[AI : Data representation and problem solving] Large Language Model - part 3
Scalability of model size
우리는 이전 챕터에서 언어 모델의 크기가 증가함에 따라 어느 순간 추론 능력을 갖추게 된다는 것을 알게 되었다.
즉, 같은 데이터를 입력하더라도 크기가 큰 모델일수록 더 추상적인 작업을 수행할 수 있고, 긴 맥락을 처리 가능하다.
그렇다면 앞으로 거대 모델은 얼마나 더 커질 수 있을까?
모델의 크기 증가 그래프와 GPU의 성능 증가 그래프는 사실상 정비례한다.
다음 그래프를 보면, 이는 직관적으로 이해할 수 있다.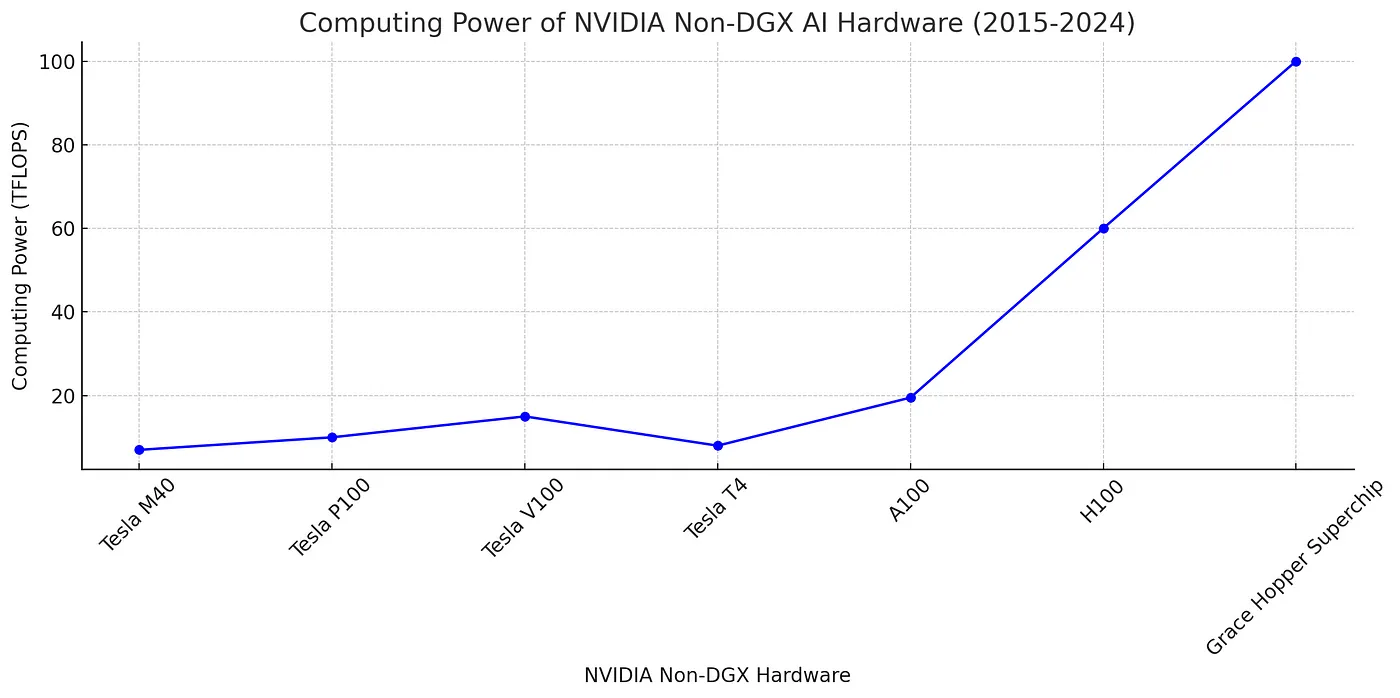
물론 최신 AI들은 GPU로만 작동하는 것이 아니다. 예를 들면, DGX 시스템은 다양한 인공지능 및 딥러닝 작업을 효율적으로 처리할 수 있도록 여러 개의 GPU를 하나의 서버에 통합한 시스템이다.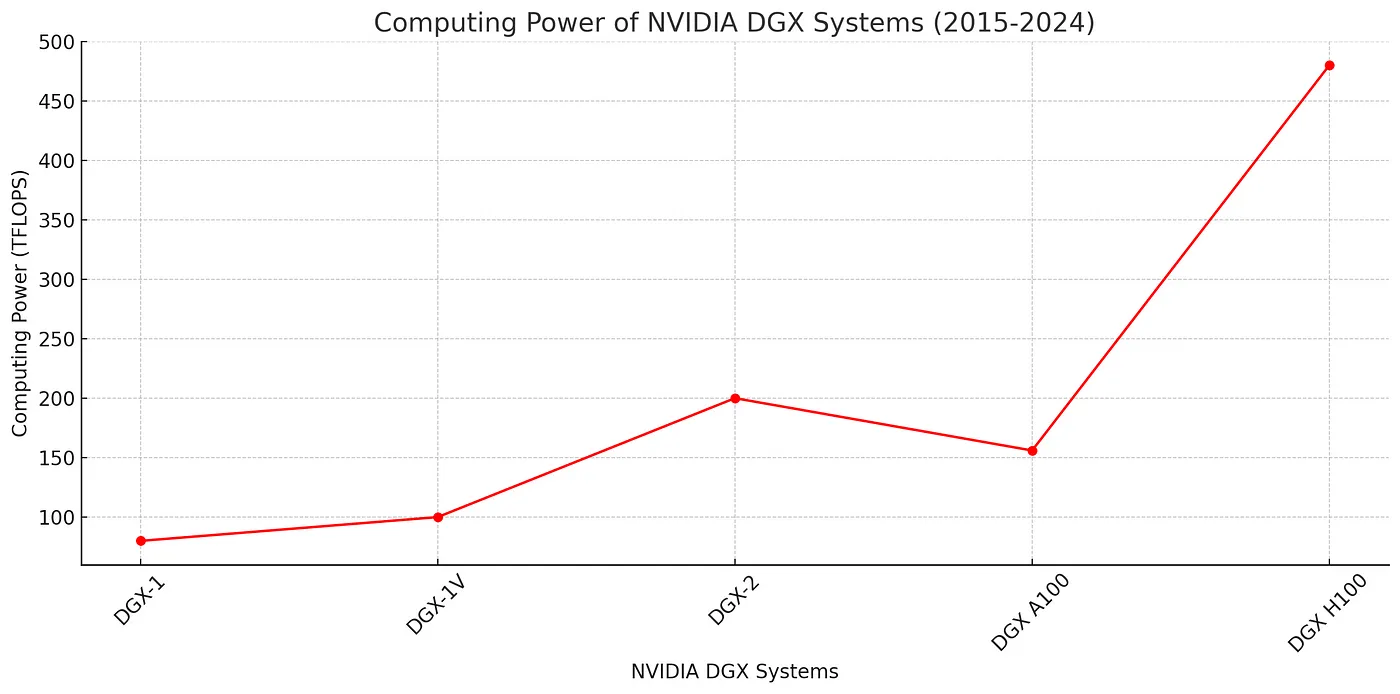
GPU든 DGX든, 현재 컴퓨팅 파워가 기하급수적으로 증가하고 있다는 것은 명확하다.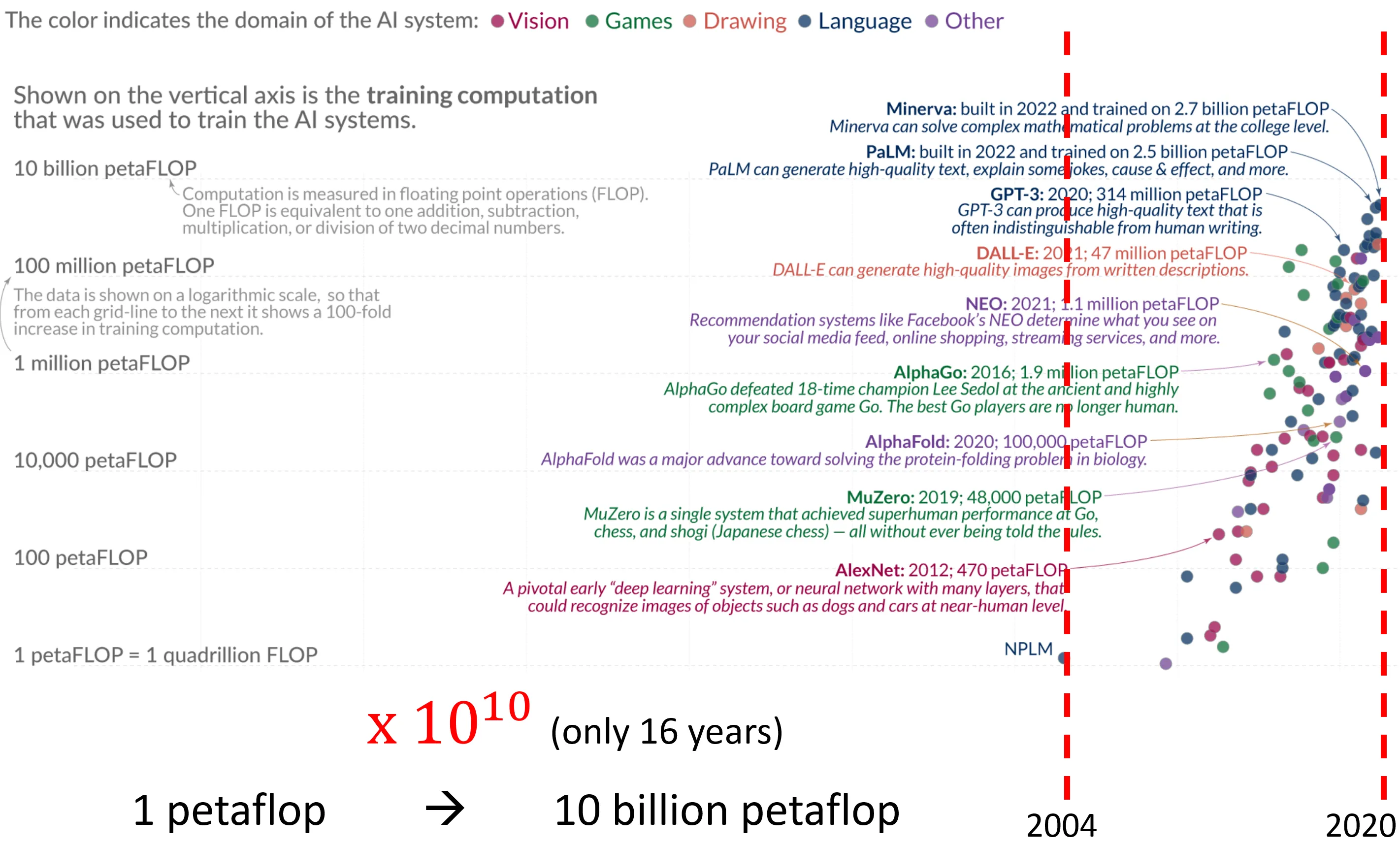
위 그림을 보자. 고작 16년만에 모델의 크기가 배 커졌다는 것을 확인해볼 수 있다.
만일 단순하게 현재의 Scalability 증가 속도가 유지된다고 하면, 2036년의 컴퓨팅 파워는 배 더 커질 수 있다는 것을 의미한다.
현재의 GPT4와 같은 거대 모델에서 배 더 커진 모델이 보여줄 추론, 생성 능력이 상상이 되는가?
Scalability of data
현재의 인터넷은 인류가 쌓아놓은 모든 문명의 집약체이다. 여기에는 수천 년 전 역사적 문서와 예술, 건축 양식 등을 포함하여 현대의 최신 기술 연구에 대한 자료에 이르기까지 인류가 여태껏 축적해온 지식과 경험을 총망라한 방대한 데이터베이스이다.
즉, 일종의 인류 문명의 아카이브라고 볼 수 있다.
이 방대한 데이터를 통해 학습한 거대 언어 모델은 결국 인간 문명을 그대로 배워냈을 것이라고 추측해볼 수 있다.
따라서 LLM이 생성해내는 가장 그럴듯한 무언가는 우리 문명에서 일어날 법한 일에 가까울 것이다.
이러한 이유로 저자는 LLM을 "문명 모델"이라고 표현한다.
즉, LLM은 단순히 언어를 처리하기 위한 도구가 아니며, 문명에서 일어날 수 있는 모든 일들을 예측, 추론, 생성할 수 있는 컴퓨팅 모델이라는 것이다.
예를 들어, LLM은 역사적 사건을 재구성하거나, 현재의 사회적, 경제적 데이터를 기반으로 미래를 예측할 수 있으며, 문학 작품 창작도, 과학적 연구를 돕는 일도 가능하다.
더더욱 중요한 점은, 인류 역사상 이렇게 넓고 정확하게 문명을 개관하고 모델링할 수 있는 도구를 가져본적이 없다는 사실이다. 우리는 현재 새로운 문명 모델이라는 도구를 처음 손에 쥐게 된 것이다.
따라서 LLM은 인류에게 문명 모델을 활용하여 앞으로 어떤 혁신을 이끌어낼 수 있을지, 어떻게 인류에게 도움이 되는 방향으로 발전시킬 수 있을지에 대한 고민이 필요하다는 점을 시사한다.
