Image Segmentation Using Deep Learning: A Survey Paper Review

이번 학기는 Image Segmentation에 꽂혀서 기초부터 천천히 공부하려 한다.
그래서 첫 공부로 Survey Paper를 찾았고, 블로그나 깃헙에 정리도 하면서 리뷰를 하려고 한다.
Source: https://arxiv.org/abs/2001.05566
리뷰 방식
- 논문을 읽으며 한 문단씩 끊어서 한줄로 요약
- 중요하게 느낀 문장은 직독직해로 기록하는 방식
Abstract
Image segmentation is a key topic in image processing and computer vision with applications such as scene understanding, medical image analysis, robotic perception, video surveillance, augmented reality, and image compression, among many others. Various algorithms for image segmentation have been developed in the literature. Recently, due to the success of deep learning models in a wide range of vision applications, there has been a substantial amount of works aimed at developing image segmentation approaches using deep learning models. In this survey, we provide a comprehensive review of the literature at the time of this writing, covering a broad spectrum of pioneering works for semantic and instance-level segmentation, including fully convolutional pixel-labeling networks, encoder-decoder architectures, multi-scale and pyramid based approaches, recurrent networks, visual attention models, and generative models in adversarial settings. We investigate the similarity, strengths and challenges of these deep learning models, examine the most widely used datasets, report performances, and discuss promising future research directions in this area
Index Terms
Image segmentation, deep learning, convolutional neural networks, encoder-decoder models, recurrent models, generative models, semantic segmentation, instance segmentation, medical image segmentation.
1. Introduction
- Image Segmentation은 다양한 분야에서 사용되고, 전통적인 방식도 여럿있었으나 현재 딥러닝 기반의 기술이 새로운 시대를 열었다. (popular deep learning model, DeepLabv3)
- 이 논문은 2019년 까지의 100개가 넘는 최신 문헌을 검토하여 구석구석 비교하고 통찰력을 제공할 것이다.
- 우리는 딥러닝 기반 작업들을 다음과 같이 분류하였다.

- 이 논문에서 신경망 선택, 학습 데이터, 학습 전략, 손실 함수등 종합적인 리뷰와 통찰력있는 분석을 제공해준다고 한다.
2. Overview of Deep Neural Networks
아쉽게도 이 논문에서 transformers은 다루지 않는다고 한다.
- 간단한 Transfer Learning에 대한 언급
2.1 Convolutional Neural Networks (CNNs)
CNNs은 보통 3가지 레이어로 구성된다.
1. Conv layer - 특징 추출을 위한 합성
2. Activation layer - 모델을 비선형으로 만들기 위함
3. Pooling layer - 특징맵을 작게 만들어줌
The main computational advantage of CNNs is that all the receptive fields in a layer share weights,
한 레이어에서 하나의 커널을 가지기 때문에, 전체 이미지에 대한 정보를 담고 있으며 적은 weights들로 효율적으로 계산할 수 있다는 뜻으로 보인다.
2.2 Recurrent Neural Networks (RNNs) and the LSTM
- RNN, LSTM에 대한 소개
(잘모르겠음)
2.3 Encoder-Decoder and Auto-Encoder Models
- Encoder는 입력을 latent-space representation으로 압축하고, 디코더는 그것을 출력으로 예측한다. Latent-representation은 의미론적 정보를 캡쳐하는데에 필수적이다.
- Auto-encoders는 encoder-decoder 모델들 중에서 입력과 출력이 같은 특별한 케이스이다.
2.4 Generative Adversarial Networks (GANs)
GAN도 설명을 하지만 Segmentation에 대한 언급은 하나도 없다. 왜 넣은거지?
3 DL-Based Image Segmentation Models
여러 이유 때문에 신경망 구조로 그룹화하여 설명한다.
읽는 도중 dilated convolution에 대해 잘 몰라서 따로 찾아봤다
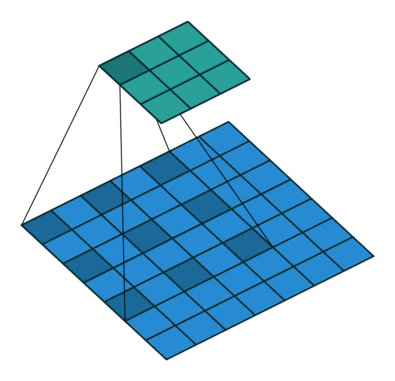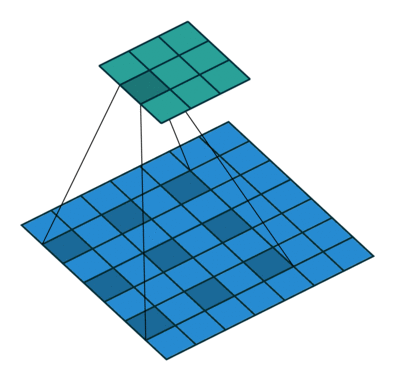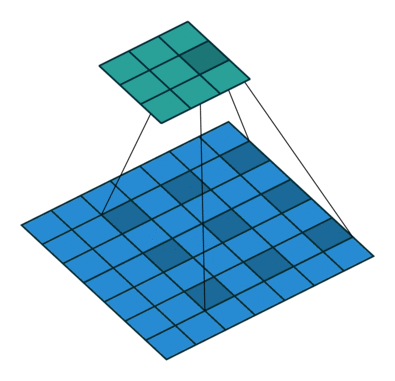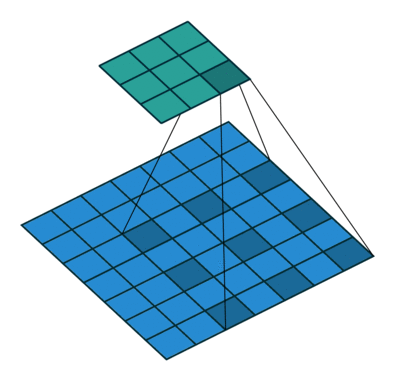
Segmenation 뿐만 아니라 Object Detection 분야에서도 이득을 볼 수 있다. 이와 같이 Contextual Information이 중요한 분야에 적용하기 유리하다. 또한 간격을 조절하여 다양한 Scale에 대한 대응이 가능하다.
출처: https://eehoeskrap.tistory.com/431 [Enough is not enough:티스토리]
3.1 Fully Convolutional Networks
- FCN (Fully Convolutional Network)이 첫 딥러닝 모델 for semantic segmentation
- FCN의 장점과 한계점 언급
- FCN의 한계점을 극복한 모델 ParseNet 언급 그리고 다양한 적용 사례들 언급
FCN도 논문을 읽고 모델을 만들어 봐야겠다.
3.2 Convolutional Models With Graphical Models
- CRF (Semantic image segmentation with deep convolutional nets and fully connected crfs) - DeepLAB_V1
- CNN의 지역화 특성의 단점을 보완- DCNN(deep CNN) + Fully connected CRF 2stage
- MRF (Semantic image segmentation via deep parsing network)
여기서 CRF, MRF를 사용하는데 개념을 찾아봐도 이해하기 힘들었다. DeepLab의 논문을 읽을 예정이니 그때 다시 정리를 하면서 이해해야겠다.
3.3 Encoder-Decoder Based Models
최근의 대부분의 Segmentation 모델은 인코더-디코더 아키텍처를 사용한다.
이 논문에서는 General Segmention과 Medical Image Segmentation을 구룹화 하였다.
3.3.1 Encoder-Decoder Models for General Segmentation
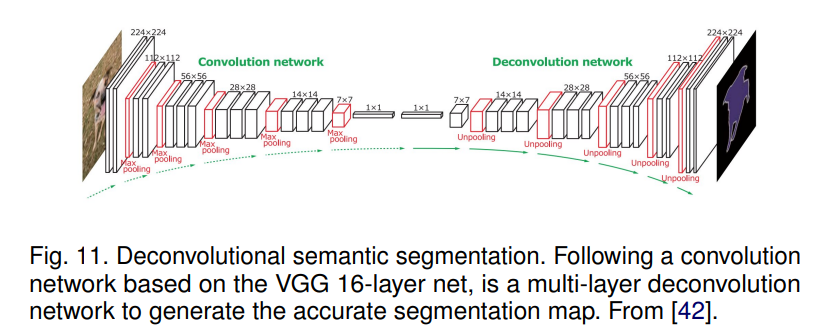
보통 그림처럼 두가지 부분으로 이루어 져있는데, Convolution network와 Deconvolution network이다. 그냥 Convolution network 반대 버전이다. pooling -> unpooling
위 그림에서 FCN을 빼고 Fully Convolutional Network로 만든 모델이 SegNet이다.
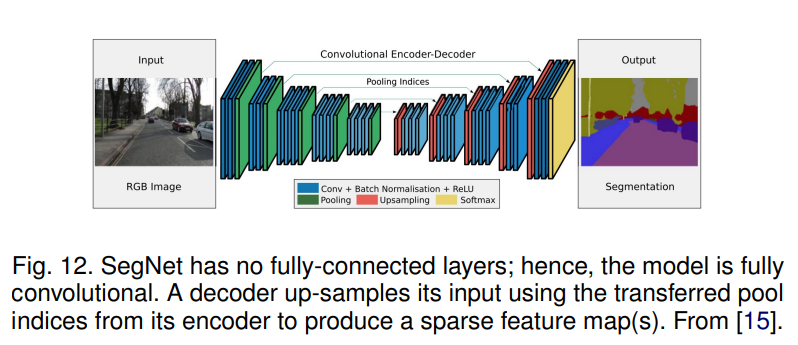
그리고 그림을 보면 알수있지만, Deconvolution이 아니고 Upsampling 후 Convolution을 사용한 것을 알 수 있다.
여기까지 논문을 읽어 보고 나머지 내용은 내가 몰라서 찾아보는 부분만 찾아서 보는식으로 해야겠다.
