[AI : Data representation and problem solving] Embedding : Data to numbers
어떤 형태의 데이터든, 컴퓨터가 이해하기 위해선 숫자로 변환하는 과정이 반드시 필요하다.
이는Encoding, Embedding, Feature extraction, Vectorization와 같이 다양하게 표현되며, 결론적으로 모두 Data to numbers의 의미를 갖는다.
Data to Numbers는 크게 학습 기반 방법과 비학습 기반 방법으로 나눌 수 있다.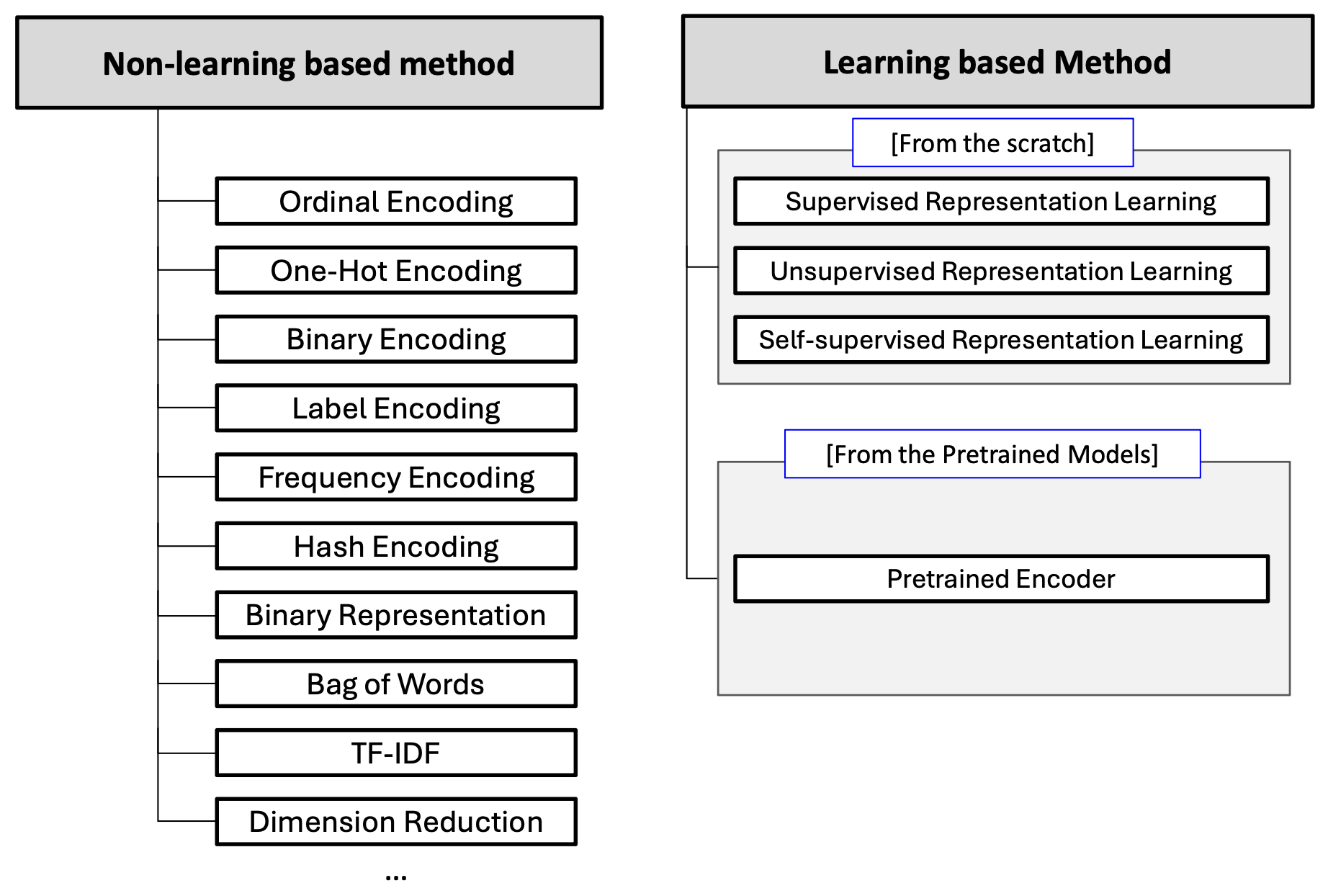
Non-learning based methods
비학습 기반 방법은 주로 사람의 직관, 빈도수 등을 기반으로한다.
-
복잡한 매개변수를 필요로 하지 않는 통계 기반 기법에 해당
-
컴퓨터가 데이터를 효율적으로 처리할 수 있도록 하는 것을 목표로 함


Bag-of-words
텍스트 데이터를 숫자로 변환하는 데 널리 사용되는 방법 중 하나이다.
이는 문서나 문장을 '단어의 가방(단어들의 집합)'으로 취급하여, 문서 내 단어의 출현 빈도를 기반으로 벡터를 생성한다.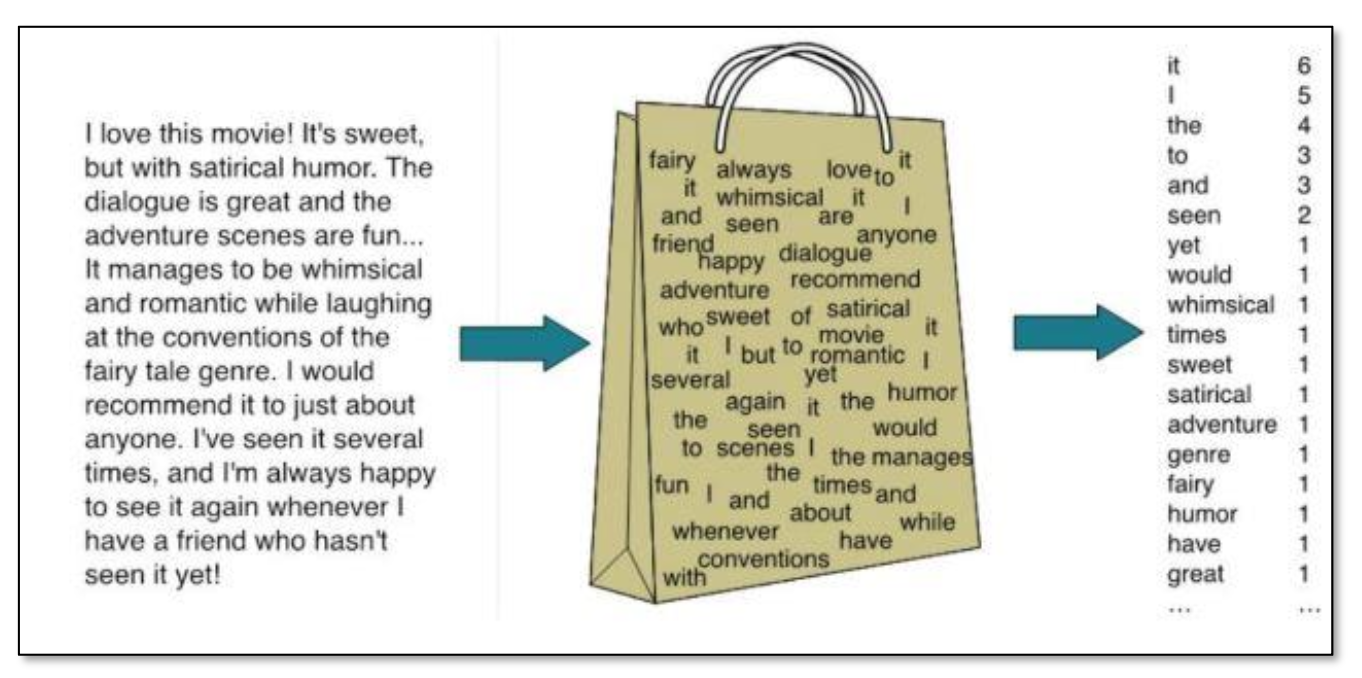
-
단어 사전 생성 : 분석할 텍스트 데이터 전체에서 고유한 단어들의 목록을 만들어 단어 사전을 구성
-
문서 벡터화 : 단어 사전 내 단어들의 출현 빈도로 표현한 벡터로 각 문서를 변환
예시를 살펴보자.
"Apple banana apple"
"Banana banana apple"
-
단어 사전
{"Apple", "Banana"} -
문장 벡터화
"Apple banana apple" : [2, 1]
"Banana banana apple" : [1, 2]
BoW 방식은 간단하고 효과적으로 텍스트 데이터를 숫자 벡터로 변환할 수 있다.
반면 단어의 순서, 문맥, 단어 간 의미적 관계를 고려하지 않아 복잡한 언어적 특성을 모델링하기에 부적합하다.
TF-IDF encoding
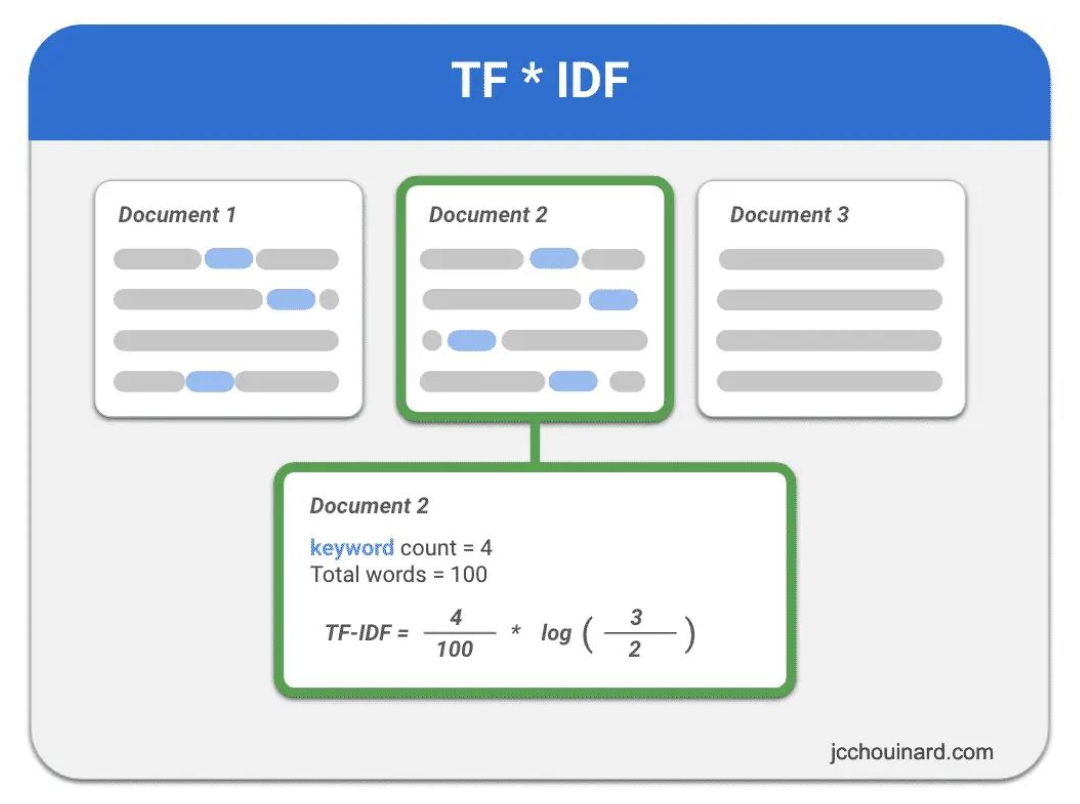
Term Frequency-Inverse Document Frequency(TF-IDF)는 단어의 출현 빈도와 단어가 문서 집합 전체에서 얼마나 중요한 정보를 담고 있는지 함께 고려하기 위한 방법이다.
이는 문서 내 중요한 단어와 중요하지 않은 단어를 구별할 수 있도록 한다.
-
TF(Term Frequency) : 문서 내에서 단어가 출현하는 빈도
-
IDF(Inverse Document Frequency) : 단어가 다른 문서들에서 얼마나 드물게 등장하는지를 나타내는 척도
작동 방식의 예시를 살펴보자.
"The quick brown fox"
"The brown fox jumps"
-
TF("brown")
두 문서에서 모두 1 -
IDF("brown")
두 문서 모두에서 출현하기 때문에 낮은 값을 가짐 -
TF-IDF("brown")
상대적으로 낮은 값을 가짐
"quick", "jumps"와 같이 특정 문서에서만 출현하는 단어는 높은 IDF값을 가지게 된다.
이는 해당 단어들이 각 문서에서 고유하며 중요한 정보를 담고 있는 것을 의미한다.
TF-IDF는 위와 같은 방식으로 중요한 단어를 강조하고, 자주 등장하지만 문서의 내용과는 크게 관련 없는 단어들("the", "is" 등)의 영향을 줄인다.
이는 텍스트 분류, 검색 엔진, 정보 검색 시스템 등에서 널리 사용된다.
Dimension reduction
고차원에 존재하는 데이터의 특징을 더 잘 설명할 수 있는 낮은 차원의 공간에서 새롭게 표현하는 것을 차원 축소라고 한다.
이는 일종의 인코딩 방법으로도 볼 수 있다.
차원 축소는 훈련 기반 방법과 비훈련 기반 방법 모두 존재하지만, 지금은 비훈련 기반 방법에 대해 살펴보자.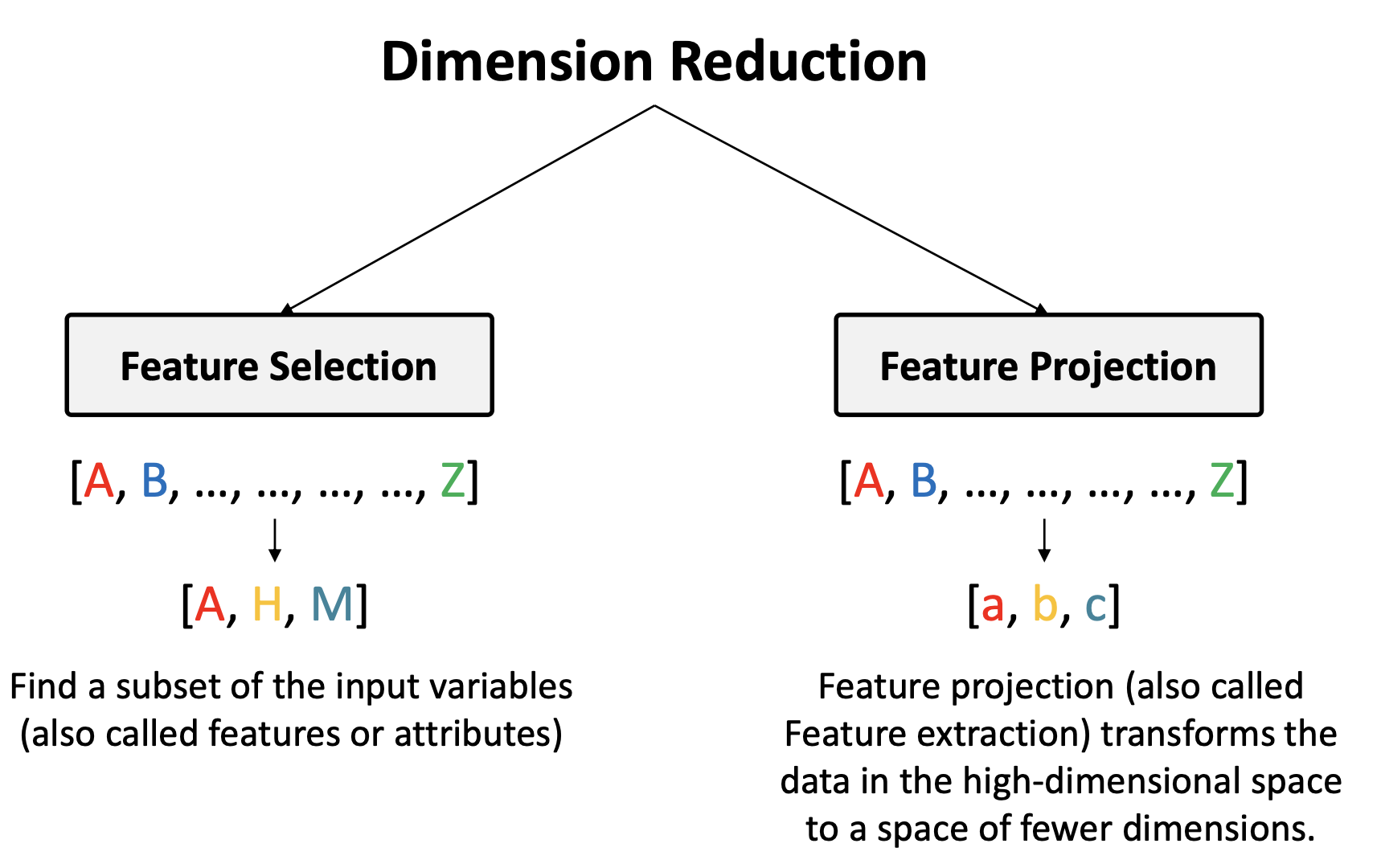
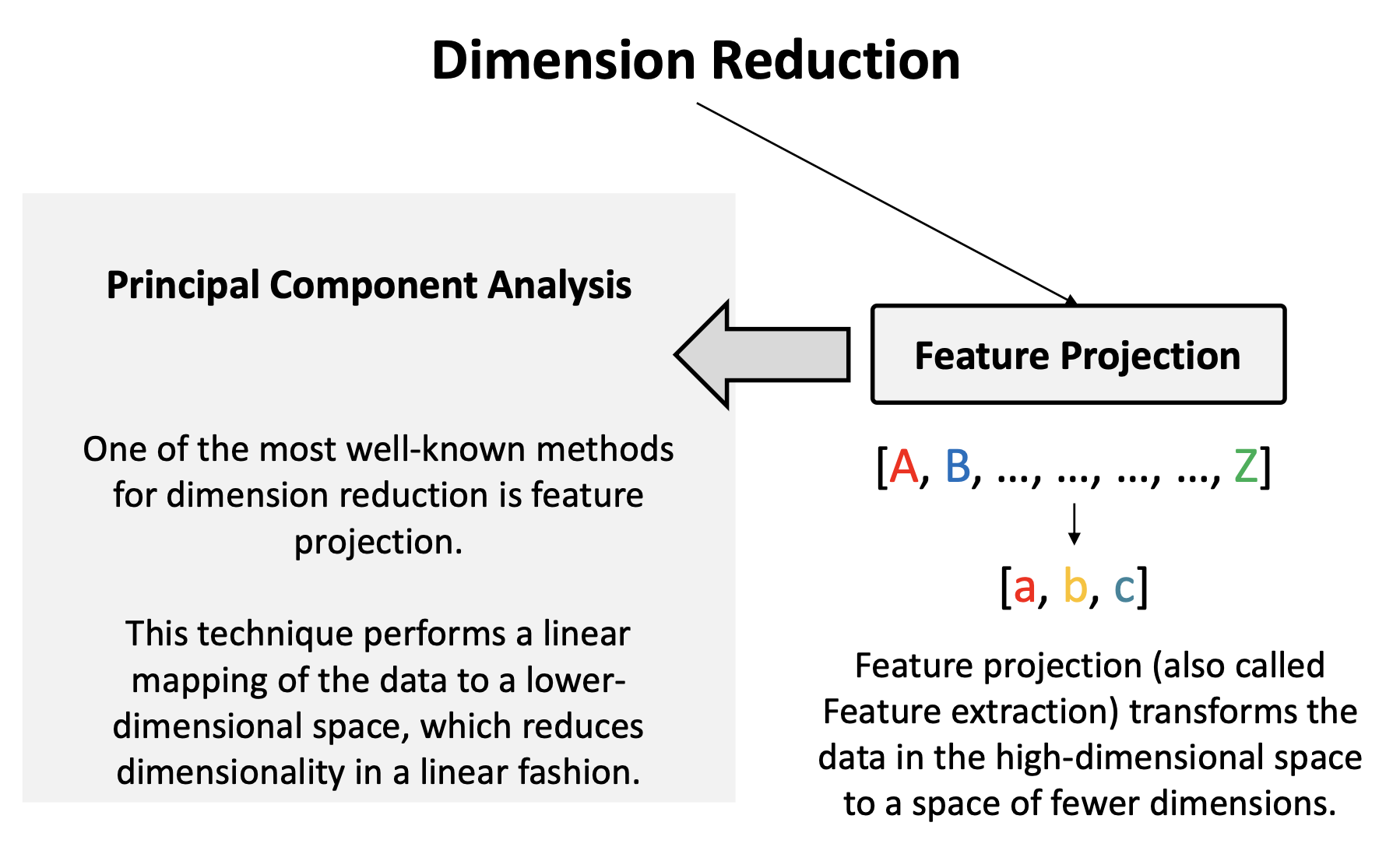
주성분 분석(PCA, Principal Component Analysis)
데이터의 분산이 최대화되는 방향을 기준으로 차원을 축소하는 방식을 주성분 분석이라고 한다.
가장 중요한 정보를 담고 있다는 것은, 다른 변수와 서로 상관 관계(독립적)가 적다는 것을 의미한다.
첫 번째 주성분은 원본 데이터의 분산을 가장 크게하는 축이며, 두 번째 주성분은 첫 번째 주성분과 직각을 이루며 다음으로 분산을 가장 크게 하는 축이다.
이러한 과정을 반복하며, 원본 데이터의 중요 정보를 최대한 보존하면서 차원을 축소한다.
이 방식은 데이터에서 중요한 특징을 추출하고, 노이즈를 줄이며, 데이터의 시각화를 용이하게 한다.
다만 PCA는 선형 관계에 기반한 방법이므로 비선형 구조를 가진 데이터에는 부적합하며, 분산을 최대화하는 축은 때로는(분류나 클러스터링) 가장 중요한 축이 아닐 수 있다.
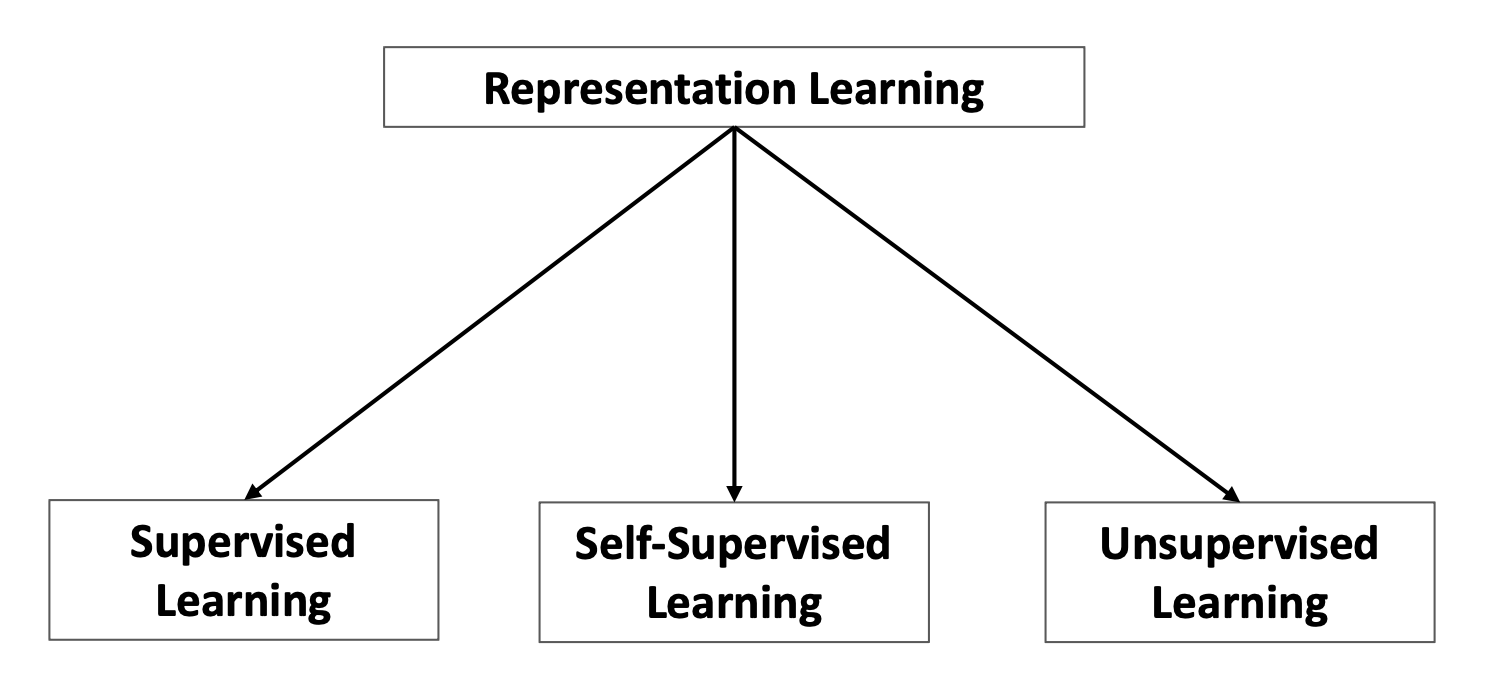
Learning based methods
-
지도 학습 : 레이블이 지정된 학습 데이터를 사용해 모델 학습
-
비지도 학습 : 레이블 없이 입력 데이터만을 사용하여 모델 학습
-
자기 지도 학습 : 레이블 없는 입력 데이터에서 스스로 레이블을 생성하여 학습
- 비지도 학습의 특별한 형태로, 입력 데이터의 내재된 특징을 학습하는 데 유용
Supervised learning
지도 학습에 기반한 표현 학습은 매우 직관적인 과정을 거친다.
이 방식은 표현 학습 자체를 직접적인 목표로 삼기보단, 응용 문제를 성공적으로 해결하는 과정 중에 우수한 표현을 스스로 학습하는 형태이다.
과일 인식기를 예시로 생각해보자.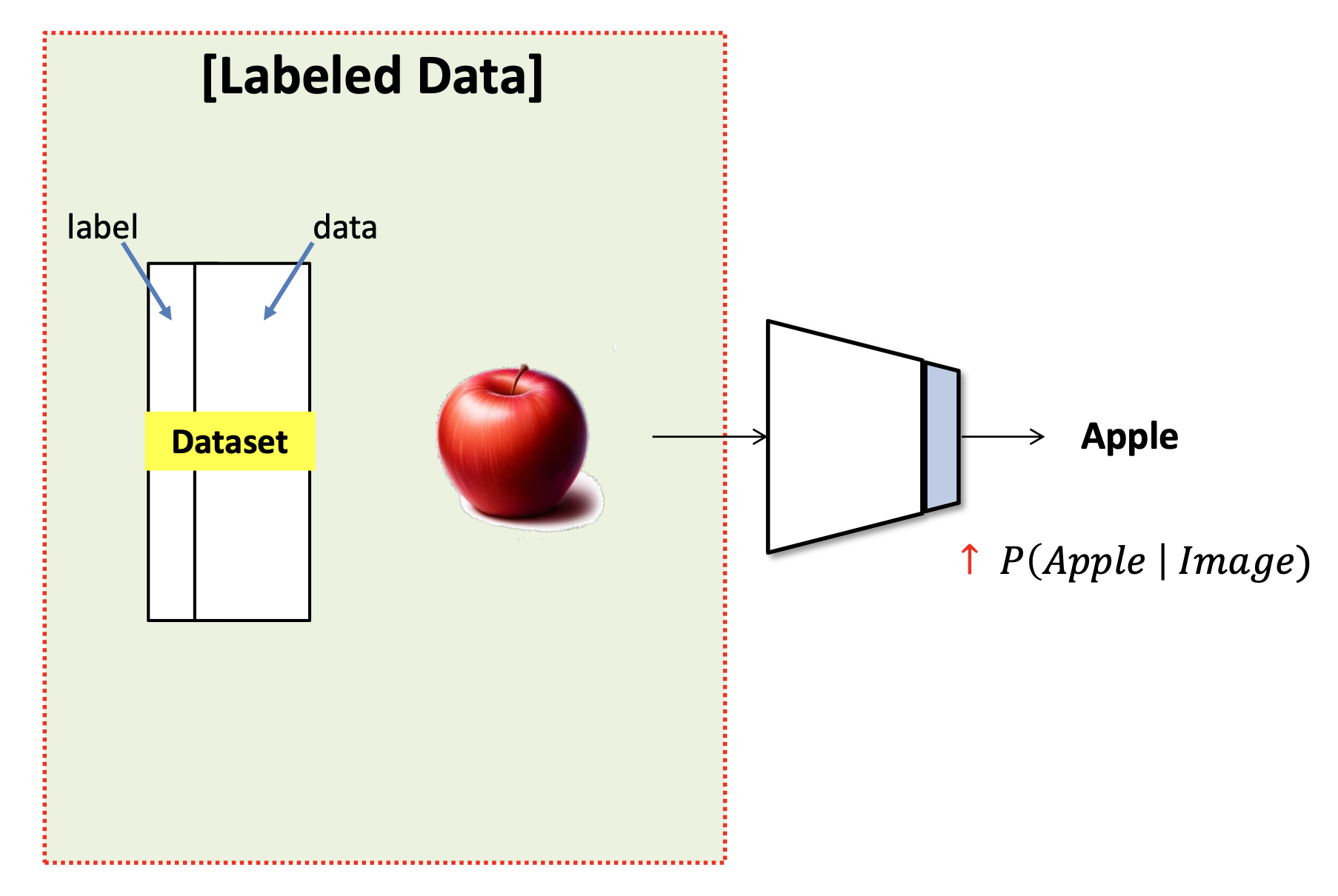
-
충분한 양의 Labeled Data를 사용해 분류기(Classificatin) 학습
-
분류를 효과적으로 수행하기 위해선 신경망의 최상위 레이어에 포함된 벡터(이미지 상 파란색 부분)가 구체적인 정보를 담고 있어야 함
-
이 숫자들이 '사과'를 의미하는지는 명확하지 않더라도, 최소한 다른 과일들과 구분가능한 차별화된 '표현'이 학습 과정에서 형성
-
결론적으로 과일 이미지는 숫자로 인코딩
장점
- 직관적이며 성능이 우수한 방식
단점
-
데이터셋 구성 비용이 크다
-
사람이 부여한 레이블(Symbol)로만 표현 가능 정보가 한정
-
각 레이블에 해당하는 데이터는 서로 명확하게 구분되어야 함
장점에 비해 단점들이 갖는 한계점으로 인해 최근에는 자기 지도 학습/비지도 학습 등 여러 방식의 연구가 활발해짐
Unsupervised learning
Autoencoder
오토 인코더는 비지도 학습의 일종으로, 입력 데이터를 차원 축소(인코딩)한 후 이를 다시 원래의 차원으로 복원(디코딩)하는 구조의 신경망이다.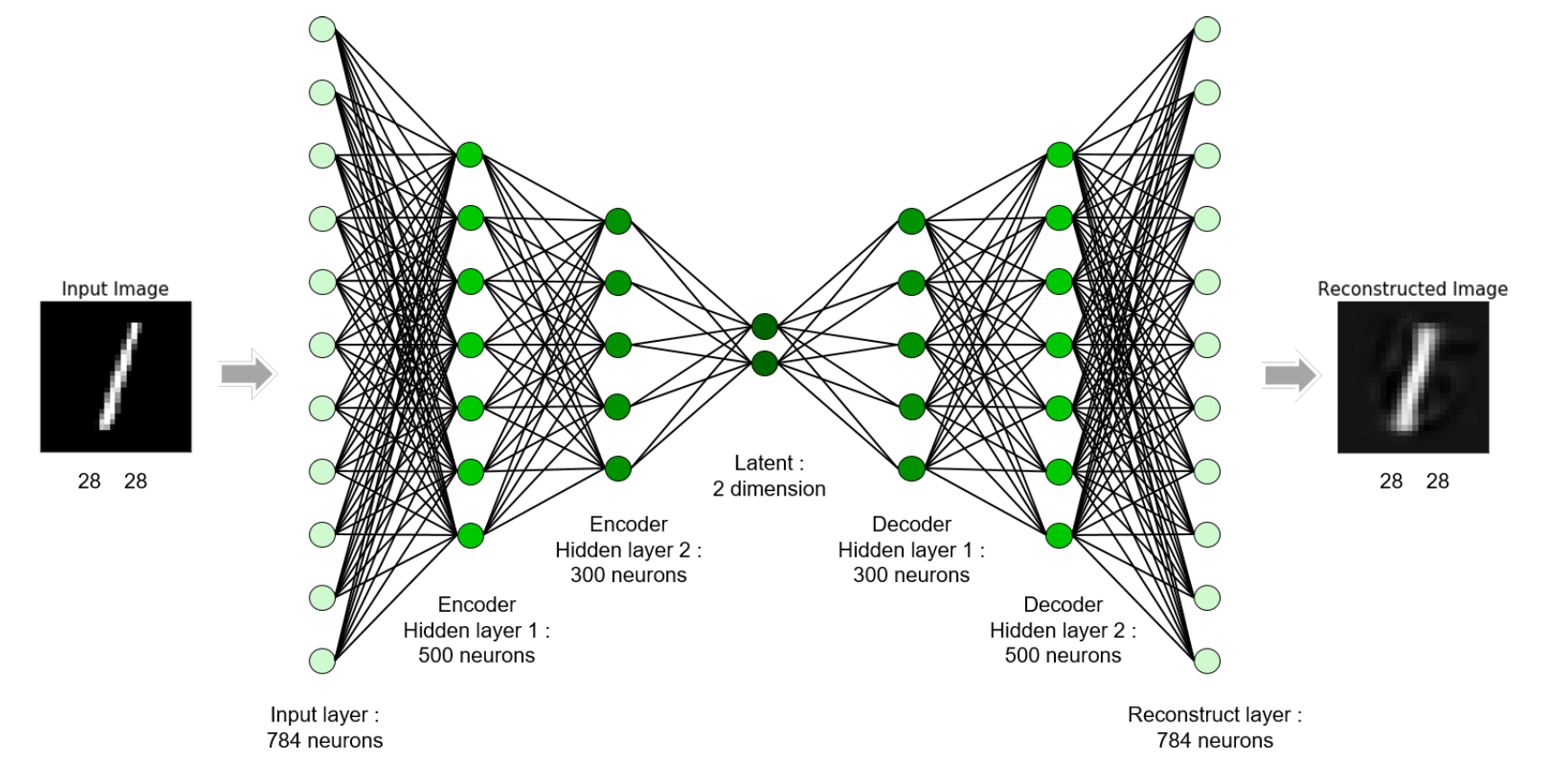
-
오토 인코더로 학습한 숫자 이미지의 정보는 인코딩되어 2차원으로 압축된다.
-
디코더는 2차원으로 압축된 숫자 정보를 토대로 원래 정보(이미지)로 복원한다.
오토 인코더는 인코딩-디코딩 과정에서 데이터의 중요한 특징을 학습하게 된다.
Denoising Autoencoder (DAE)
노이즈 제거 오토 인코더는 다음 과정을 거친다.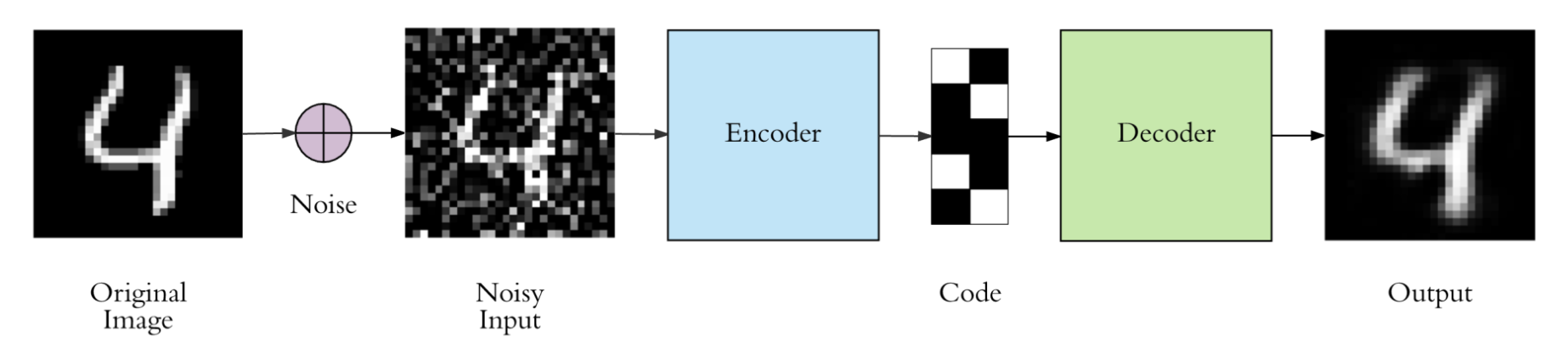
-
입력 데이터에 인위적으로 노이즈 추가
-
노이즈가 포함된 데이터를 원본 데이터로 복원하도록 학습
위 과정을 통해 데이터의 중요한 특징을 효과적으로 추출하고, 노이즈에 강건한 특징 표현을 학습한다.
Generative Adversarial Networks (GAN)
생성적 적대 신경망(GAN)은 생성자(Generator)와 판별자(Discriminator)를 경쟁적으로 학습시키는 신경망이다.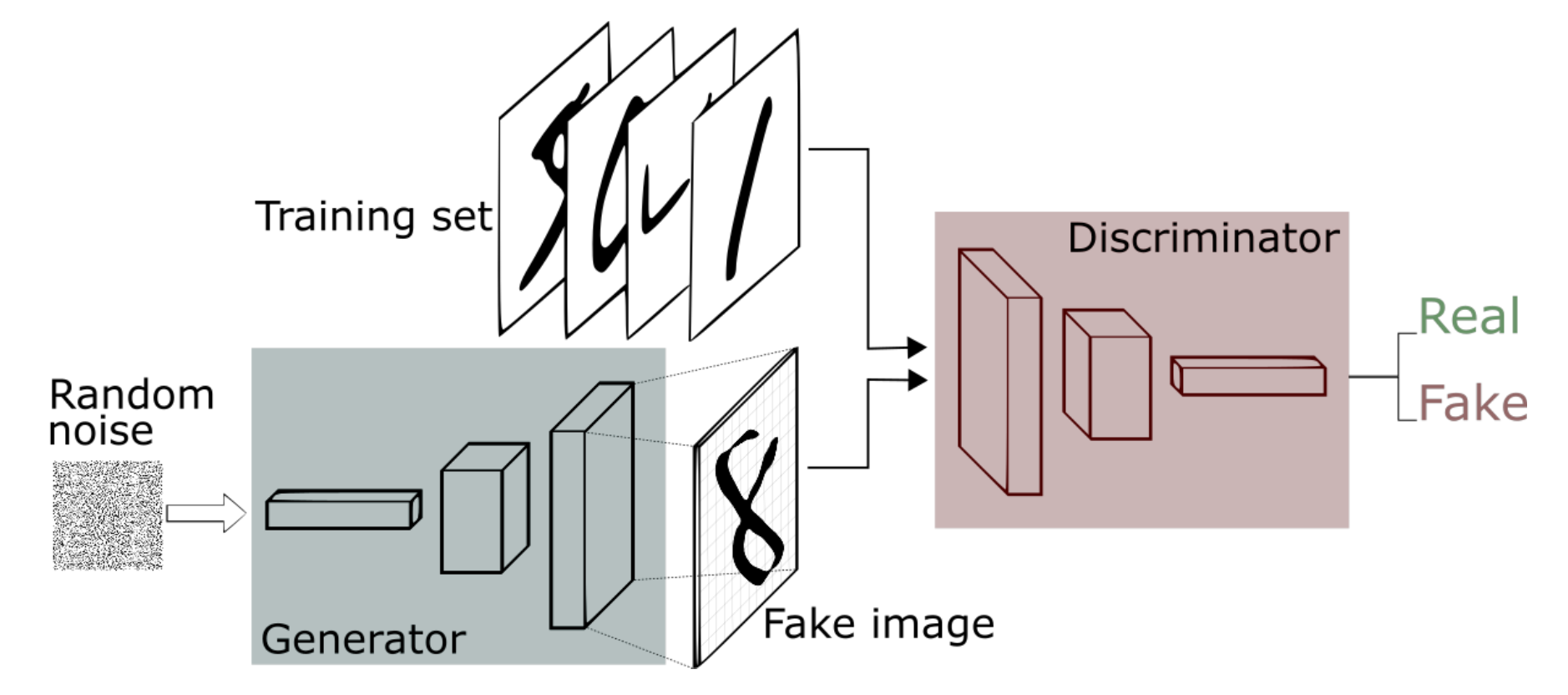
-
생성자(Generator) : 무작위 노이즈가 포함된 데이터를 받아 실제 데이터와 유사한 데이터를 생성. 생성자는 판별자를 속여 생성한 데이터를 실제 데이터로 판단하도록 하는 것이 목표
-
판별자(Discriminator) : 입력된 데이터가 실제 데이터인지, 가짜 데이터인지 판별.
위 과정을 통해 생성자는 실제와 똑같은 데이터를 생성하는 방법을 학습하고, 판별자는 실제 데이터와 생성된 데이터를 구별하는 방법을 학습한다.
GAN의 학습은 생성자와 판별자 사이의 균형을 찾는 것이다. 생성자는 더 정교한 가짜 데이터를 생성하고, 판별자는 더 정확하게 실제와 가짜를 구분하려고 한다.
두 네트워크가 최적화 상태에 도달한 것을 '나쉬 균형(Nash equilibrium)'이라고 한다. 이는 게임 이론에서 가져온 개념이며, 두 상대방 모두 최적의 응답을 하고 있어, 어느 한쪽도 자신의 전략을 단독으로 변경하여 이득을 볼 수 없는 상태를 의미한다.
위 과정이 반복된 결과로 생성자는 원본과 구분하기 어려운 고품질의 데이터를 생성하게 된다.
Self-supervised learning
자기 지도 학습은 레이블이 명시적으로 제공되지 않는 데이터에서 스스로 학습 신호를 찾아내는 방식이다.
이 방식은 데이터의 일부를 입력으로 사용하고, 나머지 부분을 예측하도록 모델을 학습시킨다.
자기 지도 학습은 데이터의 원본 형태를 활용해 데이터에 내재된 구조나 패턴을 바탕으로 학습 과제를 자동으로 생성하도록 한다.
예를 들어, 한 장의 고양이 이미지를 사용해 여러 개의 지도 학습용 데이터셋을 생성할 수 있다.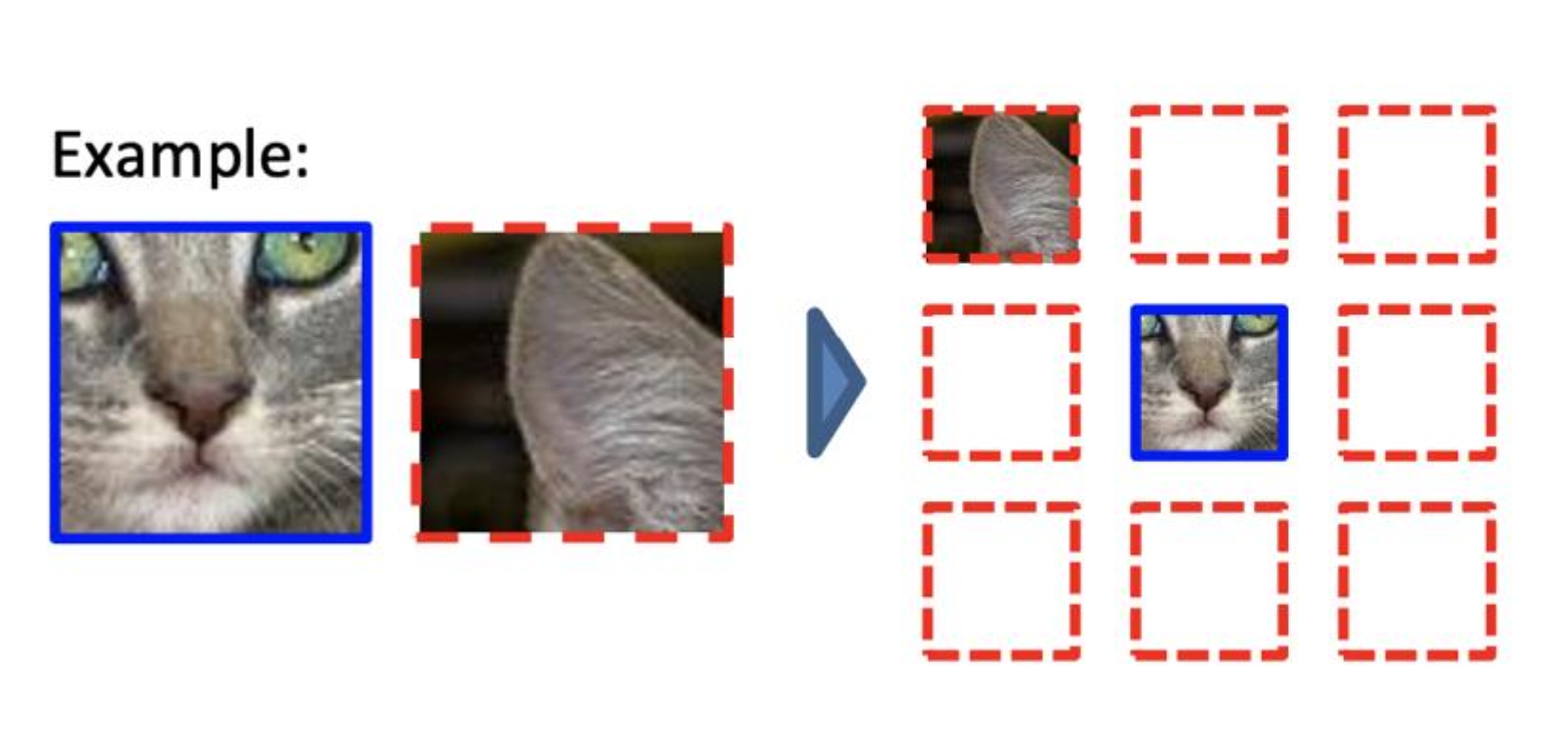
위 사진을 보자.
고양이 얼굴을 중심으로 주변 8개 이미지를 임의로 잘라내고, 잘려진 이미지들이 고양이 얼굴을 중심으로 어느 위치에 이있어야 하는지 맞추는 문제로 전환할 수 있다.
위와 같은 방식으로 학습된 기계는 고양이의 외형(표현)을 학습하게 된다.
자기 지도 학습은 모델이 데이터의 복잡한 내부 구조와 맥락, 패턴을 이해하는 방법을 학습하도록 한다.
결론적으로 모델은 데이터를 효과적으로 벡터화하는 능력(표현 학습 능력)을 갖추게 된다.
효과적인 벡터화란 데이터의 본질적인 특성과 구조를 반영하여 정보 손실이 최소화되도록 encoding 하는 것을 의미한다.
이 방식의 가장 큰 장점은 레이블링된 데이터에 의존하지 않기 때문에 풍부한 표현 학습이 가능하다는 것이다.
이는 구조화되지 않은 대량의 데이터를 활용하여 모델을 학습시킬 수 있으며, 모델은 일반화된 특성을 포착할 수 있다는 점을 시사한다.
자기 지도 학습은 특히 데이터의 사전 학습된 표현을 필요로 하는 다운스트림 작업에 유용하게 사용된다.
많은 수의 데이터셋은 기계 학습 모델의 성능에 매우 중요한 요소이다. 현실적으로 라벨링된 데이터셋보다 라벨링되지 않은 데이터셋이 매우 많으므로, 자기 지도 학습은 매우 중요한 표현 학습 방식이라고 볼 수 있다.
