Attention
전통적인 Encoder-Decoder RNN의 경우, 입력 시퀀스를 고정된 크기의 벡터로 압축해서 사용한다. 이로 인해 입력과 출력 사이의 거리가 멀어질수록 입력에 포함된 정보가 손실될 수 있다. (장기 의존성 문제)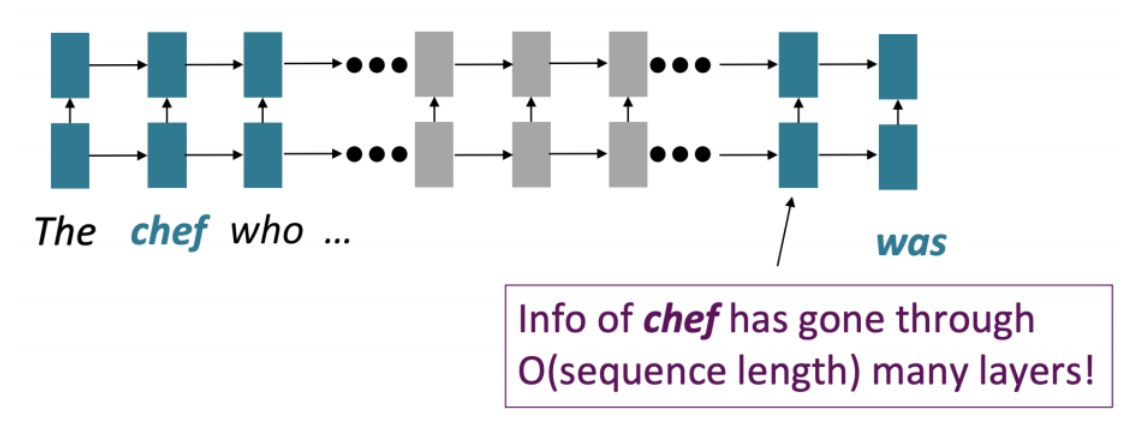
어텐션은 이 문제를 해결하기 위해, 디코더가 출력을 생성할 때 인코더의 전체 은닉 상태를 계산하여 가중치를 반영한다.
출력과 관련된 단어의 가중치는 높게 계산되기 때문에, 모델은 출력과 연관성이 높은 단어를 중요한 정보로 인식하여 해당 정보를 출력에 반영할 수 있게 된다.
Attention mechanism
Attention 메커니즘은 3가지 주요 벡터가 사용된다.
-
Query : 디코더가 현재 출력하고자 하는 단어 (디코더의 단어)
-
Key : 인코더의 각 입력 단어가 지닌 정보 (인코더의 단어)
-
Value : 보통 Key와 동일; 최종 Attetnion score를 계산할 때 활용되는 값
어텐션 메커니즘에 대해 자세히 살펴보자.
Step 1
Query 벡터와 Key 벡터간의 내적을 통해 Query와 Key가 얼마나 서로 연관된 정보인지(Attention score)를 계산한다.
Step 2
Softmax 함수를 활용하여 각 입력 단어의 중요도를 확률 형태로 표현
여기서 는 Attention weight에 해당한다.
Step 3
Attention weight와 Value의 곱을 통해 Context 벡터를 계산한다.
여기서 어텐션 가중치에 따라 Attention 값이 결정되며, 어텐션 가중치는 Q와 K가 연관된 정보일수록 높은 값을 갖게 된다.
Transformer
Transformer란, "Attention is All You Need"라는 논문에서 제안된 아키텍처로, 순수 어텐션 메커니즘만으로 인코더와 디코더를 구현하였다는 특징이 있다.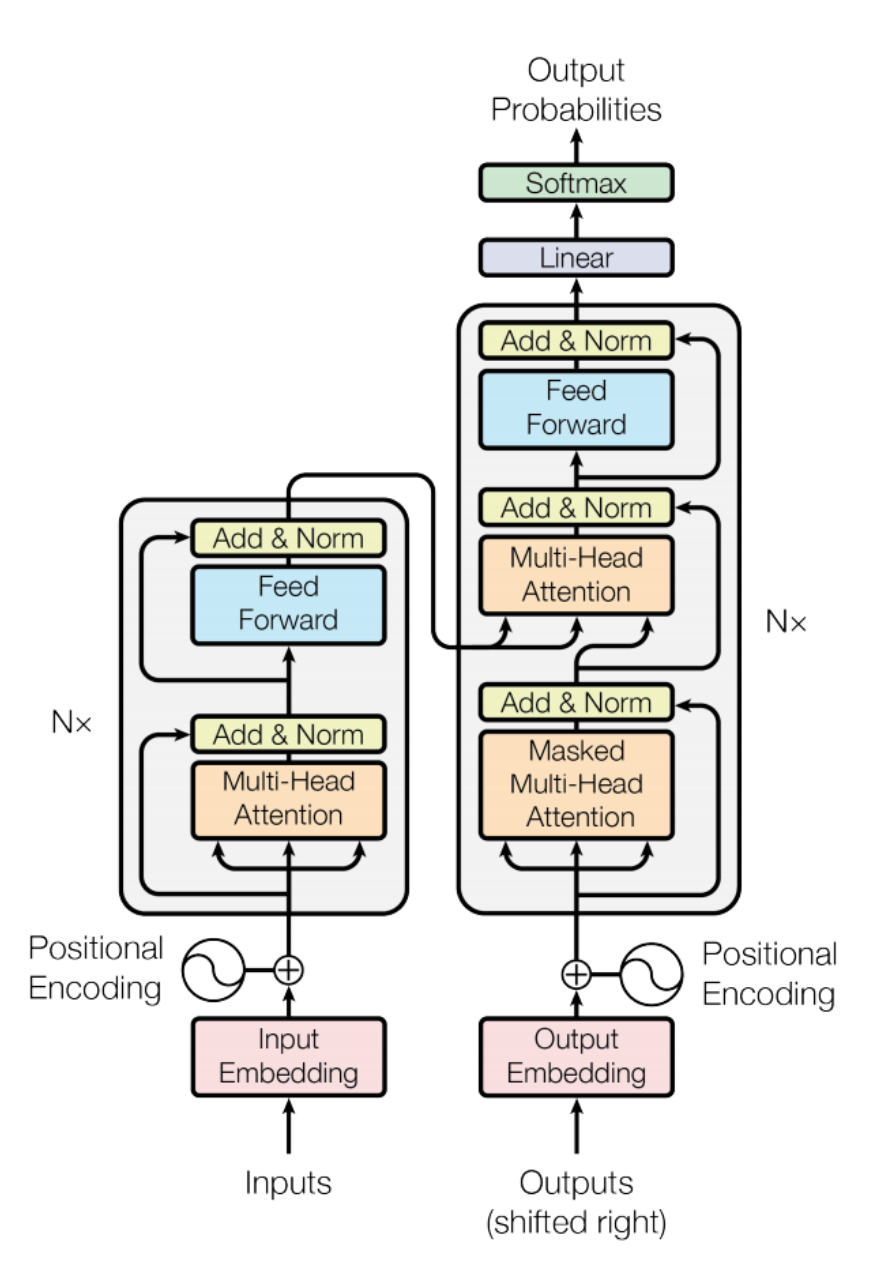
Self-attention
Self-attention은 입력의 각 단어가 다른 단어들과 어떤 관련이 있는지를 계산하기 위한 메커니즘이다.
Self-attention 계산 과정은 상술한 어텐션 메커니즘과 동일하지만,
일반적인 어텐션 메커니즘은 디코더가 현재 출력하고자 하는 단어(Query)와 인코더의 단어(Key) 간의 관계를 계산한다.
반면 Self-attention 메커니즘은 같은 입력 시퀀스 내에서 자기 자신을 포함하여 모든 단어 간 관계를 계산한다는 차이점이 존재한다.
Multi-head attention(MHA)
트랜스포머는 Self-attention을 병렬적으로 처리하기 위해 Multi-head라는 구조를 사용한다.
MHA는 서로 다른 헤드를 구성하여 입력의 모든 부분에 대해 병렬적으로 어텐션을 수행하는 방식이며, 입력의 다양한 관계들을 여러 시각으로 포착이 가능하도록 지원하는 기법이다.
다음과 같이 간단한 예시를 통해 이해할 수 있을 것이다.
MHA 동작 흐름에 대해 좀 더 자세히 살펴보자.
Step 1
각 Q, K, V를 갖는 여러 독립적인 헤드를 구성한다.
여기서 는 각 Head별로 갖는 학습 가능한 가중치 행렬에 해당한다.
Step 2
나눠진 Head는 각 Q, K, V를 통해 독립적으로 Self-Attention을 수행한다.
Step 3
여러 Head에 의한 출력들을 하나로 합산한 후, 선형 변환을 통해 최종 Attention 출력을 생성한다.
MultiHead = Concat
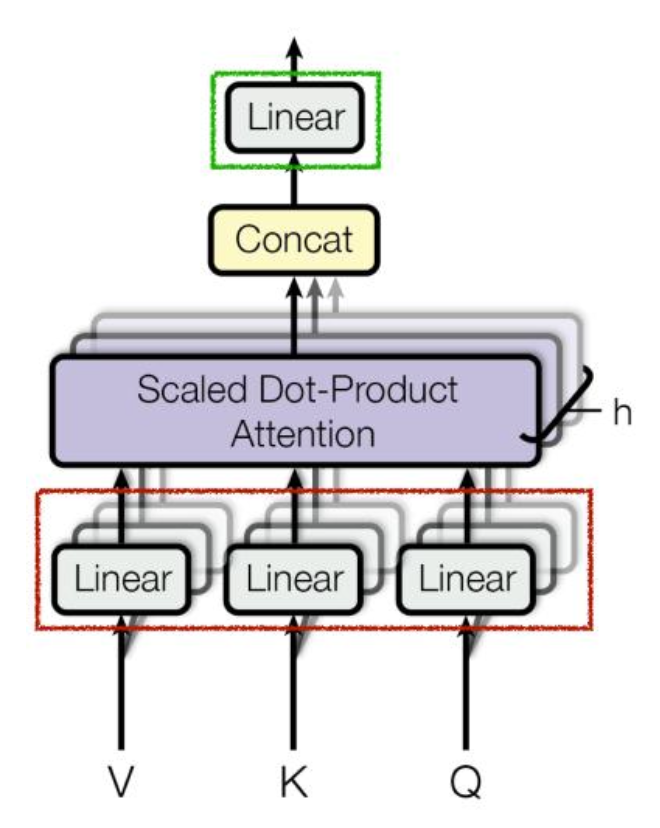
각 헤드의 가중치 행렬의 차원은 다음과 같이 결정된다.
Masked multi-head attention
Masked Attention은 디코더에서 현재 단어를 예측할 때, 미래 단어에 대한 정보를 사용하지 않도록 하기위한 기법이다.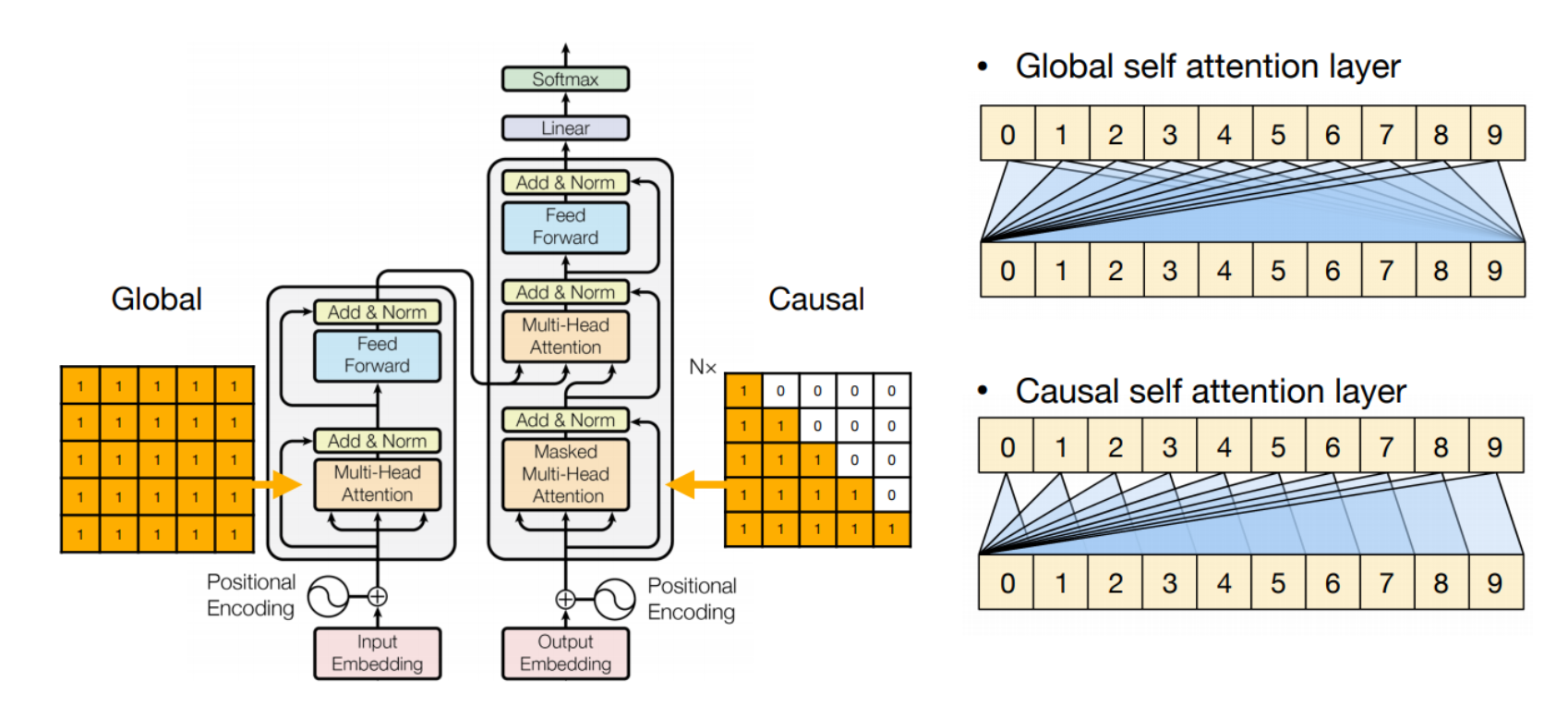
Feed-forward network
Transformer의 각 레이어에는 어텐션 다음으로 FFN(Feed-forward network)이 포함되어 있다. 이는 비선형적 특징 모델링을 돕기 위한 부분이다.
가장 기본적인 구현은 더 큰 은닉 상태 크기와 ReLU/GeLU를 활성화 함수로 사용하는 2계층 MLP이다.
Layer normalization
트랜스포머는 각 토큰의 임베딩에 대해 정규화를 수행한 뒤, 학습 가능한 아핀 변환(Affine transformation)을 적용한다.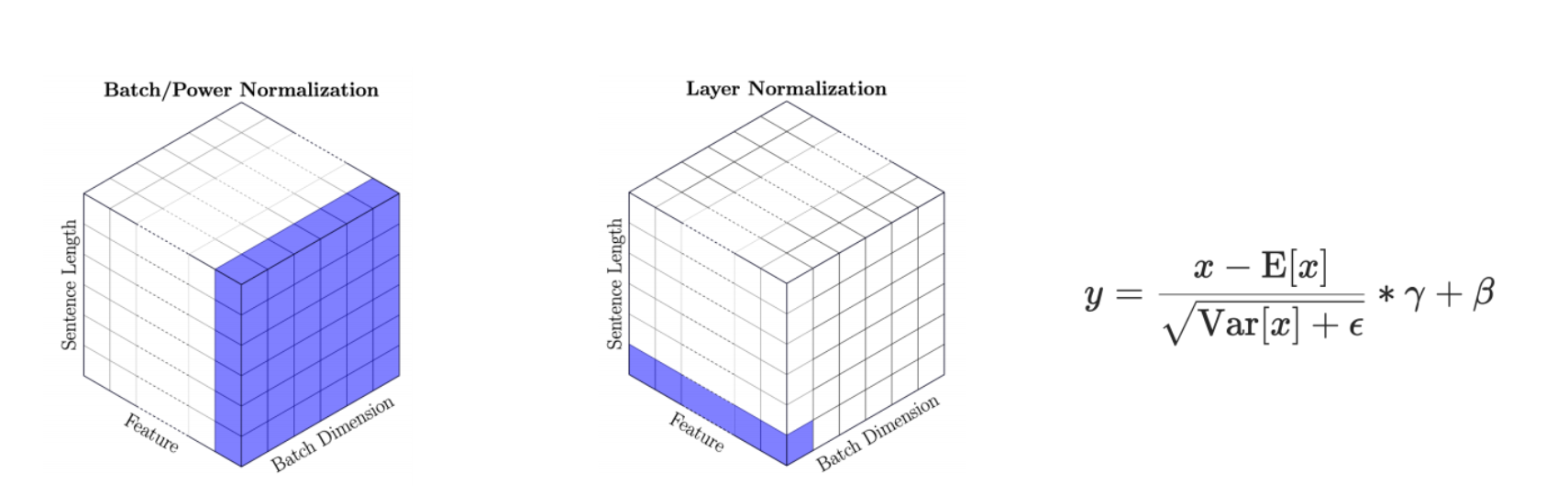
Residual connection
잔차 연결(Residual connection)은 한 계층의 입력을 그대로 다음 계층의 출력에 더해주는 기법이며, 트랜스포머는 학습 안정성을 위해 이를 채택하였다.
최근에는 Pre-norm 방식이 더 많이 사용되는 추세이다.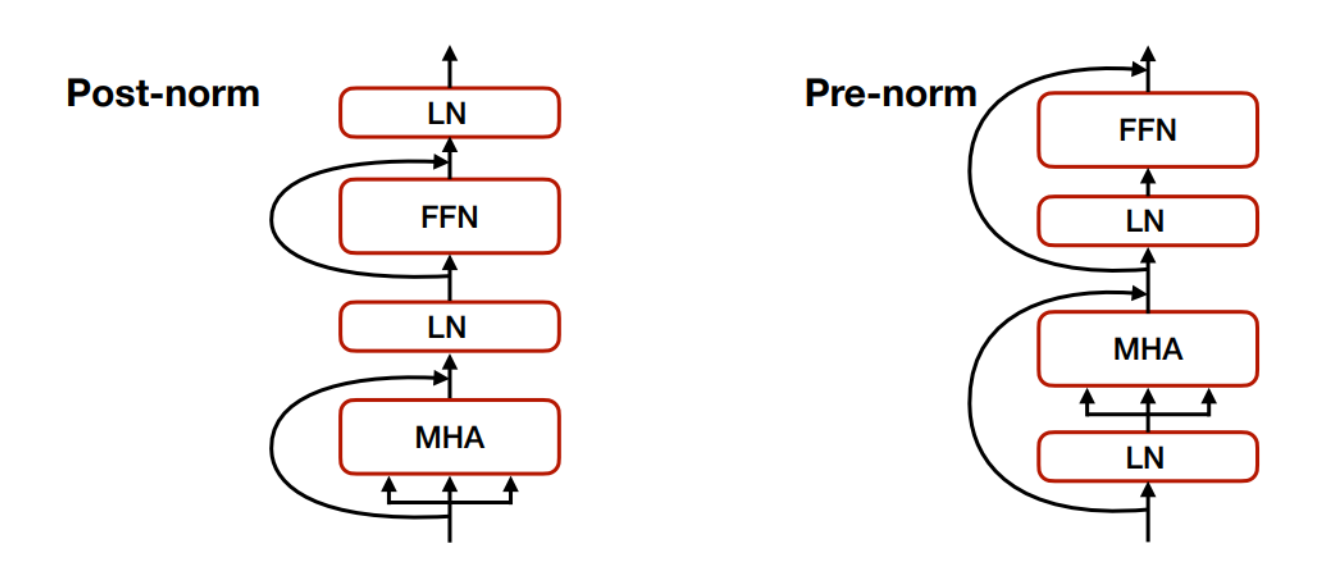
-
Post-norm : 계층 정규화 이후에 잔차 연결
-
Pre-norm : 계층 정규화 이전에 잔차 연결
Positional encoding
Transformer는 입력 토큰을 순차적으로 받는 구조가 아니기 때문에, 각 입력 토큰의 위치 정보를 따로 인코딩해주어야 하며, 이것을 Positional encoding이라고 한다.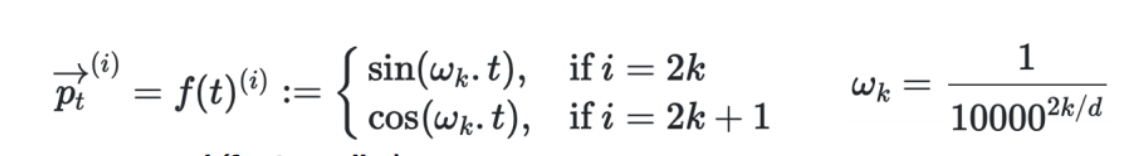
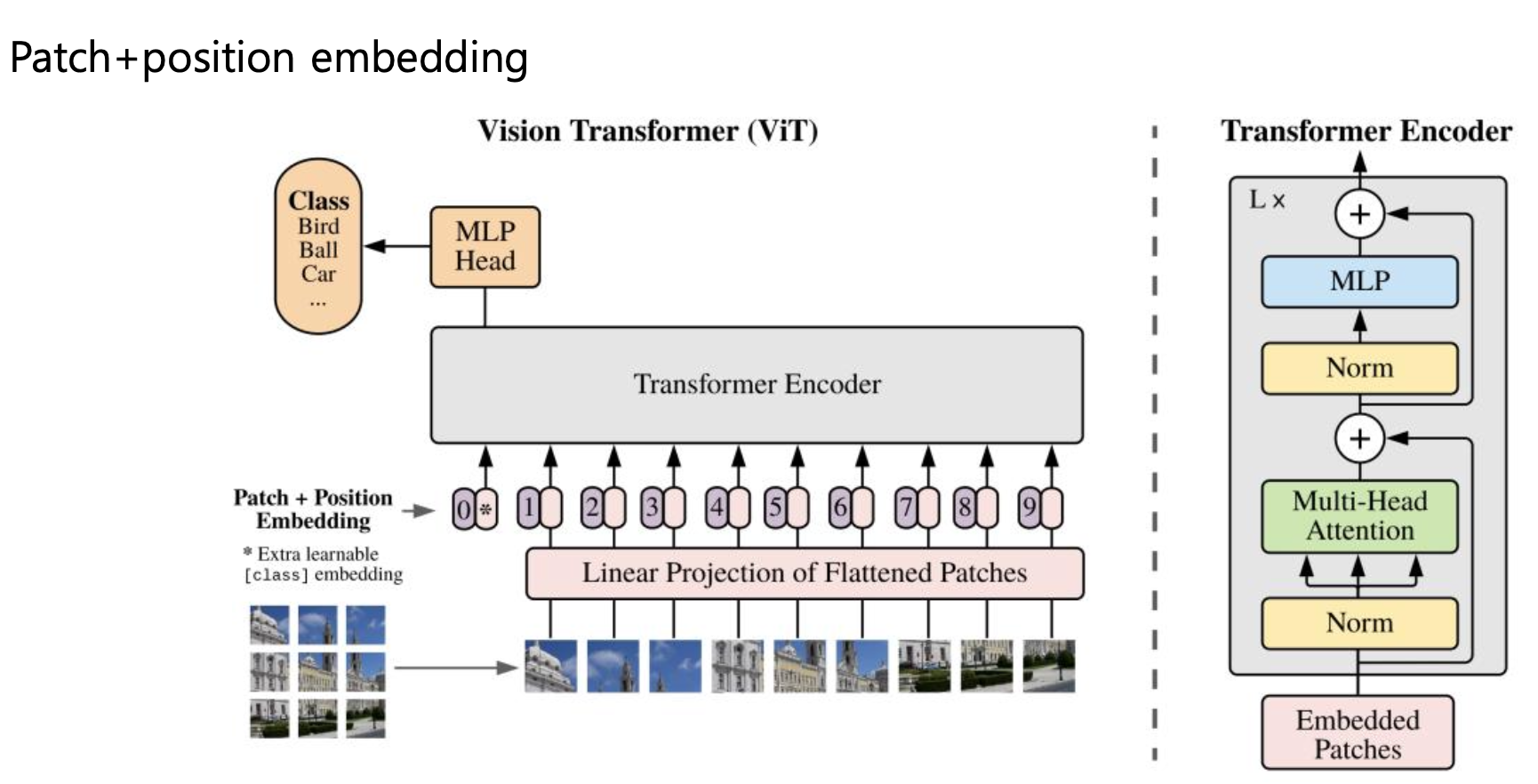
Vision Transformer (ViT)
ViT는 이미지 처리에 트랜스포머를 적용한 모델로, 2D 이미지를 패치들의 시퀀스로 간주하는 방식으로 이미지를 처리한다.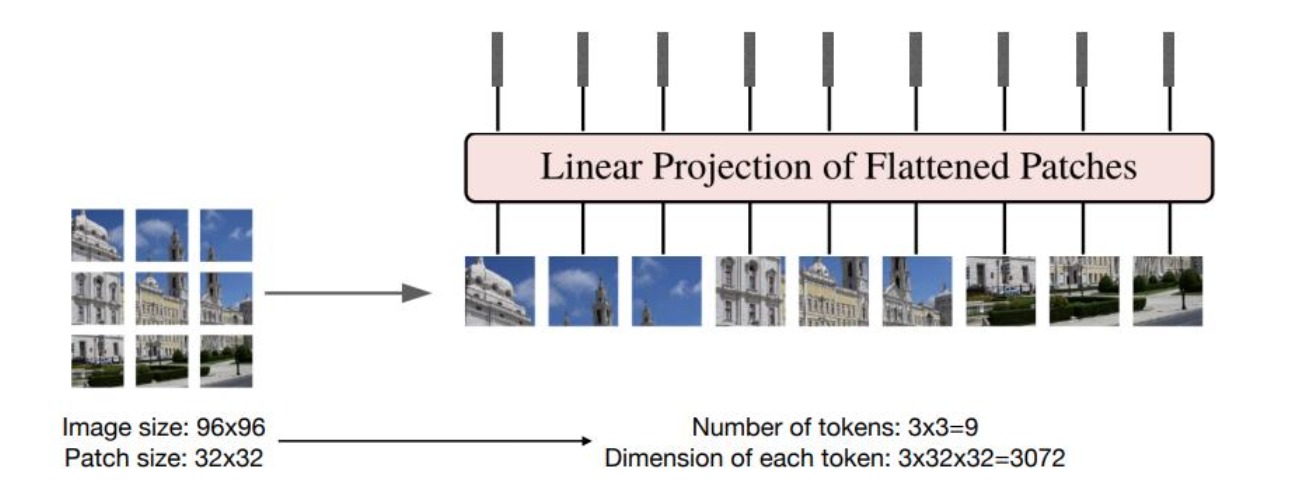
이미지는 작은 정사각형의 패치로 쪼개지며, 각 패치들은 하나의 토큰으로 간주된다.
이러한 각 패치 벡터들을 트랜스포머의 인코더로 입력하며, 트랜스포머는 각 패치 간 관계를 학습하여 이미지 전체적인 의미를 파악할 수 있다.