[AI : Data representation and problem solving] Sequence to Sequence learning
전통적인 머신러닝 문제들은 대부분 사람의 인지 기관을 모방하기 위한 기술이었다.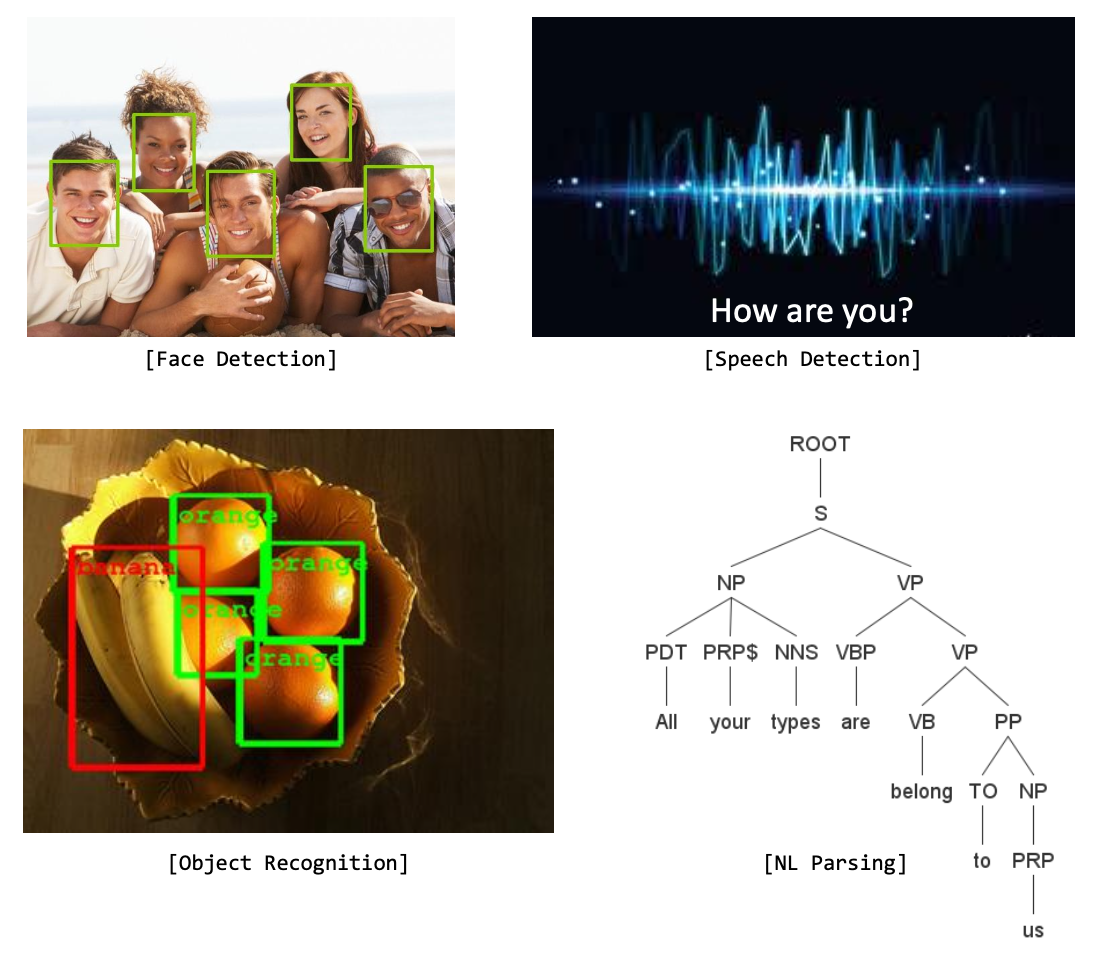
최근에는 Sequence-to-Sequence Learning이라는 새로운 프레임워크의 발전으로 인해 AI로 해결 가능한 문제의 범위가 대폭 넓어졌다.
Sequence-to-Sequence Learning를 특정 아키텍처로 이해하는 것보단 머신 러닝을 여러 문제에 적용가능한 프레임워크 정도로 이해하는 것이 적합하다.
Sequence to Sequence Learning
Seq2Seq는 서로 연관된 두 개의 데이터 시퀀스 간의 관계를 모델링(학습)하는 방식이다.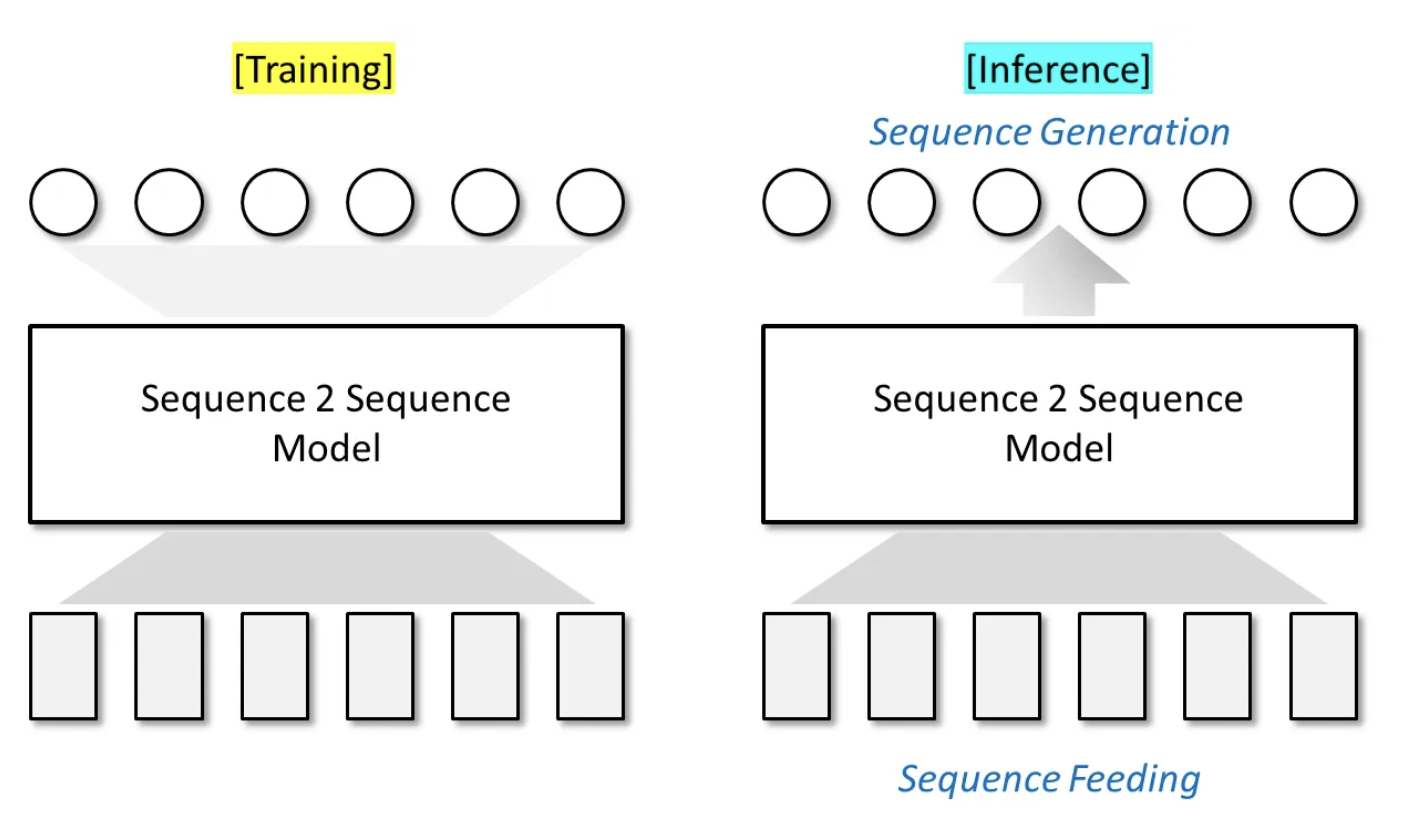
Seq2Seq를 구현하기 위해 '어떤 네트워크 구조를 활용해야 한다. 혹은 어떤 머신 러닝 기술을 활용해야 한다.'는 제약 조건은 존재하지 않으며, 시퀀스 데이터 사이의 관계를 모델링할 수 있다면 전부 Seq2Seq Learning에 해당한다.
입력 시퀀스의 크기를 이라 하고 출력 데이터 시퀀스의 크기를 이라고 할 때, 여러 케이스가 존재한다.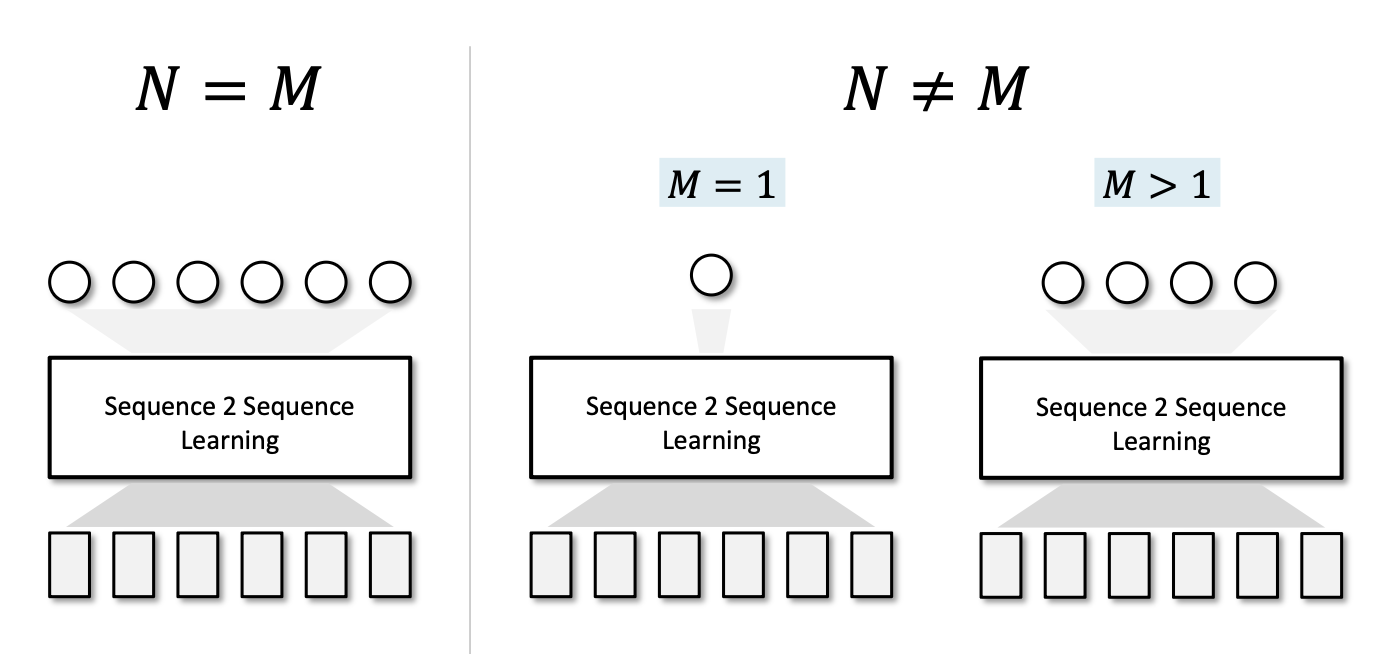
Seq2Seq Learning의 적용 범위는 매우 넓으며, 실제 일상의 대부분의 문제는 Seq2Seq로 모델링이 가능하다.
Sequence-to-Sequence Learning가 시사하는 점은 다음과 같다.
- 기존 AI가 다루던 문제의 범위를 대폭 확장
- 다양한 분야에서 새로운 접근법과 해결책을 제시
- 인간의 언어, 영상 처리 등 시퀀스 데이터를 처리하는 데 특화
- 기존 방식보다 훨씬 직관적이고 효율적인 모델링을 가능하게 한다.
따라서 Seq2Seq는 미래 머신러닝과 인공지능 발전에 있어 중추적인 역할을 할 것으로 기대된다.
음성 인식
과거 음성인식 모델은 음향 모델링을 통해 특정 음향이 어떤 단어에 해당하는지 결정하고, 언어 모델링을 통해 다음 단어를 예측하는 매우 복잡한 구조를 가졌다.
S2S 접근 방식은 음성 데이터가 입력되고, 텍스트 데이터로 변환되는 매우 단순화된 모델링을 제공한다.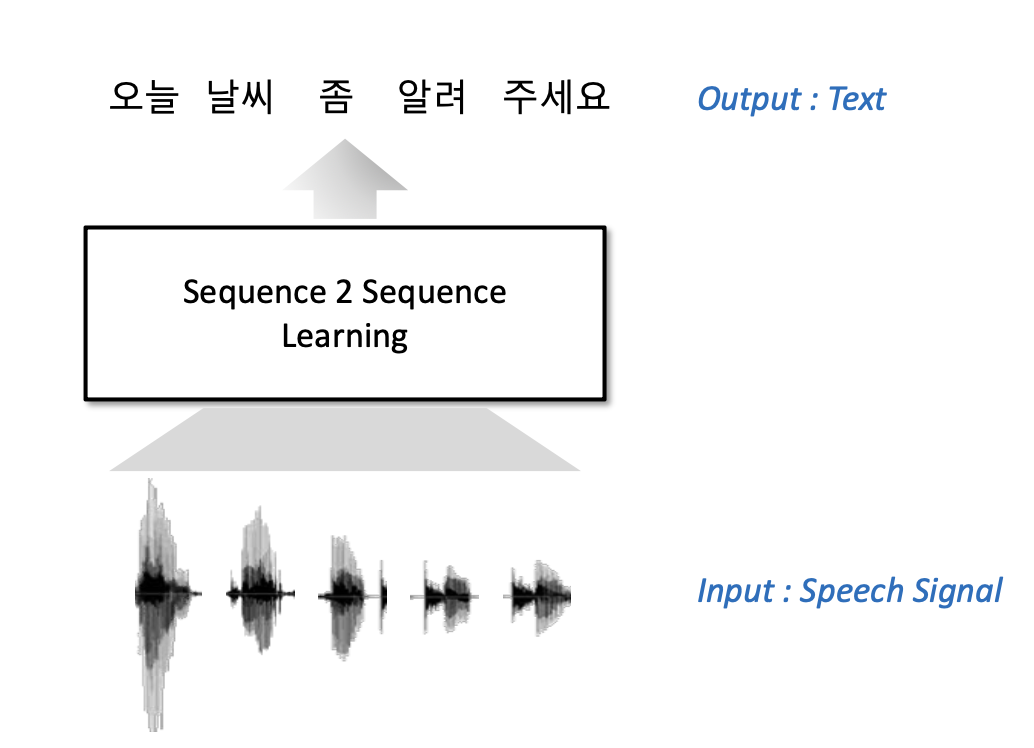
이는 음성 데이터를 텍스트로 변환하는 과정을 직관적이고 효율적으로 만든다.
S2S는 복잡한 내부 구조에 대한 깊은 이해 없이도 우수한 성능을 제공하기 때문에, 개발자는 구현에 집중하기 보다 데이터를 이용해 모델을 효과적으로 활용하는 것에만 집중할 수 있다.
영상 처리
과거에는 영상 데이터 내 특정 이벤트를 검출하기 위해 사람의 움직임을 따라가며, 스윙하는 궤적을 분석하는 복잡한 처리 과정이 필요했다.
반면 S2S Learning을 적용하면 이 과정을 대폭 단순화할 수 있다. 영상을 일정 간격으로 쪼개 각 프레임을 하나씩 시퀀스 데이터로 처리하며, 각 프레임 이미지가 설명하는 이벤트에 대한 라벨을 붙인다.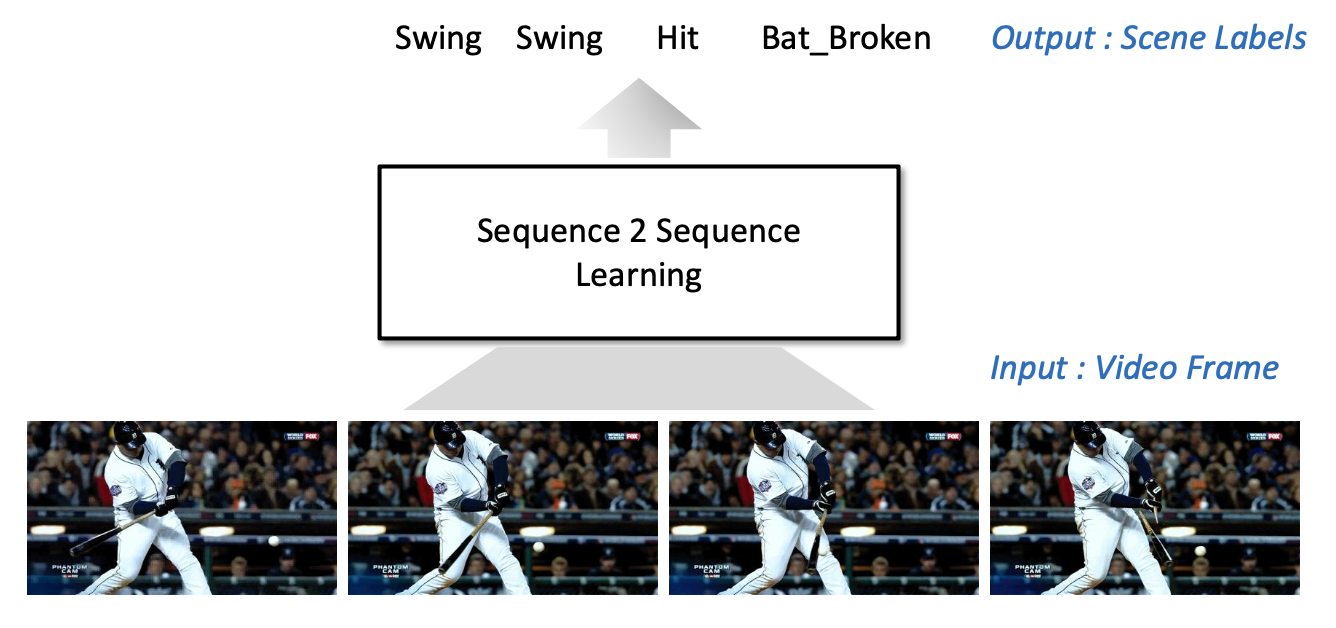
S2S Learning은 입력 영상 + 이벤트 라벨 데이터만 준비한다면, 복잡한 전문 지식 없이도 성능이 어느정도 보장된 영상 이벤트 검출기를 만들 수 있도록 한다.
자연어 처리
자연어 처리 분야에서도 마찬가지이다. 다수의 문장들이 어떤 특정 태그로 매핑될 수 있다는 정보를 가진 데이터셋만 주어진다면, 이를 S2S에 적용하여 처리할 수 있다.
마찬가지로, 특별한 언어학적 지식은 필요없다. 단지 적절하게 매핑된 데이터셋만 있으면 되는 것이다.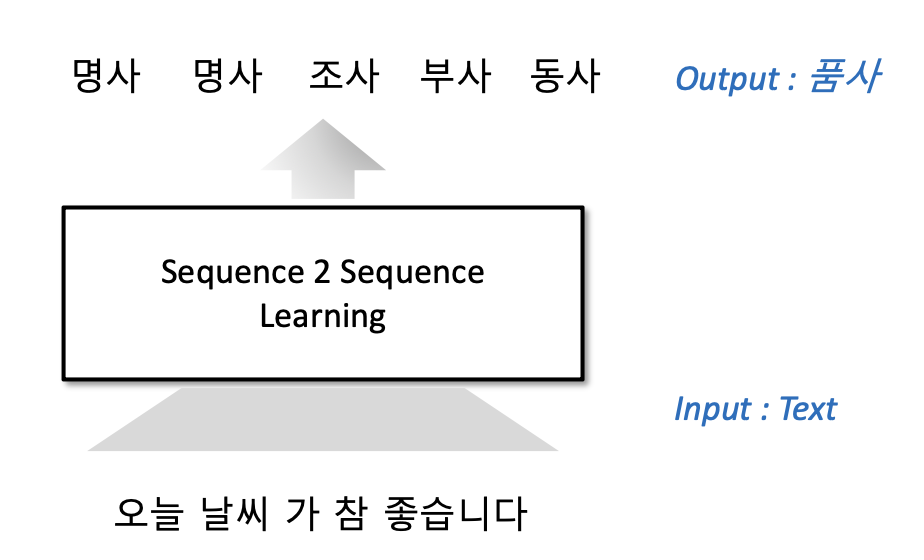
다양한 예시들
연산 문제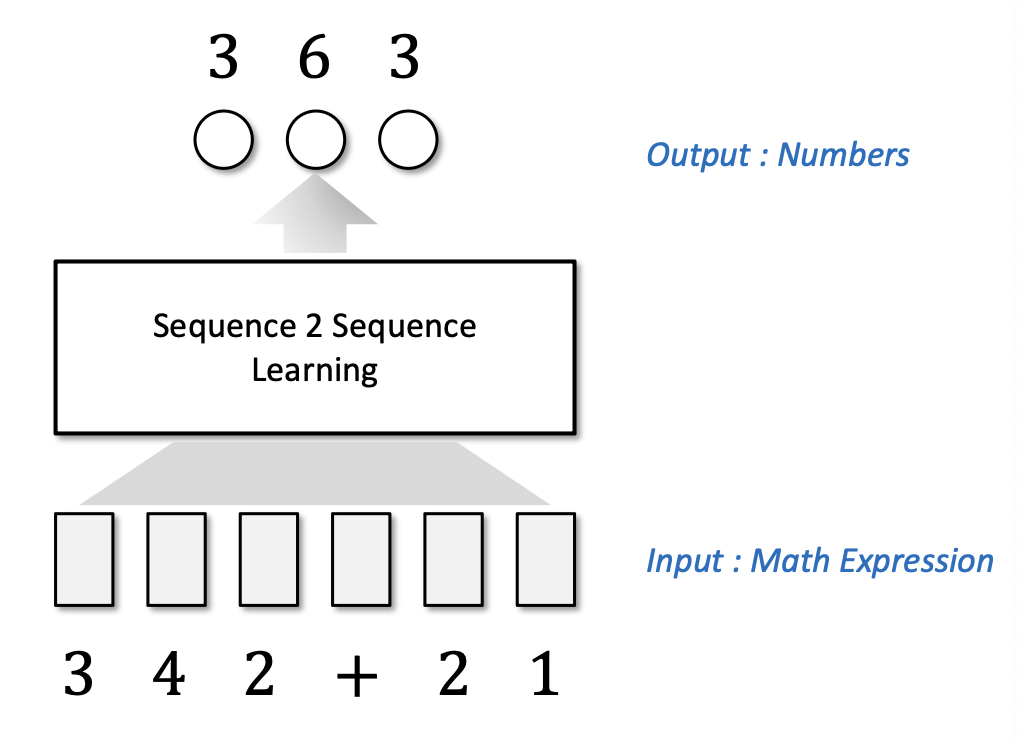
문장 자동 완성
어떤 문제에 대한 구체적인 상상과 입출력 데이터만 정의할 수 있다면, 해당 문제는 Sequence to Sequence 문제로 대부분 모델링 가능하다.
따라서 '주어진 문제를 어떻게 정의하고, 입력과 출력을 어떻게 설정하느냐'가 가장 중요한 능력이다.
