[AI : Data representation and problem solving] Large Language Model - Part 1
Large Language Model (LLM)
어느정도 크기부터 거대 언어 모델이라고 표현할 수 있을까? 우선 저자는 학문적 기준이 아닌 개인적 기준으로 다음 세 가지를 제시한다.
-
개인의 훈련 가능성
-
개인이 접근 가능한 데이터
-
추론 능력의 유무
하나씩 자세히 살펴보자.
개인이 훈련 가능한가?
설명에 앞서, 다음 그림을 보자.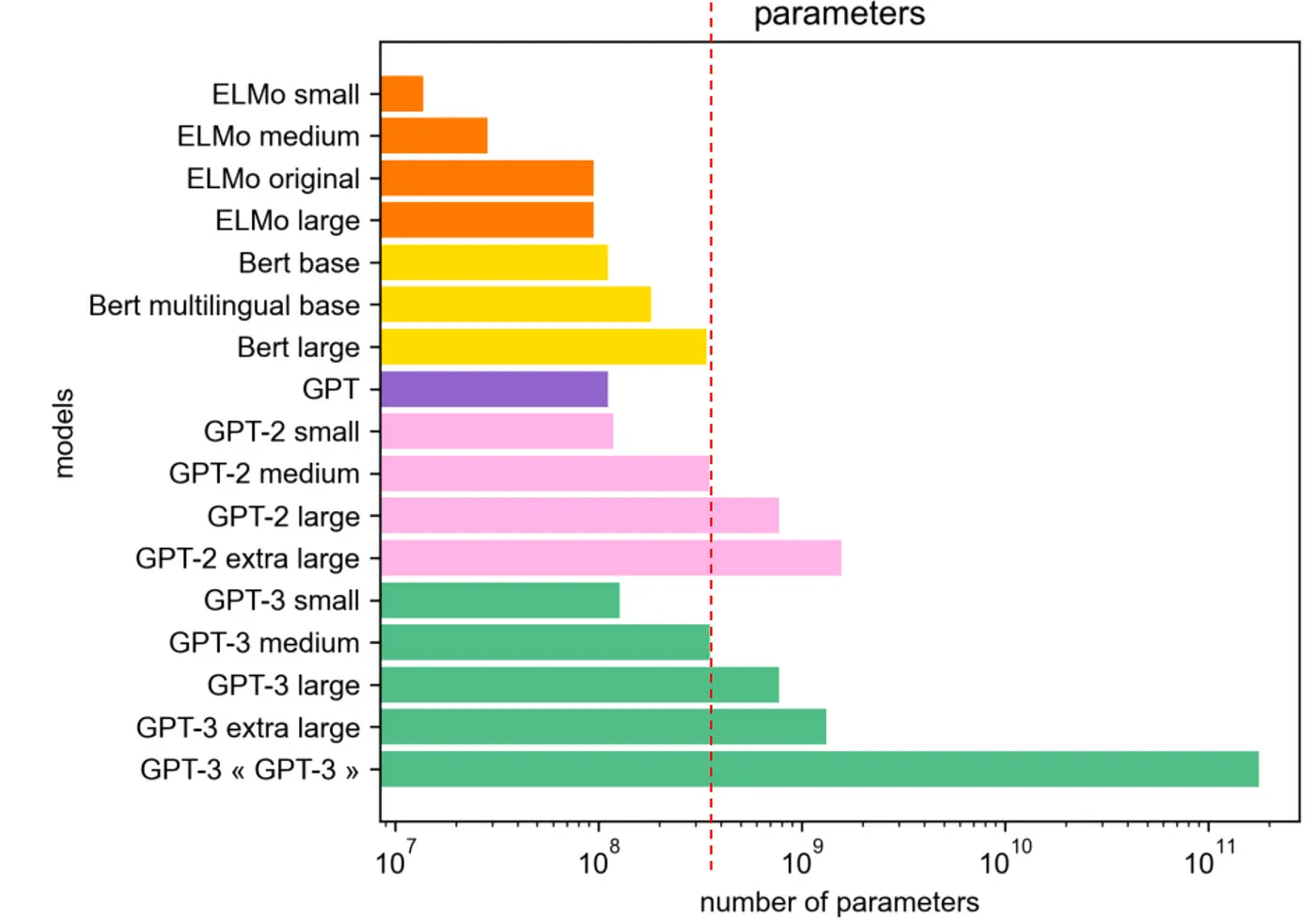
다양한 언어 모델은 꾸준히 크기가 증가하고 있다. 모델이 커질수록 언어 모델링의 성능은 좋아지는 것은 자명한 사실이다.
반면, 개인의 훈련 및 추론 가능성은 불가능에 가까워진다.
일반적인 소비자용 GPU로는 이런 모델들을 훈련하기란 사실상 불가능하며, 특히 GPT-3 정도 크기의 모델을 처음부터 훈련하려면 약 355 GPU-year가 소요된다.
추론을 수행할 때도 당연히 수십 대의 고성능 GPU가 필요하다.
따라서, 개인이 감당할 수 없는 모델 사이즈를 거대 언어 모델의 첫 번째 기준으로 꼽을 수 있다.
개인이 접근 가능한 데이터인가?
언어 모델과 거대 언어 모델들의 훈련에 사용되는 데이터는 차이가 있다.
과거 언어 모델들을 훈련할 때 사용했던 데이터는 모두 공개되어 있기 때문에 개인도 접근하여 얼마든지 활용이 가능하다.
반면, 대부분의 최신 거대 언어 모델들은 일부 공개된 데이터셋도 활용하지만 훈련에 사용된 전체 데이터셋은 비공개로 유지한다.
따라서 만약 어찌저찌 개인이 동일한 환경을 구축하더라도, 동일한 데이터셋을 활용하여 모델을 재훈련하기는 어렵다.
심플하게 생각해보자. 양질의 데이터셋을 구축하는 것은 어려운 문제이며, 양질의 데이터셋은 곧 모델의 성능을 결정한다. 이는 곧 기업의 경쟁력과 연결되기 때문에 양질의 데이터셋을 쉽게 공개하지 않는 것이 기업 입장에서 유리할 것이다.
추론 능력을 가지고 있는가?
GPT-3의 논문에서 "거대" 언어 모델은 자체적인 추론 능력을 가지고 있음을 밝혀냈으며, 이는 거대 언어 모델의 미래에 대한 청사진을 보여주었다.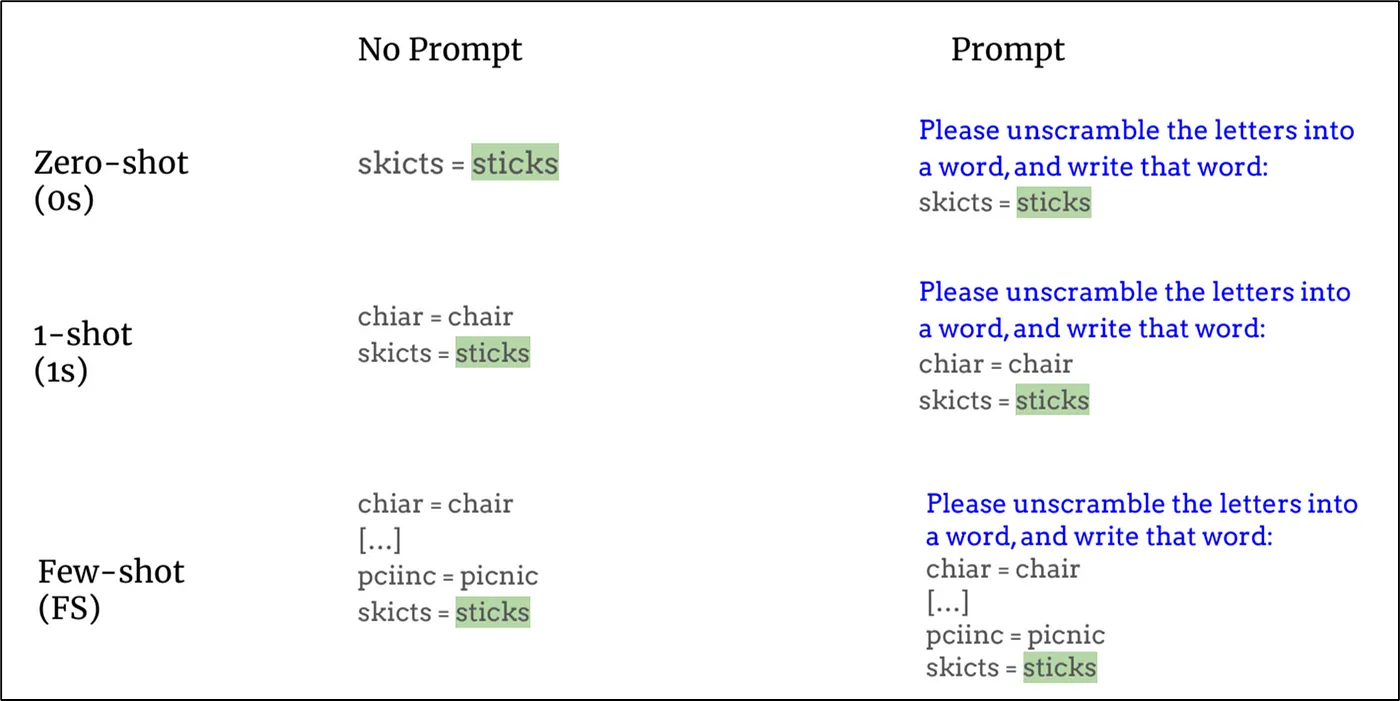
위 사진과 같이 모범 질문/답변 예제를 몇 가지 제공한 뒤 질의를 하게 될 경우, 앞의 예제를 바탕으로 추론하여 가장 그럴듯한 결과를 생성해낸다는 것을 알 수 있다.
이 과정 어디에도 파라미터 업데이트를 동반하는 훈련 과정이 없음에도 불구하고 좋은 결과를 유도할 수 있다는 의미이다.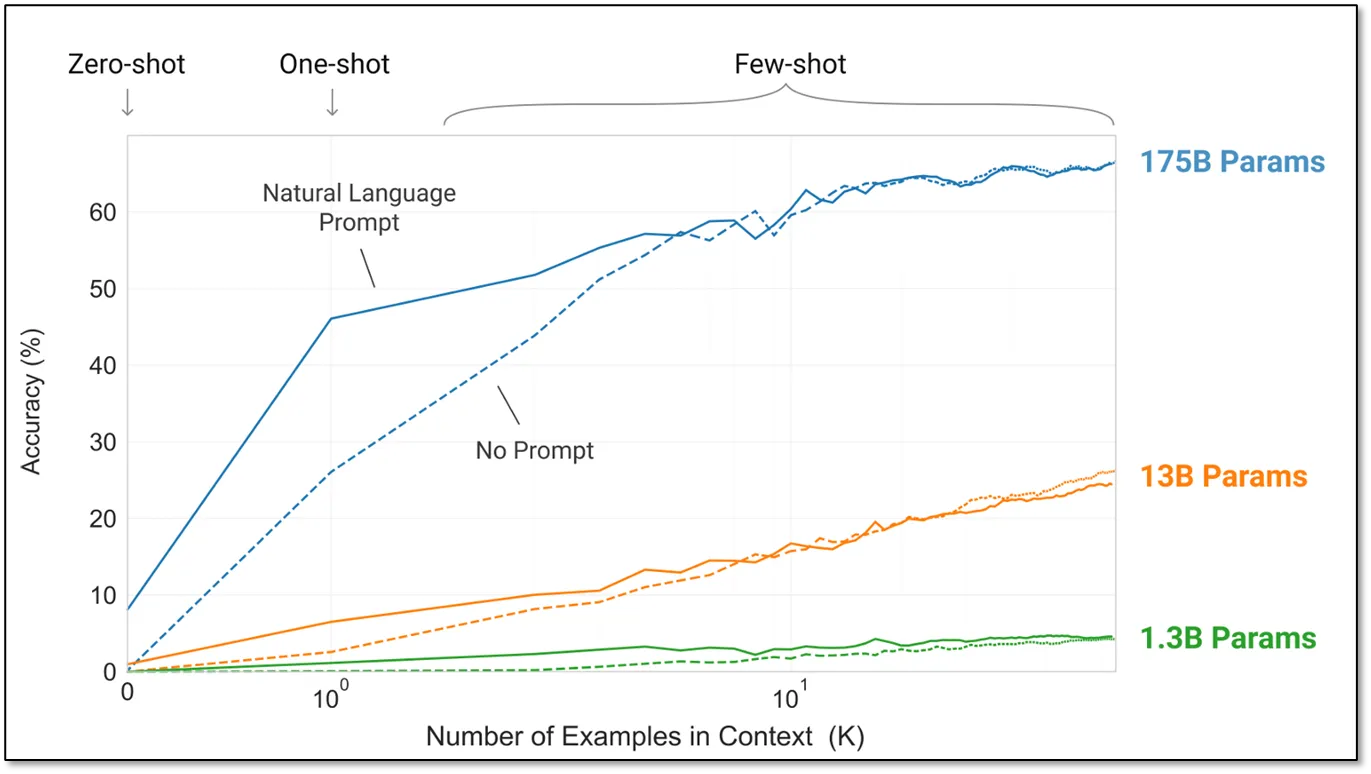
GPT-3는 거대 언어 모델이 few-shot learning과 같은 추론 능력이 있다는 것을 다양한 실험으로 검증하였다.
위 그래프를 보자. 모델의 크기가 작을 때는 아무리 많은 예제를 제공하더라도 성능의 변화가 없지만, 모델이 커지면 커질수록 예제의 개수에 따라 추론 성능이 올라가는 것을 볼 수 있다.
즉, 주어진 정보를 기반으로 좋은 답을 추론해 내는 능력을 언어 모델이 갖추게 된 것이다.
아직 이론적으로 완벽히 밝혀진 바는 없지만, 다음 그림처럼 아마도 13B ~ 175B 사이 어딘가에서 추론 능력을 발아시킬 수 있는 모델의 Critical Point가 존재한다고 추측하는 의견이 많다.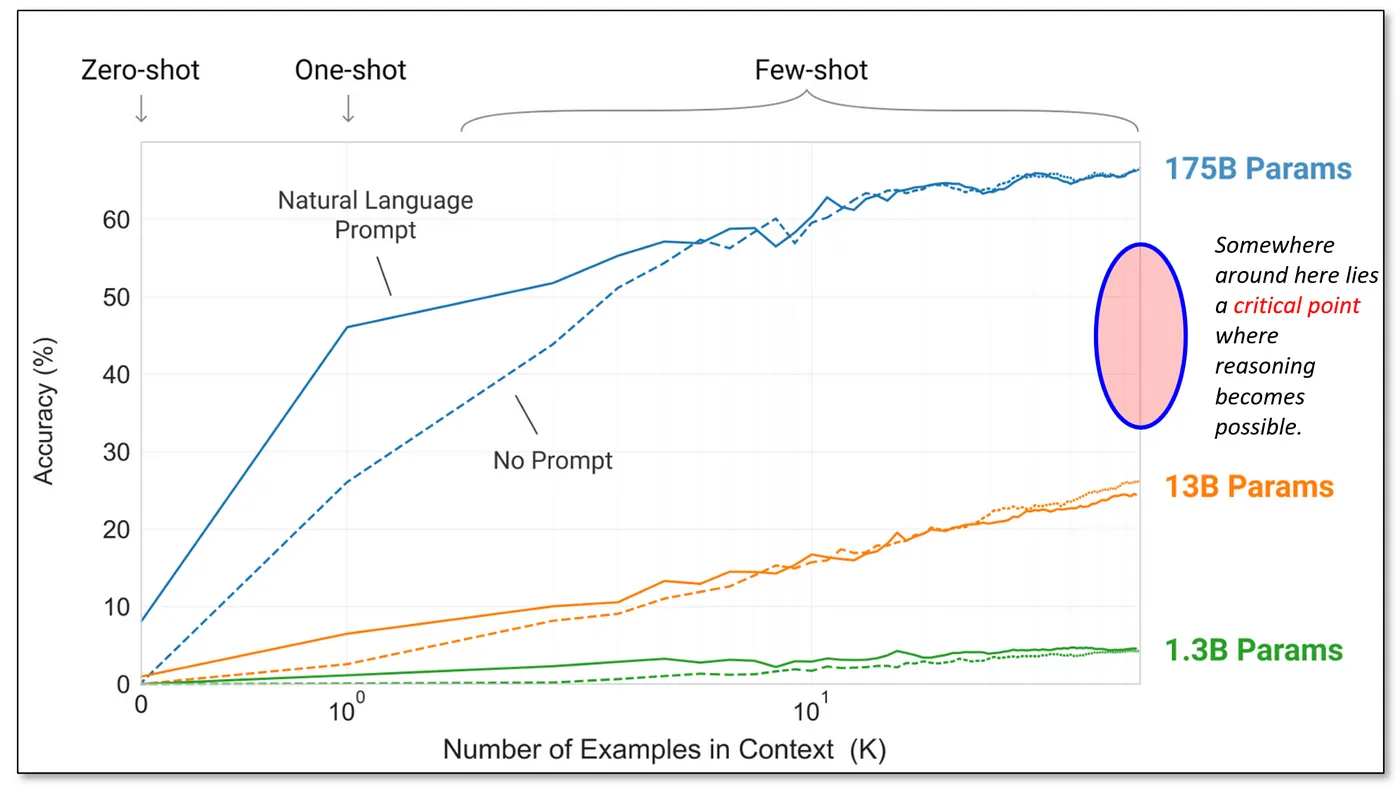
보통 30B ~ 70B의 파라미터를 가질 경우 추론 능력을 갖추게 된다고 추측하고 있다.
이러한 추론 능력은 거대 언어 모델만의 고유한 특징이므로, 대표적인 분류 기준으로 삼을 수 있다.
LLM의 특징
형상-형태적 특징
-
파라미터의 규모
LLM은 엄청난 수의 파라미터를 갖고 있으며, 많은 파라미터는 이 모델들이 방대한 언어 패턴과 지식을 습득할 수 있도록 한다.
-
읽어들일 수 있는 토큰 수
LLM은 한번에 처리할 수 있는 텍스트의 길이(토큰 수)가 매우 크다. 이는 모델이 더 긴 문맥을 이해하고 처리할 수 있다는 의미이다.
기능적 특징
-
고급 추론 능력
LLM은 수학 문제 해결, 코드 이해 및 생성, 상식 추론 등 복잡한 추론 작업도 수행할 수 있는 능력을 갖추고 있다.
-
맥락 이해
단어의 맥락에 따라 표현이 변하는 맥락적 임베딩을 사용하기 때문에, 언어를 더 세밀하게 이해하도록 한다.
-
문명 이해
LLM은 사실상 우리 문명이 만들어 낸 모든 데이터를 학습 대상으로 하기 때문에, 인간 문명의 이해를 기반으로 문화적, 사회적 맥락의 질문에도 적절히 응답할 수 있다.
-
전이 학습
LLM은 대규모 사전 학습이 이루어져 있으며, 특정 작업이나 데이터셋에 대한 미세 조정을 거쳐 모델의 지식을 특정 응용 분야에 맞출 수 있다.
-
Few-shot or Zero-shot 학습
상술했듯이, LLM은 특정 작업에 대한 학습 데이터가 거의 없거나 전혀 없는 상태에서도 추론이 가능하다.
-
상호 작용 및 생성 능력
사용자와 복잡한 맥락적 대화를 나눌 수 있다.
-
콘텐츠 생성
기사, 시, 코드 등 인간과 유사한 텍스트 콘텐츠를 생성할 수 있다.
데이터 측면의 특징
-
학습 데이터의 범위와 다양성
LLM은 책, 웹 사이트, 기사 등 다양한 텍스트 데이터를 활용하여 학습된다. 이러한 대량의 데이터를 통한 학습은 인간과 유사한 텍스트를 이해하고 생성할 수 있도록 한다. 학습 데이터의 다양성 덕분에 모델은 다양한 주제와 맥락에 대해 정확하고 관련성이 높은 응답을 생성할 수 있다.
주의점
-
편향 및 공정성
LLM을 학습하기 위한 데이터들은 인간에 의해 생성된 데이터가 대부분이다. 따라서 학습 데이터에 존재하는 편향(Ex, 범죄자 = 흑인, 간호사 = 여자)을 그대로 학습하고 생성할 수 있다. 이는 공정성과 대표성에 대한 윤리적 문제를 야기할 수 있다.
-
환경적 영향
LLM을 학습하는 데 상당한 GPU 자원이 필요하며, 이는 환경 문제에 대한 우려를 동반한다. GPU를 작동시키기 위해선 막대한 에너지(전기)가 필요하며, 이는 당연하게도 기후 변화에 큰 영향을 미칠 수 있다. 이로 인해 연구자들은 더 효율적인 학습 방법과 적은 계산 자원을 필요로 하는 모델을 개발하기 위해 노력하고 있다.
