[AI : Data representation and problem solving] Large Language Model - part 2
LLM을 활용한 문제 해결
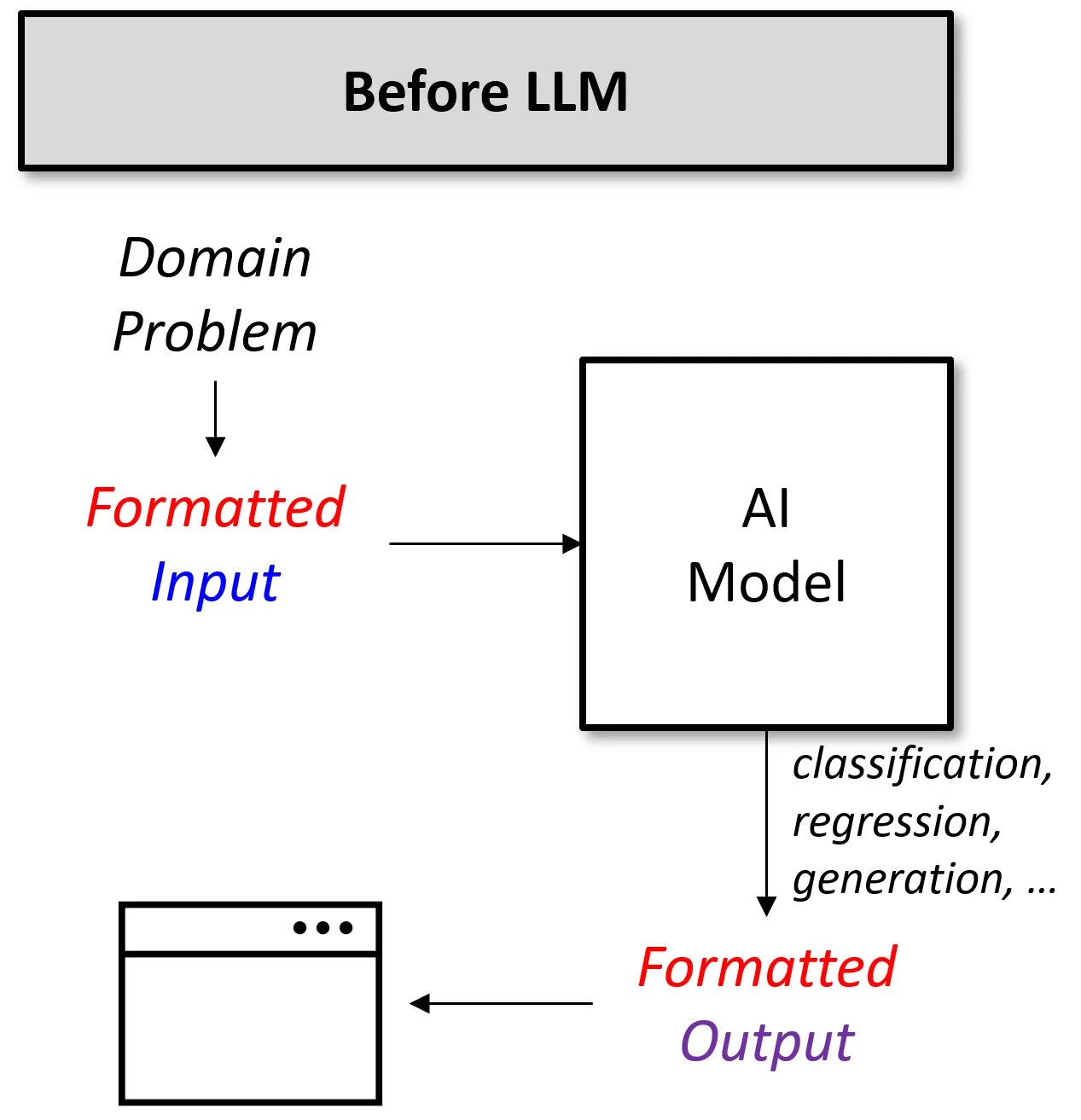
LLM 이전 AI
간단한 감성 분석 모델을 설계한다고 생각해보자. 일반적으로 다음과 같은 절차를 따를 것이다.
-
감성의 종류 정의
사용자가 감성의 종류를 정의
-
충분한 감성 데이터를 수집하고, 각 데이터에 대해 태깅을 수행
데이터를 수집하고, 각 데이터에 대해 수작업으로 감성을 태깅
-
NLP 모델 선정
사용할 NLP 모델을 선택
-
데이터를 활용한 미세 조정
태깅한 데이터를 활용하여 선택한 NLP 모델을 파인 튜닝
-
모델에 입력 데이터 전달
감성 분석을 수행할 데이터를 모델에 입력
-
출력 벡터를 해석
모델이 출력한 벡터를 해석하여 각 감성 클래스에 해당하는 확률값을 계산하여 최종 감성 클래스 결정
-
최종 서비스 구축
최종적인 서비스 형태로 구축
LLM의 등장 이전 AI 모델을 통해 감정 분석 작업을 수행하고자 한다면, 위와 같은 과정을 거쳐야 했다.
안정된 성능을 얻기 위해 훈련 데이터도 충분히 모아야 하고, 모델링 작업도 거쳐야 하며, 특히 입력과 출력을 기존 모델의 포맷에 맞춰야 한다.
즉, 문제 해결을 중심으로 모델을 설계하는 것이 아니라 모델의 입출력 형태를 중심으로 데이터 파이프라인을 구성해야 한다.
따라서 LLM 등장 이전에 AI 모델을 활용하기 위해선 모델이 잘할 수 있는 방식으로 문제와 데이터를 정의해주어야 했다.
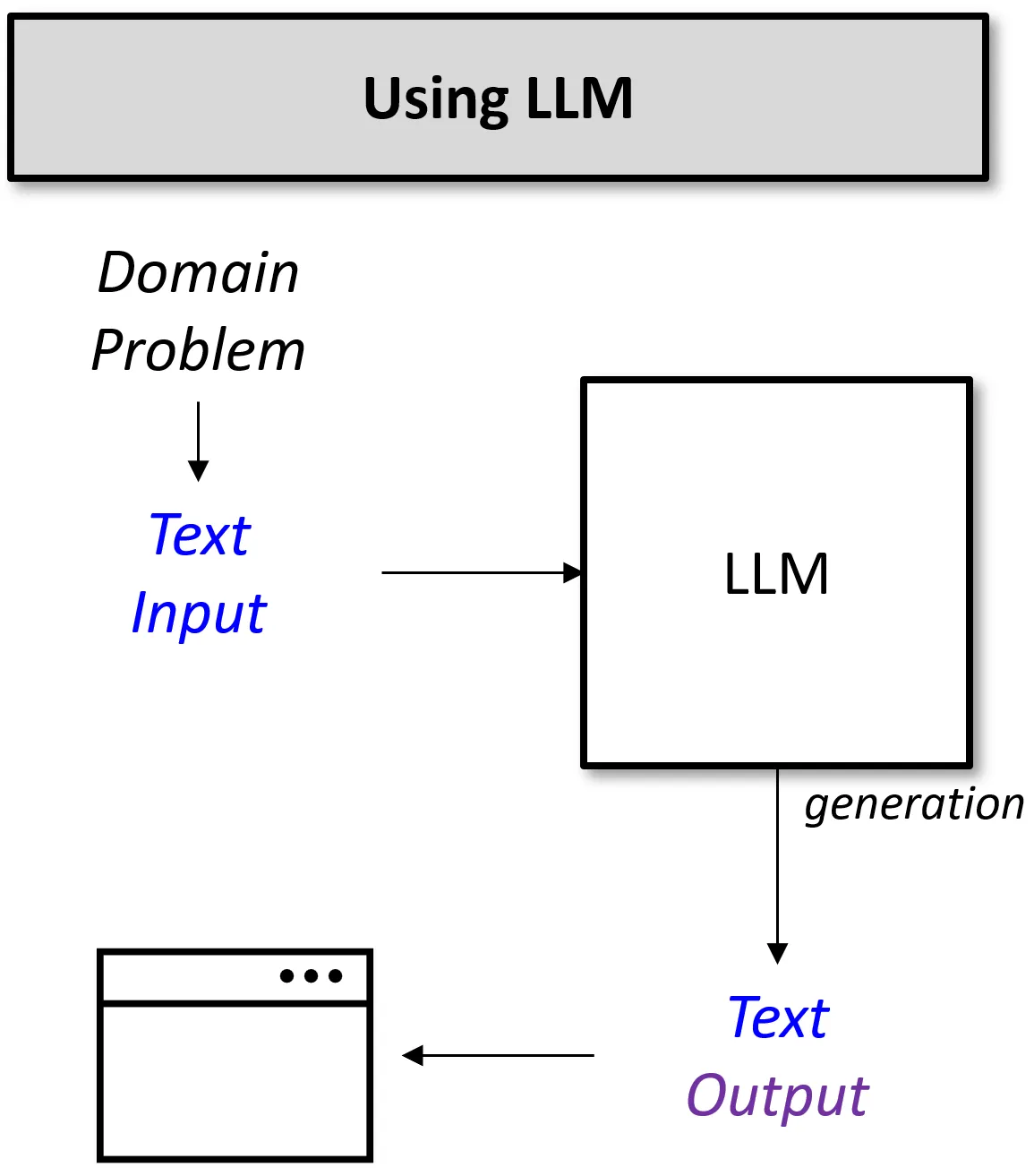
LLM 기반 AI
LLM은 이러한 문제를 매우 단순화시킬 수 있다. LLM을 활용하여 감정 분석 작업을 풀어낸다고 생각해보자.
-
감성 분석 문제를 정의
예를 들어 사용자가 텍스트를 입력하면, 그 텍스트의 감성을 분석하여 결과를 출력하는 것으로 문제를 정의
-
사전 훈련된 LLM 모델을 선택
-
모델에 데이터 입력
텍스트 데이터를 약간의 프롬프트 엔지니어링을 통해 모델에 입력한다.
예를 들어,
"정말 다시 보고 싶은 영화입니다."라는 문장의 감정을 분석하고 싶다면"다음의 문장을 {긍정, 부정, 중립, 객관}이라는 4개의 카테고리로 분류해줘. 문장 = '정말 다시 보고 싶은 영화입니다.'"와 같은 텍스트 프롬프트로 전달한다.
-
모델 출력 해석
모델이 출력한 텍스트를 적절하게 해석하여 감정을 분류
-
최종 서비스 구축
이처럼 LLM을 활용한다면, 복잡한 전처리와 모델 선택, 파인 튜닝 과정 없이도 원하는 작업을 수행하는 모델을 손쉽게 설계할 수 있다.
모든 과정을 통합된 하나의 모델로 처리 가능하므로, 개발자와 사용자 모두에게 부담을 크게 줄여준다.
가장 큰 장점은 입력과 출력이 모두 '텍스트'로 통일되어 있다는 것이다. 입력과 출력 포맷을 맞추는 작업은 생각보다 매우 복잡한 작업이다. (필자도 경험해보았다...)
before LLM vs after LLM
LLM이 문제를 해결하는 방법
이제 생성형 LLM이 다양한 문제를 어떻게 통일된 텍스트로 처리할 수 있는지에 대해 알아보도록 하자.
Decoder-Only 모델 훈련
GPT와 같은 Decoder-Only 언어 모델은 다음과 같은 방식으로 훈련된다.
- Decoder 입력 데이터를 준비한다.
-
예 :
<s>, A, B, C여기서 <s>는 문장의 시작을 의미한다.
- Decoder 출력물-정답을 준비한다.
- 예 :
A, B, C
-
Transformer를 통해 feed-forward 과정 수행
-
각 Time-step별로 예측 결과 Symbol과 출력 Symbol이 맞는지 확인한다.
예를 들어, <S>가 들어간 time-step에서는 A가 생성되며, A가 들어간 time-step에서는 B가 생성되어야 한다.
이런식으로 각 time-step별 손실값을 계산해서 누적 및 학습이 진행된다.
이를 도식화하면 다음과 같다.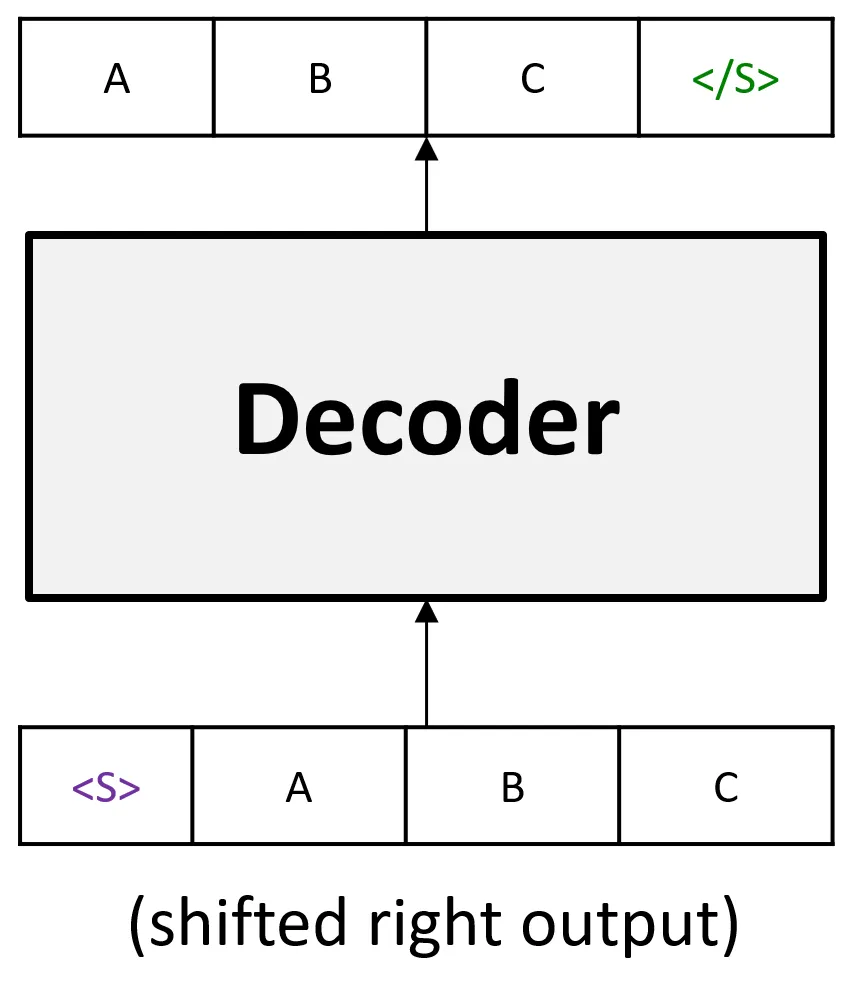
실제로 이 훈련이 진행될 때 총 4번의 확률 모델링이 발생한다.
또한 Decoder 훈련 과정에서는 Masked Attention 기법을 통해 각 Time-step에서 미래 정보를 확인할 수 없도록 한다.
즉, 출력 심볼 'A'를 생성할 때는 '<S>'만 입력으로 처리되고, 출력 심볼 'B'를 생성할 때는 '<S>, A'가 입력으로 활용된다.
P(A | <S>)
P(B | <S>, A)
P(C | <S>, A, B)
P(<\S> | <S>, A, B, C)
이런식으로 총 4개의 확률 모델링을 통해 앞의 내용을 바탕으로 뒤에 이어질 내용의 생성을 위한 최적화가 진행된다.
이를 좀 더 확장해서 생각해보자. 언어 모델은 기본적으로 문장을 완성시킬 수 있도록 훈련된다.
즉, 입력으로 주어진 문장의 앞 부분에 대해 가장 그럴듯한(Likelihood) 뒷 부분을 생성하는 것이다.
이를 조금 더 확장해서, 문단을 완성시킨다고 생각해보자.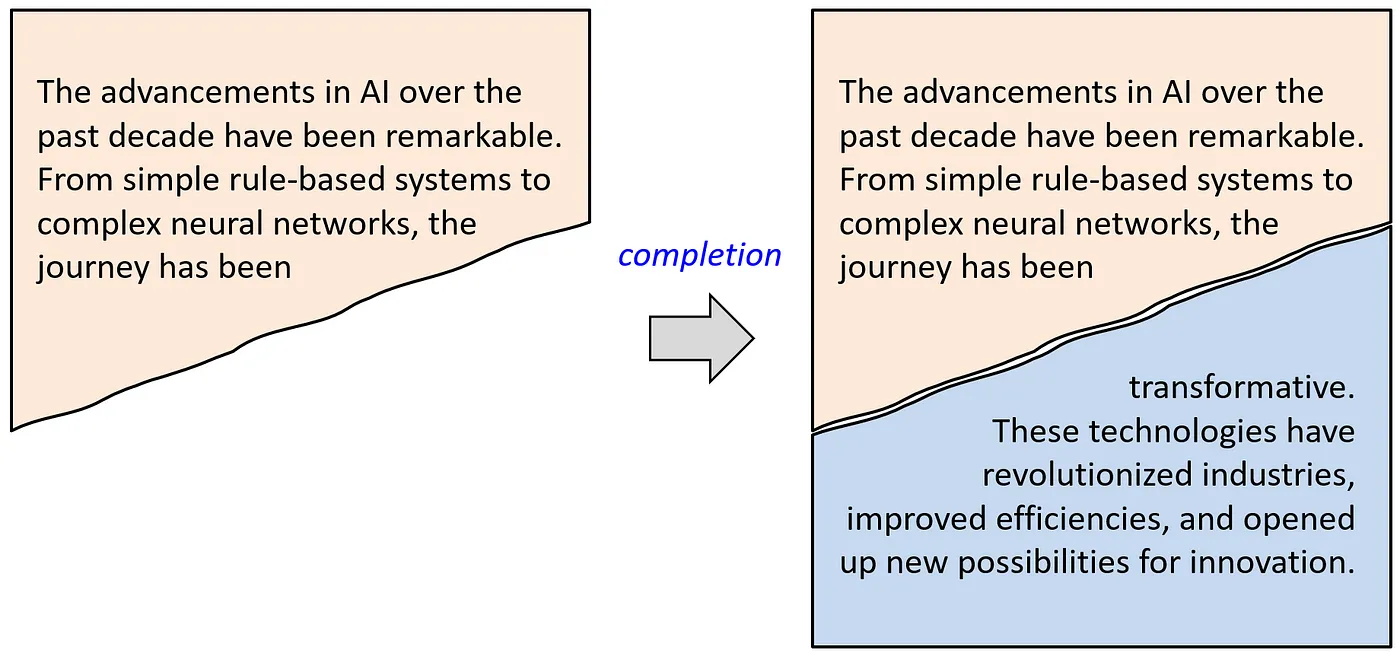
문장을 완성하는 메커니즘과 문단을 완성하는 메커니즘은 완벽하게 동일하며, 단지 입력의 스케일(토큰의 수)만 커졌을 뿐이다.
이를 일반화해보면, 입력의 스케일을 단순히 키우기만 하더라도 페이지 완성, 챕터 완성, 책 완성, ...과 같은 더 큰 Task들도 자연스럽게 해낼 수 있다고 유추해볼 수 있다.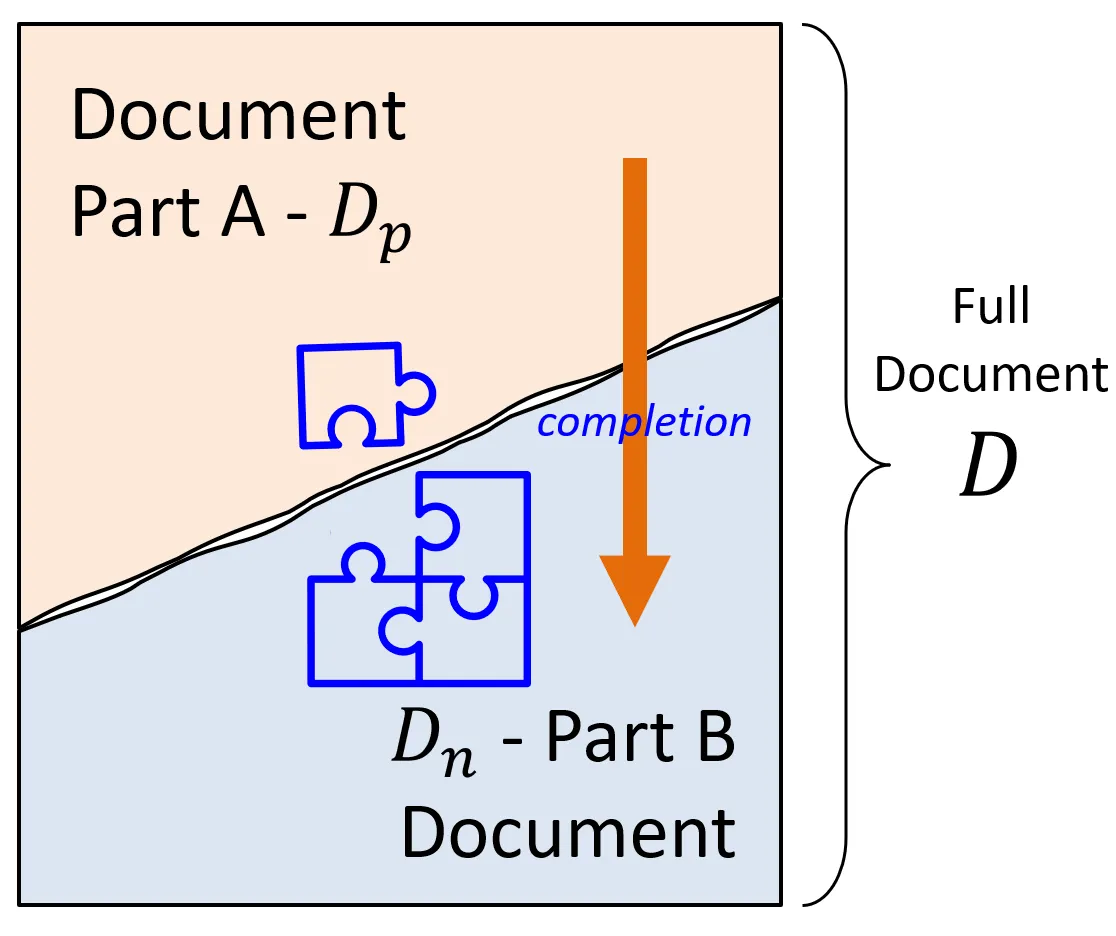
저자는 LLM을 다음과 같이 정의한다.
"LLM은 Document의 한쪽 조각에 가장 잘 어울리는(=가장 그럴듯한) 나머지 한 조각을 만들어 내는 것을 수행하는 엔진이다."
즉, LLM은 입력의 앞 조각을 기반으로 뒷 조각을 완성하는 작업을 수행할 뿐, 그 이상도 그 이하도 아니라는 것이다.
작곡을 한다, 소설을 쓴다, 코드를 작성한다, ... 와 같은 작업들도 마찬가지로 실제 LLM이 문제를 해결하는 방법은 근본적으로 모두 동일하다.
따라서 LLM은 아주 커다란 스케일의 데이터를 통해 학습되어 세상에 존재 할 법한 것을 생성하는 "자동 완성 기계"에 불과하다고 이해할 수 있다.
