[AI : Data representation and problem solving] Language Model
Language Model
언어 모델(Language Model)이란 주어진 단어 시퀀스에서 다음에 올 단어를 예측하거나, 문장의 구조와 의미를 이해할 수 있는 모델이라고 정의할 수 있다.
예를 들어, "I am going to the"라는 문장이 주어진 경우, 언어 모델은 "store", "park" 등과 같은 단어들이 적절한가 적절하지 않은가에 대한 판단이 가능하다.
규칙 기반 언어 모델 (1950 ~ 1980)
규칙 기반 언어 모델은 사람이 여러 가지 지식(언어학, 심리학, 인지과학 등)과 직관 및 경험에 근거하여 언어 모델을 설계하는 것이다.
예를 들어,
"I have to stop [smoking]"
"I have to stop [to smoke]"
이 두 문장에 대해 어떤 단어 구성이 올 것인가를 문법적 규칙에 따라 정의할 수 있다.
이때 규칙 설계 및 설명을 위해 많이 쓰이던 방식들은 다음과 같다.
-
정규 표현식
-
문맥 자유 문법(CFG)
-
구구조 문법 ...
문맥 자유 문법의 몇 가지 예시는 다음과 같다.
S -> NP VP
NP -> Det N
VP -> V NP
Det -> 'the' | 'a'
N -> 'cat' | 'dog'
V -> 'chased' | 'saw'이 규칙을 통해 "The cat chased dog"와 같은 문장을 생성할 수 있는 것이다.
실제로 이러한 방식으로 구성된 상용 언어 모델은 ELIZA, SHRDLU, LUNAR 등이 있었다.
규칙 기반 언어 모델은 초기 자연어 처리 기술에 중요한 부분을 차지했으며, 특정 문맥에서 매우 정확한 결과를 제공할 수 있었다.
하지만 이러한 모델은 대규모 데이터와 복잡한 언어 구조를 처리하는 데 한계가 있었으며, 특히 모든 언어의 패턴을 사람이 직접 다 구현하는 것은 불가능했기에 적용범위가 매우 한정적이였다.
데이터 기반 언어 모델 (1980 ~ )
데이터 기반 언어 모델은 데이터에서 LM을 얻어내는 방식이다.
데이터를 어떻게 '모델링'하느냐에 따라 매우 다양한 방식이 제안되었으며, 대표적인 아이디어들을 살펴보도록 하자.
우리가 일반적으로 LM에게 기대하는 것들은 다음과 같다.
-
자연스러움 평가 - : A-B-C-D-E라는 흐름이 얼마나 자연스러운가?
-
다음 토큰 예측 - : A-B-C-D-E 다음에는 어떤 토큰이 따라오는 것이 적절할지?
-
의미 동등성 - : A-B-C-D-E는 a-b-c-d-e와 얼마나 유사한가?
N-gram 언어 모델 (1950 ~)
N-gram 모델은 단어의 연속성을 기반으로 주어진 n개의 연속된 단어를 고려하여 다음 단어의 출현 확률을 예측하는 모델이다.
과거에는 n개의 단어까지를 기준으로 Count하는 방식이 주로 사용되었다.
"I have to stop smoking"이라는 문장이 주어졌을 때 예시를 살펴보자.
Unigram (n = 1)
각 단어의 출현 빈도만을 고려하는 방식
p(w) = count(w) / N
각 단어의 빈도("I", "have", "to", ...)를 세어 확률을 계산
Bigram (n = 2)
두 단어의 연속 출현 빈도를 고려
P(w_i | w_{i-1}) = count(w_{i-1}, w_i) / count(w_{i-1})
"I have", "have to"의 빈도 등을 세어 확률을 계산
Trigram (n = 3)
P(w_i | w_{i-2}, w_{i-1}) = count(w_{i-2}, w_{i-1}, w_i) / count(w_{i-2}, w_{i-1})
"I have to", "have to stop" 등의 빈도를 세어 확률을 계산
장점
-
단순성과 효율성 : 구현이 비교적 간단하며, 계산 속도가 빠름
-
현실적인 확률 근사화 : 실제 텍스트 데이터에서 확률 모델을 근사화
-
다양한 응용 : 자동 완성, 음성 인식, 기계 번역 등 여러 분야에 적용 가능
단점
-
데이터 희소성 문제 : n 값이 커질수록 가능한 N-gram의 수가 기하급수적으로 증가하여, 충분한 데이터 확보가 어려움
-
문맥 한계 : n개의 단어만을 고려하기 때문에, 긴 문맥은 반영하지 못함. 즉, 문맥 전체를 고려하여 단어를 예측하지 못함.
-
계산 복잡도 증가 : n이 커질수록 계산 복잡도가 증가하므로, 실시간 처리가 어려움
RNN 기반 언어 모델 (1980 ~ )
RNN은 기본적으로 시계열 데이터를 처리하기 위한 신경망으로, 이전 시점의 정보를 현재 시점의 입력과 결합하여 처리한다.
RNN은 순환 구조를 가지며, 각 시점의 출력과 다음 시점의 입력이 이어져 있다.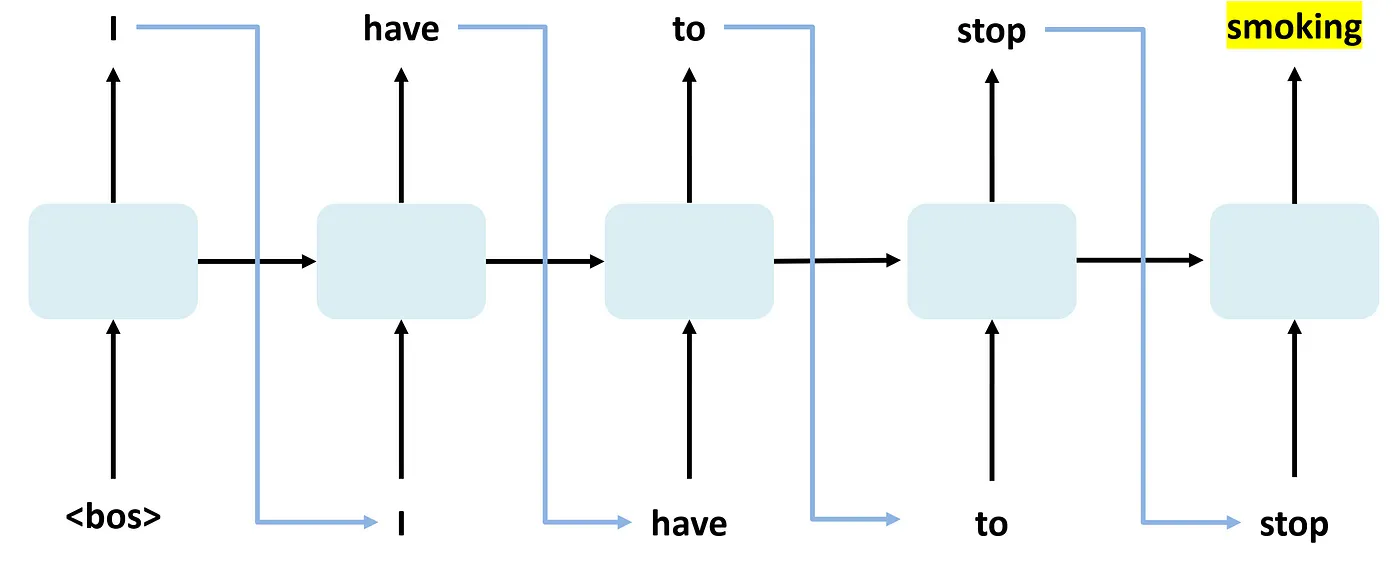
이를 통해 문맥을 고려하여 다음 단어를 예측할 수 있다는 장점이 존재하며, N-gram과 비교하여 더 긴 문맥을 반영할 수 있다.
하지만 RNN 기반 LM의 경우 다음과 같은 명확한 한계점이 존재한다.
장기 의존성 문제
긴 시퀀스 데이터를 처리할 때, 초기 입력 정보가 소실되어 모델이 전체 문맥을 반영하지 못함.
단방향 모델링 문제
RNN은 입력 데이터를 단방향(순차적)으로 처리하므로, 과거의 정보만을 기반으로 현재 상태를 업데이트한다. 이는 양방향 모두의 문맥을 고려하지 못하는 것을 의미한다.
이를 해결하기 위해 Bidirectional-RNN도 설계되었지만, 궁극적인 해결책은 아니다.
RNN + Attention (2015 ~ )
RNN의 구조적인 문제를 해결하기 위해 Attention 메커니즘이 개발되었으며, 특히 Sequence-to-Sequence 형태의 언어 모델에서 긴 문맥을 효과적으로 처리하고, 입력과 출력 간 복잡한 의존성을 모델링할 수 있다.
Attention의 자세한 내용은 이전 챕터에 정리되어 있으니, 해당 부분을 참고해보자.
RNN과 Attention의 조합은 주로 인코더-디코더 구조로 구현된다.
인코더는 입력 시퀀스를 인코딩하여 문맥 벡터를 생성하며, 디코더는 은닉 상태와 Attention 메커니즘을 활용하여 출력 시퀀스를 생성한다.
긴 문맥 처리
Attention 메커니즘을 활용할 경우, 입력 시퀀스의 모든 부분을 고려할 수 있기 때문에 장기 의존성 문제를 효과적으로 해결한다.
효과적인 시퀀스 생성
인코더-디코더 구조와 Attention을 결합할 경우 시퀀스 생성 작업에서 높은 성능을 발휘한다.
유연성
Attention 메커니즘은 입력 시퀀스의 길이에 구애받지 않기 때문에 다양한 길이의 시퀀스를 처리할 수 있다.
위와 같은 장점들로 인해 현재 Attention 메커니즘은 자연어 처리의 핵심적인 기술로 각광받고 있다.
Attention Only (Transformer, 2017 ~ )
오직 Attention만으로 인코더-디코더를 구현하여 Seq2Seq 문제를 해결하는 아이디어가 등장했으며, 이것이 바로 Transformer 아키텍처이다.
트랜스포머는 각 단계에서 Self-attention 메커니즘을 통해 입력 시퀀스의 모든 부분을 처리할 수 있기 때문에 긴 문맥을 효과적으로 반영할 수 있으며, Multi-head-attention 방식을 통해 병렬 처리가 가능해져 계산 효율성도 크게 향상되었다.
병렬 처리
MHA 메커니즘 덕분에 병렬 처리가 가능하여 훈련 속도가 크게 개선
긴 문맥 처리
Self-attention 메커니즘을 통해 입력 시퀀스의 모든 부분을 고려할 수 있어 긴 문맥을 효과적으로 반영할 수 있음
유연성
다양한 길이의 시퀀스를 처리할 수 있으며, 이는 다양한 자연어 처리 작업에 효과적이다.
Encoder-Only or Decoder-Only (2018 ~ )
Transformer 아키텍처는 기본적으로 인코더-디코더 구조이지만, 여기서 한발 더 나아가 아예 Transformer의 일부분(인코더 혹은 디코더)만 사용하는 아이디어가 제시되었다.
-
Decoder-Only : GPT
-
Encoder-Only : BERT
GPT와 BERT에 대한 내용은 이전 챕터에서 자세하게 다루었으니, 해당 부분을 찾아보도록 하자.
