉, AE는 비지도 학습(Unsupervised Learning)에 기반한 방식이다.
이는 과거 대부분의 학습이 Supervised Learning에 기반한 것과 대조적이다.
지도 학습을 위한 데이터셋을 구축(라벨링)하는 것은 어렵고 비용이 많이 드는 작업인 것을 생각해보면, AE가 갖는 이점은 매우 크다고 볼 수 있다.
Variational Autoencoder (VAE)
오토인코더는 개념적으로 매우 우아한 아키텍처이지만, 구조적 단순함으로 인해 오토인코더를 그대로 활용하기에는 다소 부족함이 존재한다.
오토인코더의 대표적인 문제점들은 다음과 같다.
-
배워내는 잠재 공간(Latent space)의 해석이 어렵다.
-
학습된 잠재 공간은 불연속한 점으로 존재한다.
-
복원된 데이터가 원본 데이터에 비해 품질이 떨어진다.
이러한 문제점들을 해결하기 위해 개발된 아키텍처가 Variational Autoencoder(VAE)이다.
VAE는 입력 데이터 에 대한 잠재 변수 의 확률 분포를 인코딩한다.
따라서 잠재 변수의 분포는 연속적인 함수이며, 해석하기가 용이하고, 새로운 데이터 생성이 가능하다.
Latent space : Autoencoder vs VAE
AE
오토인코더의 잠재 공간은 어떠한 제약이 존재하지 않는다. 따라서 학습을 통해 배워내는 특징 표현은 잠재 공간 상의 개별 포인트로 고정된다는 특징을 갖는다.
'8'을 오토인코더에 입력으로 상황을 예시로 들어보자.
인코더는 숫자 '8'을 잠재 공간 상에 하나의 고정된 점(벡터)으로 매핑한다. 이 잠재 벡터는 오토인코더가 학습한 '8'에 대한 표현 방법이며, 디코더는 이로부터 다시 '8'을 표현하게 된다.
즉, '8'은 잠재 공간 상에 한 점으로 투영된다.
VAE
VAE는 잠재 공간 상에 입력 데이터 에 대해서 를 표현하는 잠재 변수 의 연속적인 확률 분포로 나타낸다.
즉, VAE의 인코더는 '8'을 표현하기 위한 확률 분포를 학습하여 잠재 공간 상에 표현한다.
따라서 유사한 종류의 데이터들은 잠재 공간 상 일정한 영역을 형성한다.
Gaussian distribution
가우시안 분포(정규 분포)의 모양은 평균과 표준편차 두 개의 파라미터에 따라 결정된다.
: 분포의 중앙값
: 중앙값을 기준으로 분포의 폭을 결정
이를 2차원 상으로 확장한다면, 축 방향의 평균과 표준편차, 축 방향의 평균과 표준편차 총 4개의 파라미터를 통해 2차원 확률 분포를 표현할 수 있을 것이다.
정리하자면, 오토인코더의 인코더는 입력 데이터의 특징 정보를 벡터로 표현하는 방법을 학습한다.
반면 VAE의 인코더는 입력 데이터를 잠재 변수의 확률 분포로 표현하기 위한 와 를 학습한다. 즉, 데이터의 확률 분포 자체를 학습하는 것이라고 이해할 수 있다.
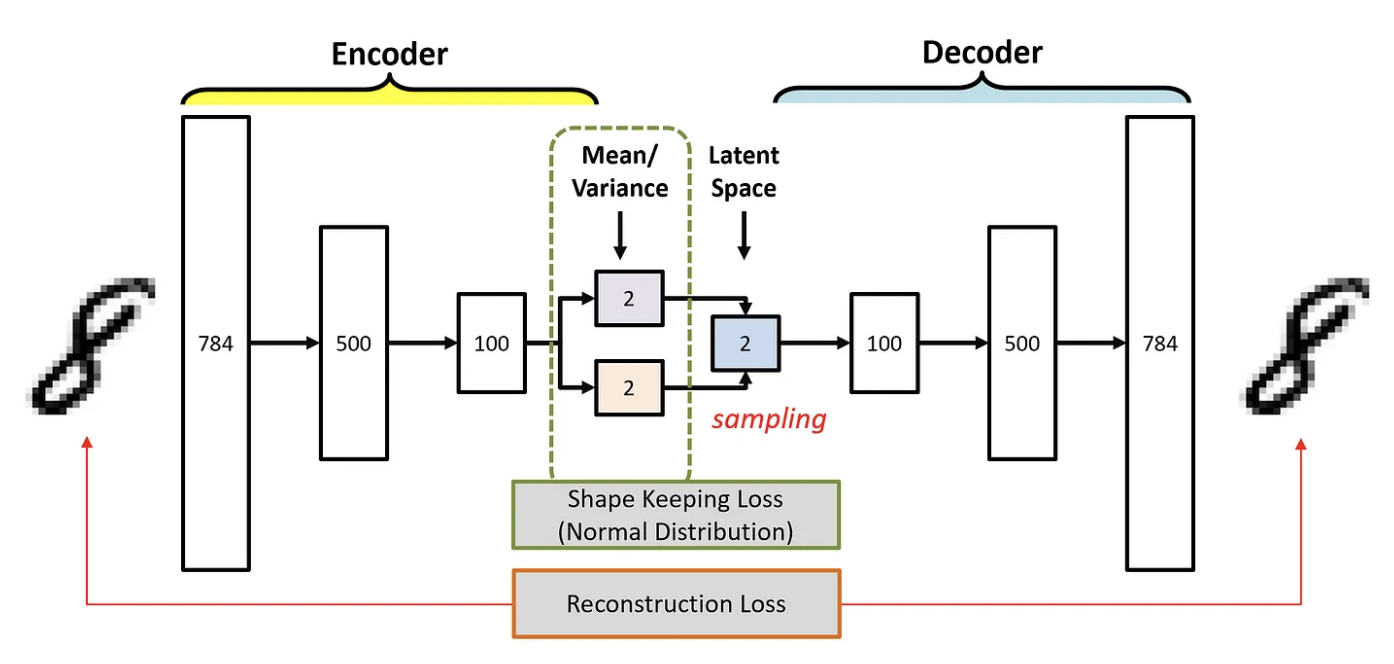
Sampling
디코더는 확률 분포를 직접 활용해서 복원을 수행할 수 없다. 즉, 의미 있는 표현을 담고 있는 벡터를 통해 디코딩을 수행한다.
따라서 디코더는 샘플링이라는 작업을 통해 확률 분포로부터 디코딩을 위한 유의미한 벡터를 추출한다.
즉, 인코더가 학습한 개의 가우시안 확률 분포로부터 샘플링 작업을 통해 하나의 표현 벡터를 얻어내고, 이 값을 디코딩하여 새로운 데이터를 생성해낼 수 있다.
여기서 또 한가지 문제가 발생하는데, 샘플링 과정은 무작위성이 포함되기 때문에 인코더까지 역전파가 제대로 전달되지 않는다.
이를 해결하기 위한 방식이 바로 Reparametrization trick이다.
Reparameterization trick
재파라미터화 트릭은 역전파가 가능하도록 샘플링 과정을 변환하기 위해 다음과 같이 잠재 변수를 표현한다.
여기서 은 가우시안 분포를 따르는 무작위 변수에 해당한다.
위 수식에서 은 고정된 표준 정규 분포에서 생성되며, 이는 인코더의 출력과는 독립적인 값이다. 즉, 모델 학습 과정에서 일종의 상수로 취급이 가능하다.
원래의 샘플링 과정은 무작위성을 포함하기 때문에 와 에 대한 Gradient를 구하기가 어렵지만, 위와 같은 수식으로 변환한다면 를 와 에 대한 함수로서 나타낼 수 있다.
따라서 샘플링의 무작위성은 에 의존하게 되고, 에 대한 Gradient를 구함으로써 역전파가 가능해진다.
에시
이를 이해하기 위해 숫자 '7'을 재구성하는 과정을 예시로 살펴보자.
1) 생성
-
은 가우시안 분포에서 독립적으로 생성된 변수
-
역전파에서 영향을 받지 않는 상수
2) 인코딩
-
숫자 '7' 이미지가 인코더를 통해 잠재 공간으로 투영
-
예를 들어, 숫자 '7' 이미지의 분포는 로 추정
3) 샘플링
-
-
이 는 디코더의 입력으로 활용
4) 디코딩
-
잠재 변수 를 통해 숫자 '7' 이미지를 재구성
-
출력은 원본 이미지와 유사한 이미지
5) 손실 계산 및 역전파
-
재구성된 이미지와 원본 이미지의 손실 (MSE or BCE)를 계산
-
손실 역전파를 통해 모델을 업데이트
위 과정에서 은 매 Step마다 가우시안 분포에서 추출되며, 한 Step 내에서 고정된 값으로 존재한다. 따라서 샘플링을 역전파가 가능하도록 변환(Trick)한다.
이러한 방식으로 재파라미터화 트릭을 통해 샘플링의 역전파가 가능해졌기 때문에, 모델의 안정적인 학습을 지원할 수 있는 것이다.
Log Variance
실제로 코드 구현에 있어서는 수치적 안정성을 확보하기 위해 분산에 로그를 씌운 Log Variance를 활용한다.
로그 분산을 활용할 경우 분산 값은 항상 양수이며, 분산이 매우 작은 경우나 매우 큰 경우 안정적인 연산을 돕기 때문에 매우 유용하게 활용된다.
Loss function
VAE의 손실 함수는 두 가지 구성 요소로 이루어진다.
Reconstrcution loss
재구성 손실은 입력 데이터와 생성된 데이터 사이의 차이로 정의된다.
디코더가 인코더의 잠재 표현을 통해 새롭게 생성한 데이터가 원본 데이터와 얼마나 유사한지를 나타낸다.
이는 일반적으로 평균 제곱 오차(Mean Squared Error, MSE) 혹은 이진 교차 엔트로피(Binary Cross-Entropy)로 정의된다.
여기서는 이진 교차 엔트로피를 기준으로 알아보자.
여기서 는 잠재 변수 로부터 생성된 데이터 의 확률 분포를 나타낸다.
재구성 손실이 작을수록 생성된 데이터가 원래 입력 데이터를 잘 복원한다는 것을 의미한다.
Latent Space Regularization Loss
단순히 이미지만 잘 복원하는 것이 아니라, 우리가 가정했던 잠재 공간의 형태로 실제로 잘 표현하느냐도 중요한 지표이다.
우리는 가우시안 분포를 가정했기 때문에, 인코더가 학습한 와 를 통해 표현되는 확률 분포 가 정규 분포와 얼마나 가까운지를 측정하면 된다.
이를 계산하기 위한 수식이 바로 KL-Divergence이다.
KL 발산은 하나의 확률 분포 가 다른 확률 분포 로 변하는 데 필요한 정보의 양을 측정하는 수식으로, 위 경우 특정 분포 와 사전 분포 사이의 차이를 계산하여 손실 함수로 사용된다.
즉, KL 발산의 값이 작아질수록 인코더가 생성한 잠재 변수의 확률 분포가 가우시안 분포에 가까워진다는 의미이다.
이 두 가지 함수로 VAE 모델의 전체 손실 함수를 정의할 수 있다.
여기서 는 재구성 손실과 정규화 손실 간의 가중치를 조절하는 하이퍼파라미터이다.
결론적으로 VAE를 통해 배워내는 잠재 공간은 우리가 해석 가능한 연속 공간이므로, 와 를 조절함에 따라 어느 영역에 어떤 숫자가 매핑되는지 해석해볼 여지도 존재한다.
