[AI : Data representation and problem solving] CLIP
CLIP
Motivation
-
Vision-Language integration : CLIP은 비전과 언어의 강점을 하나의 통합된 모델로 처리
-
Natural language prompts : CLIP은 자연어 설명을 기반으로 이미지를 이해하고 분류할 수 있음
-
Zero-shot learning : CLIP은 학습 중 해당 작업에 대한 레이블이 지정된 데이터셋을 본 적 없어도 작업을 처리할 수 있음
How?
-
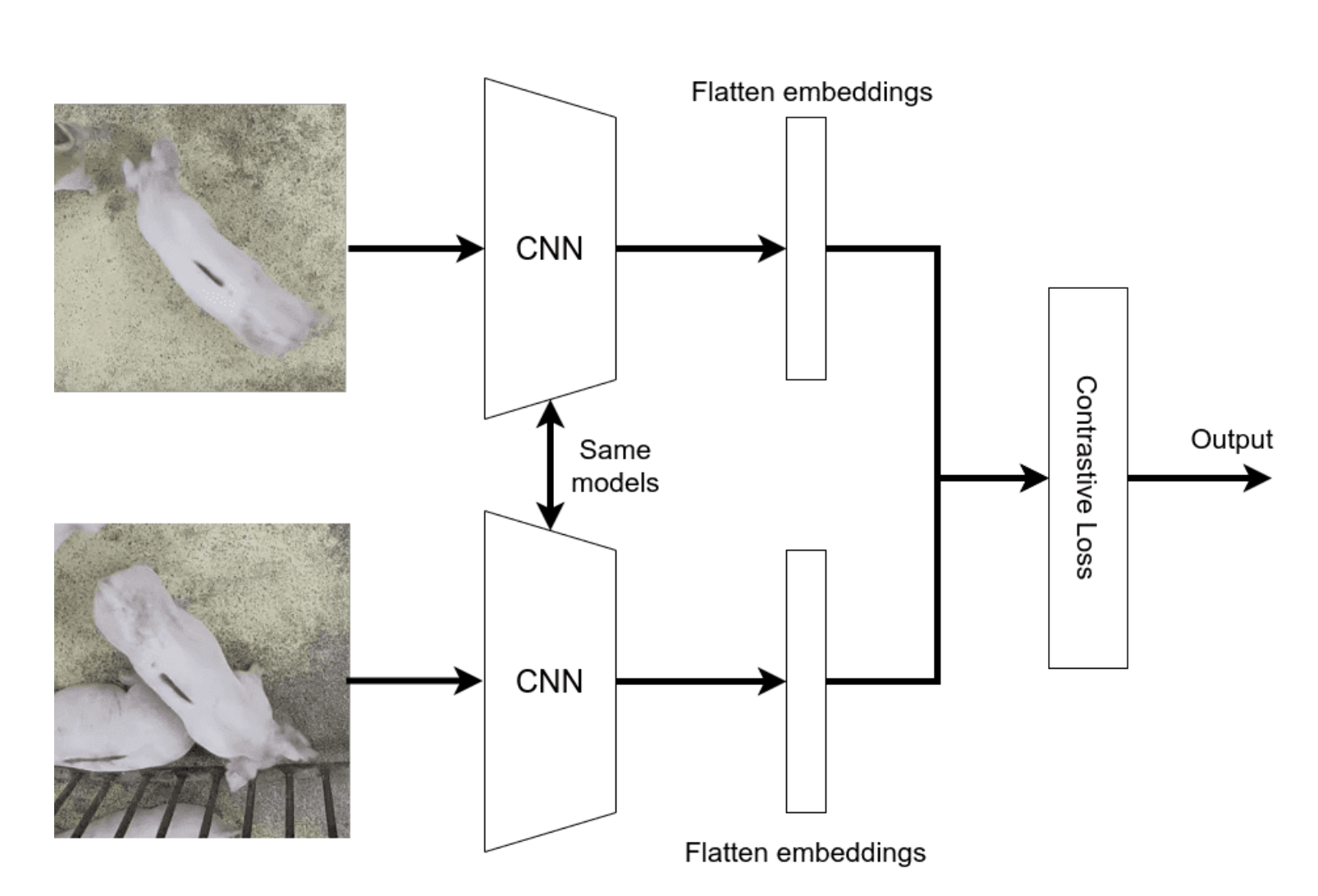
Contrastive learning : 이미지와 해당 텍스트 설명 간 유사성을 최대화하고, 다른 일치하지 않는 텍스트와의 유사성은 최소화하는 대조 학습 활용
-
Embedding space : 이미지와 텍스트를 공유된 임베딩 공간에 매핑하여 형태(텍스트 or 이미지)에 관계 없이 의미적으로 유사한 항목들이 서로 가까이 위치
-
Data augmentation : CLIP은 이미지와 텍스트 모두에 대해 다양한 데이터 증강 기법을 적용하여 모델의 강건성과 다양성을 확보
Results and Benefits
-
Versatillity (다양성) : 동일한 Pre-trained 모델을 다양한 시각 작업에 활용(Backbone model)할 수 있으며, 텍스트 프롬프트만 조정하면 되기 때문에 별도의 미세 조정이 필요 없음
-
Scaling Benefits : 모델 규모가 커질수록 성능이 향상
-
Generalization : CLIP은 학습 방법론 덕분에 학습 중 본적 없는(un-seen label) 시각 작업에도 일반화 성능이 뛰어남

한량 극복 프로젝트